GPT Image-2 引爆技术圈!底层技术原理与架构全拆解

GPT Image-2 引爆技术圈!底层技术原理与架构全拆解

老周聊架构
发布于 2026-05-08 18:37:26
发布于 2026-05-08 18:37:26
2026年4月,OpenAI用 GPT-Image-2 在 Image Arena 榜单上以 1512 分登顶,领先第二名 242 分——这是 AI 生图领域有史以来最大的代差领先。这不是一次版本迭代,而是一场范式革命:图像不再是通过"去噪"逐步显现,而是像写文章一样,一个 token 一个 token 地"写"出来。本文深度拆解其底层技术原理与架构设计。
一、发布概况:为什么说它"引爆"了技术圈
GPT-Image-2 于 2026 年 4 月正式发布,是 OpenAI 图像生成模型的最新力作。它的核心定位是原生多模态视觉推理系统,而非简单的"画图工具"。
关键性能数据:
指标 | GPT-Image-1.5 | GPT-Image-2 | 提升幅度 |
|---|---|---|---|
Image Arena 得分 | ~1270 | 1512 | +242 分 |
文字渲染准确率 | 70-85% | 99%+ | 跨代升级 |
复杂空间推理失败率 | 12% | 1.8% | -85% |
单图生成延迟 | 10-20s | < 3s | 提速 5-6 倍 |
最高分辨率 | 1024×1024 | 4096×4096 | 4K 原生 |
中文语料训练占比 | 8% | 23% | +187% |
242 分的领先优势是什么概念?在 AI 评测榜单历史上,这个幅度通常意味着整整一代的技术代差。它不仅碾压了 Midjourney V7、Google Imagen 4,连 OpenAI 自己的前代产品也被彻底超越。
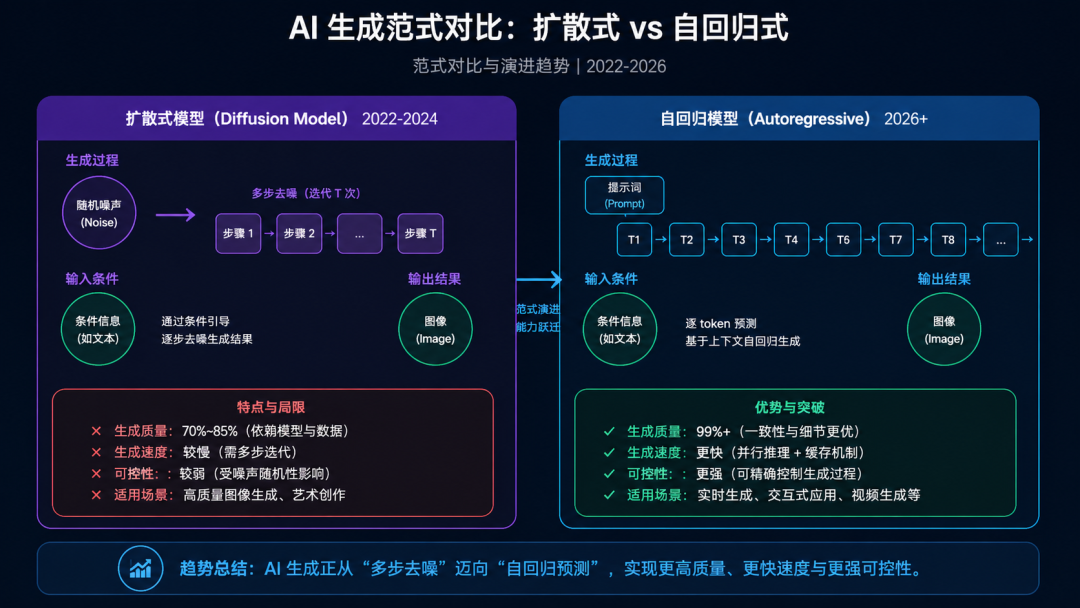
二、范式革命:从"扩散模型"到"自回归"的根本转变
2.1 扩散模型为什么走到瓶颈
过去三年,AI 生图由扩散模型(Diffusion Model)主导——Stable Diffusion、Midjourney、DALL-E 3 背后都是这个范式。其核心逻辑是:从纯噪声出发,逐步去噪,逐步显现图像。
这个过程本质上是像素分布的统计建模:模型学会了"什么样的像素组合看起来像一只猫",但它并不知道"猫有四只脚、尾巴、胡须"这些结构性的知识。因此,当遇到需要精确空间推理的指令时——
"在图片右上角放一个红色价格标签,字体用黑体,与背景光照保持一致"
扩散模型只能"猜测",而无法精确"规划"。
扩散模型的三个根本缺陷:
- 文字渲染差:模型把文字当"纹理图案"学习,而非"语义单元",经常出现乱码或错字
- 空间推理弱:像素级生成缺乏对元素间逻辑关系的显式理解,多元素指令遵循率不足 50%
- 两阶段分离:文本理解(一个模型)和图像生成(另一个模型)分离,中间传递必然有语义损耗
2.2 自回归:图像生成的"终极形态"
GPT-Image-2 彻底放弃了扩散范式,转向自回归(Autoregressive) 架构——与 GPT 生成文本的逻辑完全一致。
核心思想: 将图像视为由离散"图像 token"组成的超长序列,模型像写文章一样,一个 token 接一个 token 地生成。
从数学本质看,两者学习的目标函数存在根本差异:
- 扩散模型:学习条件概率
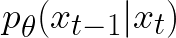
,即给定当前有噪声的图像,预测去噪后的图像,核心是学会逆向去噪过程
- 自回归模型:学习条件概率
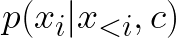
,即给定文本条件 c 和已生成的 token,预测下一个最合理的 token,其中
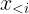
表示已生成的全部 token 序列
自回归的顺序生成特性带来了两个关键优势:
- 精确的文字渲染:文字 token 在序列中有明确的位置和上下文,模型是"写"文字,而非"绘制"文字图案
- 结构化推理能力:模型必须基于全局语义理解来生成每个局部,天然具备构图规划能力
2.3 Tokenizer:图像是如何变成 token 的
Transformer 是序列模型,输入输出必须是离散的 token。文本有 BPE/WordPiece,图像则需要专门的 Tokenizer(分词器)。一张 224×224 的 RGB 图包含超过 15 万个连续像素值,直接输入 Transformer 会导致计算复杂度呈二次方爆炸。
GPT-Image-2 的 Tokenizer 技术经历了十年演进,核心是两阶段路线:
第一阶段(Tokenizer): 图像 → 离散 token 序列,通过向量量化将连续像素压缩为码本索引
第二阶段(Generator): Transformer 自回归预测 token → 解码回图像
阶段 | 技术 | 关键突破 |
|---|---|---|
VQ-VAE (2017) | 向量量化变分自编码器 | 离散表示的起点,但存在码本坍塌问题 |
VQGAN (2020) | 引入对抗训练 | LPIPS 感知损失解决图像模糊,f=16 压缩比下仍保持高质量 |
ViT-VQGAN (2021) | Vision Transformer 骨干 | EMA 更新码本,训练更稳定,几何直觉更优 |
RQ-VAE (2022) | 残差量化 | MAGVIT-v2 首次让 LM 超越扩散模型 |
FSQ (2023) | 有限标量量化 | DeepMind 简化量化同时提升质量 |
GPT-Image-2 的 Tokenizer 可能采用了改进的 VQ-VAE 变体,结合了残差量化和对抗训练的优点,实现多尺度压缩——高分辨率图像被压缩为数十万个离散 token,再由 Transformer 自回归生成。
三、架构深度拆解:三大支柱撑起的视觉推理系统
GPT-Image-2 的卓越性能建立在三大核心架构创新之上,它们共同构成了一个具备"思考-生成-校验"闭环的智能视觉系统。
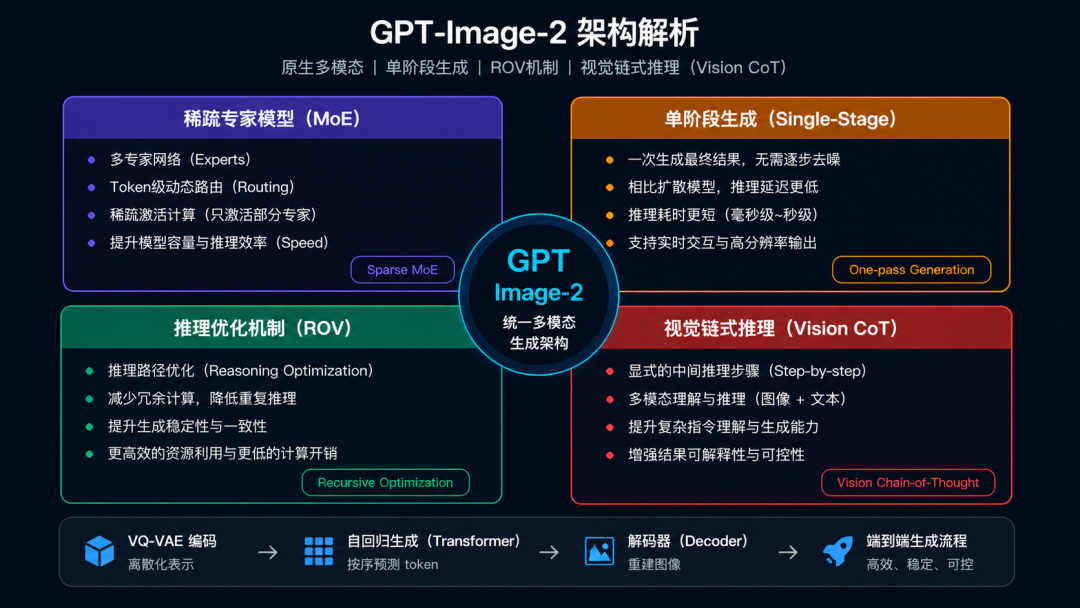
3.1 支柱一:原生多模态 MoE 架构
GPT-Image 1.5 是"GPT-4o 理解 + 外挂图像模型渲染"的两阶段流水线。 文本理解和图像生成是两个独立模块,中间通过一层编码传递信息——这必然导致语义损耗。
GPT-Image-2 则是原生多模态模型。它不是 GPT-4o 的附属模块,而是 OpenAI 下一代基础模型"Spud"的视觉输出分支,在文本、图像、音频、视频 token 上联合训练。
这意味着:文本 token 和图像 token 在同一个 Transformer 内部并行处理,共享同一套语义表征空间。
当模型"读"到 Prompt 中的"痛"字时,这个文字概念与生成"痛"字图像所需的笔画、结构信息在底层表征上紧密关联。模型在"说"出指令的同时,就在"规划"如何画出对应的图形——理解与生成高度统一。
这就是为什么 GPT-Image-2 能精准生成"老干妈"品牌设计——不只是画了一个辣椒瓶,而是理解了这是一个中国品牌,需要符合其视觉调性。
3.2 支柱二:单阶段推理管道
旧有流水线(GPT-4o 理解 → 调外部图像模型)有两个问题:
- 延迟高:两个模型串行执行,总延迟 10-20 秒
- 精度损耗:中间表示丢失了字形结构的精确信息
GPT-Image-2 采用了单阶段推理:解析 Prompt 的"思考"过程和渲染像素的"生成"过程,在同一次模型前向传播中完成。
这相当于一位画家在构思画面的同时就直接落笔,而非先写一份详细的作画说明书再交给另一只手去画。架构变化从生成 PNG 元数据标签的不同就能证实——GPT-Image-1.5 和 GPT-Image-2 输出的标签完全不同,说明底层系统经历了彻底重构。
3.3 支柱三:递归输出验证(ROV)
这是最具工程智慧的创新。传统模型生成图像后即结束,好坏由用户评判。GPT-Image-2 引入了一个递归输出验证循环:
模型生成图像 → 调用自身视觉理解能力进行"自我审查" → 评估与 Prompt 的语义对齐程度 → 分数未达标则重新生成 → 循环迭代,直至通过质量阈值
这意味着模型配备了一位严格的内部质检员。具体实现包括:
- 内部评估器:训练小型分类器,评估生成图像与文本提示的语义对齐程度
- 迭代修正:对生成序列中的问题区域进行局部重生成,而非整体重绘
- 多轮优化:最多进行 N 轮迭代,直到满足质量阈值或达到最大迭代次数
这个机制让复杂空间推理的失败率从 12% 骤降至 1.8%。代价是推理延迟增加约 40%——但对于需要商用级质量的设计任务,这个代价完全值得。
四、视觉推理链:GPT-Image-2 为什么能"看懂"复杂指令
4.1 Chain-of-Thought for Vision
为什么 GPT-Image-2 能处理"左上角放 Logo、右侧是产品图、底部留出二维码区域"这种复杂空间指令?
答案是它集成了视觉推理链(Chain-of-Thought for Vision) 机制。模型在生成前,会先进行隐式的"思考":
- 解析 Prompt:理解这是一个"商业海报"设计任务,而非"画一张科技感图片"
- 规划画面布局:确定标题区、图表区、插图区的精确位置
- 确定元素关系:Logo 放左上角、促销文案放中部、产品图放右侧
- 按"蓝图"逐步渲染:像素级执行设计规划
这个过程不再是黑箱,而是可被部分追溯的理性决策。当输入"设计一张 618 促销海报"时,模型会自动补充"促销氛围""价格突出""行动号召"等设计要素——这是 GPT-Image-2 理解"设计简报"而非"关键词"的关键。
4.2 文字渲染的革命
过去,在图像中生成可读文字,尤其是复杂字形的中文,是 AI 生图的"阿喀琉斯之踵"。
GPT-Image-2 凭借统一语义空间和自回归的序列生成能力,将文字渲染准确率从 70-85% 跃升至 99%+:
- 文字被视为"语义单元":模型在生成前就规划好文字内容和排版位置,而非把文字当纹理生成
- 中文作为"一等公民":训练数据中中文语料占比 23%,远超 DALL-E 3 的 8%,OpenAI 还与多家中国设计公司签订了数据合作协议
- 字符级精确控制:即使是"藏""懿"等复杂汉字,也能像素级还原
4.3 多图一致性:角色不再"漂移"
生成多格漫画或系列插图时,传统模型最大的问题是"角色漂移"——同一角色在不同图中长相不同。
GPT-Image-2 通过预定义视觉特征和跨图一致性约束,实现了角色外观的稳定保持。生成四格漫画时,主角"阿橘"(橘猫戴红围巾)在四格中毛发颜色、围巾色值、眼睛形状完全一致。
五、性能优化:3 秒生成 4K 图像的工程奇迹
自回归生成本质上是顺序过程——生成第 n 个 token 需要前 n-1 个 token 作为输入。这导致生成 4096×4096 图像时,如果完全顺序执行,延迟将不可接受。GPT-Image-2 采用了多项工程优化:
并行化策略:
- 分块并行生成:将图像划分为多个区域,每个区域独立生成,最后拼接,模型需具备强大的全局一致性理解能力
- 推测解码:用小型"草稿模型"快速生成多个候选 token 序列,然后用大模型并行验证,加速生成过程
- 分层 KV 缓存:不同分辨率的图像块使用不同的缓存粒度,减少重复计算
混合精度与量化:
- 训练阶段使用 BF16 混合精度,保持数值稳定性
- 推理阶段采用 INT8 量化,将权重从 FP16 压缩到 INT8,推理速度提升 2-4 倍
- 动态量化:简单区域使用低精度,复杂区域使用高精度,动态分配计算资源
硬件感知优化:
- Flash Attention 3.0:将注意力计算内存复杂度从
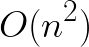
降低到 O(n)
- Tensor Core 优化:矩阵乘法完全在 Tensor Core 上执行,最大化计算吞吐量
六、应用场景与局限性
6.1 适用场景
GPT-Image-2 在以下场景具有碾压性优势:
- 商业设计:营销海报、电商详情页、UI 设计稿,文字准确率支持直接商用
- 复杂空间指令:需要精确布局的海报、截图、信息图
- 多图一致性创作:漫画系列、角色设计、品牌视觉
- 多语言文字:中文、阿拉伯文、日文等非拉丁文字的精准渲染
6.2 现存局限
尽管优势明显,GPT-Image-2 仍有局限:
- 艺术独特性不足:纯艺术创作上,仍不及 Midjourney V7 的视觉冲击力
- 极端写实人像:超高精度摄影场景,Google Imagen 4 的肤质光影处理略胜一筹
- 精细局部控制:相比 Stable Diffusion 3 的 ControlNet、LoRA,局部编辑能力较弱
- 成本与封闭:仅通过 API 使用,无法本地部署,长期成本可能高于开源方案
七、总结:不是终点,而是新起点
GPT-Image-2 的出现,标志着 AI 图像生成从"模仿像素分布"的"画图工具",正式迈入了"理解视觉逻辑"的"视觉系统"阶段。
其核心启示是:
- 统一表示的重要性:文本和图像在同一个语义空间中处理,消除了模态间的信息壁垒
- 顺序生成的优势:自回归的序列特性天然适合结构化内容的生成
- 自我监督的价值:递归验证将单次生成升级为迭代优化,显著提升输出质量
对于设计师而言,基础设计工作将被大幅自动化——但真正有价值的,是那些需要创意判断和审美决策的工作。当技术门槛消失,创意才真正变得稀缺。
你用过 GPT-Image-2 了吗?文字渲染真的达到 99% 准确率了吗?评论区聊聊你的体验!
— 完 —
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-26,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号