为 AI agent 构建智能上下文记忆

为 AI agent 构建智能上下文记忆

deephub
发布于 2026-05-11 12:53:44
发布于 2026-05-11 12:53:44
Memory(记忆)是任何有效 AI agent 的基础组件。在最核心的层面,memory 存的是过去的用户交互和上下文信息,让 agent 在时间维度上做出更准确的响应。一个 agent 仅靠配置好的大语言模型(large language model,LLM)和工具就能跑起来,但真正的可靠性和个性化来自 memory。
Memory 让 agent 在多次交互之间保留对话上下文,这样即使是多个 agent 协作完成任务也一样。这种上下文连续性让系统能更准确地把握用户意图,输出与预期对得上的响应。
当 agent 同时拿到当前输入和相关上下文时,它产出的内容会更有依据。视情况,agent 可能:
- 触发一次工具调用
- 向用户请求澄清
- 直接给出最终响应
Memory 把 AI agent 从被动响应的系统,变成具备上下文感知的助手。
为什么不把全部历史交互都丢给 LLM
messages: Annotated[List[BaseMessage], add_messages]context window 一旦做大,最简单的做法就是每次新请求都把过去所有用户交互(有时甚至跨多个会话)一起发过去,让模型完全靠 attention 机制自己解读。
这种策略实现简单,对短期、小规模的任务表现良好。但对话一长问题就来了:
- 模型容易被过多且无关的上下文淹没 ⚠️
- attention 机制本身不透明,输出会出现不一致
- 同一类输入产生不同响应,开发者很难定位原因
- token 用量随每轮交互增长,成本明显上去 💰
- 上下文越大,处理时间越长,延迟也跟着上 ⏱️
对话历史不断膨胀,每条查询的处理成本越来越高,响应越来越慢,对生产级 agent 系统尤其不友好。
由此引出一个关键问题:怎么把上下文压下去,又不丢相关性?
Rolling Context Window
一种替代做法是限定一个最近交互的最大数量发送给模型,这种技术被称为 rolling context window。
只保留最近的 N 次交互,开发者就能:
- 控制 token 用量
- 降低延迟
- 把成本维持在可预测区间
这种做法适用于任务主要依赖近期对话历史的场景。但对那些需要较旧或长期信息的 agent,硬切窗口会让理解残缺、输出不准。
注:rolling window 既可以按消息数计,也可以按 token 计。
WINDOW_SIZE = 6
#Added
a wrapper method for return window messages
def rolling_add_messages(old, new):
combined = add_messages(old, new)
return combined[-WINDOW_SIZE:]
class AgentState(TypedDict):
messages: Annotated[List[BaseMessage], rolling_add_messages]用倒排索引做更聪明的上下文裁剪
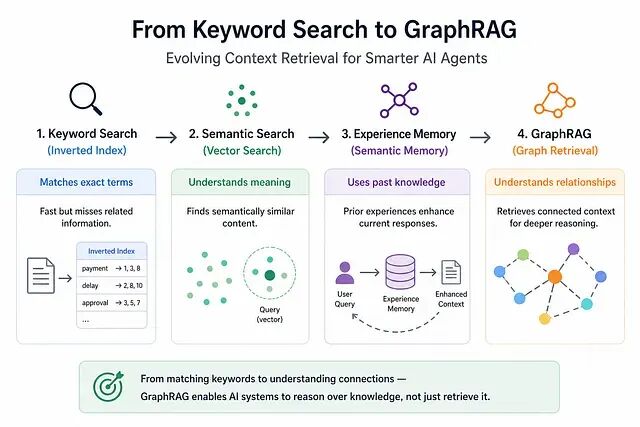
倒排索引是一种数据库数据结构,把内容(词或数字)直接映射到它在文档或文档集合中出现的位置,用于实现极快的全文检索。
在聊天历史上构建一个倒排索引,用户提交查询时检索与查询中的词最匹配的上下文。
把所有相关匹配交给模型。这样发给基础模型的上下文量会显著缩小,同时仍然保留最相关的信息 ,哪怕这些信息来自对话很早的部分。
但仅靠精确词匹配未必够用,查询可能用了语义相近、但用词不同的表达,结果就是上下文检索不完整,可能引出错误输出或幻觉,语义上接近的查询甚至会拿到完全不同的回应。
一个最简单的倒排索引构建与搜索可以这样写:
def build_inverted_index(messages):
index = defaultdict(set)
for i, msg in enumerate(messages):
words = msg.lower().split()
for word in words:
index[word].add(i)
return index
def search_context(query, index, messages):
query_words = query.lower().split()
matched_ids = set()
for word in query_words:
if word in index:
matched_ids.update(index[word])
return [messages[i] for i in matched_ids]语义上下文检索
语义检索是一种数据检索技术,它解读用户意图和查询的上下文含义,而不仅仅匹配关键词。
不依赖精确词匹配可以用语义上下文检索。语义检索保留用户意图,按含义而非具体词去取回上下文消息,能压住幻觉,让 agent 响应更准、更可靠。
句子先被切成 token,然后用轻量级 AI embedding 模型把每个 token 转成向量。每个 token 向量会基于周围词提供的上下文做细化。这些 token 向量再被聚合成一个表示整句含义的句子向量,存入向量数据库。
用户提交查询时,查询同样会被转成向量,并使用 cosine similarity 与库中存储的向量比较:
similarity = cos(angle between vectors)
接近 0.9 的相似度分数说明含义高度相近,低于 0.3 通常说明两句无关。具体阈值视应用而定。检索出的最相关上下文随后被送入基础模型生成响应。
下面这段示例代码使用 Sentence Transformers 生态中的轻量预训练 sentence-embedding 模型,配合 FAISS作为内存向量数据库做语义检索。
from sentence_transformers import SentenceTransformer
import faiss
import numpy as np
# Sample data
sentences = [
"schedule meeting tomorrow",
"send project report",
"prepare meeting agenda"
]
# Load embedding model
model = SentenceTransformer("all-MiniLM-L6-v2")
# Convert sentences into vectors
embeddings = model.encode(sentences)
# Create FAISS index
index = faiss.IndexFlatL2(embeddings.shape[1])
index.add(np.array(embeddings))
# Search
query = "plan meeting"
query_vector = model.encode([query])
distances, indices = index.search(np.array(query_vector), k=2)
print([sentences[i] for i in indices[0]])语义经验记忆
每条用户查询通常从一个干净状态开始,没有以前交互里积累的知识,所以体验上就会显得不完整、不够个性化。
更好的做法是:用户每次提交查询,系统就跨过去的交互检索语义相似、可能对当前请求有帮助的上下文。context window 要做切分 —— 一部分留给最近对话,一部分留给语义检索取回的相关历史。
这样 agent 就能基于用户偏好和先前交互调整响应,体验更一致、更个性化、更熟悉。
这就是把先前获得的知识当作经验,用来增强当前用户查询的地方。
Graph RAG
跨上下文检索本身就不容易,尤其是相关知识分散在多次交互或多份文档里时。纯语义检索往往只覆盖所需信息的一部分,那些语义不同但逻辑上相关的重要细节会被漏掉。
举个例子:用户问 "Why was the payment delayed?",语义检索可能取回带有 payment delay 或 transaction pending 的消息,但很容易漏掉 "approval from finance team is pending" 或 "compliance verification not completed" 这类陈述 —— 它们和延迟在逻辑上是连在一起的,但用词差太多,相似度方法抓不到。
这就是 GraphRAG起作用的地方,它把信息表示成一张图:文档或概念是节点,关系是边,从而支持更有结构、更有连通性的上下文检索。
但麻烦是:当知识图谱必须随着运行时不断引入的新信息动态更新时,维护和演进这张图,在计算和设计两端都会带来不小的开销。
构建知识图谱通常包含这些步骤:
- 识别节点(实体或概念)
- 识别节点之间的关系
- 定义本体(图的结构与 schema)
- 用数据填充图
这种结构化表示能比单纯语义相似度取回更丰富、更有连接性的上下文,让响应更完整,也减少相关知识之间被漏掉的连接。
可以使用 Microsoft 的 GraphRAG 库,自动从内容中识别实体(节点)和关系,并据此构建知识图谱。
Step 1:初始化项目目录
安装 GraphRAG 并创建工作目录:
pip install graphrag
graphrag init --root ./graphrag_demo命令会创建如下结构:
graphrag_demo/
├── input/
├── settings.yaml
└── prompts/
把源文档放进 input/ 文件夹。Step 2:构建知识图谱
运行 indexing 命令,提取实体、检测关系、构建图:
graphrag index --root ./graphrag_demoStep 3:查询图谱
直接对生成好的知识图谱发起查询:
graphrag query \
— root ./graphrag_demo \
— method global \
"Why was the payment delayed?"系统会跨图检索互相连接的上下文,从而支持多跳推理,而不仅仅是语义相似度。
总结
现代 AI agent 想给出准确且个性化的响应,光靠关键词匹配或孤立的语义相似度是不够的。倒排索引能高效缩小上下文规模,语义检索能保住意图,但两条路都可能漏掉散落在多份知识里的关系。
GraphRAG 把信息组织成相互关联的实体和关系,让跨上下文的多跳推理成为可能,而不只是取回相似的文本片段。agent 也因此从表层检索走向对概念之间关系的更深理解。
把 rolling context window、语义相似度检索、经验记忆和基于图的检索结合起来,就能构建出不只会回忆、还会推理的 agent。这样的系统给出的答案更完整,幻觉更少,体验也更个性化、更一致。
agent memory 的未来在于从存储信息转向连接知识,让 AI 系统从上下文感知的助手,进一步演进为具备上下文推理能力的协作者。
by Mudassir Fazal
喜欢就关注一下吧
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-01,如有侵权请联系 cloudcommunity@tencent.com 删除
本文分享自 DeepHub IMBA 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与 腾讯云自媒体同步曝光计划 ,欢迎热爱写作的你一起参与!
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号