Nature | 计算/AI 遇上药物发现:一场正在重塑制药产业的技术革命

Nature | 计算/AI 遇上药物发现:一场正在重塑制药产业的技术革命

DrugIntel
发布于 2026-03-30 15:58:55
发布于 2026-03-30 15:58:55

标题: Computational approaches streamlining drug discovery 作者: Anastasiia V. Sadybekov & Vsevolod Katritch 期刊:Nature 616, 673–685 (2023) 机构: University of Southern California DOI: 10.1038/s41586-023-05905-z 文章类型:综述(Review)
引言
做一款小分子药物,平均需要约15年时间、约20亿美元投入,而临床试验的失败率高达90%。这组冰冷的数字,是每一位药物研发从业者的日常现实。尽管失败最常发生在昂贵的临床阶段,但追根溯源,大多数失败的种子其实早在发现阶段就已经埋下——靶标验证不充分、配体性质欠佳、先导化合物的ADMET与药代动力学特征不理想。
Sadybekov和Katritch在2023年发表于Nature的这篇综述,系统审视了计算方法如何在药物发现的最早期环节带来根本性变革。它不是一篇简单的技术汇编,而是一幅关于 计算驱动药物发现 (computer-driven drug discovery)的全景路线图——从化学空间的指数级扩张,到虚拟筛选方法的架构创新,到AI/深度学习的能力边界与陷阱,再到物理与数据驱动方法的深度融合。
一、变革的三大基石
文章开篇即指出,计算药物发现从"辅助角色"走向"核心驱动力"并非偶然,而是三个相互独立又高度协同的因素共同推动的结果:
1.1 结构生物学革命:靶标的三维世界被打开
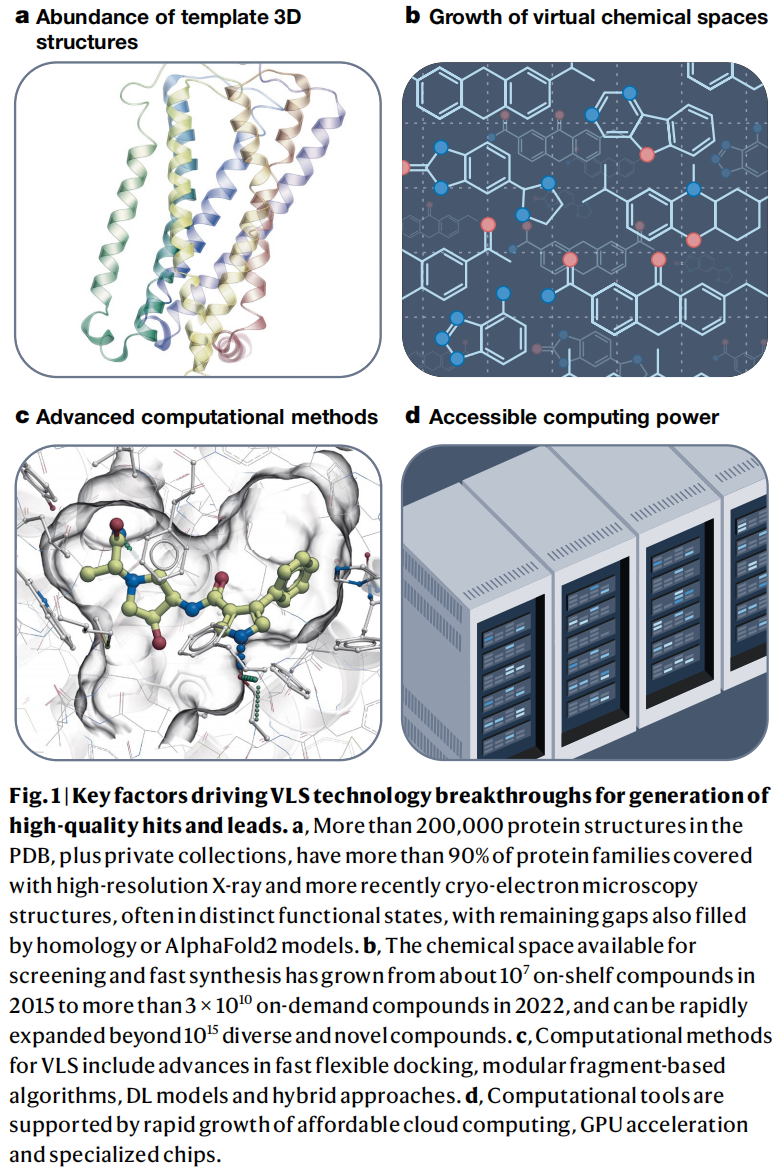
从自动化晶体学、微晶体学到冷冻电镜(cryo-EM)技术,目前PDB数据库中已积累超过20万个蛋白质结构,覆盖了90%以上的蛋白质家族。尤其值得一提的是GPCR领域的结构突破——作为介导50%以上药物作用的膜蛋白家族,GPCR长期以来是结构解析的难题,而近年来的技术进步使得大量GPCR结构在不同功能状态下被解析,直接为配体筛选和先导化合物优化提供了高分辨率的3D模板。
对于仍缺乏实验结构的靶标,AlphaFold2和RosettaFold等AI结构预测工具提供了补充。但文章也坦率指出,AlphaFold2模型在小分子对接中的表现参差不齐:对于有实验结构同源物的靶标尚可,但对GPCR和抗菌靶标等结构同源性较低的类别,对接表现令人失望。AlphaFold2模型通常需要清理阻塞结合口袋的loop区域,或补充已知的离子/辅因子信息,才能获得合理的命中富集。
1.2 可及化学空间的爆发式增长
这是整篇文章的核心论述主线之一。作者从三个层次梳理了化学空间的演化格局:
实体库(In-stock collections):规模约10⁶–10⁷量级,来自100多家化学供应商的现货化合物。优点是交付快(<1周)、HTS兼容;缺点是增长缓慢、新颖性有限、维护成本高。
按需合成虚拟库与化学空间(On-demand databases and spaces):这是当前变革的核心战场,规模达10¹⁰–10¹⁵量级。以Enamine REAL数据库/空间为代表,基于"稳健反应原理"(robust reaction principle),利用精心筛选的平行合成方案和库存合成子(building blocks),保证了合成快速(<4周)、可靠(成功率>80%)且经济可行。具体而言:
- • REAL数据库(完全枚举型):从2017年约1.7亿化合物增长到2022年超过55亿,其实际合成成功率已在多项前瞻性筛选中得到验证。
- • REAL Space(非枚举型化学空间):覆盖170+种反应和137,000+种合成子,截至论文发表时已达360亿化合物,并可进一步扩展到10¹⁵量级。
- • 其他商业空间包括WuXi的GalaXi Space(约80亿)、Otava的CHEMriya(118亿),这些空间之间的重叠率低于10%,保证了化学多样性。
生成式化学空间(Generative spaces):规模理论上可达10²³–10⁶⁰,涵盖所有理论上可能存在的类药有机分子。但与按需空间不同,生成空间中化合物的合成路径和成功率是未知的,需要额外的合成可行性预测。
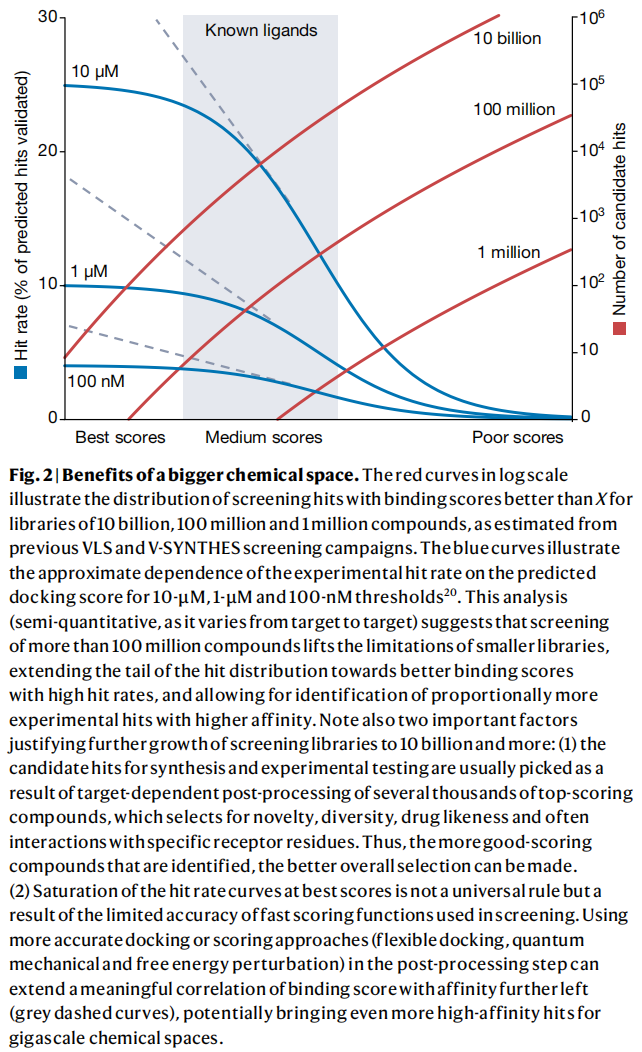
文章着重强调了"更大空间"带来的三重优势:
- 1. 命中数量线性增长:筛选更多化合物可成比例地增加命中数。
- 2. 命中质量指数提升:更大的空间使发现更高亲和力、更高选择性、更优理化性质的配体成为可能。超大规模筛选已反复证实能获得中纳摩尔乃至亚纳摩尔级别的命中。
- 3. 先导优化高度简化:任何命中在同一按需空间中都有数千个类似物和衍生物,大大减少了昂贵的定制合成需求。
1.3 计算方法与算力的协同进步
云计算和GPU加速使大规模计算成为可能,而新一代虚拟筛选算法则致力于在速度与准确性之间找到新的平衡点——这是应对10¹⁰量级化合物库的核心挑战。
二、超大规模虚拟筛选的核心挑战与技术路线
2.1 Gigascale筛选面临的两难困境
在百亿级化学空间中进行筛选,面临的并非单一的速度问题,而是速度与准确性的双重挑战:
速度瓶颈:按每个化合物10秒/CPU核的对接速度计算,筛选10¹⁰个化合物需要3,000+年的单核CPU时间,即使在云端也需约100万美元的计算费用。
假阳性灾难:在10¹⁰化合物库中,即使假阳性率低至百万分之一,也将产生10,000个假阳性命中——这些"作弊"分子利用打分函数的漏洞获得高分,可能完全淹没真正的候选命中。
文章指出了几种实用的假阳性控制策略:(1)双打分函数共识筛选;(2)选择高度多样化的命中(许多假阳性聚集于相似化合物);(3)从多个分数范围对冲选择;(4)人工审查最终候选列表中的异常相互作用模式。
同时,文章也提出了一个在gigaspace中独特的"宽容性原则":由于10¹⁰空间中潜在命中可达百万级,丢失50%的命中(假阴性)完全可以接受,因此可在一定程度上牺牲灵敏度以换取更低的假阳性率。
2.2 基于受体结构的虚拟筛选
分子对接是最经典的虚拟筛选方法,通过将虚拟库中的分子对接到受体结构中并预测结合分数来发现命中。文章总结了对接的三大技术路径:
- • 分子力学方法(如ICM docking、ROSETTALigand、Glide):使用内坐标表示进行配体的快速构象采样
- • 经验3D形状匹配(如DOCK、AutoDock Vina):基于三维互补性进行评分
- • 混合对接漏斗(如Glide SP→XP):先粗后精的分层策略
在标准虚拟库(<1000万化合物)的前瞻性筛选中,聚焦候选集通常能获得10–40%的实验命中率,产生具有0.1–10 µM亲和力的新化学实体。
随着库规模向REAL Space等gigascale空间扩展,传统的全库逐一对接方法遭遇了计算瓶颈。VirtualFlow等迭代方法尝试通过逐步提高对接精度来分层过滤,但计算成本仍与化合物数量线性增长,限制了其在快速膨胀的化学空间中的可扩展性。
2.3 V-SYNTHES:模块化合成子筛选范式
这是文章的技术亮点之一。V-SYNTHES(Virtual Synthon Hierarchical Enumeration Screening)代表了一种全新的筛选范式,其核心思想是将化学空间的模块化构造原理融入筛选算法本身。
算法流程(以二组分反应为例):
- 1. 步骤一——合成子枚举与封端:以REAL Space的反应和合成子目录为起点,在一个连接位点完全枚举合成子,用甲基或苯基封端其他位点,构建"最小枚举库"(1–3百万片段)。
- 2. 步骤二——片段对接筛选:将最小枚举库对接至靶标口袋,选取顶部约0.1%的最佳片段(1,000–10,000个)。
- 3. 步骤三——第二位点枚举:将选定的最佳片段与第二位点的合成子组合,构建聚焦化合物库(1–3百万全分子)。
- 4. 步骤四——全分子对接:以更精细的对接参数筛选聚焦库,得到顶部30,000–50,000个全分子。
- 5. 后处理:经过更精细的对接/打分、类药性过滤、PAINS过滤、多样性筛选等,最终选出100–500个候选分子用于合成与实验测试。
对于三组分或四组分反应,只需迭代重复步骤3–4即可。
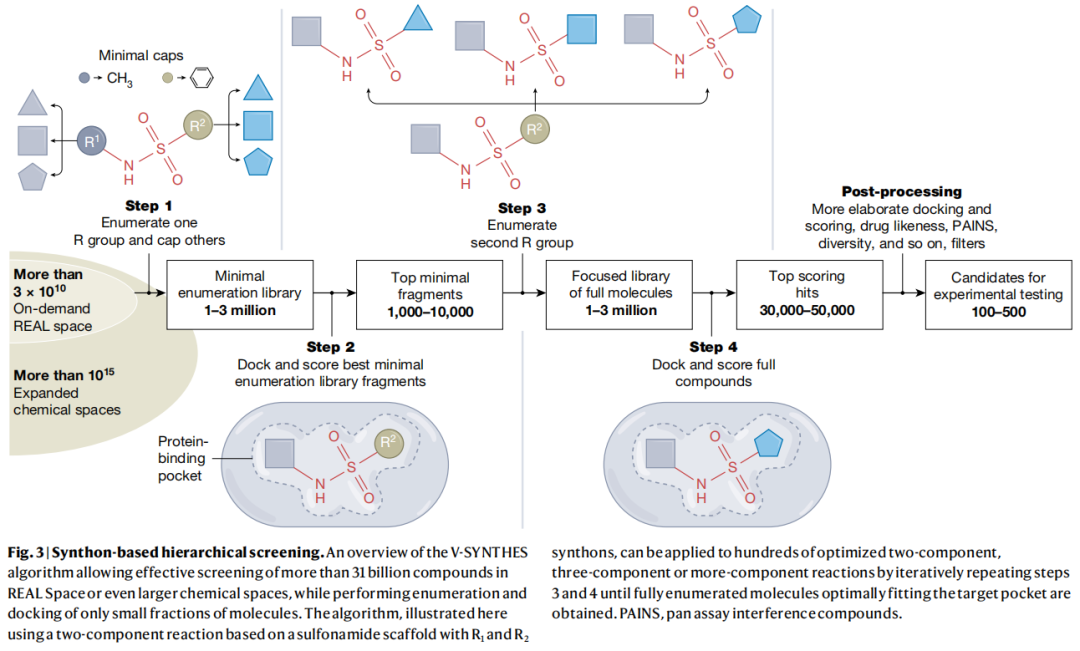
关键技术细节:
- • 将合成子与骨架组合并用最小基团封端是V-SYNTHES的关键要求——因为合成子的裸反应性基团往往会与受体产生强而虚假的相互作用,这些相互作用在全分子中并不存在。
- • 评估片段结合姿态时,会优先选择封端基团指向口袋有生长空间区域的命中。
实际表现:
- • 在大麻素受体CB2拮抗剂发现中,V-SYNTHES实现了23%的亚微摩尔命中率(标准VLS的5倍),同时仅消耗约1/100的计算资源。
- • 在ROCK1激酶筛选中取得了类似的命中率,其中一个命中达到低纳摩尔活性。
- • 后续的SAR-by-catalogue优化在同一化学空间中实现了约100倍的活性和选择性提升。
BioSolveIT的Chemical Space Docking采用了类似思路但更为激进——直接对接单个合成子片段再与骨架枚举。虽然更快,但由于不含骨架的更小片段对接可靠性下降,且反应性基团的性质常与反应产物不同,在环加成反应和三组分骨架上需要额外验证。
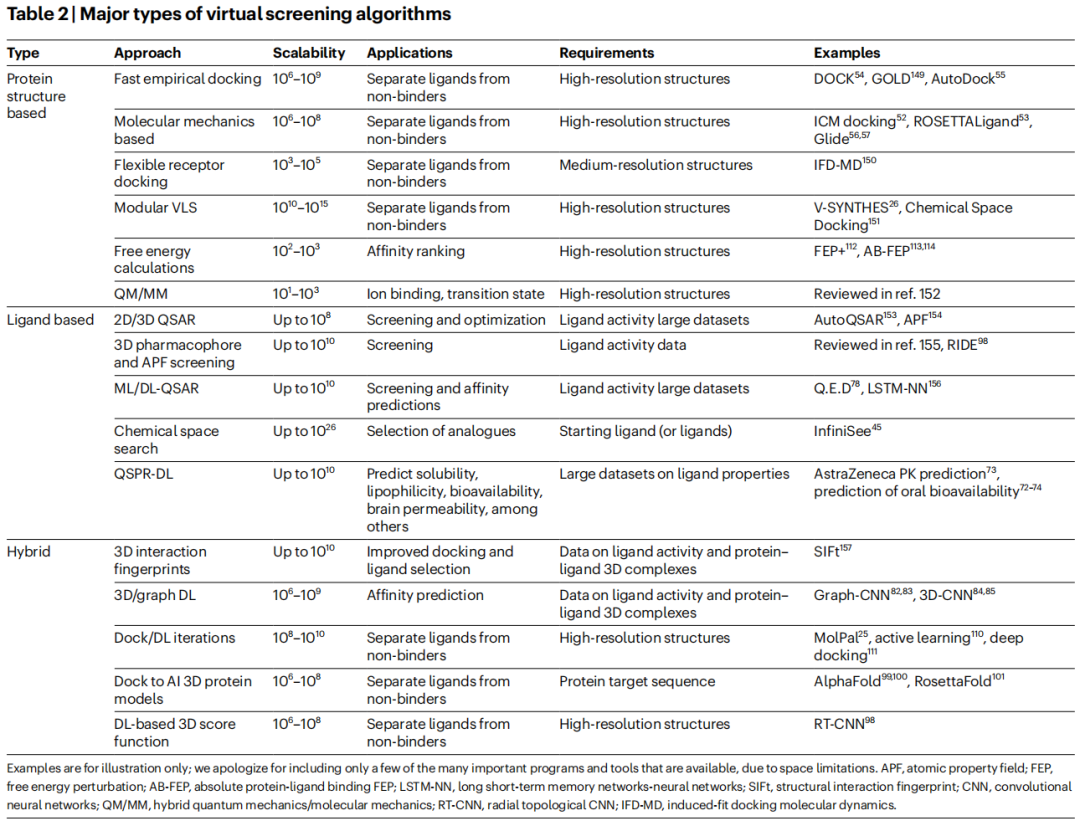
2.4 方法学全景对比
文章通过两张极为详尽的表格(Table 1和Table 2),系统比较了实验方法与计算方法的关键参数。以下提炼核心对比:
维度 | 传统HTS | 基于片段的药物发现 | Gigascale DEL | Gigascale VLS |
|---|---|---|---|---|
库规模 | 10⁵–10⁷ | 10³–10⁵ | 10¹⁰ | 10¹⁰–10¹⁵ |
命中率 | 0.01–0.5% | 1–5% | 0.01–0.5% | 10–40%* |
初始命中亲和力 | 弱 (1–10 µM) | 极弱 (100–1000 µM) | 中 (0.1–10 µM) | 中高 (0.01–10 µM) |
到先导化合物的定制合成数 | 500–1,000 | 500–1,000 | 200–500 | 0–50 |
专利新颖性 | 低,需改造 | 低,需理性设计 | 取决于DEL库 | 高,天然新颖 |
核心局限 | 库小、结合模式未知、设备昂贵 | NMR/X-ray设备昂贵,优化步骤多 | 假阳性多,需脱DNA重合成验证 | 计算资源(但模块化方法降低>1000倍) |
注:VLS的命中率指预测候选中经实验确认的比例。

三、AI/深度学习:能力、局限与陷阱
3.1 QSPR与QSAR:从理化性质到靶标活性
QSPR(定量构效-性质关系):在溶解性、脂溶性、口服生物利用度、血脑屏障渗透性等理化和药代动力学性质预测上,大规模公共和私有数据集的积累使得DL-QSPR模型已能对广泛化学空间做出较好预测。
QSAR(定量构效关系):在靶标活性预测方面,模型质量高度依赖数据可用性。IDG-DREAM Drug-Kinase Binding Prediction Challenge的盲测结果揭示了几个重要事实:
- • 最佳模型(团队Q.E.D,基于核回归)使用了约60,000个化合物-激酶对的亲和力数据进行训练,达到了Spearman秩相关系数0.53、RMSE 0.95 (pKd)的预测精度——这一精度与单点实验检测的准确性和召回率相当。
- • 尽管最佳DL模型使用了多达90万个实验数据点进行训练,其表现仍不及更简单的核回归模型。
- • 激酶家族是独特的:它是最大的靶标类别(500+成员),拥有相似的正构结合口袋和高度的交叉选择性。第二大系统性交叉反应家族是约50个氨基能GPCR。对于其他靶标家族,ML/DL方法的泛化能力仍有待检验。
3.2 通用结合亲和力模型的困境
开发普适性结合亲和力预测模型是AI药物发现的核心愿景。当前主流方向是利用PDBbind数据库中的蛋白-配体3D复合物结构及对应的结合数据,训练图卷积网络(Graph-CNN)、3D深度卷积网络(3D-CNN)等模型。
然而,一项关键研究发现,无论采用何种神经网络架构,对PDBbind复合物中非共价分子间相互作用的显式描述,相比仅使用配体或仅使用受体的简单近似,并未提供任何统计优势。换言之,这些DL模型的良好表现依赖于"记忆相似的配体和受体",而非真正捕捉到结合的一般规律。
文章将此归因于PDBbind数据库缺乏足够的"负空间"表示——即具有次优相互作用模式的配体,这些负例对于强制模型真正学习结合规律十分重要。
3.3 对AI药物发现的冷静审视
文章列举了AI面临的系统性挑战:
- • 过拟合与虚假性能:在有限且缺乏负例的数据集上训练的DL模型,容易产生过拟合。已有研究将某些类别的模型直接定性为"无用",或发现模型严重受到训练数据集中主观因素的偏倚。
- • "生产缺口":ML模型在实验室中表现良好但在实际部署中失败,是AI社区广泛认知的问题。AI领域的领袖明确指出,高质量数据的选择是弥合这一缺口的核心要求,呼吁转向"以数据为中心的AI"路线。
- • 可解释性:已有工具尝试使AI"可解释",即能够提炼数据中的一般趋势,但这仍处于早期阶段。
尽管如此,AI已开始产生实质性影响。文章列举了第一批进入临床的AI设计药物候选分子:
- • 激酶领域:AI驱动发现的DDR1激酶抑制剂,据报道在体内有效。ISM001-055已进入I期临床试验(治疗特发性肺纤维化),尽管化合物和靶标身份未披露。
- • GPCR领域:针对5-HT₁A、双靶标5-HT₁A–5-HT₂A和A₂A受体的AI驱动化合物已进入临床。
- • 重要背景:这些早期成功案例均来自已被深入研究的激酶和GPCR家族,且化合物与已知高亲和力骨架具有较高的化学相似性。下一代AI药物候选分子需要在新颖性和适用范围上实现突破。
四、混合方法:物理与数据驱动的深度融合
4.1 互补优势与协同策略
文章明确指出,基于物理的方法和数据驱动的方法具有互补的优缺点:
- • 基于结构的对接:天然可泛化到任何具有3D结构的靶标,在消除假阳性方面更为准确,但计算成本高。
- • 数据驱动方法:可在缺乏结构时工作,速度更快(尤其GPU加速),但难以泛化到数据匮乏的靶标。
在D3R Grand Challenge 4的配体IC₅₀预测盲测中,同时使用物理和ML打分的混合方法显著优于仅用其中一种的方法。这为混合策略提供了直接的实证支持。
4.2 迭代加速方法
为加速超大规模筛选,MolPal、Active Learning和DeepDocking等方法采用了"稀疏子集对接→训练ML过滤模型→全库过滤"的迭代策略,报告可实现14–100倍的计算成本降低。但文章也指出,这些方法在快速增长的化学空间中的可扩展性尚不确定。
4.3 从粗到精的多层次分析
文章强调了一个重要的方法论原则:快速对接算法和ML模型的打分函数主要被设计和训练用于区分潜在结合物与非结合物,而非精确预测结合亲和力。对于更精确的活性预测,初始筛选得到的较小聚焦库可进一步采用自由能微扰(FEP)等更精细但更慢的方法进行分析和排序。GPU加速正在使这些精细方法在虚拟筛选后处理和先导优化阶段的更广泛应用成为可能。
五、实战案例:SARS-CoV-2主蛋白酶的攻坚战
文章以SARS-CoV-2主蛋白酶(Mᵖʳᵒ)作为方法学比较的核心案例,这是一个公认的高难度靶标——活性位点浅而开放,数百次传统虚拟筛选尝试几乎全部失败。
5.1 超大规模虚拟筛选路线
- • VirtualFlow筛选14亿REAL化合物:发现10–100 µM范围的命中,经按需合成优化获得IC₅₀ = 1.0 µM的先导化合物。
- • 2.35亿化合物筛选(基于更合适的非共价抑制剂共晶结构PDB: 6W63):4个月内发现纳摩尔级Mᵖʳᵒ抑制剂,最佳化合物亲和力38 nM,细胞抗病毒活性77 nM——接近临床药物nirmatrelvir(Paxlovid活性成分)的水平,且具有良好的体外ADMET性质。
5.2 COVID Moonshot混合方法路线
- • 晶体学筛选1,500个小片段,发现71个结合于不同亚口袋的命中,但无一在100 µM浓度下显示体外蛋白酶抑制活性。
- • 众包计算设计(片段合并与生长)发现了多个SAR系列,最终通过结构驱动和AI驱动的计算方法,使用1000万+种MADE合成子优化,获得了细胞IC₅₀约100 nM的临床前候选化合物——规模空前(合成>2,400个化合物、执行>10,000个检测)。
5.3 关键启示
文章的一个重要判断是:尽管超大规模VLS的初始筛选结果较温和,但其总体产出与Moonshot这一更复杂、更昂贵的混合方法方案不相上下——而VLS仅需合成和测试数百个按需化合物。这表明,即便对于具有挑战性的浅口袋靶标,在gigascale级别执行、辅以准确结构和充分的测试与优化,基于结构的虚拟筛选仍可提供可行的替代方案。
六、未来展望:从Computer-Aided到Computer-Driven
6.1 化学空间的持续扩展
- • xREAL扩展已达1,730亿化合物,可进一步扩展至10¹⁵以上(通过MADE合成子、四/五组分反应、新型click化学)。
- • 新型稳健反应持续涌现:SuFEx点击化学、镍电催化双脱羧偶联反应、MIDA硼酸酯迭代偶联等,每种反应都可迭代式地生成数十亿多样化合物。
- • 全自动建块组装的机器人合成平台已在运行,尽管大规模生产数千种专用建块仍是瓶颈。
6.2 生成式设计与合成预测的融合
生成对抗网络结合强化学习(GAN-RL)已被用于同时预测合成可行性、新颖性和生物活性,实现了"计算优化→合成→体外测试"的迭代循环。深度学习逆合成分析也在推动对新反应序列和合成路径的预测。在成熟的反应体系和充分研究的靶标家族中,这些方法已产出临床候选分子。
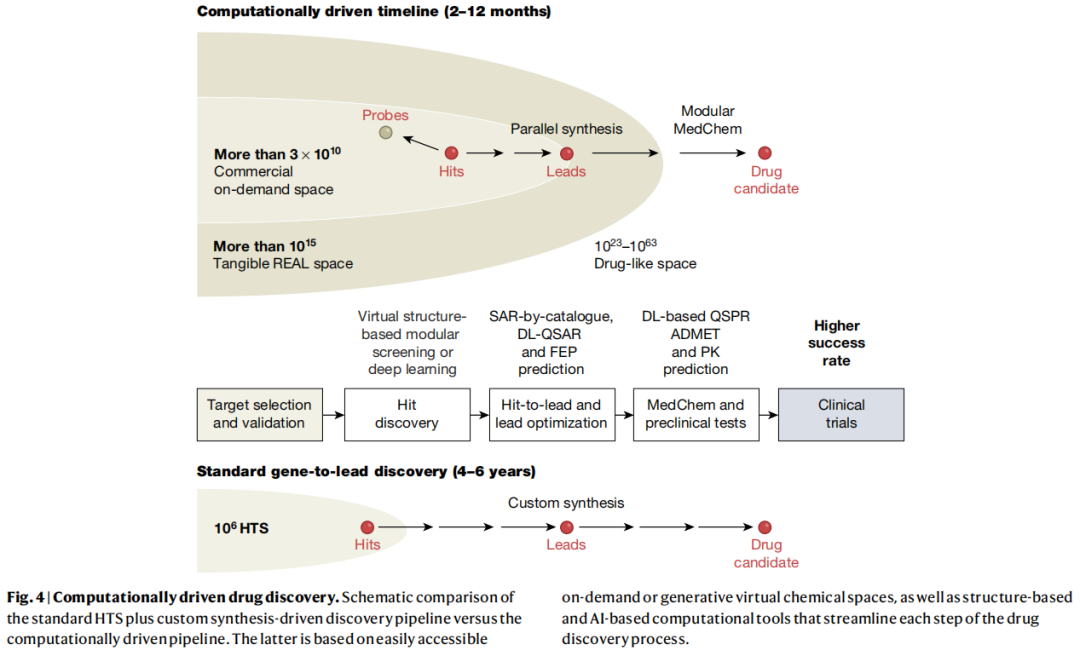
6.3 计算驱动管线的愿景
传统的"基因到先导化合物"流程耗时4–6年,而计算驱动的管线有望压缩至2–12个月。文章引用了两个标志性案例:
- • 从靶标到先导化合物仅需21天(Insilico Medicine, DDR1激酶抑制剂)
- • 从靶标到IND申请仅10个月,仅合成78个分子(Schrödinger, MALT1抑制剂SGR-1505)
6.4 不可回避的局限
文章始终保持清醒的态度,明确指出:
- • 最佳虚拟筛选的实验验证率为10–40%,多数预测并不正确。
- • 最佳亲和力预测的RMSE难以低于1 kcal/mol。
- • ADMET和PK性质的计算预测同样存在类似局限。
- • 计算预测始终需要实验验证——但实验数据反馈回模型训练也构成了持续改进的正向循环。
文章对"消除动物实验"持审慎乐观态度:随着更准确的体外检测技术(CACO-2、MDCK、器官芯片、功能性类器官)提供更好的ADMET/PK估算,结合不断改进的计算模型,有望逐步减少乃至最终取代动物实验——美国FDA已释放了这一方向的信号。
七、总结
这篇综述的核心价值
维度 | 评价 |
|---|---|
系统性 | 从化学空间、到筛选算法、到AI/DL、到混合方法、到实战案例,构建了完整的技术图谱 |
客观性 | 既展示令人振奋的进展,也诚恳剖析AI过拟合、PDBbind局限、AlphaFold2对接失败等核心挑战 |
实用性 | Table 1(实验vs计算方法)和Table 2(虚拟筛选算法全景)可直接作为技术选型参考 |
前瞻性 | 提出"computer-driven drug discovery"的生态系统构想,超越了单一技术的讨论 |
可读性 | 以SARS-CoV-2 Mᵖʳᵒ为贯穿案例,将方法论讨论锚定在具体的药物发现场景中 |
写在最后
这篇综述不会给你一个简单的答案,但它会帮你建立起关于"计算如何改变药物发现"的最完整认知框架。在AI制药泡沫与实质并存的今天,这种冷静而全面的视角尤为珍贵。
本文为服务AIDD中文社区整理,所有学术成果归原作者所有。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-13,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号