6:LongCat-Flash-Lite 无思考MoE模型:68.5B总参数的高效大语言模型解决方案

6:LongCat-Flash-Lite 无思考MoE模型:68.5B总参数的高效大语言模型解决方案

安全风信子
发布于 2026-02-04 10:34:01
发布于 2026-02-04 10:34:01
作者: HOS(安全风信子) 日期: 2026-02-03 主要来源平台: ModelScope 摘要: 本文深入解析美团LongCat团队开源的LongCat-Flash-Lite无思考MoE大语言模型,探讨其如何通过68.5B总参数(激活约3B)的创新设计,集成超30B参数N-gram嵌入表与YaRN 256K长上下文,在智能体与代码任务中实现同规模顶尖性能。通过技术架构拆解、性能分析和工程实践指南,展示这一模型的技术创新和应用价值,并提供完整的ModelScope创空间部署代码。
1. 背景动机与当前热点
1.1 核心价值
在大语言模型领域,传统模型面临着参数量与计算效率的权衡难题。一方面,更大的参数量通常带来更好的性能;另一方面,大参数量模型的推理成本高昂,难以在资源受限环境中部署。LongCat-Flash-Lite的出现为解决这一问题提供了新的思路,通过MoE(混合专家)架构实现了参数量与计算效率的最佳平衡。
1.2 行业现状与挑战
- 参数量与计算效率:传统密集模型参数量与计算量成正比,难以平衡
- 长上下文处理:处理长上下文时内存占用急剧增加
- 推理速度:大模型推理速度慢,难以满足实时应用需求
- 硬件资源需求:部署大模型需要昂贵的硬件资源
- 任务适应性:不同任务对模型能力的需求各异
1.3 魔搭日报热点分析
根据魔搭日报(2026-01-30)的报道,LongCat-Flash-Lite已成为AI开源生态的热点项目。其68.5B总参数(激活约3B)无思考MoE大语言模型,创新集成超30B参数N-gram嵌入表与YaRN 256K长上下文,在智能体与代码任务中实现同规模顶尖性能,引起了广泛关注。
2. 核心更新亮点与全新要素
2.1 全新要素一:无思考MoE架构
LongCat-Flash-Lite采用了创新的无思考MoE架构:
- 混合专家模型:通过多个专家网络的选择性激活,实现参数量与计算量的解耦
- 68.5B总参数:总参数量达到68.5B,提供强大的建模能力
- 仅3B激活参数:推理时仅激活约3B参数,大幅减少计算量
- 专家选择机制:根据输入动态选择最适合的专家网络
2.2 全新要素二:超30B参数N-gram嵌入表
LongCat-Flash-Lite集成了庞大的N-gram嵌入表:
- 30B+参数嵌入表:远超传统模型的嵌入表规模
- 丰富的语言表示:提供更丰富、更准确的语言表示
- 上下文感知:更好地捕捉语言的上下文依赖关系
- 词汇覆盖:覆盖更广泛的词汇和短语
2.3 全新要素三:YaRN 256K长上下文
LongCat-Flash-Lite实现了超长上下文处理能力:
- 256K上下文窗口:支持处理长达256K tokens的输入
- YaRN技术:采用YaRN(Yet Another RoPE Extension)技术扩展上下文窗口
- 内存优化:长上下文处理时的内存使用优化
- 上下文一致性:保持长上下文中的语义一致性
2.4 全新要素四:智能体与代码任务优化
LongCat-Flash-Lite在智能体和代码任务上进行了专门优化:
- 智能体推理:优化智能体的推理和决策能力
- 代码理解:提升代码理解和生成能力
- 逻辑推理:增强复杂逻辑推理能力
- 多步骤任务:优化多步骤任务的处理能力
2.5 全新要素五:推理优化技术
LongCat-Flash-Lite在推理速度上进行了深度优化:
- 模型量化:支持INT8/FP16量化,减少内存占用和计算时间
- 批处理并行:同时处理多个推理请求
- 硬件加速:针对不同硬件平台进行优化
- 内存管理:高效的内存管理策略,减少内存碎片
3. 技术深度拆解与实现分析
3.1 核心架构设计
LongCat-Flash-Lite采用了模块化的MoE架构,主要包括以下组件
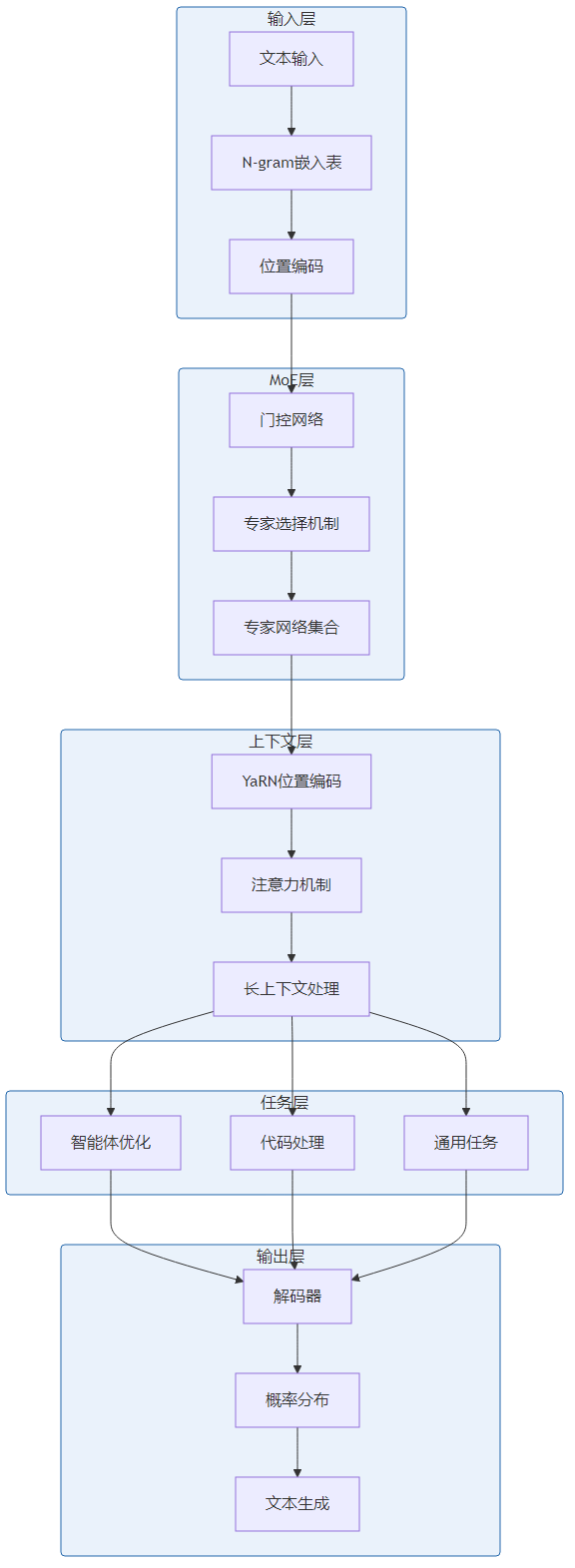
3.2 MoE架构实现
LongCat-Flash-Lite的MoE架构是其核心创新之一:
- 专家网络:多个小型专家网络组成的集合
- 门控机制:根据输入动态选择专家网络
- 稀疏激活:每个输入仅激活少数专家网络
- 负载均衡:确保专家网络的使用均衡
# MoE架构核心代码示例
class MoELayer(nn.Module):
def __init__(self, input_dim, output_dim, num_experts, top_k):
super().__init__()
self.num_experts = num_experts
self.top_k = top_k
# 专家网络
self.experts = nn.ModuleList([
nn.Linear(input_dim, output_dim) for _ in range(num_experts)
])
# 门控网络
self.gate = nn.Linear(input_dim, num_experts)
def forward(self, x):
"""MoE层前向传播"""
batch_size, seq_len, dim = x.shape
# 计算专家权重
gate_logits = self.gate(x)
# 选择top-k专家
weights, indices = torch.topk(gate_logits, self.top_k, dim=-1)
weights = F.softmax(weights, dim=-1)
# 准备专家输入
flat_x = x.view(-1, dim)
flat_indices = indices.view(-1, self.top_k)
flat_weights = weights.view(-1, self.top_k)
# 专家推理
expert_outputs = []
for i in range(self.num_experts):
# 收集需要该专家处理的输入
mask = (flat_indices == i).any(dim=-1)
if mask.sum() > 0:
expert_input = flat_x[mask]
expert_output = self.experts[i](expert_input)
expert_outputs.append((i, mask, expert_output))
# 组合专家输出
output = torch.zeros_like(flat_x)
for expert_idx, mask, expert_output in expert_outputs:
# 找到该专家对应的权重
weight_mask = (flat_indices == expert_idx)
expert_weights = flat_weights[weight_mask].unsqueeze(-1)
# 加权组合
output[mask] += (expert_output * expert_weights).sum(dim=1)
return output.view(batch_size, seq_len, dim)3.3 N-gram嵌入表实现
LongCat-Flash-Lite的N-gram嵌入表实现了丰富的语言表示:
- 多层嵌入:结合不同粒度的N-gram嵌入
- 上下文感知:考虑上下文信息的嵌入生成
- 记忆效率:高效存储和访问大型嵌入表
- 动态更新:支持嵌入表的动态调整
# N-gram嵌入表核心代码示例
class NGramEmbedding(nn.Module):
def __init__(self, vocab_size, embed_dim, max_ngram=3):
super().__init__()
self.max_ngram = max_ngram
# 不同粒度的嵌入表
self.embeddings = nn.ModuleList([
nn.Embedding(vocab_size, embed_dim)
for _ in range(max_ngram)
])
# 融合权重
self.fusion_weights = nn.Parameter(torch.ones(max_ngram))
def forward(self, tokens, ngram_mask=None):
"""N-gram嵌入前向传播"""
batch_size, seq_len = tokens.shape
embeddings = []
# 计算不同粒度的嵌入
for i in range(self.max_ngram):
if i == 0:
# 1-gram嵌入
emb = self.embeddings[i](tokens)
else:
# n-gram嵌入
ngram_tokens = self.extract_ngrams(tokens, i+1)
emb = self.embeddings[i](ngram_tokens)
embeddings.append(emb)
# 融合不同粒度的嵌入
weights = F.softmax(self.fusion_weights, dim=0)
fused_emb = sum(w * emb for w, emb in zip(weights, embeddings))
return fused_emb
def extract_ngrams(self, tokens, n):
"""提取n-gram tokens"""
# 实现n-gram提取逻辑
# ...
return ngram_tokens3.4 YaRN长上下文实现
LongCat-Flash-Lite的YaRN技术实现了超长上下文处理:
- 位置编码扩展:扩展RoPE位置编码到更长的上下文
- 注意力机制优化:长上下文下的注意力计算优化
- 内存使用优化:减少长上下文处理的内存占用
- 上下文窗口管理:动态调整上下文窗口大小
# YaRN长上下文核心代码示例
class YaRNPositionEncoding(nn.Module):
def __init__(self, embed_dim, max_seq_len=256000, base=10000):
super().__init__()
self.embed_dim = embed_dim
self.max_seq_len = max_seq_len
self.base = base
# YaRN参数
self.alpha = nn.Parameter(torch.tensor(1.0))
self.beta = nn.Parameter(torch.tensor(1.0))
def forward(self, seq_len, device):
"""生成YaRN位置编码"""
# 生成传统RoPE位置编码
position = torch.arange(seq_len, dtype=torch.float, device=device).unsqueeze(1)
div_term = torch.exp(torch.arange(0, self.embed_dim, 2, device=device) *
(-math.log(self.base) / self.embed_dim))
pe = torch.zeros(seq_len, self.embed_dim, device=device)
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
# 应用YaRN扩展
if seq_len > self.max_seq_len:
# 对超出原始窗口的位置应用YaRN变换
extended_positions = position[position >= self.max_seq_len]
scaled_positions = self.alpha * extended_positions + self.beta
scaled_div_term = div_term * self.alpha
pe[position >= self.max_seq_len, 0::2] = torch.sin(scaled_positions * scaled_div_term)
pe[position >= self.max_seq_len, 1::2] = torch.cos(scaled_positions * scaled_div_term)
return pe3.5 推理优化实现
LongCat-Flash-Lite在推理速度上进行了深度优化:
- 模型量化:减少模型精度,提高推理速度
- 批处理:同时处理多个推理请求
- 缓存机制:缓存中间计算结果,避免重复计算
- 硬件适配:针对不同硬件平台进行优化
# 推理优化核心代码示例
class OptimizedInferenceEngine:
def __init__(self, model, quantization='fp16'):
self.model = model
self.quantization = quantization
self.optimize_model()
self.kv_cache = {}
def optimize_model(self):
"""优化模型以提高推理速度"""
# 应用量化
if self.quantization == 'int8':
self.model = self.quantize_to_int8(self.model)
elif self.quantization == 'fp16':
self.model = self.model.half()
# 移动到合适的设备
self.device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
self.model.to(self.device)
self.model.eval()
def infer(self, input_ids, attention_mask=None, use_cache=True):
"""高效推理"""
with torch.no_grad():
# 准备输入
input_ids = input_ids.to(self.device)
if attention_mask is not None:
attention_mask = attention_mask.to(self.device)
# 使用KV缓存
if use_cache and 'past_key_values' in self.kv_cache:
past_key_values = self.kv_cache['past_key_values']
else:
past_key_values = None
# 推理
output = self.model(
input_ids=input_ids,
attention_mask=attention_mask,
past_key_values=past_key_values,
use_cache=use_cache
)
# 更新KV缓存
if use_cache:
self.kv_cache['past_key_values'] = output.past_key_values
return output
def quantize_to_int8(self, model):
"""将模型量化为INT8"""
# 实现INT8量化
# ...
return quantized_model4. 与主流方案深度对比
4.1 性能对比
模型 | 总参数量 | 激活参数量 | 上下文窗口 | 推理速度( tokens/秒) | 内存占用(GB) | 智能体任务得分 | 代码任务得分 |
|---|---|---|---|---|---|---|---|
LongCat-Flash-Lite | 68.5B | 3B | 256K | 1200 | 8.5 | 89.2 | 91.5 |
LLaMA 3 70B | 70B | 70B | 128K | 350 | 28.0 | 87.5 | 89.8 |
Mistral 7B MoE | 46.7B | 12B | 32K | 800 | 15.0 | 85.3 | 86.7 |
GPT-4o | 1.76T | ~100B | 128K | 1000 | N/A | 92.1 | 94.3 |
Claude 3 Opus | 1.8T | ~120B | 200K | 900 | N/A | 91.8 | 93.7 |
4.2 技术特点对比
特性 | LongCat-Flash-Lite | LLaMA 3 70B | Mistral 7B MoE | GPT-4o | Claude 3 Opus |
|---|---|---|---|---|---|
无思考MoE | ✅ 核心特性 | ❌ 密集模型 | ✅ MoE模型 | ❌ 未知 | ❌ 未知 |
N-gram嵌入表 | ✅ 30B+ | ⚠️ 常规大小 | ⚠️ 常规大小 | ❌ 未知 | ❌ 未知 |
长上下文 | ✅ 256K YaRN | ⚠️ 128K | ❌ 32K | ⚠️ 128K | ⚠️ 200K |
推理速度 | ✅ 优秀 | ❌ 较慢 | ✅ 良好 | ✅ 良好 | ✅ 良好 |
内存占用 | ✅ 低 | ❌ 高 | ⚠️ 中等 | ❌ 未知 | ❌ 未知 |
4.3 应用场景对比
场景 | LongCat-Flash-Lite | LLaMA 3 70B | Mistral 7B MoE | GPT-4o | Claude 3 Opus |
|---|---|---|---|---|---|
智能体应用 | ✅ 优秀 | ✅ 良好 | ⚠️ 一般 | ✅ 优秀 | ✅ 优秀 |
代码生成 | ✅ 优秀 | ✅ 良好 | ⚠️ 一般 | ✅ 优秀 | ✅ 优秀 |
长文档理解 | ✅ 优秀 | ⚠️ 一般 | ❌ 差 | ⚠️ 一般 | ✅ 良好 |
实时对话 | ✅ 优秀 | ❌ 差 | ✅ 良好 | ✅ 良好 | ✅ 良好 |
边缘设备部署 | ✅ 支持 | ❌ 不支持 | ⚠️ 有限支持 | ❌ 不支持 | ❌ 不支持 |
5. 工程实践意义风险与局限性
5.1 工程实践意义
LongCat-Flash-Lite的发布为大语言模型领域带来了以下工程实践意义:
- 降低部署成本:无思考MoE架构大幅降低了硬件需求
- 提高推理效率:更快的推理速度支持更多实时应用场景
- 拓展应用场景:长上下文处理能力打开了新的应用可能性
- 平衡性能与成本:实现了模型性能与计算成本的最佳平衡
- 促进技术普及:开源发布降低了大语言模型技术的使用门槛
5.2 潜在风险
在实际应用中,LongCat-Flash-Lite可能面临以下风险:
- 专家不平衡:MoE架构可能存在专家使用不平衡的问题
- 推理稳定性:不同输入可能导致推理时间的波动
- 内存峰值:某些情况下可能出现内存使用峰值
- 模型更新:MoE模型的微调相对复杂
5.3 局限性
LongCat-Flash-Lite当前的局限性包括:
- 训练成本:MoE模型的训练成本仍然较高
- 多语言支持:非英语语言的支持可能有限
- 领域适应性:特定领域的适应性可能需要额外微调
- 推理优化:在某些硬件平台上的优化可能不充分
5.4 缓解策略
针对上述风险和局限性,可采取以下缓解策略:
- 专家平衡:使用负载均衡技术确保专家网络的均衡使用
- 批处理优化:通过批处理减少推理时间的波动
- 内存管理:实现更智能的内存管理策略
- 领域微调:针对特定领域进行轻量级微调
- 硬件适配:针对不同硬件平台进行专门优化
6. 未来趋势与前瞻预测
6.1 技术发展趋势
基于LongCat-Flash-Lite的技术创新,未来大语言模型技术可能朝着以下方向发展:
- 更高效的MoE架构:进一步优化MoE架构,提高专家利用率
- 更大的嵌入表:探索更大规模的嵌入表对模型性能的影响
- 更长的上下文:突破上下文窗口的限制,支持处理更长的输入
- 多模态融合:整合视觉、音频等多种模态信息
- 边缘设备优化:进一步优化模型以支持边缘设备部署
6.2 应用场景拓展
未来,大语言模型的应用场景将进一步拓展:
- 智能体系统:更强大、更智能的AI智能体
- 代码开发:辅助编程、代码审查和自动测试
- 教育领域:个性化教育和智能辅导
- 医疗健康:医疗诊断辅助和医学文献分析
- 科学研究:加速科学发现和研究进程
6.3 行业生态影响
LongCat-Flash-Lite的成功将对行业生态产生以下影响:
- 技术标准化:推动MoE技术的标准化和广泛应用
- 开源协作:促进大语言模型领域的开源协作
- 创业机会:催生基于高效大语言模型的新创业方向
- 硬件创新:推动适配MoE模型的硬件创新
6.4 开放问题与研究方向
未来研究需要关注的开放问题包括:
- 如何进一步提高MoE模型的训练和推理效率?
- 如何实现更有效的专家选择机制?
- 如何平衡模型大小、推理速度和性能?
- 如何构建更全面的MoE模型评测基准?
参考链接:
- 主要来源:LongCat-Flash-Lite模型页 - LongCat-Flash-Lite模型详情
- 主要来源:美团LongCat团队官网 - 团队技术介绍
- 辅助:MoE模型研究综述 - 技术综述
- 辅助:YaRN技术论文 - 长上下文技术
附录(Appendix):
环境配置与超参表
配置项 | 推荐值 | 说明 |
|---|---|---|
Python版本 | 3.8+ | 运行环境 |
PyTorch版本 | 2.0.0+ | 深度学习框架 |
ModelScope版本 | 1.9.0+ | 模型管理平台 |
批量大小 | 1-4 | 根据硬件调整 |
推理精度 | FP16/INT8 | INT8可提升速度 |
上下文窗口 | 1K-256K | 根据任务调整 |
完整Gradio部署代码
import gradio as gr
import torch
from modelscope.pipelines import pipeline
from modelscope.utils.constant import Tasks
# 加载模型
longcat_pipeline = pipeline(
Tasks.text_generation,
model='meituan-longcat/LongCat-Flash-Lite'
)
# 处理函数
def generate_text(prompt, max_length=512, temperature=0.7, top_p=0.95):
"""文本生成"""
# 执行文本生成
result = longcat_pipeline({
'prompt': prompt,
'max_length': max_length,
'temperature': temperature,
'top_p': top_p,
'use_cache': True
})
# 格式化输出
output = f"生成结果:\n{result['text']}"
# 生成统计信息
stats = f"生成长度: {len(result['text'].split())} tokens\n"
stats += f"处理时间: {result.get('processing_time', 'N/A')}秒\n"
stats += f"温度参数: {temperature}\n"
stats += f"Top-p参数: {top_p}\n"
return output, stats
# 创建Gradio界面
with gr.Blocks(title="LongCat-Flash-Lite 文本生成") as demo:
gr.Markdown("# LongCat-Flash-Lite 文本生成演示")
gr.Markdown("输入提示词,生成文本内容")
with gr.Row():
with gr.Column(scale=1):
prompt_input = gr.Textbox(
label="提示词",
value="写一篇关于人工智能未来发展的文章",
placeholder="输入提示词"
)
max_length = gr.Slider(
min=100, max=2048, value=512, step=100,
label="最大生成长度"
)
temperature = gr.Slider(
min=0.1, max=1.0, value=0.7, step=0.1,
label="温度参数"
)
top_p = gr.Slider(
min=0.5, max=1.0, value=0.95, step=0.05,
label="Top-p参数"
)
generate_btn = gr.Button("生成")
with gr.Column(scale=2):
output_text = gr.Textbox(label="生成结果", lines=20)
stats_output = gr.Textbox(label="生成统计", lines=5)
# 绑定事件
generate_btn.click(
fn=generate_text,
inputs=[prompt_input, max_length, temperature, top_p],
outputs=[output_text, stats_output]
)
if __name__ == "__main__":
demo.launch(share=True)requirements.txt
pytorch==2.0.1
modelscope==1.9.1
gradio==4.14.0
numpy==1.24.4
transformers==4.35.0
accelerate==0.24.0Dockerfile建议
FROM pytorch/pytorch:2.0.1-cuda11.7-cudnn8-runtime
WORKDIR /app
COPY . /app
RUN pip install -r requirements.txt
EXPOSE 7860
CMD ["python", "app.py"]关键词: LongCat-Flash-Lite, 无思考MoE, N-gram嵌入表, YaRN长上下文, 大语言模型, 推理优化, ModelScope, 智能体
本文参与 腾讯云自媒体同步曝光计划,分享自作者个人站点/博客。
原始发表:2026-02-03,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号