Grafana 一直 No Data?我排查了 2 天,最后竟是这个原因…

Grafana 一直 No Data?我排查了 2 天,最后竟是这个原因…

一根头发丝的宽度
发布于 2026-05-06 20:35:49
发布于 2026-05-06 20:35:49

这不是一篇“照本宣科的教程”,而是我花2天踩坑的真实实验复盘。 如果你正在搭:K8s + Prometheus + Grafana + MySQL 监控,这篇内容能直接当“避坑手册”,帮你少熬2个大夜!
🧭 一、实验背景:从0搭建的监控链路,本以为是“常规操作”
我先搭好了基础环境:
- 本地虚拟化部署的Kubernetes集群(单master+多node)
- 基于Prometheus Operator部署的监控核心(含AlertManager)
- Grafana可视化面板(通过Helm一键部署)
- 以StatefulSet方式运行的MySQL 8.0集群(Headless Service暴露)
这次的目标很明确:
👉 打通 MySQL → mysqld_exporter → Prometheus → Grafana 的完整监控链路
整个链路拆解下来就5步,看上去简单到不可能出错:
MySQL(数据源)
↓
mysqld_exporter(指标采集)
↓
ServiceMonitor(Prometheus采集规则)
↓
Prometheus(指标存储)
↓
Grafana Dashboard(可视化展示)
但现实给了我一记重拳:
❌ 一路No Data、一路报错、一路怀疑人生
🚨 二、问题起点:最崩溃的“明明有数据,却啥也看不到”
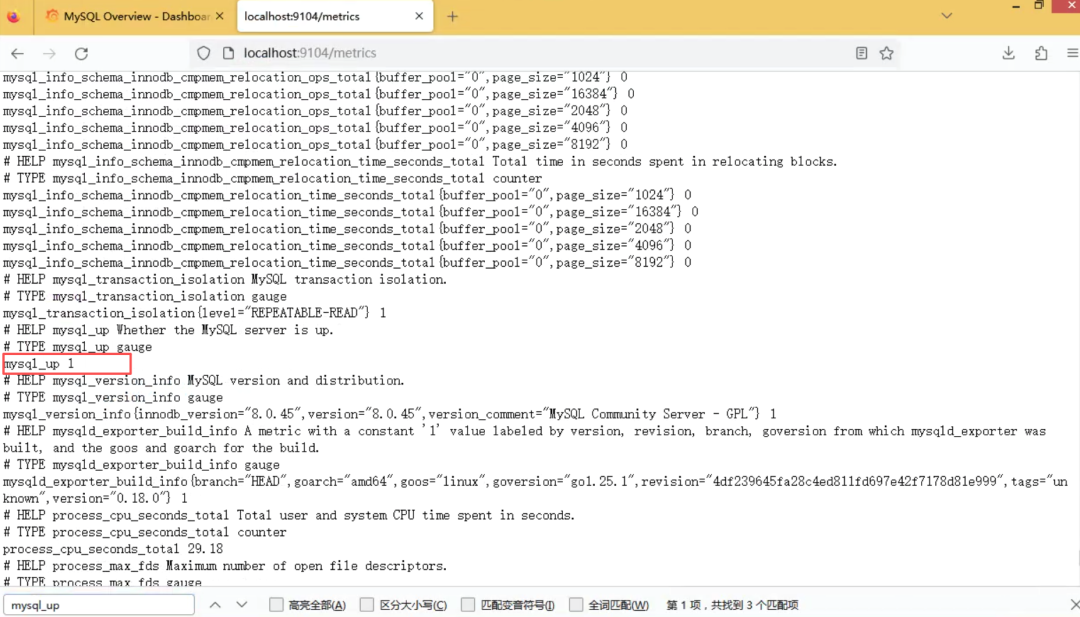
一开始我做了基础验证,确认链路“看似正常”:
- 访问mysqld_exporter的
/metrics页面,能正常加载指标 - 清晰看到核心指标
mysql_up 1(说明exporter能连上MySQL)
但诡异的是:
- 登录Prometheus UI查询
mysql_up,显示“no data” - 导入MySQL监控Dashboard后,Grafana清一色“No Data”
那一刻我陷入了典型的“运维自我怀疑”:
是不是本地Workstation环境太拉胯?
要不要把集群迁移到vCenter重新搭?
是不是MySQL镜像有问题?
👉 事实证明:所有怀疑都是多余的,问题完全不在环境,全在细节配置
🧠 三、核心认知:监控系统的“底层逻辑”(踩坑后才懂)
这次实验最核心的收获,是想通了一句话:
监控系统 = 数据 + 标签(label)+ 查询(query)
翻译成熟话就是:
有数据 ≠ 能展示
Grafana要正常显示数据,必须同时满足3个“对齐条件”,缺一不可:
1️⃣ Prometheus能采集并存储到完整的指标数据
2️⃣ 采集的label与面板查询的label完全匹配
3️⃣ 查询语句/变量没有把数据“过滤一空”
后面我踩的所有坑,本质上都是这3个条件没对齐。
💣 四、踩坑复盘(按真实排查顺序,每一步都踩在痛点上)
下面是我 2 天里踩过的 5 个关键坑,从“表面报错”到“隐蔽无提示”,每一个都能让运维人破防👇
❌ 坑1:mysql_up 像“过山车”,1和0来回跳
📊 现象
exporter的/metrics里,mysql_up指标极不稳定:
mysql_up 1 → 0 → 1 → 0(每隔几秒切换一次)
🔍 排查过程(走了弯路)
第一反应是“exporter账号权限不够”,反复执行授权语句:
GRANT PROCESS, REPLICATION CLIENT, SELECT ON *.* TO 'exporter'@'%';
FLUSH PRIVILEGES;
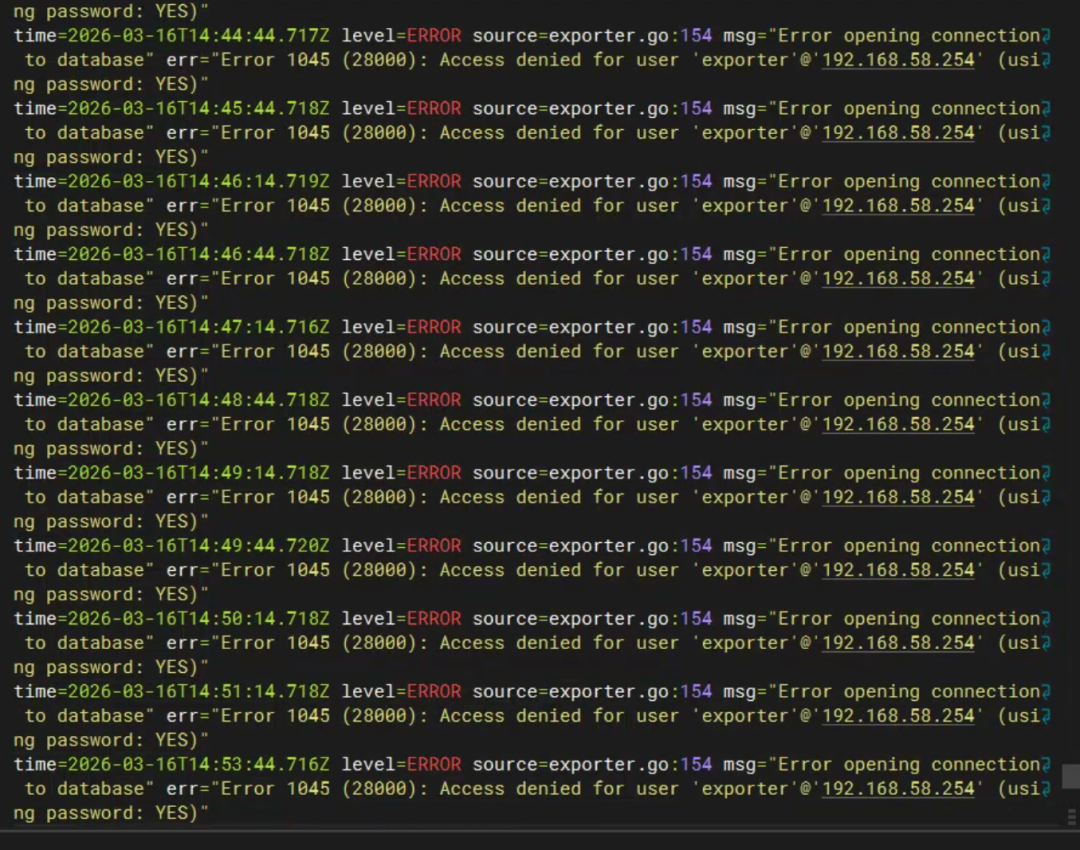
但依旧没用。直到查exporter的Pod日志,才看到关键报错:
level=ERROR source=exporter.go:154 msg="Error opening connection to database" err="Error 1045 (28000): Access denied for user 'exporter'@'192.168.58.255' (using password: YES)"
💥 根因(MySQL 8.x 经典坑)
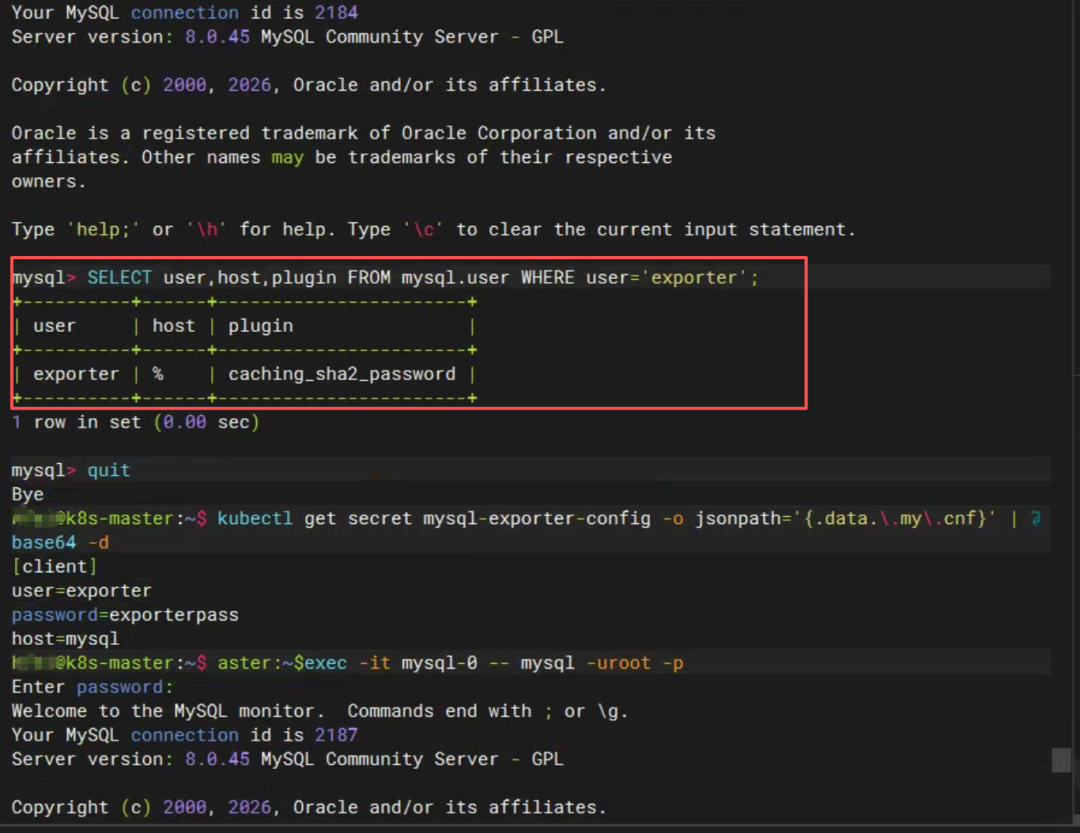
MySQL 8.0默认的身份认证插件是:
caching_sha2_password
而我当前环境的mysqld_exporter版本,完全不兼容这个新插件,导致连接时断时续。
✅ 解决(一行SQL搞定)
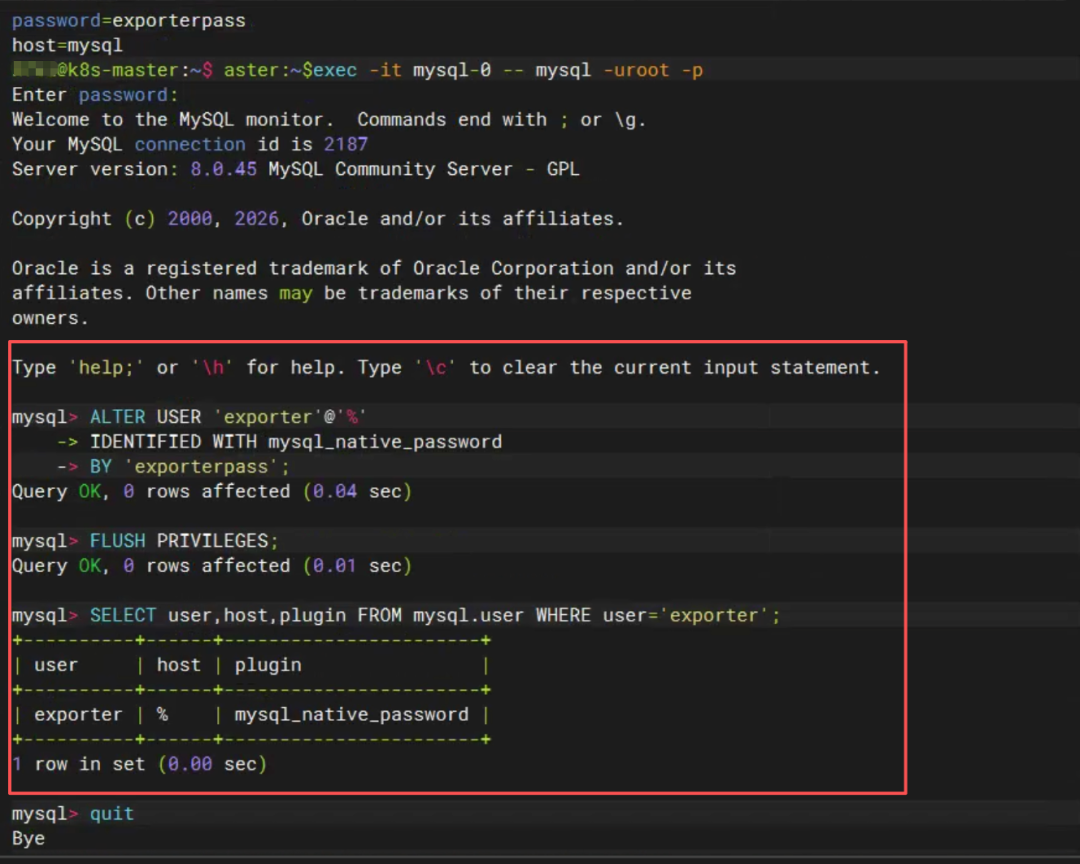
修改exporter用户的认证方式,切回兼容的mysql_native_password:
ALTER USER 'exporter'@'%'
IDENTIFIED WITH mysql_native_password
BY 'exporterpass';
FLUSH PRIVILEGES;
🎯 结果
mysql_up 稳定=1 ✔(再也不跳变)
❌ 坑2:权限全对,却依然报Access denied
📊 现象
exporter日志持续报错,IP是K8s Pod的集群IP:
Access denied for user 'exporter'@'192.168.10.23'
🔍 排查过程(最隐蔽的一步)
我核对了:
- exporter账号的权限(PROCESS/SELECT等都给了)
- MySQL的bind-address(允许所有IP访问)
- K8s网络策略(无拦截) 甚至手动在exporter Pod里telnet MySQL端口,能通,但就是连不上。
💥 根因(Headless Service的DNS坑)
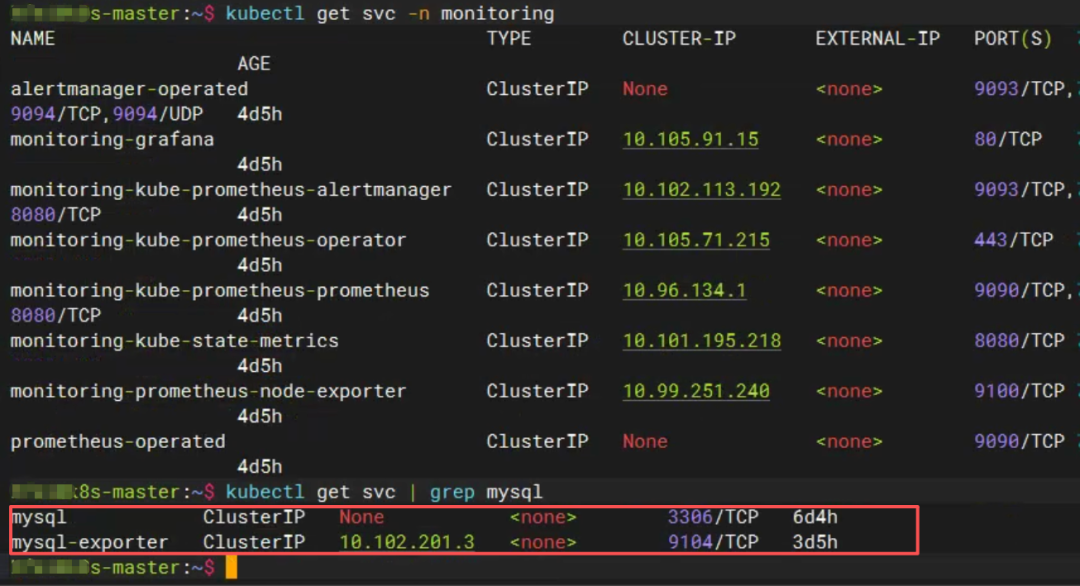
我的MySQL用的是Headless Service(ClusterIP: None),而exporter配置的连接地址是:
MYSQL_HOST=mysql ❌
🧠 Kubernetes关键知识点
Headless Service的DNS解析规则不是“Service名”,而是:
Pod名.Service名.命名空间.svc.cluster.local ✅
// 例如
mysql.default.svc.cluster.local -> 不一定解析
mysql-0.mysql.default.svc.cluster.local -> Pod
mysql-1.mysql.default.svc.cluster.local -> Pod
简化写法是mysql-0.mysql(mysql-0是第一个MySQL Pod名),直接写mysql根本解析不到具体Pod。
✅ 解决
修改exporter的环境变量:
kubectl create secret generic mysql-exporter-config \
--from-literal=.my.cnf="[client]
user=exporter
password=exporterpass
host=mysql-0.mysql
port=3306"
mysql-0.mysql是 StatefulSet 的稳定 DNS。
🎯 结果
✔ exporter稳定连接MySQL
✔ mysql_up指标彻底正常
❌ 坑3:Prometheus 压根没采集到数据
📊 现象
exporter正常了,但Prometheus UI查mysql_up依旧显示“no data”。
🔍 排查路径(精准定位)
- 打开Prometheus UI → Status → Targets
- 翻遍所有target,找不到mysql-exporter的采集项
- 检查ServiceMonitor资源:
kubectl get servicemonitor -n monitoring - 查看ServiceMonitor详情,发现label匹配错误
💥 根因(大小写敏感的“致命细节”)
ServiceMonitor里的label写反了大小写:
# 错误写法(我踩的坑)
labels:
Release: monitoring ❌
# 正确写法(Prometheus Operator识别的label)
labels:
release: monitoring ✅
👉 Kubernetes的label是严格区分大小写的!一个字母大写,直接导致Prometheus认不到采集规则。
✅ 解决
修正ServiceMonitor的label,重新应用配置:
apiVersion: monitoring.coreos.com/v1
kind:ServiceMonitor
metadata:
name:mysql-exporter
namespace:monitoring
labels:
release:monitoring# 统一小写
spec:
selector:
matchLabels:
app:mysql-exporter
endpoints:
-port:metrics
interval:10s
🎯 结果
✔ Prometheus Targets里出现mysql-exporter,状态UP
✔ 能查到mysql_up及所有MySQL指标
❌ 坑4:Grafana 报错“DS_PROMETHEUS找不到”
📊 报错
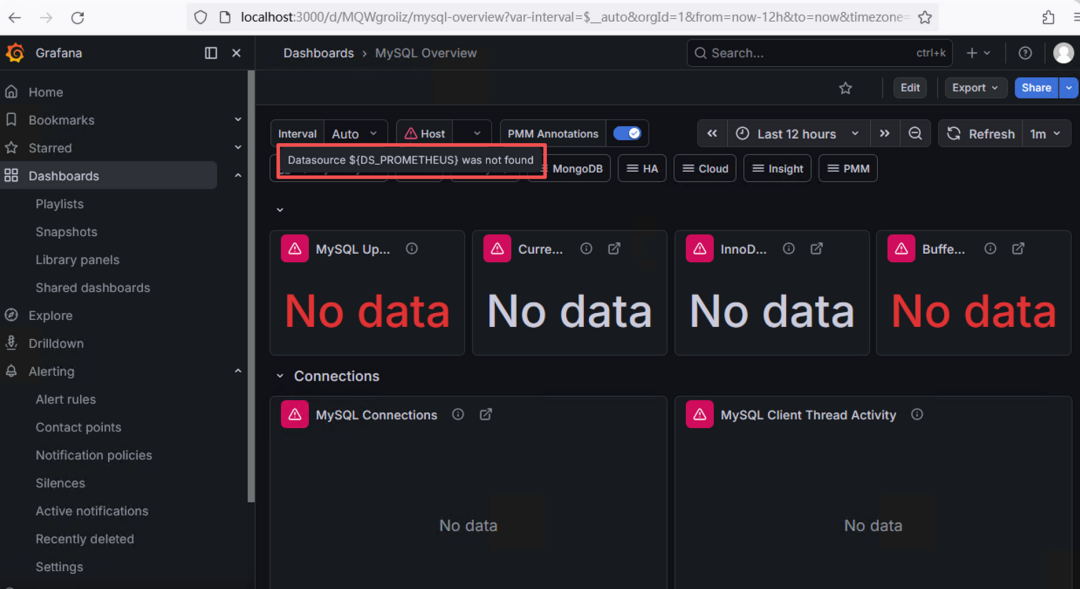
导入MySQL官方Dashboard后,面板顶部直接红框报错:
Datasource ${DS_PROMETHEUS} was not found
🔍 排查过程
一开始以为是Prometheus数据源没配好:
- 反复测试Grafana的Prometheus数据源(显示“Success”)
- 手动改Dashboard的查询语句,把
${DS_PROMETHEUS}换成实际数据源名,能查到数据
这才意识到:是Dashboard的变量没定义。
💥 根因
大部分开源的MySQL监控Dashboard,都会用${DS_PROMETHEUS}作为“数据源变量”,但我的Grafana里根本没创建这个变量。
🎯 结果
❌ 这一步并没有解决,与下一个坑算同一坑。
❌ 坑5(终极坑):Grafana全是No Data
📊 现象
最崩溃的一步:
- 无任何报错
- Prometheus有数据
- Grafana数据源正常
- 但所有图表都显示“No Data”
🧪 关键排查操作
打开Grafana的Explore功能,做对比查询:
裸查指标(无过滤):
mysql_global_status_threads_connected ✔ 有数据,曲线正常
带变量查询(Dashboard默认写法):
mysql_global_status_threads_connected{instance=~"$instance"} ❌ 无数据
再次确定prometheus是拿到了数据的,grafana是能查询到数据的,现在回想来这个操作也没啥意义。
✅ 解决
进入Dashboard → MySQL Overview → 右上角的“Settings” →Variables
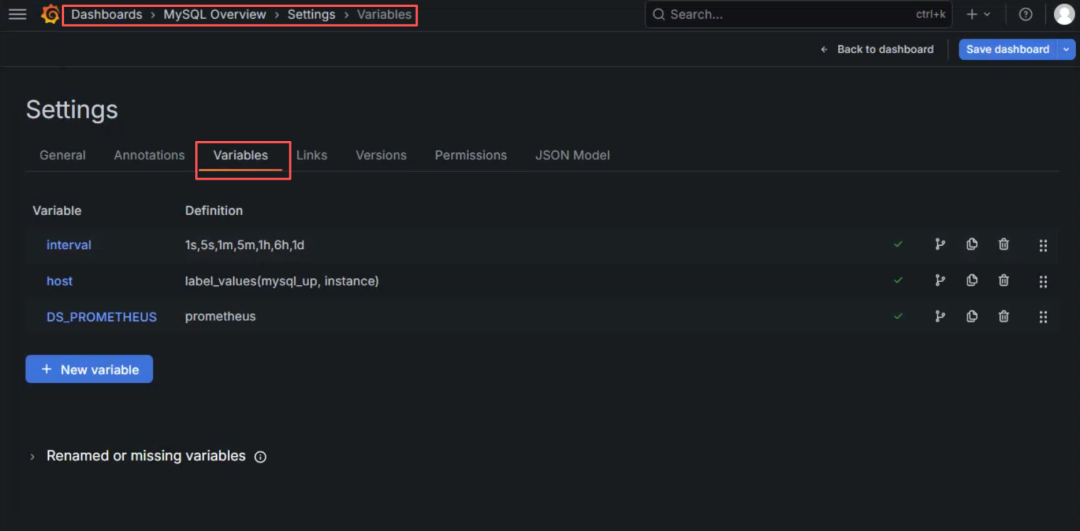
点击 New variable
1. Variable type -> Data source
2. Name -> DS_PROMETHEUS
3. Type -> Prometheus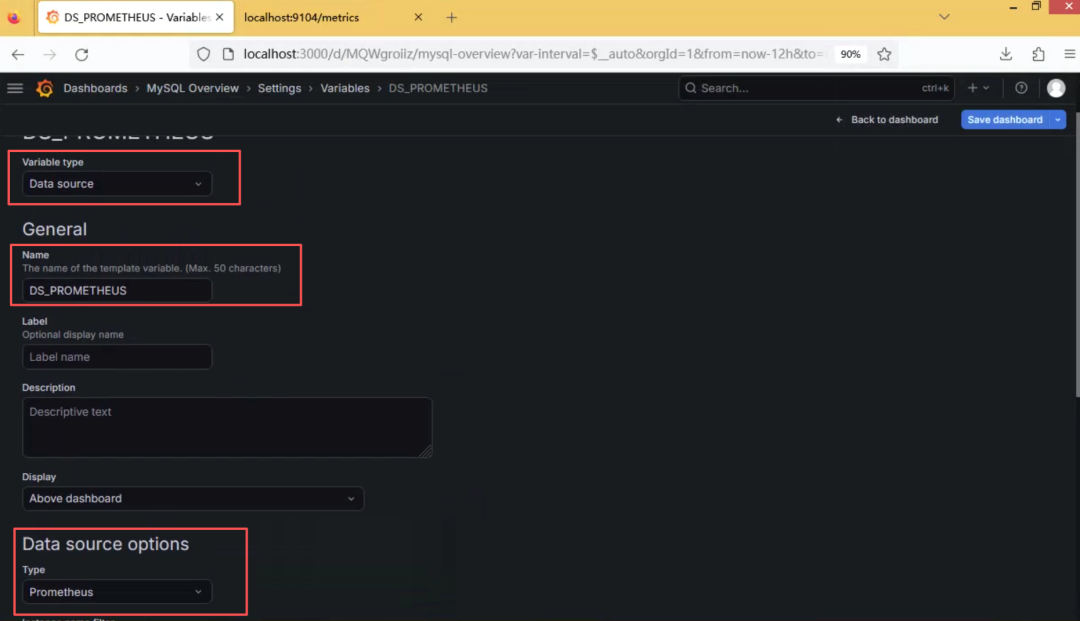
- 点击右上角的
Save dashboard保存
🎯 最终结果
Grafana → 所有图表恢复正常 ✔
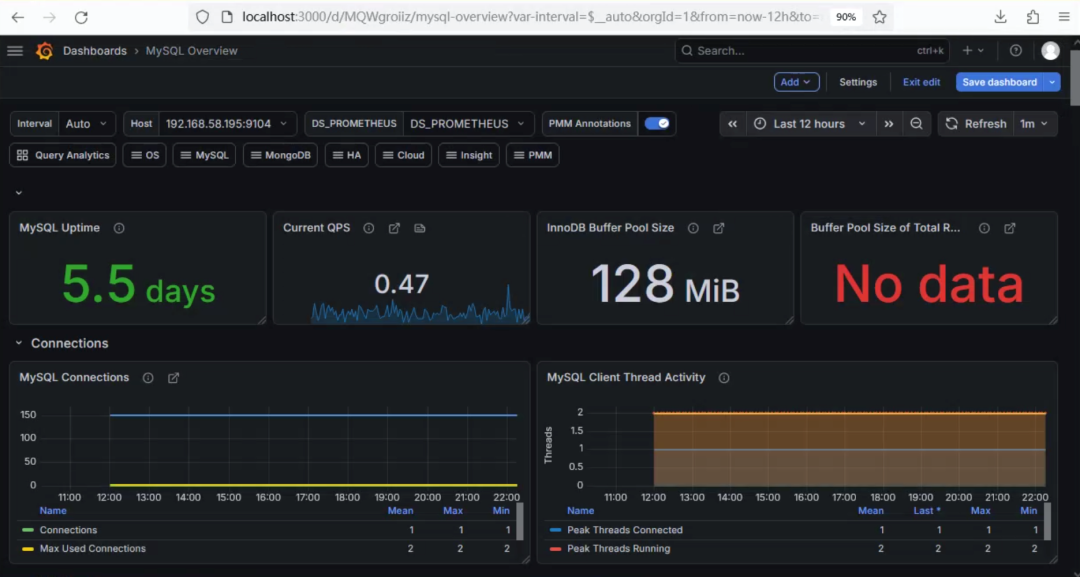
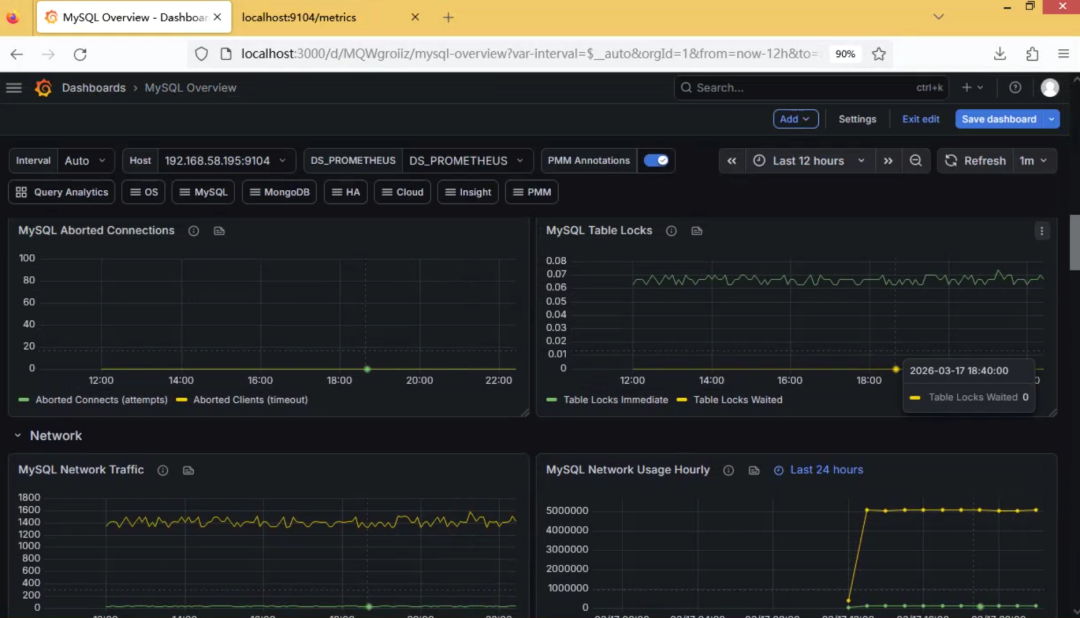
能清晰看到MySQL的QPS、连接数、InnoDB状态、慢查询、Buffer Pool使用率等核心指标。
🧩 五、为什么会“一看到No Data就怀疑环境”?
这次踩坑让我发现一个典型的运维心理误区:
👉 一看到No Data,第一反应是“环境有问题”,而非“配置细节”
但实际排查下来:
90%的No Data问题 = 配置问题
尤其是label大小写、变量定义、DNS解析这类“小细节”,远比环境问题更常见。
🧠 六、实验本质:所有问题都归为3类
把2天的坑抽象一下,其实就3类问题,覆盖了监控链路的核心:
1️⃣ 数据链路问题
Exporter ↔ MySQL 连接异常
Prometheus ↔ Exporter 采集异常
(对应坑1、坑2、坑3)
2️⃣ 标签对齐问题
ServiceMonitor label 与 Prometheus 采集规则不匹配
instance/job label 与 Dashboard 查询不匹配
(对应坑3、坑5)
3️⃣ 查询/变量问题
Grafana 变量未定义、变量取值为空
PromQL 过滤条件错误
(对应坑4、坑5)
🔥 七、万能排查流程(建议直接收藏)
以后再遇到“Grafana No Data”,按这个顺序查,效率直接拉满:
Step 1️⃣ 查源头:确认exporter有数据
# 进入exporter Pod
kubectl exec -it mysql-exporter-xxxx -n monitoring -- sh
# 访问本地metrics
curl localhost:9104/metrics | grep mysql_up
✅ 能看到mysql_up 1→ 进入Step2;❌ 先修exporter
Step 2️⃣ 查采集:确认Prometheus有数据
- 打开Prometheus UI → Status → Targets
- 确认mysql-exporter的target状态为UP
- 执行基础查询:
mysql_up✅ 有数据 → 进入Step3;❌ 修ServiceMonitor/label
Step 3️⃣ 查面板:裸查指标是否正常
在Grafana Explore执行:
mysql_global_status_threads_connected # 不带变量
✅ 有数据 → 进入Step4;❌ 修Grafana数据源
Step 4️⃣ 查变量:确认变量不为空
- 检查instance/DS_PROMETHEUS等变量
- 执行:
label_values(mysql_up, instance)✅ 有取值 → 进入Step5;❌ 修变量查询规则
Step 5️⃣ 查过滤:确认PromQL无错误
把Dashboard的查询语句复制到Explore,替换变量为实际值,验证是否有数据。
✍️ 最后一句
这次实验最大的收获,不是“搭好了监控”,而是彻底理解了:
监控系统真正难的,从来不是“部署”,而是“数据对齐”
如果你现在也卡在“Grafana No Data”,先从“数据→label→查询”这三个点入手,大概率一步就能定位问题。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-17,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号