从RAG到CAG,面向性能的提升

从RAG到CAG,面向性能的提升

半吊子全栈工匠
发布于 2026-06-15 12:22:13
发布于 2026-06-15 12:22:13
那么对于基于大模型的RAG 应用,有没有相关的性能优化手段呢?
KV缓存是现代大模型服务方式的基础实现细节,在KV缓存中,各个注意力层的键和值被保存,有效地保存了整个模型的中间表示,以便可以用于进一步的自回归生成传递。
CAG 提供了一种替代检索增强生成的范式。其工作原理是将所有相关知识预加载到 LLM 的扩展上下文中,而不是从知识库中检索它,并在推理时使用它来回答查询。
1. CAG实验的环境设置
确保已经安装了必要的库:
#!pip install -U bitsandbytes
import torch
from transformers import (
AutoTokenizer,
BitsAndBytesConfig,
AutoModelForCausalLM)
import bitsandbytes as bnb
from transformers.cache_utils import DynamicCache登录HuggingFace生成一个访问令牌:
from huggingface_hub import notebook_login
notebook_login()加载分词器和4-bit 模型:
bnb_config = BitsAndBytesConfig(
load_in_4bit=True,
bnb_4bit_use_double_quant=True,
bnb_4bit_quant_type="nf4",
bnb_4bit_compute_dtype=torch.bfloat16)
model_id = "meta-llama/Meta-Llama-3.1-8B-Instruct"
tokenizer = AutoTokenizer.from_pretrained(model_id)
model = AutoModelForCausalLM.from_pretrained(
model_id,
quantization_config=bnb_config,
device_map='auto')2.CAG实验的知识准备
这些信息包括与医疗器械相关的模拟临床报告和事件,所有这些数据都是完全合成的,并非基于真实事件。这些知识对于医疗器械领域来说是非常具体的。一个标准的、经过预先培训的 LLM 在没有得到这个上下文的情况下不能回答关于这些报告的问题。换句话说,模型需要这些特定的知识来理解和响应关于报告的问题。
创建一个简单的函数,将准备好的知识预加载到模型中。该过程利用了HuggingFace的动态缓存机制 (特别是键值缓存) 来高效地存储处理后的知识。这个预加载步骤对于缓存增强生成 (CAG) 是至关重要的,它允许模型 “记住” 知识并避免推理过程中的冗余计算。
该函数实质上是将准备好的知识文本作为输入,通过模型进行一次处理。然后将注意力层产生的KV状态存储在缓存中。随后的查询可以利用这些缓存的信息,大大加快生成过程。本质上,该函数返回表示预处理知识的 “键” 和 “值”,以便在生成阶段使用。这就是模型如何有效地合并外部知识,而不必为每个新查询重新处理它。
def preprocess_knowledge(
model,
tokenizer,
prompt: str) -> DynamicCache:
"""
Prepare knowledge kv cache for CAG.
Args:
model: HuggingFace model with automatic device mapping
tokenizer: HuggingFace tokenizer
prompt: The knowledge to preprocess, which is basically a prompt
Returns:
DynamicCache: KV Cache
"""
embed_device = model.model.embed_tokens.weight.device # check which device are used
input_ids = tokenizer.encode(prompt, return_tensors="pt").to(embed_device)
past_key_values = DynamicCache()
with torch.no_grad():
outputs = model(
input_ids=input_ids,
past_key_values=past_key_values,
use_cache=True,
output_attentions=False,
output_hidden_states=False)
return outputs.past_key_values3.创建键值缓存数据
在生成KV缓存数据之前,我们需要格式化提示词并向模型提供指令。这个提示次的结构 (包括任何特定的指令或特殊的标记) 是至关重要的,并且严重依赖于所选择的模型。不同的LLM有不同的输入要求。有些模型使用唯一的特殊标记 (如 < s> 、[CLS] 或 ) 来表示序列的开始、分离输入的不同部分或发送特定任务的信号。因此,根据使用的特定模型定制提示词和说明是非常重要的。
在示例中,将根据所使用的模型 (假设是 Llama-3.1-Instruct) 的要求格式化提示和指令。这将确保模型正确地处理知识并生成适当的 KV 缓存数据。
def prepare_kvcache(documents, answer_instruction: str = None):
# Prepare the knowledges kvcache
if answer_instruction is None:
answer_instruction = "Answer the question with a super short answer."
knowledges = f"""
<|begin_of_text|>
<|start_header_id|>system<|end_header_id|>
You are an medical assistant for giving short answers
based on given reports.<|eot_id|>
<|start_header_id|>user<|end_header_id|>
Context information is bellow.
------------------------------------------------
{documents}
------------------------------------------------
{answer_instruction}
Question:
"""
# Get the knowledge cache
kv = preprocess_knowledge(model, tokenizer, knowledges)
kv_len = kv.key_cache[0].shape[-2]
print("kvlen: ", kv_len)
return kv, kv_len
knowledge_cache, kv_len = prepare_kvcache(documents =knowledge)在预加载知识到键值缓存之后,存储它的长度。为了为后续查询维护一致的上下文,每次查询之后将 KV 缓存截断回原来的长度。这可以确保每个查询操作预期的知识库,防止查询之间不必要的交互。
4.查询回答
将知识预加载到 LLM 的 KV缓存中之后,现在就可以回答有关报告的问题了。关键的第一步是实现一个 clean_up 函数。上面已经描述过,这个函数将负责在每次查询之后将 KV 缓存恢复到其原始状态 (仅包含预加载的知识)。
def clean_up(kv: DynamicCache, origin_len: int):
"""
Truncate the KV Cache to the original length.
"""
for i in range(len(kv.key_cache)):
kv.key_cache[i] = kv.key_cache[i][:, :, :origin_len, :]
kv.value_cache[i] = kv.value_cache[i][:, :, :origin_len, :]这个函数处理预测过程,包括使用预加载的知识 (存储在 KV 缓存中) 来回答查询:
def generate(
model,
input_ids: torch.Tensor,
past_key_values,
max_new_tokens: int = 300
) -> torch.Tensor:
"""
Generate text with greedy decoding.
Args:
model: HuggingFace model with automatic device mapping
input_ids: Input token ids
past_key_values: KV Cache for knowledge
max_new_tokens: Maximum new tokens to generate
"""
embed_device = model.model.embed_tokens.weight.device
origin_ids = input_ids
input_ids = input_ids.to(embed_device)
output_ids = input_ids.clone()
next_token = input_ids
with torch.no_grad():
for _ in range(max_new_tokens):
outputs = model(
input_ids=next_token,
past_key_values=past_key_values,
use_cache=True
)
next_token_logits = outputs.logits[:, -1, :]
next_token = next_token_logits.argmax(dim=-1).unsqueeze(-1)
next_token = next_token.to(embed_device)
past_key_values = outputs.past_key_values
output_ids = torch.cat([output_ids, next_token], dim=1)
if (next_token.item() in model.config.eos_token_id) and (_ > 0):
break
return output_ids[:, origin_ids.shape[-1]:]现在已经准备好开始预测过程。这涉及到使用预加载的知识 (有效地存储在键值 (KV) 缓存中) 来生成对用户查询的答案。
query = 'my query is .....'
clean_up(knowledge_cache, kv_len)
input_ids = tokenizer.encode(query, return_tensors="pt").to(model.device)
output = generate(model, input_ids, knowledge_cache)
generated_text = tokenizer.decode(output[0], skip_special_tokens=True, temperature=None)
print(f"Response of the model:\n {generated_text}")5. RAG与CAG的比较
RAG 和 CAG 的主要目标都是通过集成外部知识来增强语言模型。简而言之,RAG 的策略包括将外部知识编码为矢量存储在矢量数据库中。在查询 LLM 之前,还将输入查询编码为向量,并检索与查询向量相似度最高的知识向量。然后,将检索到的信息添加到给 LLM 的提示中以生成响应。这种方法非常强大,理论上可以扩展到非常大的知识源。然而,它在文档选择中引入了潜在的问题,这取决于文档的分块方式和用于创建向量数据库的嵌入模型的质量。
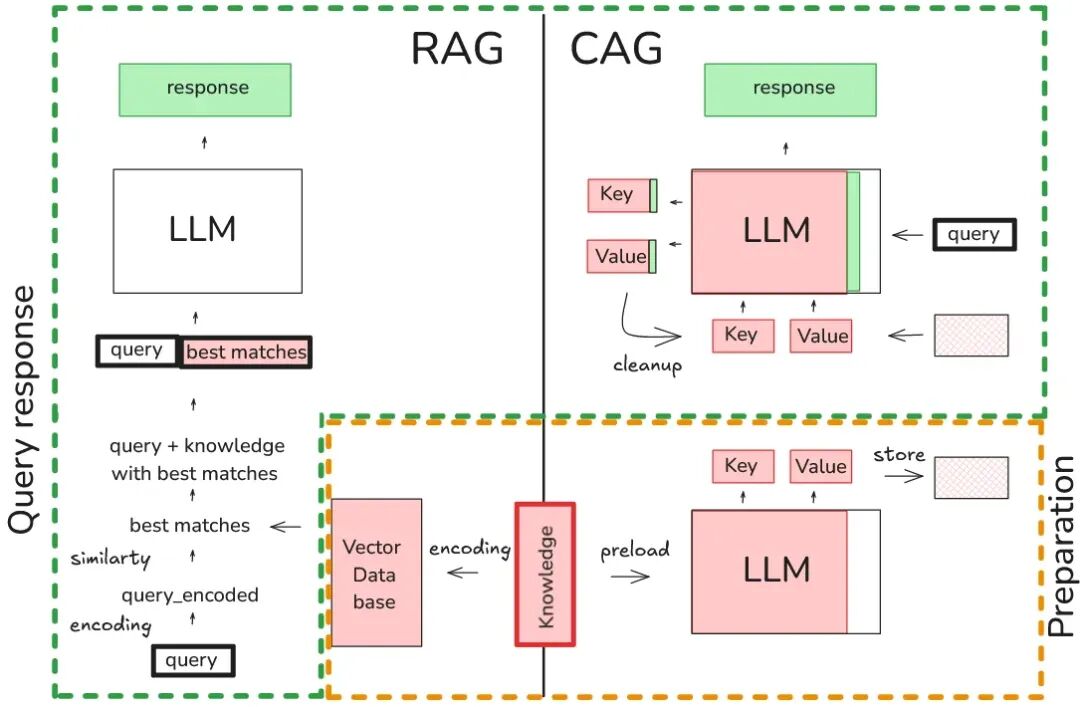
CAG 提供了一种更简单的方法。如果外部知识库具有可管理的大小,则 CAG 直接涉及将整个知识库与查询一起包含在提示词中。然后,LLM 可以处理查询和知识库以生成响应。这种策略消除了对矢量数据库和相似性计算的需要。CAG 受益于 LLM的最新进展,例如 Llama、 Mixtral 和 Gemma 等模型,它们证明了使用更大的上下文窗口可以提高性能和效率。
然而,如果 CAG 的实现很简单,在每个提示词中都包含整个知识库,那么将导致非常慢的推理时间。这是因为 llm 通常一次生成一个令牌,并且每个预测取决于整个前面的上下文。这就是 CAG 的关键创新之处: 通过将知识库预加载到模型的上下文中,并使用动态缓存策略 (特别是键值缓存) ,可以避免为每个新查询重复处理知识库。模型有效地 “记住” 处理过的知识,允许它在推理期间只关注查询。
6.小结
CAG根据预先缓存的知识生成响应。如果正在处理一个非常大的数据集 (例如,超过 1000 个示例) ,预加载模型和生成 KV 缓存变得计算成本很高。在这种情况下,强烈建议将生成的 KV 缓存数据存储到磁盘。这允许您直接加载预计算缓存,避免了每次都需要重新生成它,这对于大规模应用程序的可伸缩性非常重要。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-03-01,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号