SAM3| 文本+视觉概念 提示 分割一切

SAM3| 文本+视觉概念 提示 分割一切

OpenCV学堂
发布于 2026-04-02 21:24:52
发布于 2026-04-02 21:24:52
SAM3 (Segment Anything Model 3) 是 Meta 用于可提示概念分割(PCS)的下一代基础模型。在SAM 2 的基础上,SAM 3 引入了一项全新功能:检测、分割和跟踪由文本提示、图像示例或两者指定的视觉概念的所有实例。
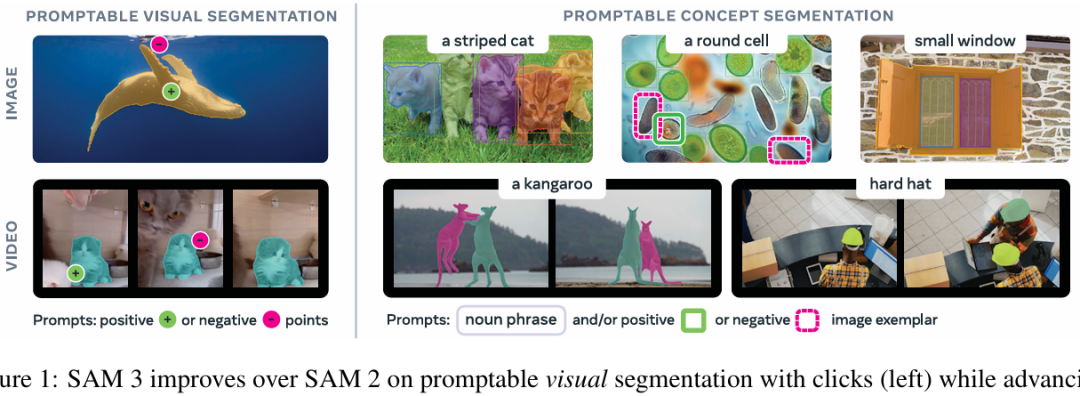
以前的SAM 版本会根据提示分割单个对象,而SAM 3 则不同,它可以找到并分割出现在图像或视频中任何地方的每一个概念,从而与现代实例分割的开放词汇目标保持一致。

概述
与现有系统相比,SAM 3 在可提示概念分割方面的性能提高了 2 倍,同时保持并改进了SAM 2 的交互式视觉分割功能。该模型擅长开放式词汇分割,允许用户使用简单的名词短语(如 "黄色校车"、"条纹猫")或通过提供目标对象的示例图像来指定概念。这些功能对依赖于简化的预测和跟踪工作流的生产就绪流水线起到了补充作用。
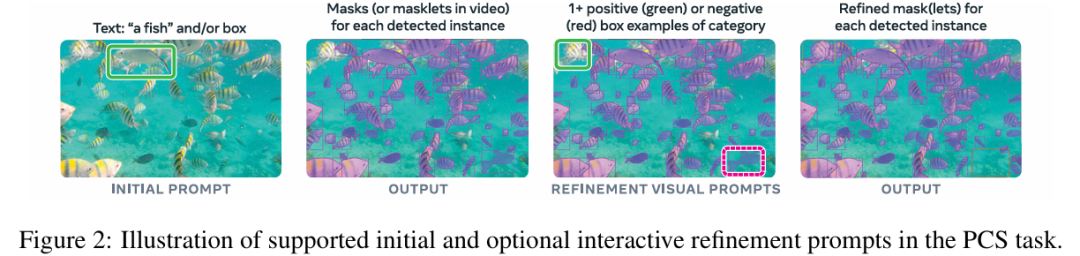
什么是 Promptable Concept Segmentation(PCS)?
PCS 任务将概念提示作为输入,并为所有匹配对象实例返回带有唯一标识的分割掩码。概念提示可以是
文本:简单的名词短语,如 "红苹果 "或 "戴帽子的人",类似于零起点学习
图像示例:围绕示例对象(正片或负片)的边界框,实现快速归纳
结合:将文本和图像示例结合在一起,实现精确控制这有别于传统的视觉提示(点、方框、遮罩),后者只对单个特定对象实例进行分割,这在最初的SAM 系列中得到了推广
关键指标

架构
SAM 3 由检测器和跟踪器组成,它们共享一个感知编码器(PE)视觉主干网。这种解耦设计可避免任务冲突,同时实现图像级检测和视频级跟踪,其界面与Ultralytics Python 和CLI 使用兼容。

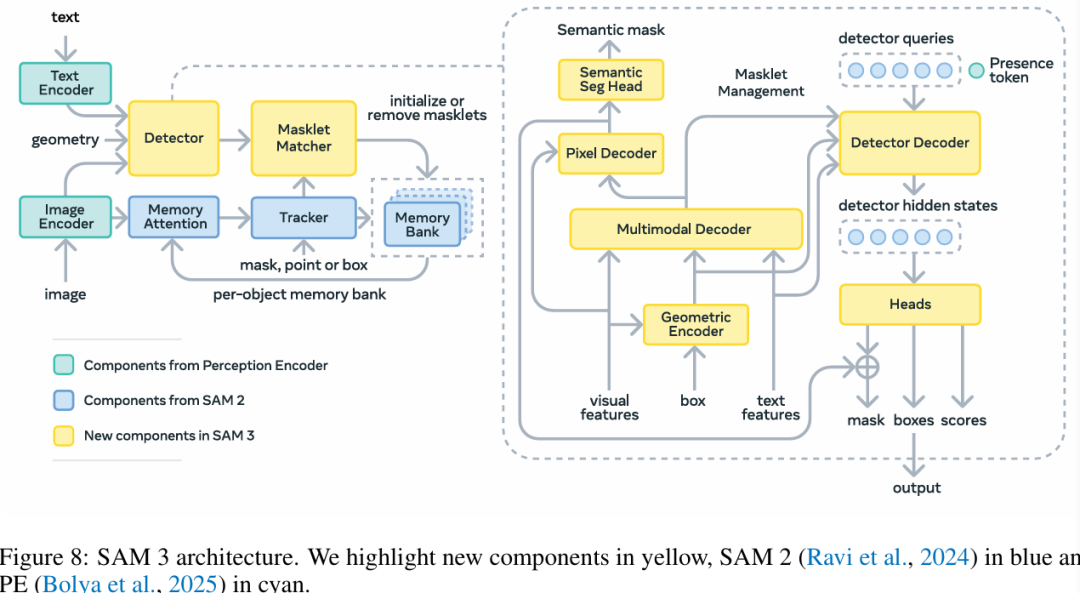
核心组件
探测器 基于 DETR 的图像级概念检测架构
用于名词短语提示的文本编码器
基于图像提示的示例编码器
融合编码器根据提示调节图像特征
将识别("是什么")与定位("在哪里")分离开来的新型存在头
用于生成实例分割掩码的掩码头跟踪器继承自SAM 2的基于内存的视频分割功能
提示编码器、掩码解码器、内存编码器
用于跨帧存储对象外观的存储库
在多对象环境中利用卡尔曼滤波器等技术辅助进行时空消歧存在标记:学习到的全局标记,可预测目标概念是否出现在图像/帧中,通过将识别与定位分离来改进检测。
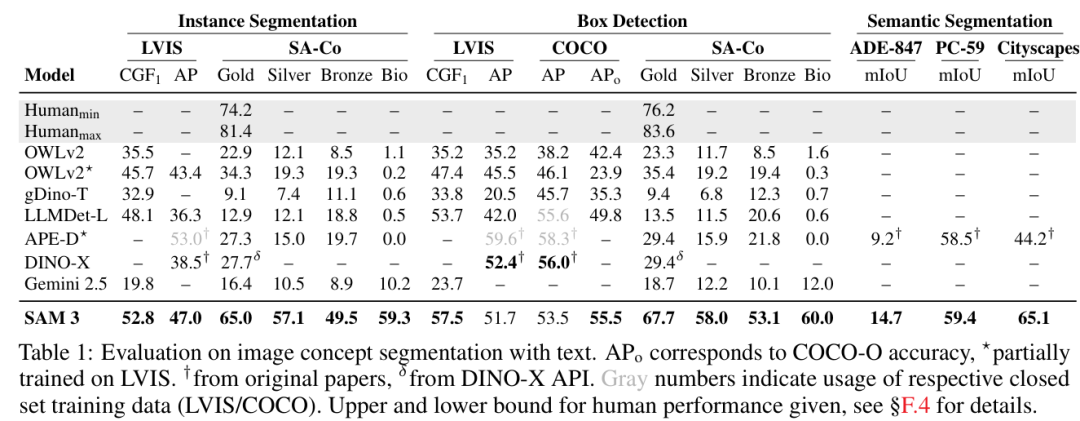
性能与对比
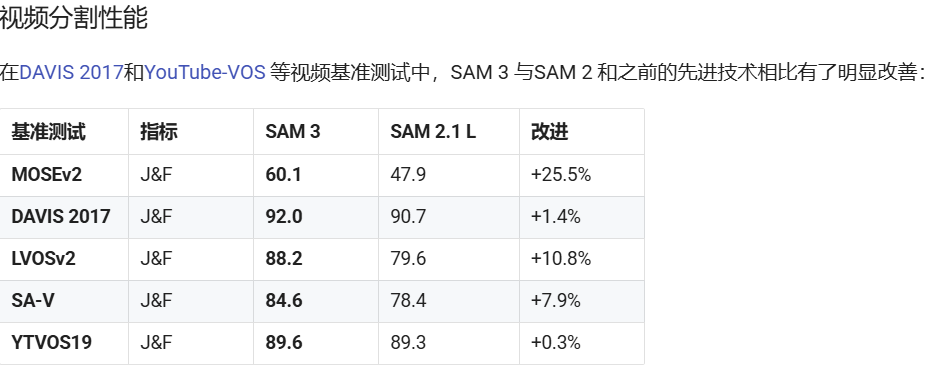
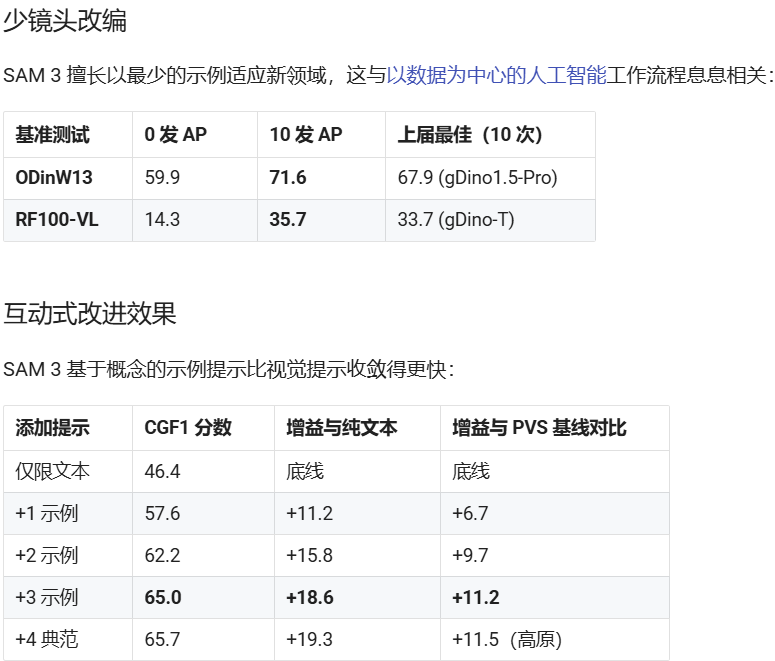
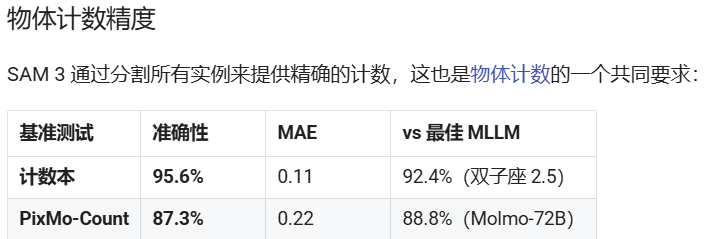
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-10-15,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号