模型训练显存占用分析,谁是内存杀手?


模型训练时占用显存大小,可分为两大部分。模型状态:包括模型参数,对应梯度和优化器状态。剩余状态:包括中间值激活状态,临时内存和内存碎片,其中大头是激活值状态。本节结合前向和反向计算过程,分析两大部分的显存占用。
1)混合精度训练的整体流程以及使用FP32精度更新参数的必要性。 2)通过更新简单神经网络的参数,分析各种参数的产生和传递过程。 3)激活值的显存占用和对应内存优化策略-激活值重计算介绍
1,混合精度下的显存占用
1.1,混合精度训练
混合精度训练是一种结合单精度(FP32)和半精度(FP16)优势的模型训练技术,旨在平衡训练效率与模型精度,其核心逻辑是,用 FP16 执行核心计算(降低存储 / 带宽消耗),用 FP32 维护权重主副本(保障精度)。
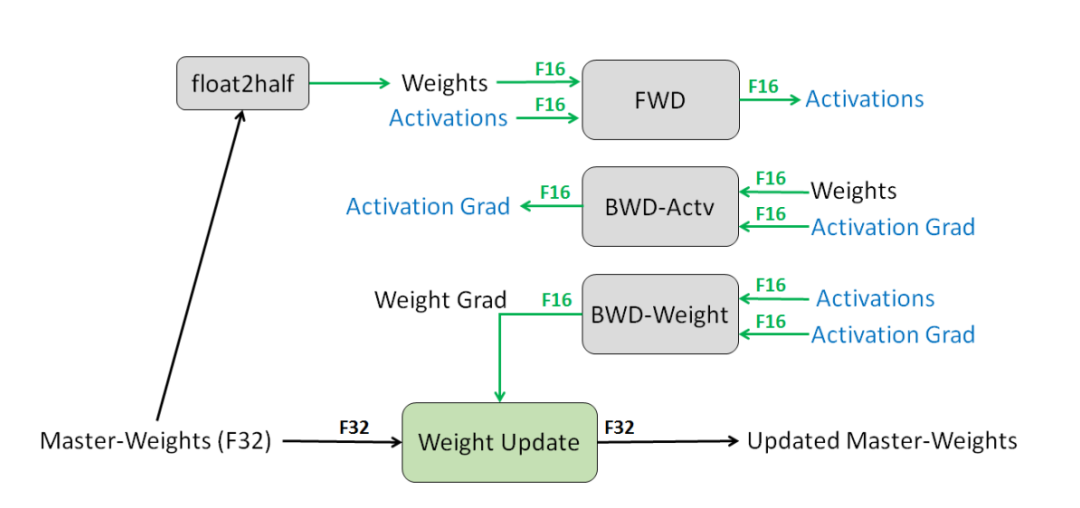
图1,混合精度训练过程
下面分四个阶段,权重初始化,前向传播,反向传播,权重更新,具体介绍混合训练的过程。
权重初始化
- • 维护一个 FP32 权重主副本(Master Weights)用于存储完整精度的权重信息,避免更新过程中精度丢失,这是保障精度的核心。
- • 每次迭代前,将 FP32 主权重转换为 FP16 格式进行存储,并用于当前迭代的前向和反向计算,不直接参与权重更新。
前向传播
- • 输入数据与 FP16 权重进行计算,得到的所有激活值(Activations)均以 FP16 格式存储,大幅降低存储需求。
- • 保存 FP16 格式的激活值,供后续反向传播时复用,进一步减少存储开销。
反向传播
- • 基于 FP16 格式的激活值和损失函数,计算FP16 格式的权重梯度(Gradients)。反向传播的核心计算仍用 FP16 完成,降低计算过程中的带宽占用。
权重更新
- • 梯度与学习率相乘。由于 FP16 可能无法表示极小的 “梯度 × 学习率” 值(或因数值对齐导致更新失效),需将 FP16 梯度转换为 FP32 格式,与 FP32 学习率进行乘法运算。
- • 更新 FP32 主权重,用上述 FP32 格式的 “梯度 × 学习率” 更新 FP32 主权重,确保权重更新的精度不丢失。
- • 迭代循环:下一次迭代时,重复 “FP32 主权重→FP16 计算副本” 的转换,进入新一轮前向 / 反向流程。
混合精度训练的本质是 “扬长避短”:用 FP16 的低存储 / 低带宽优势加速计算,用 FP32 的高精度优势保障权重更新的准确性,实现 “精度与 FP32 训练持平、存储 / 带宽消耗减半” 的目标
1.2,显存占用
训练中显存占用的两大部分:模型状态和剩余状态,具体到参数值类型为,参数、梯度、优化器参数、中间激活值四类。在训练过程中采用混合精度和Adam优化器,除去中间激活值,前三类占用显存约为可训练参数量的16倍。这里指的是常驻内存的占用,对于梯度从FP16到FP32的转换的内存消耗是临时的,最终也不需要保存FP32的梯度。
假设参数量为 , 显存占用如下:
使用FP16精度的参数和梯度,完成前向计算和反向传播的核心计算,优化器维护了一份FP32精度的参数副本,和对应FP32精度的一阶和二阶动量,并使用FP32精度更新参数。
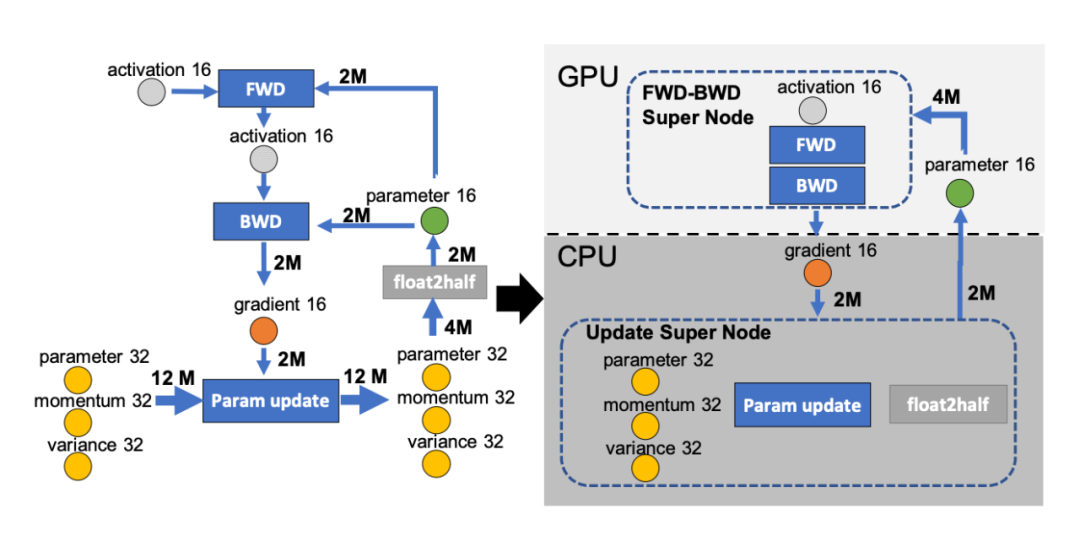
图2,前向计算和反向传播数据流图。图片来源[2]
2,为什么需要这些变量
下面以包含三个节点的简单神经网络,说明前向和反向传播的过程:
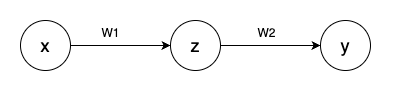
- • 参数初始化
x 为输入初始值为10。
z 为隐层神经元,表达式为:
y 为输出初始值为5,表达式为:
w1 为第一层神经元参数,w2 为第二层神经元参数,初始值都为1
损失函数:
1.1,第一次前向过程和损失计算
- • 前向计算过程
- • loss 计算
- • 反向传播计算导数
在以上的过程中,参数、中间值,梯度都是使用FP16的精度格式完成计算和存储的。
- • 参数更新
学习率为
参数更新时,需要完成参数和梯度从FP16到FP32的精度转换后再进行参数更新,更新后FP32参数和梯度转换到FP16保存,并进行下一轮的迭代。
总结:
完成一次完整的参数更新,需要用到的变量有:
- • 剩余状态:主要是中间激活值、输入x、输出y 和 、中间的z值。
- • 模型状态:可训练的参数 w1 和 w2,模型参数梯度 和(adam优化器状态)。
3,中间激活值显存占用分析
3.1,什么是中间激活值?
在模型训练过程中,前向计算会产生一些输出结果,这些结果在反向传播算梯度时,会用来一起计算梯度,这些前向计算结果统一称为中间激活状态 Activations。在混合精度计算中,中间激活一般使用fp16保存,一个参数占两个字节。
激活值占用的内存,各大分布式框架中都可以通过激活值重计算的方式优化。核心思想是通过牺牲计算量来换取内存的优化,即保存一部分,计算一部分,最终能优化到总参数量的33%[1],这就是 actions checkpoint的策略。
3.2,中间激活值显存占用估计
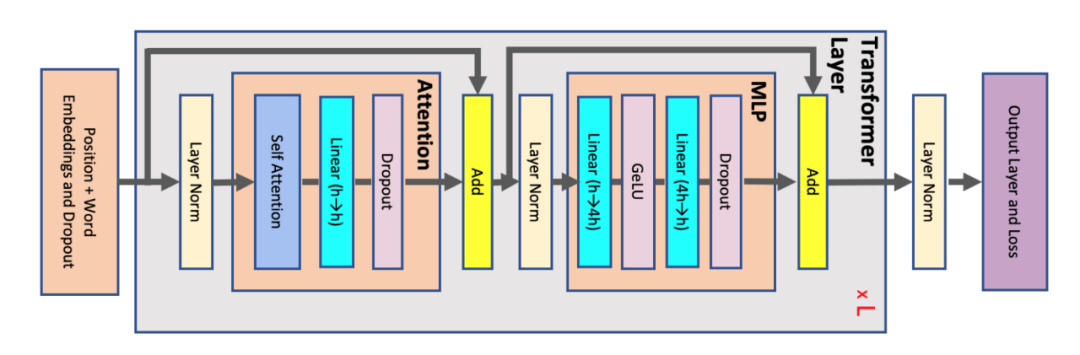
图2,大模型架构图仅展示一层结构,并显示了内部各模块的操作。图片来源[3]
输入向量为 , 其中 b为batch_size,s 为序列长度,h为隐层向量维度,记模型多头数为a。
- • 进行attention 部分
1,保存共享输入 x,占用:
2,计算 时,需要保存两个变量,占用: ,
3,softmax 计算保存输出,输出的维度为 [b, a, s, s],占用:, a为模型多头数量。
4,进行dropout需要mask矩阵和输出结果,占用:
5,计算权重,需要保存结果和变量V,占用:
6,输出进行dropout,保存mask ,占用:
attention 模块统计:
- • 进行 前馈MLP 计算
1,保存输入x,占用:
2,第一层输出结果,占用:
3,ReLU 激活输出,占用:
4,输出进行dropout,保存mask矩阵,占用:
MLP模块统计:
在进入attention 和MLP 之前还需要layer normal, 保存输出,占用:
总结
假设有l层,总的显存占用为:
前面讲到模型的参数量为 ,当模型的层数和隐藏层维度确定后,模型参数量是固定值。而激活值占用显存和batch大小,序列长度成正比。所以当出现OOM内存溢出时候,除了使用激活值重计算,还可以适当减少batch大小。
参考:
1, arxiv:1604.06174 2, arXiv:2101.06840 [cs.DC] 3, arXiv:2205.05198v12.1.1
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-09-06,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号