llama4j:Java 工程师的 LLM 核弹

llama4j:Java 工程师的 LLM 核弹

javpower
发布于 2026-05-22 18:52:26
发布于 2026-05-22 18:52:26
llama4j:Java 工程师的 LLM 核弹
这是一枚精准制导的技术核弹——直接把大模型推理塞进 JVM 的内存空间,让 Python 生态的 HTTP 桥接方案变成历史。
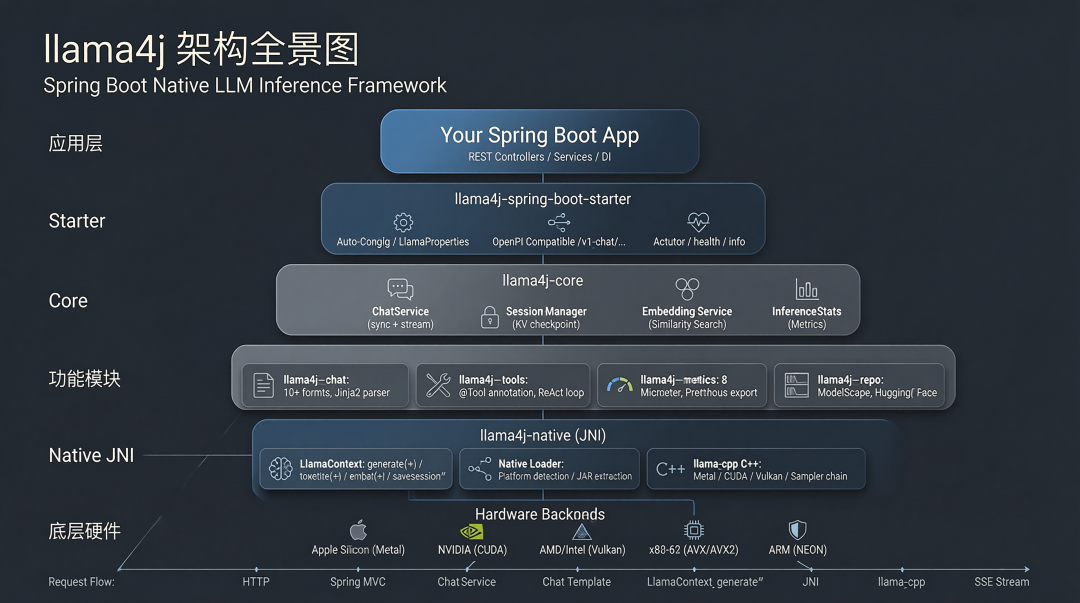
llama4j 架构全景图
现状:Java 部署 LLM 的「技术屈辱」
过去两年,Java 工程师在 LLM 落地场景里,活得像个二等公民。
你的 Spring Boot 微服务要调用大模型?标准姿势是这套「屈辱三连」:

这套架构的每一层都是技术债务:
屈辱点 | 代价 | 本质问题 |
|---|---|---|
网络税 | 1-5ms HTTP 往返,高并发下指数爆炸 | 进程间通信是原罪 |
序列化损耗 | JSON 编解码 + 对象映射双重消耗 | 数据在 JVM 和 Python 之间来回搬运 |
运维地狱 | Python 环境 + Docker + 服务发现 + 健康检查 ×2 | 两套技术栈,两套监控,两套故障域 |
Spring 生态断裂 | Auto-Config、Actuator、Micrometer 全部失效 | Python 侧car 是生态孤岛 |
讽刺的是:你花了三年把系统迁移到 Spring Cloud,结果为了跑个 7B 模型,又要重新养一个 Python 团队。
llama4j:降维打击的技术暴力
llama4j 的解法不是「优化」传统方案,而是彻底否定它的存在前提。

三个 Zero,直接宣判 Python 桥接方案的死刑:
- Zero Python —— 没有 Python runtime,没有 conda,没有 pip 依赖地狱
- Zero Docker —— 不需要第二个容器,不需要 sidecar 模式
- Zero Network Hop —— JNI 直接穿透,内存地址级调用,延迟从毫秒级降到微秒级
这不是优化,这是架构层面的降维打击。
七维能力雷达:碾压式统治

llama4j 七维能力雷达
数据不会说谎。llama4j 在七个关键维度上,对传统方案形成全面包围:
维度 | llama4j | 传统 Python Sidecar | Ollama | vLLM |
|---|---|---|---|---|
部署复杂度 | 10/10 单 JAR | 2/10 双服务+Docker | 7/10 | 5/10 |
延迟表现 | 10/10 ~0ms | 4/10 1-5ms | 6/10 | 7/10 |
Spring 集成 | 10/10 原生 | 2/10 手动 REST | 3/10 | 3/10 |
内存效率 | 9.5/10 ~20MB | 3/10 ~200MB+ | 7/10 | 4/10 |
可观测性 | 9/10 Micrometer | 3/10 孤岛监控 | 5/10 | 6/10 |
冷启动 | 9/10 预编译 JNI | 3/10 Python init | 8/10 | 4/10 |
生态完整度 | 9/10 全链路闭环 | 5/10 断裂 | 6/10 | 8/10 |
注意:传统方案在 Spring 集成维度只拿到 2 分——不是它不想集成,是根本集不进去。Python 进程对 Spring 生态来说就是个黑盒。
架构解剖:七层模块化设计的暴力美学
llama4j 不是「能跑就行」的玩具,而是一套生产级分层架构,每一层都经过工业场景的千锤百炼:
请求全链路(极致简洁):
HTTP Request → Spring MVC → ChatService → Chat Template Render
→ LlamaContext.generate() → JNI → llama.cpp Sampler Chain
→ Token Stream → SSE Response
没有中间商赚差价。没有 JSON 序列化损耗。没有跨进程通信延迟。
核心特性:每一项都是「杀手级」
5.1 Function Calling —— Java 注解驱动的 ReAct 引擎
告别 prompt engineering 的原始时代:
@Component
public class WeatherTools {
@Tool(name = "get_weather", description = "Get current weather for a city")
public WeatherReport getWeather(
@ToolParam(description = "City name, e.g. Beijing") String city,
@ToolParam(description = "Temperature unit") String unit) {
return weatherService.fetch(city, unit);
}
}
框架自动完成完整 ReAct 闭环:
- 检测
tool_calls意图 - 反射调用 Java 方法
- 回填执行结果
- 继续模型生成
流式工具调用 SSE 事件序列(OpenAI 兼容):
tool_calls delta → finish_reason: "tool_calls"
→ content delta (real-time) → finish_reason: "stop" → [DONE]
5.2 Grammar 约束 —— 结构化输出的暴力控制
让 LLM 的输出像数据库查询一样精确:
// 一键 JSON 模式
ChatRequest.builder()
.jsonMode(true)
.addMessage(Role.USER, "Extract name and age from: John is 30")
.build();
// 自定义 GBNF 语法(AutoCloseable 安全生命周期)
try (GrammarConstraint gc = GrammarConstraint.create(ctx, myGbnf, "root")) {
GenerateParams params = GenerateParams.builder("Generate colors")
.grammar(gc)
.maxTokens(256)
.build();
} // gc.close() 自动释放 native 资源
5.3 生产观测 —— 8 维 Micrometer 指标体系
开箱即用的可观测性,直接接入你现有的 Prometheus/Grafana:
Metric | Type | 业务含义 |
|---|---|---|
llama4j.inference.requests | Counter | 总推理请求数 |
llama4j.inference.latency | Timer | P50/P95/P99 延迟分布 |
llama4j.tokens.prompt | Summary | Prompt token 数 |
llama4j.tokens.completion | Summary | 生成 token 数 |
llama4j.tokens.per.second | Gauge | 实时生成吞吐 |
llama4j.kv.cache.usage | Gauge | KV Cache 利用率 |
llama4j.queue.depth | Gauge | 请求队列深度 |
llama4j.inference.errors | Counter | 推理错误数 |
5.4 Session 管理 —— KV Cache 持久化
多轮对话的性能核武器:
SessionManager manager = new SessionManager(new InMemorySessionStore());
Session session = manager.createSession("qwen2.5-7b");
// 第一轮对话后 checkpoint KV cache
manager.checkpoint(session.id(), context);
// 30 分钟后恢复:KV cache 原样还原,**无需重新计算 prompt**
Session restored = manager.resumeSession(session.id(), context);
在长上下文场景中,这是10倍级性能提升的关键。
5.5 硬件感知模型选择 —— 智能量化推荐
GgufRepository repo = new GgufRepository();
// 输入模型参数量(B),自动推荐最优量化方案
String quant = repo.recommendQuantization(7.0);
// 8GB VRAM → "Q4_K_M"
// 12GB VRAM → "Q5_K_M"
// 16GB+ VRAM → "Q8_0"
// 国内优先 ModelScope,国际回退 HuggingFace
Path model = repo.resolve("Qwen/Qwen2.5-7B-Instruct-GGUF:Q4_K_M");
三分钟实战:让 Spring Boot 开口说话
Step 1:引入依赖
<<dependency>
<groupId>com.llama4j</groupId>
<artifactId>llama4j-spring-boot-starter</artifactId>
<version>1.0.0-SNAPSHOT</version>
</dependency>
Step 2:一行配置
llama4j:
model:
path: /models/qwen2.5-7b-q4_k_m.gguf
n-ctx: 4096
n-gpu-layers: -1 # -1 = 全部 offload 到 GPU
n-threads: 8
Step 3:直接调用
curl -X POST http://localhost:8080/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"messages": [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Explain quantum computing in one paragraph."}
],
"temperature": 0.7
}'
没有 Python。没有 Docker。没有 sidecar。
这就是 Java 开发者应得的一等公民待遇。
选型决策树:llama4j 的统治边界
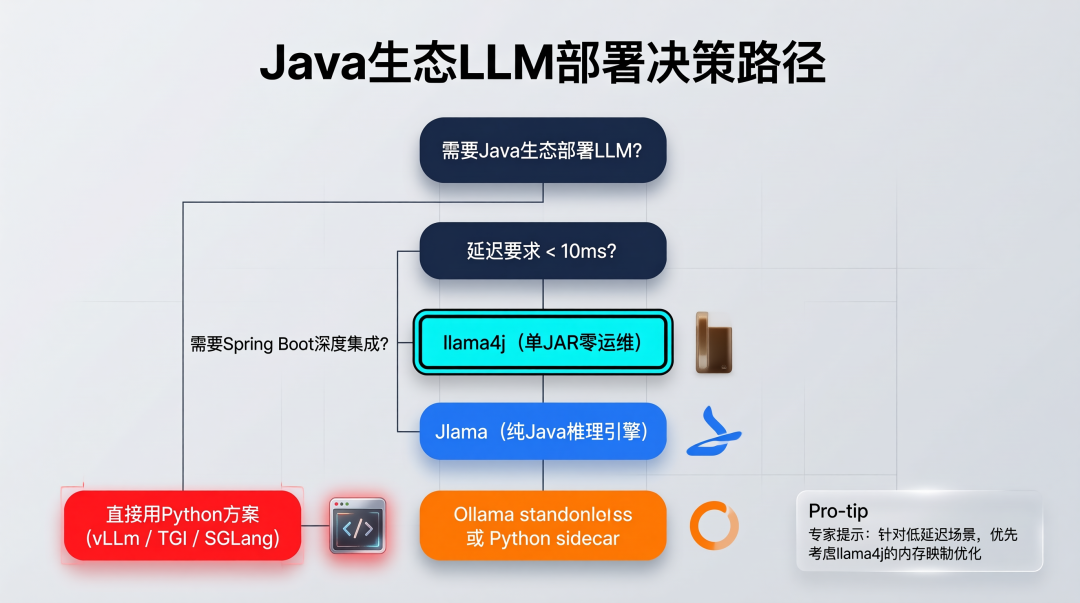
场景 | 最优解 | 理由 |
|---|---|---|
Spring Boot 单体 / 微服务 | llama4j | Auto-config + Actuator + DI 三位一体,零摩擦集成 |
纯 Java、无 Spring、极致控制 | Jlama | 100% Java 实现,Java 21 Vector API 加速 |
快速原型 / 个人开发 | Ollama | 开箱即用,但需额外 HTTP 调用层 |
高吞吐 GPU 集群 | vLLM | PagedAttention + 连续批处理,但需 Python 栈 |
性能参数调优
llama4j 的 JNI 层预编译了全平台 native 库:
平台 | GPU Backend | 库文件 |
|---|---|---|
macOS (Apple Silicon / Intel) | Metal | .dylib |
Linux (x86_64) | CUDA / Vulkan / CPU | .so |
Windows (x86_64) | CUDA / CPU | .dll |
构建命令:
# macOS Apple Silicon + Metal
./scripts/build-native.sh --classifier macos-aarch64 --gpu metal
# Linux CUDA
./scripts/build-native.sh --classifier linux-x86_64 --gpu cuda
生产环境黄金参数:
llama4j:
model:
n-ctx: 4096 # 根据实际 prompt 长度调整,避免内存浪费
n-gpu-layers: -1 # -1 = 全部 offload 到 GPU,VRAM 充裕时首选
n-threads: 8 # CPU 推理时设为物理核心数
batch-size: 512 # 批处理大小,影响吞吐
rope-freq-base: 10000 # RoPE 频率,长上下文模型需调整
结语:Java 工程师的 LLM 主权宣言
llama4j 不是一个「让 Java 能调用 Python」的妥协方案。它是一个主权宣言——宣告 Java 生态在 LLM 推理领域拥有与 Python 同等的、甚至更高效的技术话语权。
对于深耕 Spring Boot 的企业级开发者,这意味着:
- 不再维护两套 Docker 镜像
- 不再为跨语言链路写熔断降级
- 不再让 Python runtime 吃掉 200MB 内存
- 不再忍受 JSON 序列化的性能损耗
Stop stitching together Python microservices. Run LLM inference where your Java code lives.
一个 JAR 包。一个进程。Zero DevOps overhead。
这就是 llama4j 的暴力美学。
GitHub:github.com/javpower/llama4j
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-21,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号