NLP基础(分词):wordpiece 算法


导读:在之前的文章中,我们介绍了BPE(Byte Pair Encoding)算法如何通过合并高频字符对解决未登录词问题(NLP基础(分词):BPE 算法)。今天,我们将深入探讨其升级版算法——WordPiece。作为BERT、GPT等主流模型的分词核心,WordPiece在BPE的基础上引入了更智能的合并策略。它究竟有何独特之处?为何能成为预训练模型的标配?本文将通过原理剖析、代码实战和实例对比,带你彻底掌握WordPiece!
1
WordPiece vs BPE
BPE的核心是合并高频字符对(例如将“u”和“g”合并为“ug”),而WordPiece的合并策略更进一步——每次选择合并后能最大化语言模型概率的字符对。简而言之,BPE是“频率驱动”,而WordPiece是“概率驱动”。
🌰举个栗子🌰
假设词汇表包含以下单词:
low: 5次lowest: 3次newer: 6次wider: 4次
BPE的选择:合并频率最高的字符对(如e和r,共出现10次)。
WordPiece的选择:计算合并后句子的整体概率提升,优先合并语义更连贯的字符对(如low和est)。
2
算法原理
1. 核心公式:概率最大化
WordPiece通过以下公式选择合并的字符对:
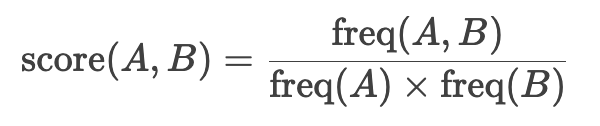
其中,freq(A)和freq(B)是字符A和B的独立频率,freq(A,B)是它们连续出现的频率。分数越高,说明A和B的共现越有意义。
2. 算法步骤
- 初始化:将所有单词拆分为字符(如“chat”拆为
c, h, a, t)。 - 统计字符对得分:根据公式计算每对相邻字符的得分。
- 合并最高分字符对:将得分最高的字符对合并为一个新符号。
- 重复迭代:直到词表大小达到预设值或无法继续合并。
3. 实例演示
假设有一个简单的训练语料库,包含以下单词及其频率:
{'hug': 10, 'pug': 5, 'pun': 12, 'bun': 4, 'hugs': 5}
通过WordPiece算法进行3次合并,生成子词。
第一次合并:
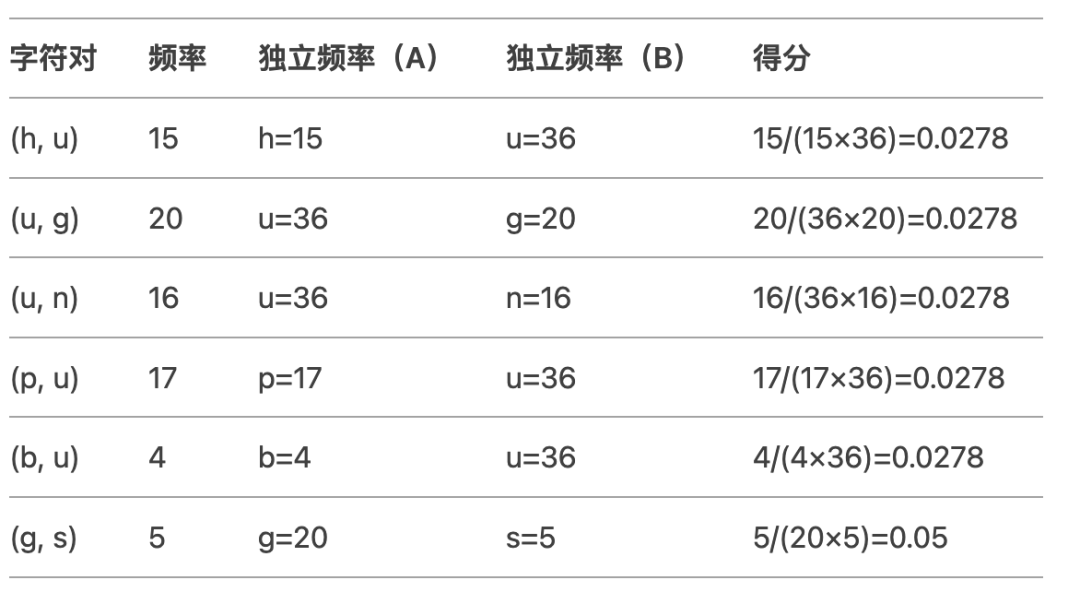
最高得分字符对:(g, s)(得分0.05)。
合并结果:将 g s 合并为 gs,更新训练语料:
{'h' 'u' 'g': 10, 'p' 'u' 'g': 5, 'p' 'u' 'n': 12, 'b' 'u' 'n': 4, 'h' 'u' 'gs': 5}
第二次合并:
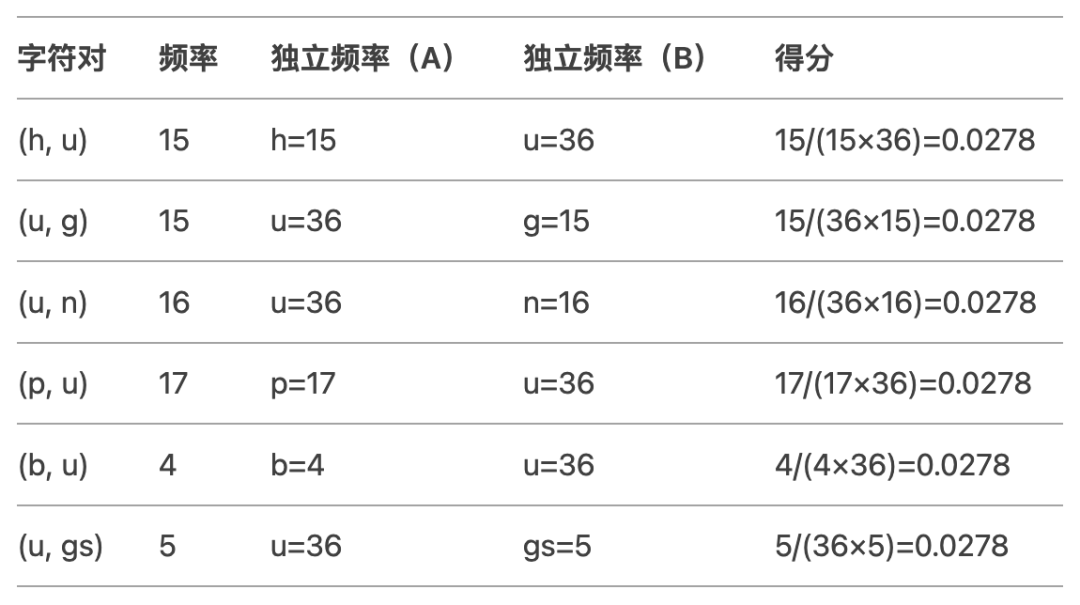
最高得分字符对:所有得分相同(0.0278),按顺序选择第一个 (h, u)。
合并结果:将 h u 合并为 hu,更新训练语料:
{'hu' 'g': 10, 'p' 'u' 'g': 5, 'p' 'u' 'n': 12, 'b' 'u' 'n': 4, 'hu' 'gs': 5}
第三次合并:
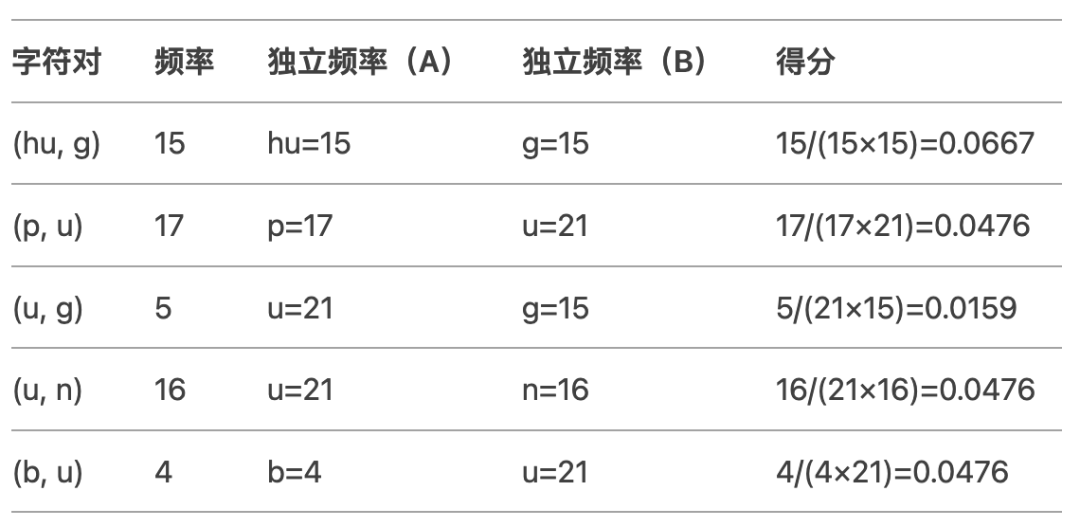
最高得分字符对:(hu, g)(得分0.0667)。
合并结果:将 hu g 合并为 hug,更新训练语料:
{'hug': 10, 'p' 'u' 'g': 5, 'p' 'u' 'n': 12, 'b' 'u' 'n': 4, 'hugs': 5}
最终,保留了高频词'hug',原'hugs'被拆成'hug'和's'。
3
python实现
下面通过python代码实现上述示例:
from collections import defaultdict
def compute_scores(vocab):
"""计算字符对得分(基于拆分后的字符序列)"""
pairs = defaultdict(int)
char_counts = defaultdict(int)
for word, freq in vocab.items():
chars = word.split() # 按空格拆分已分割的字符
for i in range(len(chars)):
char_counts[chars[i]] += freq
if i < len(chars) - 1:
pair = (chars[i], chars[i+1])
pairs[pair] += freq
scores = {}
for pair, count in pairs.items():
a, b = pair
score = count / (char_counts[a] * char_counts[b])
scores[pair] = score
return scores
def merge_vocab(pair, vocab):
"""合并字符对(处理拆分后的字符序列)"""
a, b = pair
merged = f"{a}{b}"
new_vocab = {}
for word, freq in vocab.items():
# 将字符序列中的 "a b" 替换为 "ab"
new_word = ' '.join(word.split()).replace(f"{a} {b}", merged)
new_vocab[new_word] = freq
return new_vocab
# 初始词汇表(已拆分)
vocab = {
'h u g': 10,
'p u g': 5,
'p u n': 12,
'b u n': 4,
'h u g s': 5
}
# 执行3次合并
for i in range(3):
scores = compute_scores(vocab)
best_pair = max(scores, key=scores.get)
vocab = merge_vocab(best_pair, vocab)
print(f"Iteration {i+1}: Merged {best_pair} → {vocab}")得到结果如下:
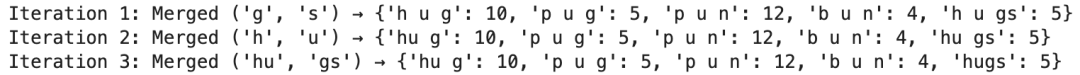
4
优缺点
优点
- 语义优先:通过概率最大化合并,子词更贴合语义(如优先合并
##ing而非i和n)。 - 适配预训练模型:BERT等模型依赖上下文,WordPiece能捕捉词根、词缀等语义单元。
- 歧义处理:对多义词(如“bank”)可生成不同子词组合,增强模型鲁棒性。
缺点
- 计算复杂:每次合并需重新计算概率得分,训练效率低于BPE。
- 依赖初始分词:需预拆分为字符,对中文等无空格语言需额外处理。
- 不可逆性:合并后的子词无法拆分,可能导致错误累积。
参考文献:
1. Wu, Y., et al. (2016). Google’s Neural Machine Translation System. arXiv:1609.08144.
2. Devlin, J., et al. (2018). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. arXiv:1810.04805.
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-07-06,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号