Figure AI 公司及其人形机器人概览

Figure AI 公司及其人形机器人概览

霞姐聊IT
发布于 2026-04-28 12:22:26
发布于 2026-04-28 12:22:26
Figure AI是一家美国的人形机器人公司,成立于2022年,总部在加州,由连续创业者Brett Adcock创立,员工约百人级别。
Figure AI的投资方包括OpenAI、Microsoft、NVIDIA、Jeff Bezos、亚马逊、英特尔等巨头,2025年估值已达到约390亿美元。
这个估值已经在AI创业公司的第一梯队了:
公司 | 类型 | 市值/估值(美元) | 员工规模(约) |
|---|---|---|---|
OpenAI | 大模型 | $80B–$120B | ~4,500–7,000+ |
Anthropic | 大模型 | $20B–$40B | ~2,500 |
xAI | 大模型 | $50B–$80B | ~1,200+ |
FigureAI | 具身智能 | ~$39B | ~180 |
优必选(UBTECH) | 人形机器人 | $7B–$9B | ~2,500+ |
银河通用 | 机器人 | ~$3B | 估计数百人级 |
智元(AgiBot) | 人形机器人 | $2B–$3B | 估计数百人级 |
宇树(Unitree) | 机器人 | $1.5B–$2B | ~500 |
Figure AI的核心方向是通用人形机器人+具身智能(EmbodiedAI),有三款产品:Figure 01、02、03人形机器人。
这三代人形机器人的演进,体现了从“能动”到“能干活”,再到“具备通用智能”的能力跃迁。
Figure 01于2023年3月首次发布,主要作为原型验证平台,具备基本的双足行走和简单抓取能力,用于证明AI与机器人结合的可行性。
到了2024年推出的Figure 02,已经进入工业测试阶段,具备更成熟的视觉系统和五指灵巧手,并在宝马工厂中进行实际任务测试,实现了较为稳定的搬运和分拣等工作,标志着机器人开始具备实用价值。
而在2025年10月发布的Figure 03,则是面向通用场景和规模化应用的产品,不仅在感知、触觉和运动控制上大幅升级,还针对Helix具身智能模型进行了深度优化,使机器人在复杂环境中的理解与操作能力进一步提升。
整体来看,这三代产品清晰地展示了Figure从技术验证走向实际应用,再迈向通用智能系统的战略路径。
这三代机器人的更具体信息可参照下图:

二、一、Figure 03商业化现状
截至目前,Figure 03尚未面向普通消费者开放公开售卖,并未进入成熟市场化零售阶段。产品整体仍处于从技术验证走向规模化商业部署的过渡期,并已于2026年初逐步开启产业场景落地应用。
根据公开信息,Figure 03现已完成量产投产,并且已经向宝马、亚马逊在内的工业与商业合作伙伴完成首批量产机型交付,标志着该机型正从前期试点测试,正式迈向实际商业化落地应用。
在此之前,Figure与宝马的合作主要围绕前代机型Figure 02展开,其在工厂长期实地作业、现场任务执行所积累的工况经验,也全部反哺至Figure 03的结构设计与功能迭代当中。
面向普通家庭市场以及终端个人用户的零售业务,目前仍属于Figure AI长期远期规划目标,现阶段暂无相关落地计划。
价格方面,官方并未对外公布Figure 03的正式售价。行业普遍分析认为,该机长期消费级普及目标价位在2万~3万美元;
而在量产初期,受产能规模有限、硬件成本偏高影响,早期交付机型的实际采购价格会明显高于目标区间,定价整体偏向高端工业机器人水平。
总体而言,Figure03目前更属于临近商业化的通用机器人技术平台,并非完全成熟、可面向市场大规模批量销售的量产消费产品。
三、二、Figure03技术特点
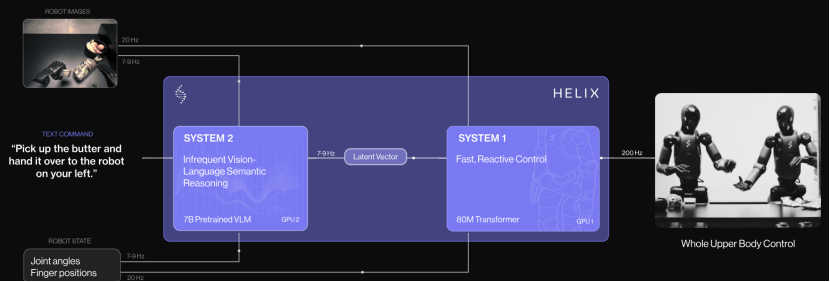
Figure 03的技术特点可以从“具身智能驱动的系统重构”角度理解。
它开始系统性地围绕Helix模型对机器人进行优化,使整体设计从“AI适配硬件”逐步转向“硬件适配AI”。
标志着Figure的技术路线从单纯的机器人迭代迈入以具身智能为核心的阶段。
Helix是Figure AI为人形机器人开发的具身智能模型,属于Vision-Language-Action(VLA)范式。
其核心在于将视觉感知、语言理解与动作执行统一到同一系统中,使机器人不仅能够“看见”和“听懂”,还可以基于理解直接生成动作。
与传统机器人将感知、决策与控制模块割裂处理不同,Helix试图将“看—想—做”整合为一个连续闭环,从而显著提升系统的灵活性与泛化能力。
在架构层面,Helix分为两个互补系统:
System2(慢思考层)负责语言理解、场景分析与任务规划,使用大型视觉语言模型;
System1(快执行层)通过视觉运动Transformer生成高频率连续动作。
两者通过潜在语义向量进行联通并联合优化,实现高层语义与低层动作控制的协同,从而在复杂环境中生成连续行为,而非依赖离散预设流程。
在训练设计上,Helix使用大约500小时的多机器人遥操作数据,并自动通过视觉语言模型生成与行为对应的自然语言指令对,用于训练深度神经网络。
这种多样化数据采集与自动标注策略既覆盖了丰富任务语义,又显著降低人工标注成本。
Helix采用端到端训练方式,无需为每个任务单独微调,通过统一的权重集合直接支持抓取、整理、分类等多种操作。
同时,训练过程中还考虑了System1与System2输入的时间偏移校准,使模型在实际部署时能够与延迟环境匹配,提升了实时控制可靠性。
尽管训练数据规模相对较小,Helix在高维连续动作空间中仍展示了强大的泛化能力,能够零样本操作未见过的物体。
Figure 03在感知、触觉和控制方面进行了系统优化:
视觉系统实现低延迟、高帧率,并在手部加入嵌入式摄像头以解决操作遮挡问题,从而提高环境感知的连续性和准确性;
指尖配备高精度触觉传感器,使机器人能够感知微小力变化,实现对物体抓取力度的精细控制;
在控制方面,Figure 03强化了全身多自由度连续动作能力,结合Helix模型能够在复杂环境中生成流畅的连续动作序列,而非依赖离散预设动作,这不仅提升了任务执行的稳定性,也为多任务迁移和泛化提供了基础。
其设计面向非结构化环境,不仅适用于工业场景,还扩展至家庭和服务应用,在安全性、灵活性与环境适应性方面进行了优化。
在具体硬件上,Figure披露,每台机器人内部配备两块低功耗嵌入式GPU,分别对应动作控制和任务理解两大模块。
虽然具体型号未公开,但业内普遍判断其基于NVIDIA嵌入式GPU平台(如Jetson或同等级产品)。
这种本地推理架构可以满足毫秒级实时控制需求,是机器人稳定执行动作的关键基础。
此外,Figure03的工程设计考虑了长时间运行、能源系统和量产架构,使其从实验性平台逐步过渡为可部署的系统。
总体来看,Figure03的核心价值不在单点技术突破,而在于围绕具身智能模型对感知、决策与动作链路进行系统级优化,体现了机器人设计从“以机械与控制为中心”向“以智能模型为中心”的范式转变,同时通过大规模多任务训练和端到端优化为未来通用机器人能力奠定基础。
四、三、总结
Figure AI 及其 Figure 03 展示了当代人形机器人技术的前沿方向:通过Helix模型实现通用智能与端到端控制,并在感知、触觉和控制方面完成系统优化。虽然目前仍处于商业化初期,但其技术路线和战略布局显示了公司在构建未来通用机器人生态中的潜力与野心。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-23,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号