AI论文速读 | Timer-S1:具有串行扩展能力的十亿级时间序列基础模型

AI论文速读 | Timer-S1:具有串行扩展能力的十亿级时间序列基础模型

时空探索之旅
发布于 2026-04-02 12:24:08
发布于 2026-04-02 12:24:08
论文标题:Timer-S1: A Billion-Scale Time Series Foundation Model with Serial Scaling
作者: Yong Liu(刘雍), Xingjian Su(苏行健), Shiyu Wang(王世宇), Haoran Zhang(张淏然), Haixuan Liu(刘海昡), Yuxuan Wang(王雨轩), Zhou Ye(叶舟), Yang Xiang(向阳), Jianmin Wang(王建民), Mingsheng Long(龙明盛)
机构:清华大学,字节跳动
论文链接:https://arxiv.org/abs/2603.04791
Cool Paper:https://papers.cool/arxiv/2603.04791
TL;DR:清华与字节跳动联合提出 83 亿参数量的时间序列基础模型 Timer-S1,以串行缩放突破现有模型扩展瓶颈,融合 TimeMoE 和 TimeSTP 模块实现串行预测,基于万亿级 TimeBench 数据集训练并结合多阶段后训练优化。
关键词:时间序列预测、MoE,时序基础模型,Serial-Token Prediction

点击文末阅读原文跳转本文arXiv链接
摘要
本文提出了Timer‑S1,这是一种高性能混合专家(MoE)时间序列基础模型,总参数量达83亿,每个token的激活参数量为7.5亿,上下文长度为11500。为解决现有预训练时间序列基础模型在可扩展性上的瓶颈,我们从模型架构、数据集与训练流程三个维度实施串行扩展策略。Timer‑S1融合了稀疏TimeMoE模块与通用TimeSTP模块,以实现串行token预测(STP)——一种贴合时序预测串行特性的通用训练目标。该范式引入串行计算以提升长期预测效果,同时避免了标准下一个token预测中开销高昂的滚动式推理与显著的误差累积问题。为构建高质量、无偏的训练数据集,我们构建了包含一万亿个时间点的数据集TimeBench,并通过精细的数据增强手段降低预测偏差。我们还创新性地引入了后训练阶段,包括持续预训练与长上下文扩展,以提升模型在短期预测与长上下文场景下的性能。在大规模评测基准GIFT‑Eval上的实验结果表明,Timer‑S1取得了当前最优的预测效果,作为预训练模型斩获了最优的MASE与CRPS指标。Timer‑S1将正式开源,以助力相关领域的后续研究工作。
Q: 这篇论文试图解决什么问题?
A:这篇论文致力于解决时间序列基础模型(Time Series Foundation Models, TSFMs)的可扩展性瓶颈(scalability bottleneck)问题,具体体现在以下几个核心挑战:
1. 模型规模与预测性能的限制
现有预训练时间序列基础模型(如Timer、Timer-XL、Timer-3等)主要在有限的模型规模(limited model sizes)内运行,难以通过简单的参数扩展获得显著的性能提升。论文指出,现有架构在扩展到十亿参数级别时面临优化困难,无法充分利用大规模预训练带来的优势。
2. 时间序列预测的串行本质与计算效率的矛盾
时间序列预测是一个固有的串行问题(inherently serial problem):
- 并行预测(Parallel Forecasting) 虽然计算高效,但缺乏对长期依赖的逐步推理能力,无法通过足够的串行计算来可靠地捕捉循环依赖。
- 自回归预测(Autoregressive Forecasting) 虽然符合串行本质,但需要"滚动式"(rolling-style)迭代推理,导致计算开销巨大和严重的错误累积(error accumulation),特别是在长期预测中。
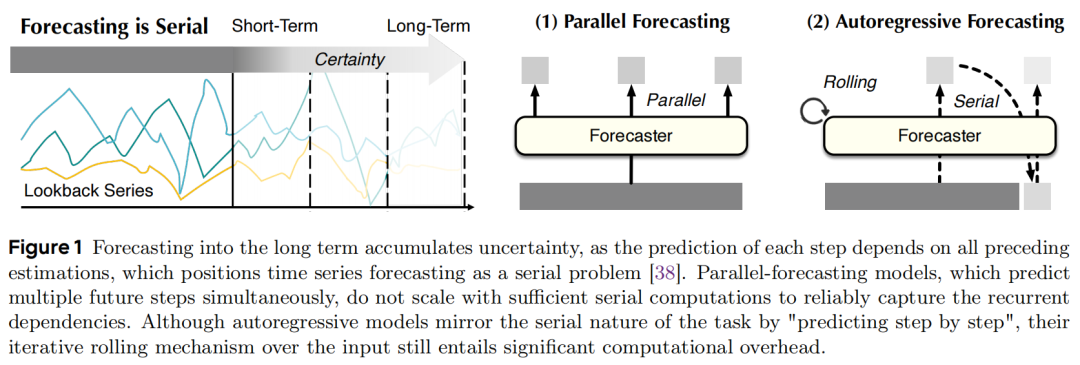
3. 数据异质性与训练偏差
时间序列数据具有显著的分布异质性(distributional heterogeneity)、频率多样性和非平稳性(non-stationarity)。现有模型在处理跨领域数据时面临挑战,且训练数据的不平衡分布会导致预测偏差(predictive bias),例如模型倾向于捕捉特定的方向性趋势或在特定频率上表现不佳。
4. 短长期预测任务的优化冲突
短期预测和长期预测具有不同的优化目标和学习难度。单阶段预训练难以同时优化这两种能力,因为:
- 长期预测依赖于短期预测的准确性(逐步推理)
- 但统一的数据集和训练目标可能忽视这种任务差异,导致训练困难
解决方案概述
针对上述问题,论文提出了Timer-S1模型,通过三维串行扩展(Serial Scaling)策略:
- 架构维度:提出Serial-Token Prediction (STP) 机制,通过TimeSTP块引入渐进式串行计算,在单次前向传播中生成多步预测,避免滚动推理。
- 数据维度:构建TimeBench(一万亿时间点的高质量语料库),并采用重采样(Resampling)和数值翻转(Value-Flipping)等数据增强技术消除预测偏差。
- 训练维度:设计多阶段训练流程(预训练+持续预训练+长上下文扩展),分别优化表示学习、短期预测精度和长上下文处理能力。
该模型在GIFT-Eval基准测试中取得了最先进的性能(MASE: 0.693, CRPS: 0.485),验证了其在通用预测(General Forecasting)任务上的能力。
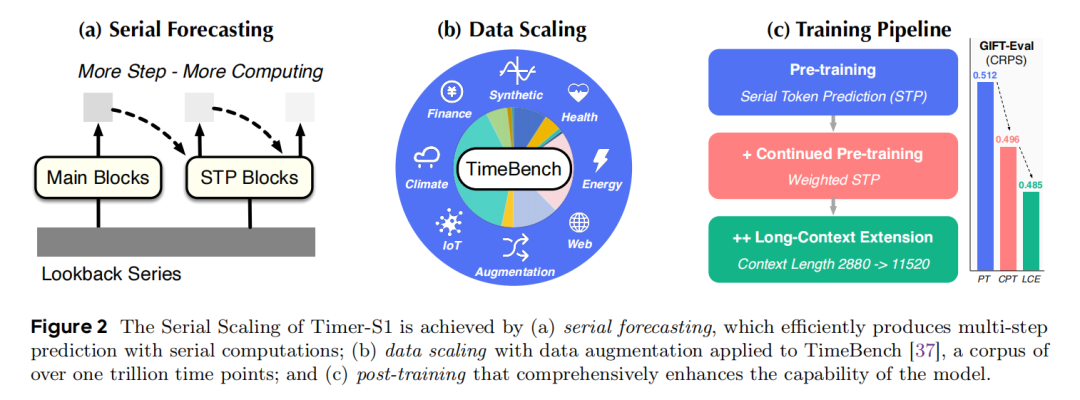
论文的核心目标:有效扩展时间序列基础模型,该模型在显著提升预测性能的同时降低推断成本。(原文:effectively scaling a time series foundation model that delivers substantially stronger forecasting performance while reducing inference cost)
Q: 有哪些相关研究?
A: 与Timer-S1相关的研究可归纳为以下几个主要方向:
1. 时间序列预测的方法演进
该领域经历了从经典统计方法到现代基础模型的范式转变:
- 统计方法:包括ARIMA、Exponential Smoothing等 [8],为时间序列分析奠定理论基础,但在复杂非线性模式上表现受限。
- 机器学习方法:如SVR、基于树的模型等 [25],增强了数据驱动的鲁棒性。
- 深度学习方法:TCNs、RNNs、Transformers等 [29, 53, 54],利用强大的特征提取和序列建模能力,但通常针对特定任务从头训练,泛化能力有限。
2. 时间序列基础模型(Time Series Foundation Models, TSFMs)
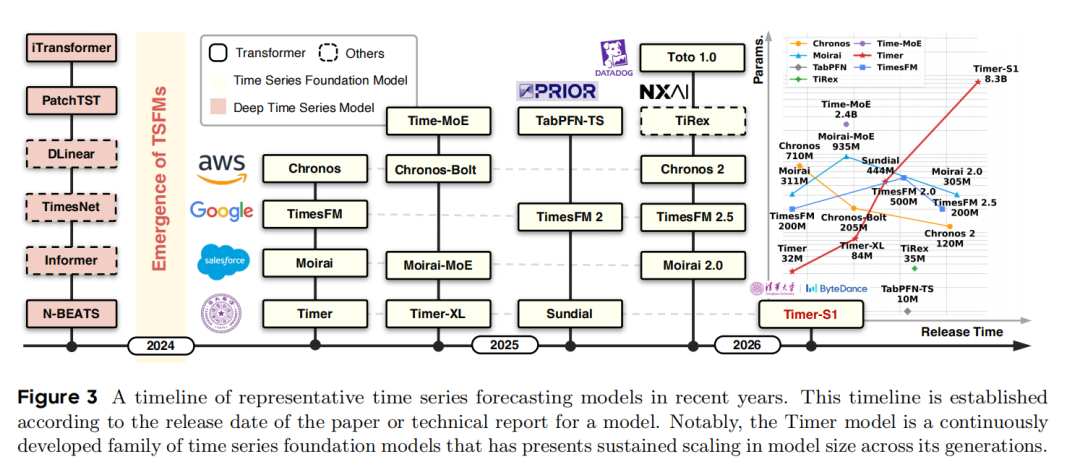
这是与Timer-S1最直接相关的研究方向,旨在通过大规模预训练实现"一次训练,随处应用":
模型 | 核心特点 | 与Timer-S1的关系 |
|---|---|---|
Timer系列 | Timer(基于decoder-only Transformer和next-patch预测)、Timer-XL(长上下文自注意力)、Timer-3/Sundial(流匹配生成式预测) | Timer-S1的直接前身,继承了其单序列归一化和patch嵌入策略,但突破了规模瓶颈 |
Chronos/Chronos-2 | 基于T5架构的编码器-解码器模型,采用分词器将时间序列映射为离散token | Timer-S1在GIFT-Eval上与其竞争,但采用连续值表示而非离散分词 |
TimesFM | 仅解码器架构,采用patch-wise训练和解码器注意力掩码 | 与Timer-S1共享类似的仅解码器理念,但Timer-S1引入MoE和串行预测机制 |
Moirai系列 | 基于掩码自编码器(MAE)和任意变量注意力,Moirai-MoE探索了MoE架构 | Moirai-MoE 也尝试MoE扩展,但Timer-S1通过Serial-Token Prediction解决了其扩展性瓶颈 |
其他TSFMs | TiRex (上下文学习增强)、Toto (可观测性优化)、TabPFN-TS、Migas-1.0、Time-MoE等 | Timer-S1在GIFT-Eval基准上与这些模型进行零样本性能比较 |
3. 模型架构关键技术
Timer-S1整合了多项在NLP和TSFM中验证的架构创新:
- Mixture-of-Experts (MoE) :稀疏激活的专家混合架构,用于处理时间序列数据的异质性。相关工作包括Moirai-MoE 和Time-MoE,但Timer-S1首次将其扩展到83亿参数规模。
- 多Token预测(Multi-Token Prediction, MTP) :在LLM中用于加速训练的技术,被TimesFM和Sundial引入时间序列领域。Timer-S1提出的Serial-Token Prediction (STP)区别于标准MTP,通过保留串行计算块并避免训练-测试差距来改进长期预测。
- 位置编码与归一化:采用RoPE(旋转位置编码)实现上下文长度扩展,QK-Norm稳定注意力分数,Pre-RMSNorm提升训练稳定性。
4. 数据治理与训练策略
- 数据增强:KernelSynth用于合成数据生成;Timer-S1特有的重采样(Resampling)和数值翻转(Value-Flipping)技术用于缓解预测偏差。
- 预训练范式:包括数据标准化 、训练目标设计和损失函数。Timer-S1创新性地提出多阶段训练(预训练+持续预训练+长上下文扩展),区别于单一阶段预训练。
- 评估基准:GIFT-Eval作为大规模通用评估基准,包含144,000个时间序列,Timer-S1在此基准上达到SOTA。
5. 理论基础
- 串行假设(Serial Scaling Hypothesis):理论论证了时间序列预测作为串行问题的本质,为Timer-S1的架构设计提供了理论依据。
- 非平稳性处理:针对时间序列的非平稳和随机特性,Timer-S1采用实例归一化(Instance Normalization)和分块嵌入来应对。
这些相关工作共同构成了Timer-S1的技术背景,而Timer-S1的核心贡献在于通过Serial Scaling(串行扩展)策略,首次成功将时间序列基础模型扩展到十亿参数级别,同时解决了长期预测中的错误累积和计算效率问题。
Q: 论文如何解决这个问题?
论文通过Timer-S1模型提出三维串行扩展(Serial Scaling)策略,从架构设计、数据治理和训练流程三个维度系统性地解决了时间序列基础模型的可扩展性瓶颈。具体解决方案如下:
1. 架构维度:Serial-Token Prediction (STP) 机制
Timer-S1的架构围绕时间序列串行预测本质设计,整体包含归一化与嵌入、Transformer主干、预测头三大核心模块,以TimeMoE块为基础串联TimeSTP块实现STP机制,具体如下:
1. 归一化和嵌入
针对时间序列跨域尺度差异、多元语义干扰问题,采用实例重归一化+patch级token嵌入,聚焦单变量时序模式学习,为后续计算奠定统一表征基础。
实例重归一化:对单变量时间序列 计算均值 、方差 ,归一化得 ;预测输出通过 还原原始尺度,让模型聚焦局部时序规律。
patch嵌入:将归一化序列划分为长度为 的patch,非整除时左填充并生成二进制掩码 ,通过残差网络实现嵌入:
其中 为初始嵌入, 为Transformer隐藏维度。
2. Transformer主干
采用Decoder-only Transformer架构,由堆叠的TimeMoE块(主块)+串联的 个TimeSTP块构成,是STP机制的核心载体,解决了传统自回归误差累积、多token预测缺乏串行计算的问题。
unsetunset(1)TimeMoE块:稀疏混合专家的上下文表征unsetunset
基于稀疏Mixture-of-Experts适配时序数据异质性,单块含多头注意力(MHA)+MoE模块,加入Pre-RMSNorm、QK-Norm提升训练稳定性,核心公式如下:
- 前向计算:
- QK-Norm:缓解softmax分数饱和问题
- 因果自注意力:结合RoPE编码相对位置 其中,为旋转矩阵,其旋转角度由决定;表示基于token的注意力评分;为三角因果掩码; 为可学习的标量参数。
- MoE模块:稀疏配置 、 ,通过分配专家, 是第个专家的门控值 加入辅助损失 实现专家负载均衡 其中和分别表示分配给专家的token比例及分配给该专家的路由器概率比例,而表示指示函数。
- NTP(next-token prediction)目标:经 个TimeMoE块后,进行下一patch预测,同时损失函数进行约束:
unsetunset(2)TimeSTP块:渐进式串行计算的多步预测unsetunset
串联在TimeMoE块后,针对时间序列预测的串行本质(即长期预测依赖逐步推理,但传统自回归存在错误累积和计算开销),论文提出了一种新的预测范式:每个块融合前一模块输出与初始嵌入,实现“预测步数越多,计算深度越深”:
- 信息融合:接收前一块(block)嵌入 与初始嵌入 ,经投影层融合: 其中 为一个投影层和一个TimeMoE块
- 前向处理:融合后嵌入经TimeMoE模块得
- STP(Serial-Token Prediction)目标:第 个块预测偏移的未来片段
与现有方法的区别:
- 对比Next-Token Prediction (NTP):避免滚动式自回归(rolling autoregression)导致的错误累积和推理延迟
- 对比Multi-Token Prediction (MTP):不直接并行输出所有未来token,而是通过渐进式串行计算(progressive serial computations)建模长期依赖,符合"预测步数越多,计算深度越深"的直觉
3. 预测头
采用共享分位数预测头 ,适配GIFT-Eval测评的概率预测需求,支持分位数输出并通过加权分位数损失逼近CRPS指标,核心公式如下:
- 分位数输出:生成 个分位数预测 ,经实例重归一化的逆操作还原尺度,采用 的分位数集。
- 训练损失:以加权分位数损失(wQL)为核心,作为CRPS的近似; 其中 为pinball损失,根据 与 的大小关系分别计算 或 。
- 设计优势:patch嵌入与投影层在TimeMoE、TimeSTP块间共享,保证token嵌入到时序patch的转换一致性,通过密集监督提升参数效率,且架构兼容线性投影、扩散基头等其他预测头类型。
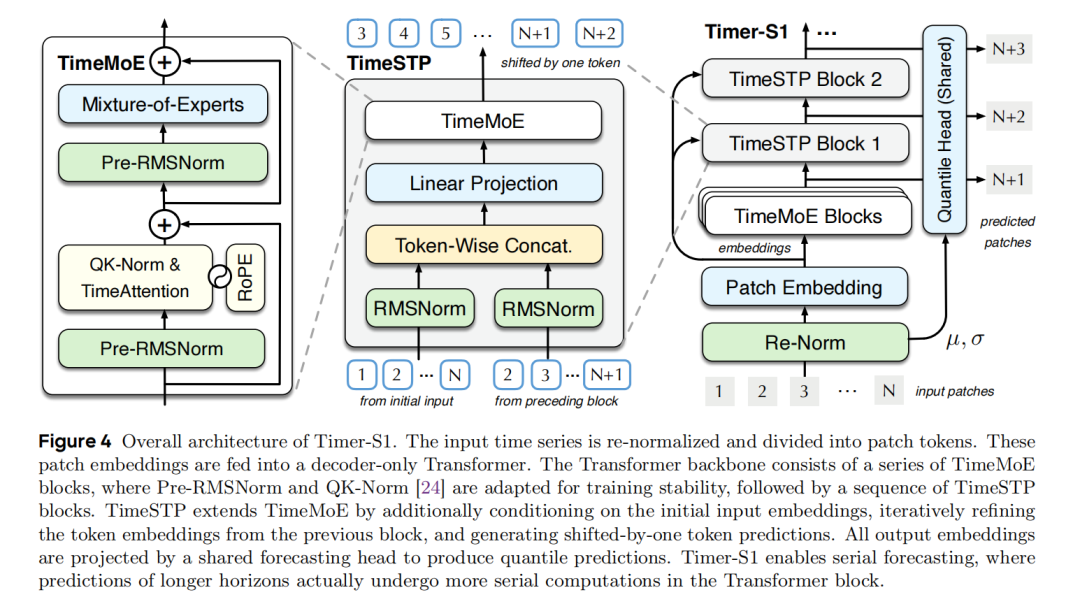
Timer-S1
Timer-S1
2. 数据维度:TimeBench语料库与偏差消除
TimeBench数据集构建:
- 规模:整合超过一万亿(1 trillion)个时间点,涵盖金融、物联网、气象、医疗等多领域真实数据,以及KernelSynth合成的时序因果模型数据
- 质量控制:
- 通过ADF检验(平稳性)和基于谱熵的可预测性度量筛选高质量变量
- 因果均值插补、基于和IQR的异常值剔除
- 移除与GIFT-Eval测试集潜在重叠的样本,防止数据泄漏
数据增强策略(解决预测偏差):
- 重采样(Resampling):通过降采样和基于傅里叶基的插值改变采样率,增强对不同时间分辨率的鲁棒性,避免模型过度拟合特定频率
- 数值翻转(Value-Flipping):将输入和输出序列乘以−1,逆转趋势方向,消除模型对特定方向性趋势的偏好(directional bias)
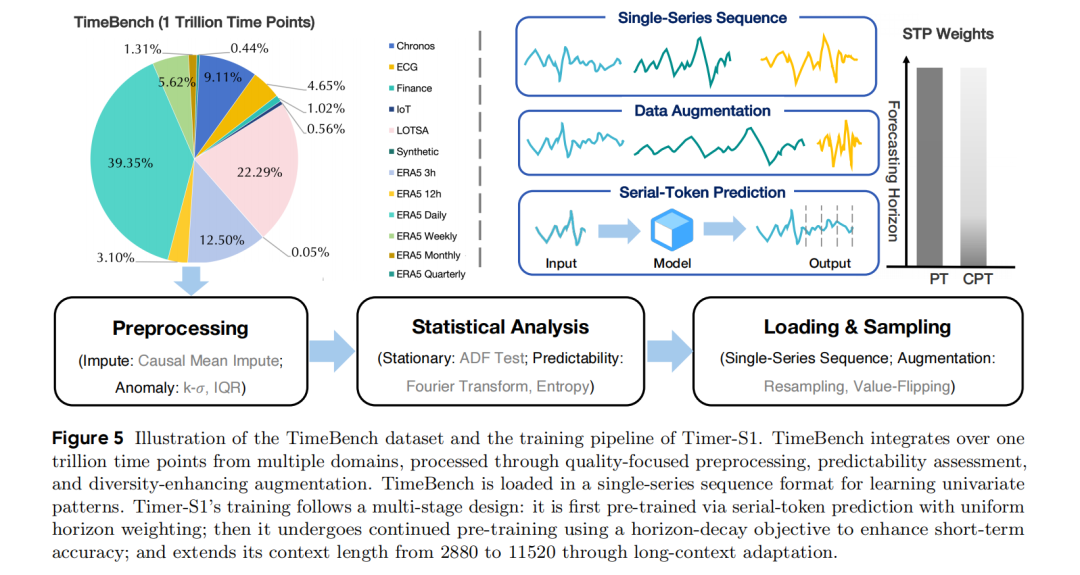
3. 训练流程维度:多阶段解耦训练
将训练流程解耦为三个阶段,针对不同能力进行优化:
预训练(Pre-Training)
- 目标:联合优化Next-Token Prediction (NTP)和Serial-Token Prediction (STP)
- 策略:对所有预测长度(horizons)赋予相等权重,构建密集的预测任务集(任意长度作为输入/输出)
- 目的:充分训练TimeMoE(上下文表示)和TimeSTP(多步预测)模块,最大化样本效率
后训练
加权STP预测(Weighted Serial-Token Prediction)
在Timer-S1模型中,每个TimeSTP模块专门用于特定预测周期。虽然STP模块旨在提升长期预测性能,但作为长期预测初始阶段的短期预测仍需进一步优化。为此,采用加权序列标记预测(wSTP)损失函数进行持续预训练,该方法优先学习浅层STP模块。
对浅层 TimeSTP 块(短期预测)赋予更高权重,权重随预测长度按衰减(为块深度)。
持续预训练(Continued Pre-Training, CPT)
- 针对性:专门提升短期预测性能(短期精度是长期预测的基础)
- 数据重访机制:混合GIFT-Eval预训练数据和TimeBench采样,防止对特定分布的过拟合
长上下文扩展(Long-Context Extension, LCE)
- 技术:基于RoPE(旋转位置编码)将上下文长度从2,880扩展到11,520
- 收益:为模型提供更丰富的历史信息,提升长期预测精度
训练基础设施
Timer-S1的训练由字节跳动的VeOmni框架支撑,可实现模型跨多设备扩展至十亿级参数量;采用BF16精度保障效率,TimeBench原始数据转换为约4TB的Parquet压缩文件。为解决内存滑动窗口采样的数据膨胀问题,采用混合内存-磁盘加载策略,将数据集划分为50MB分片,通过内存队列管理活跃分片,平衡I/O并发与采样随机性。
Q: 论文做了哪些实验?
A: 论文在第5节(Experiments)中开展系统实证研究,主要分为基准测试性能评估、扩展性分析、消融研究三类实验,各实验现象及对应图表如下:
(1)基准测试性能评估
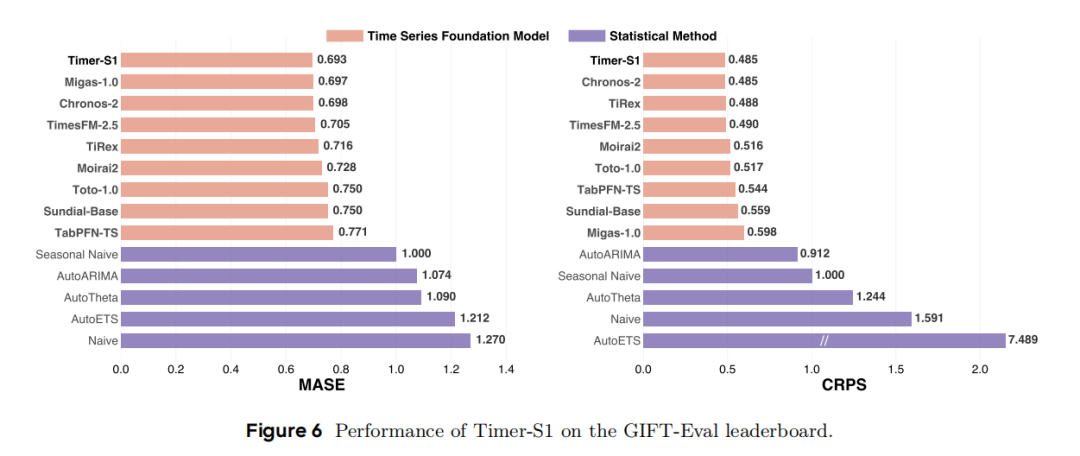
- GIFT-Eval整体性能(图6):以点预测和概率预测相关指标为评估标准,将Timer-S1与多种统计方法、先进时间序列基础模型进行对比,可见Timer-S1在两类指标上均表现最优,达到当前最优水平。
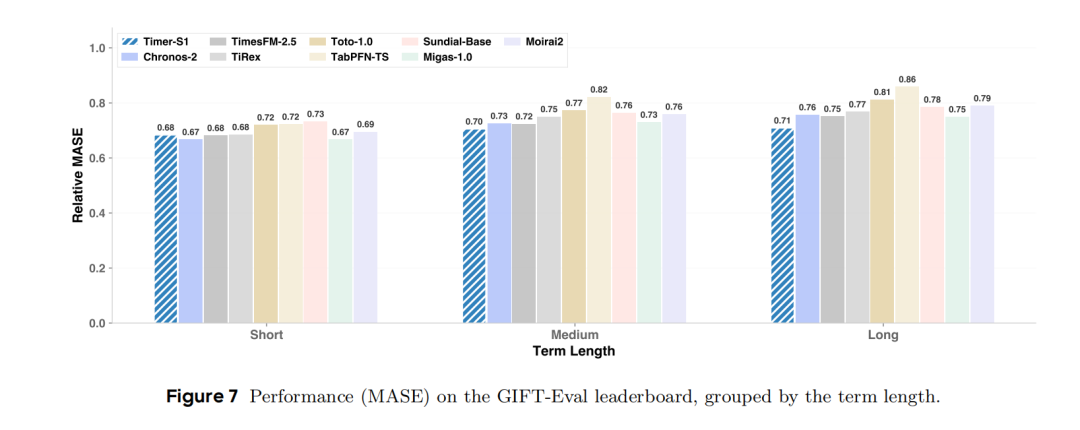
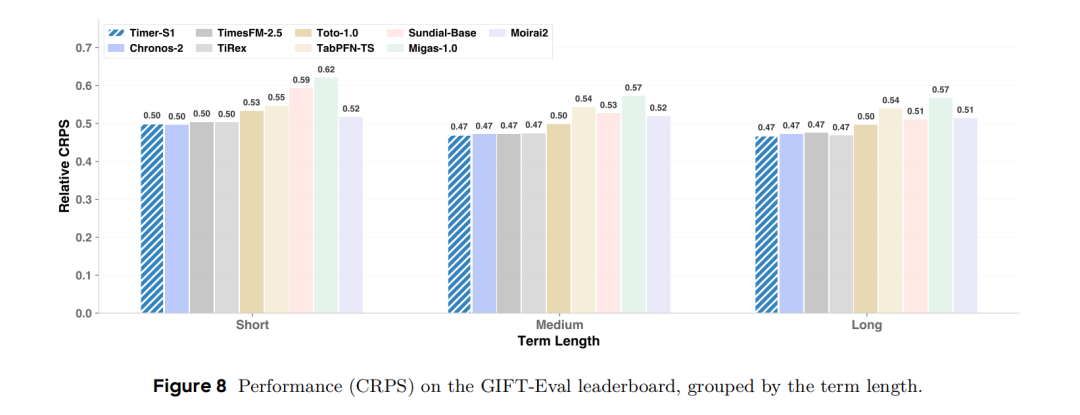
- 按预测长度分组分析(图7、图8):将GIFT-Eval任务按短期、中期、长期划分,对比不同模型在各组任务中的表现,可见Timer-S1在中期和长期任务上的优势最为突出,印证了其串行预测机制在长程依赖建模上的有效性。
- 后训练阶段消融(图9):依次测试基础预训练、加入持续预训练、再加入长上下文扩展三个阶段的模型表现,可见随着训练阶段的逐步完善,模型性能持续提升,体现了多阶段训练流程的价值。

(2)扩展性分析
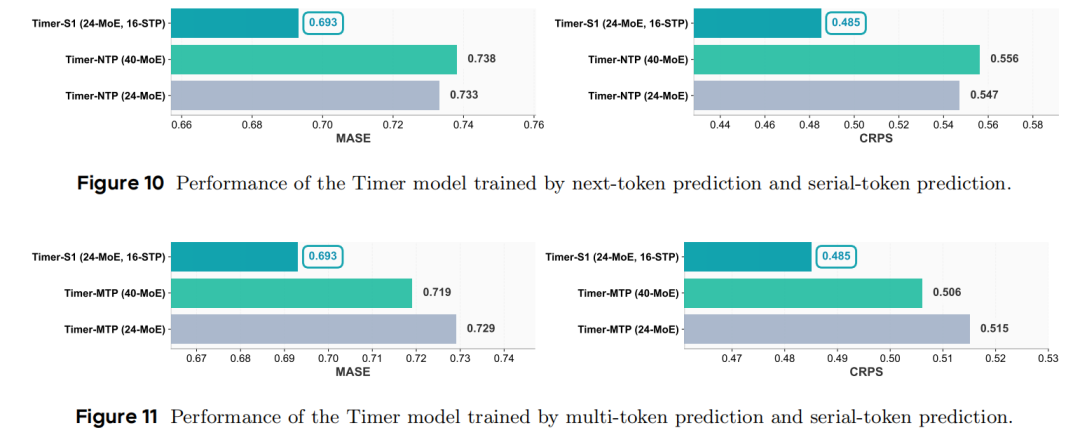
- 训练目标对比实验(图10,图11):设置不同训练目标(串行预测、纯自回归、多token并行预测),且保证参数量相当以实现公平对比,可见采用串行预测目标的模型表现最优,纯自回归模型误差累积明显,并行预测模型因缺乏串行计算而表现较差。
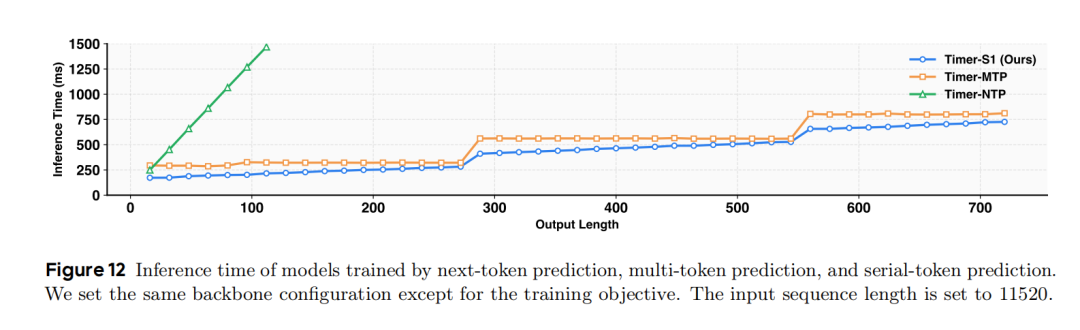
- 推理效率分析(图12):在固定输入长度下,对比不同训练目标模型的推理延迟,可见Timer-S1的推理延迟随输出长度线性增长且增长幅度最小,纯自回归模型延迟最高,多token并行预测模型存在较高计算开销。
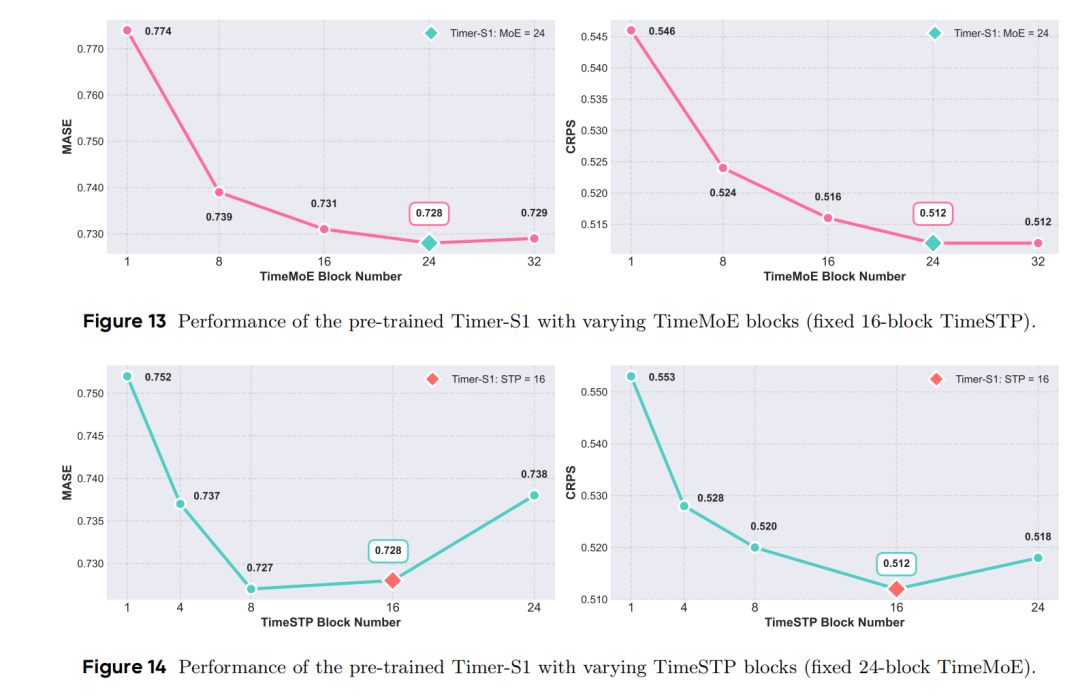
- 模型规模扩展实验(图13、图14):分别调整TimeMoE块和TimeSTP块的数量,观察模型性能变化,可见TimeMoE块数量增加时性能持续提升,达到一定数量后趋于稳定;TimeSTP块数量增加至一定值时性能最佳,过多则会因优化难度增加导致性能轻微下降。
(3)消融实验
- TimeSTP架构设计验证(图15):设计两种变体模型与原模型对比,一种在训练时引入未来输入偏移嵌入、测试时移除辅助块,另一种训练后丢弃STP块改用滚动自回归,可见两种变体模型的性能均明显劣于原模型,验证了原架构设计中保留STP块用于推理、避免训练时使用未来信息的必要性。

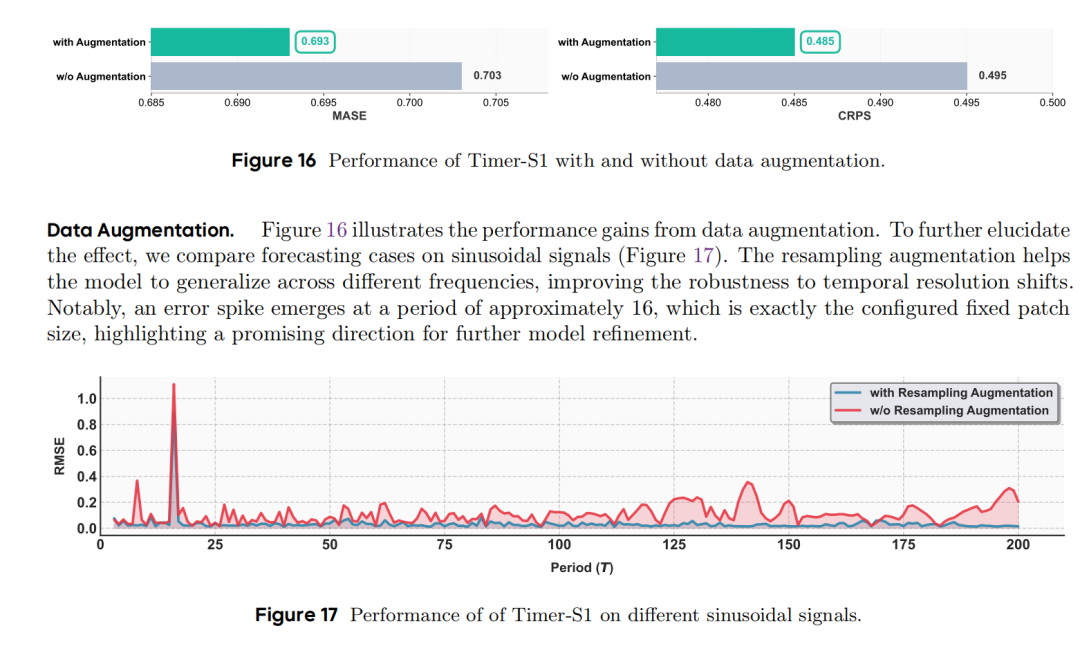
- 数据增强效果(图16、图17):对比有无数据增强的模型表现,可见加入数据增强后模型性能更优;在正弦信号频率鲁棒性测试中,无重采样增强的模型在特定频率处出现明显误差峰值,而有增强的模型误差曲线更平滑,证明数据增强可有效缓解模型对特定频率的过拟合。
- 预训练迁移能力(图18):对比从头训练与预训练+微调的模型表现,可见经过TimeBench数据集预训练后再微调的模型性能显著更优,证明预训练可有效提升模型的跨域泛化能力,且能适配不同格式的下游任务。

综上,实验现象均印证了Timer-S1模型串行预测机制、三维扩展策略及各核心架构设计的有效性,各模块协同作用实现了模型性能与效率的优化。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-12,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号