企业级智能体与Skills管理的思考总结

企业级智能体与Skills管理的思考总结

Wangzy
发布于 2026-06-22 19:15:36
发布于 2026-06-22 19:15:36
前记:
经常被其他团队问的一句话:
"你们开发了哪些智能体?哪些可以直接给我们用?"
能给的回答只有两个:要么把低代码平台上的智能体链接发给对方让他们自己点;要么把这个智能体重新封装成一套 API 注册给对方调用。
链接没法被另一个智能体引用,API 又要走一遍鉴权与接入流程——两种方式都别扭,复用成本高得离谱。
跨平台时更难:低代码平台 A 上的智能体,没办法被高代码平台 B 上的 Agent 直接调用;MCP 网关上注册的工具,又不一定能被 Skill 引用。
这不是某一家公司独有的状况。Dify、百炼、扣子、自研 LangGraph、第三方 SaaS 各跑各的,智能体散落、技能重复、工具失管,已经是 2026 年大多数中大型企业的真实状态。
当智能体开始散落成"提示词碎片"和"平台孤岛"时,真正的问题已经不在模型层、不在工具层,而是治理层。本文要回答的核心问题就是:企业需要什么样的结构来管住这件事?
第一章:Skill 是什么——从"提示词附件"到"软件制品"
要回答治理问题,得先回到一个更基础的问题:今天行业里说的"Skill"到底是什么?
1.1 一个普通用户的 Skill 使用闭环
最近微信读书发布了一个对外的 Skill,把查书、查笔记、查阅读时长等能力打包成一个能被任意 AI 助手安装的"技能包"。它是把抽象概念讲清楚的好例子,我们顺着三张截图看一遍完整使用流程。
第一步:在微信读书 App 里看到 Skill 长什么样
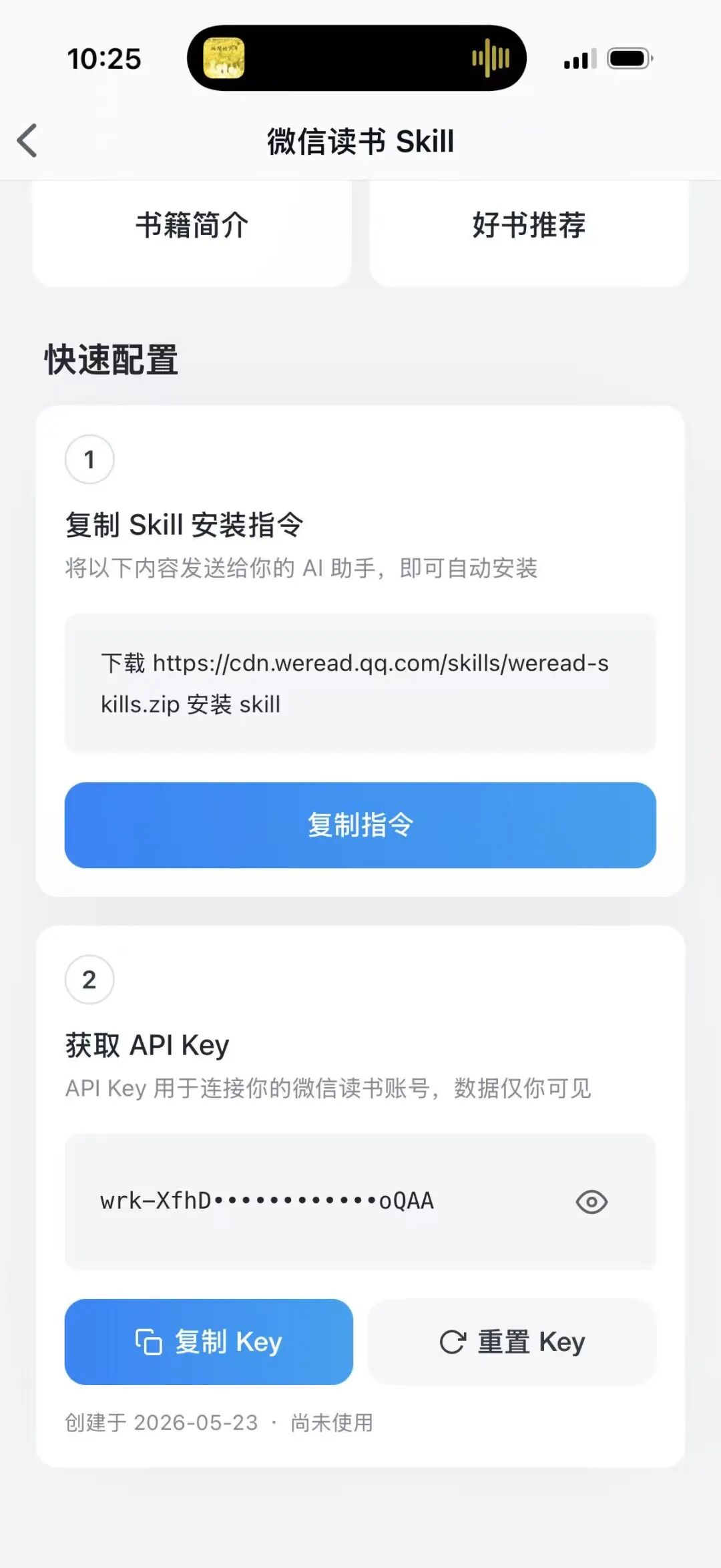
微信读书 App 内置的 Skill 配置页
页面只暴露给用户两样东西:一条安装指令(一个 zip URL),一个 API Key。这是 Skill 在"分发面"的最小表达——一个可下载的文件包 + 一段身份凭证。
第二步:把安装指令丢给 AI 助手
用户把 下载 https://cdn.weread.qq.com/skills/weread-skills.zip 安装 skill 这条自然语言指令发给 ima copilot:
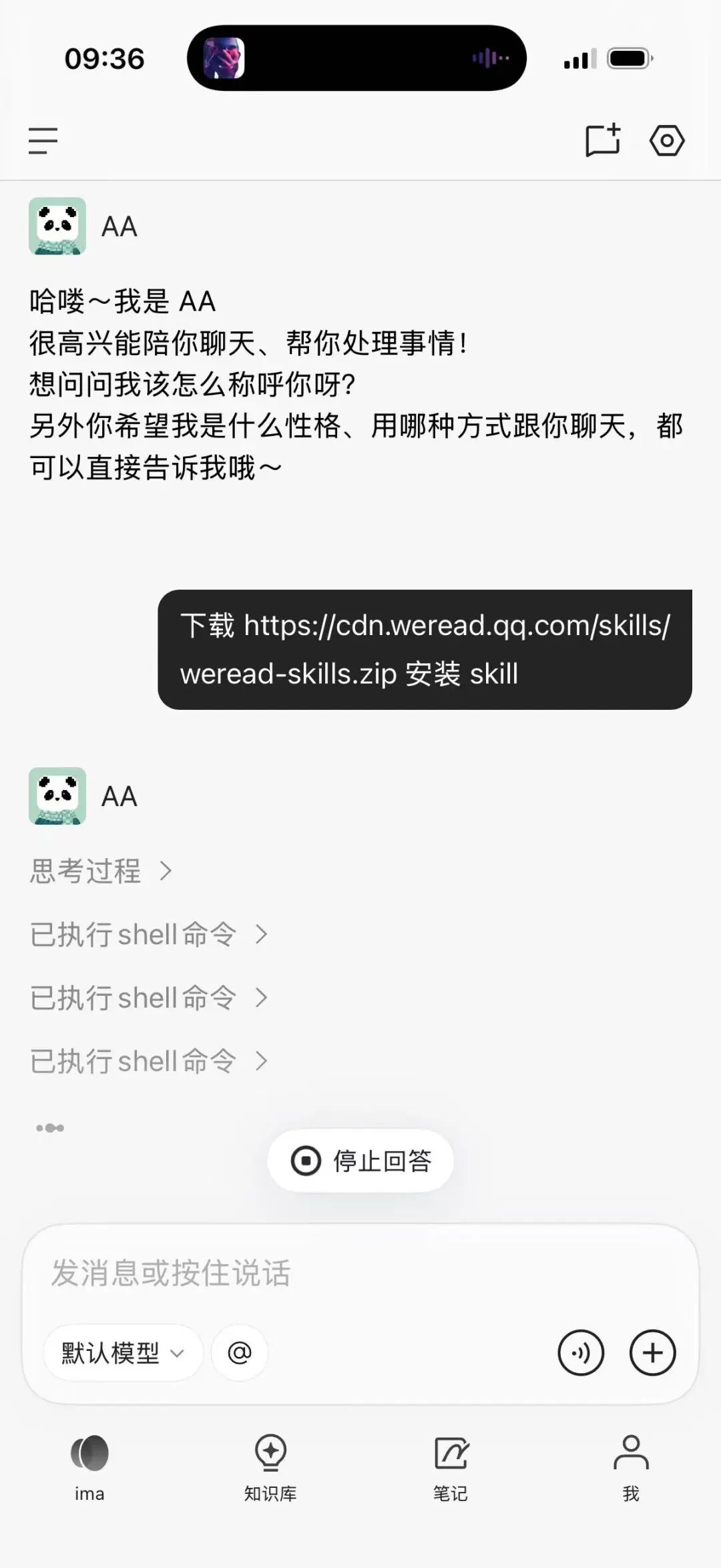
ima copilot 接收安装指令并自主执行 shell 命令
AI 助手没有问任何细节,自主完成了三条 shell 命令——下载、解压、放入指定目录。整个过程没有人工配置 JSON、没有手填环境变量、没有写胶水代码。Skill 的安装是自描述的。
第三步:直接用自然语言调用
完成安装后,用户问"我这个月读了多久":
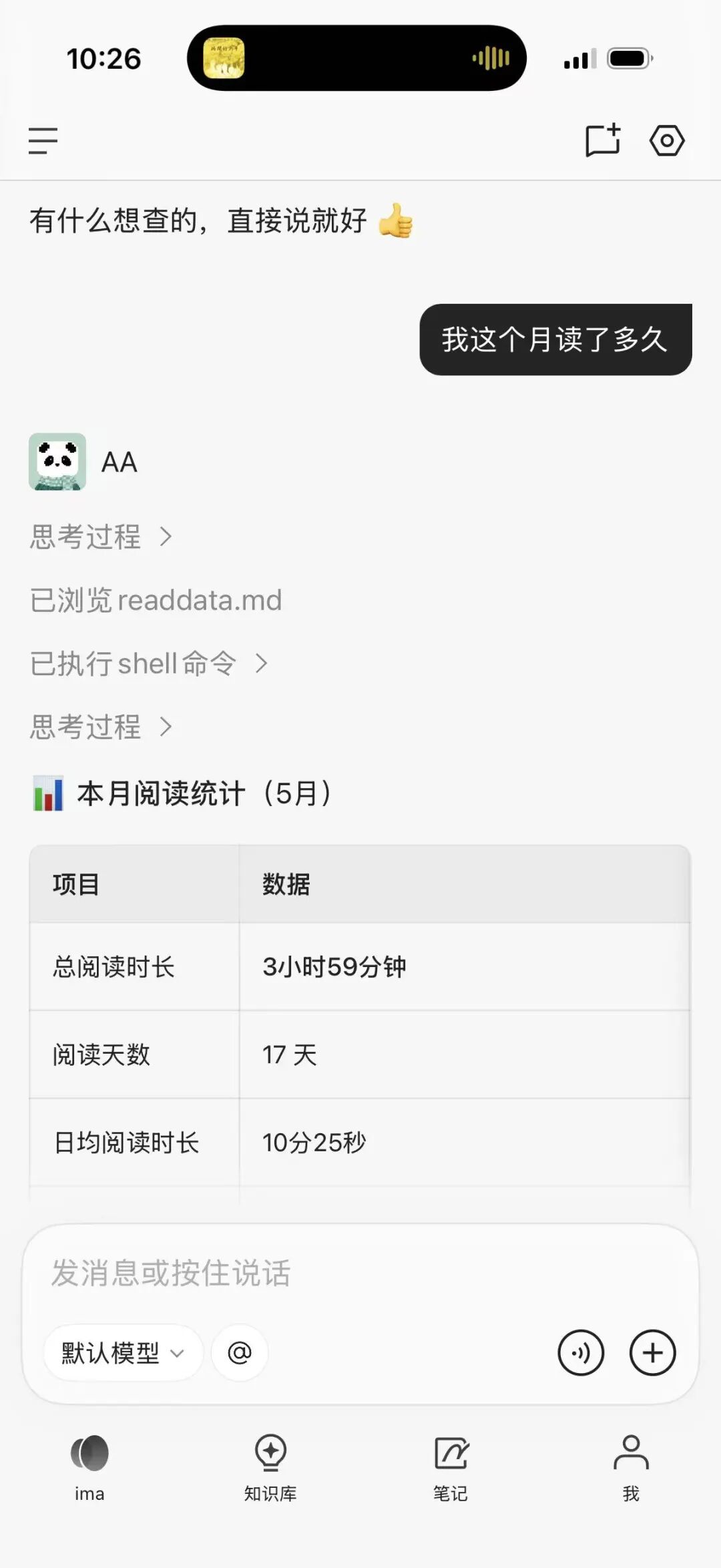
ima copilot 调用 weread Skill 返回阅读统计
AI 浏览了 Skill 包里的 readdata.md 说明文档,执行了对应的 shell 命令,返回一张结构化统计表:总阅读时长 3 小时 59 分钟、阅读天数 17 天、日均 10 分 25 秒。
这个三步闭环里有三件事值得拎出来:
- 可分发——Skill 是一个完整的、可被 URL 引用的文件包
- 自描述——文件包里的元数据告诉 AI 这是什么、怎么用
- 自包含——附带身份凭证,AI 拿到就能调,不需要二次集成
这三件事合起来,就是今天行业说的"Skill"——不是一段提示词,而是一个能被独立分发、独立调用、独立治理的能力单元。
1.2 一个被快速接受的开放标准
这种"Skill"的具体格式并不是微信读书自创,而是遵循了 Anthropic 在 2025 年 10 月 16 日发布、12 月 18 日转为开放标准的 Agent Skills 规范(agentskills.io)。
在不到三个月时间里,这套规范被 32 款 AI 工具采纳,包括 Claude Code、OpenAI Codex CLI、VS Code、GitHub Copilot、Gemini CLI、JetBrains Junie、AWS Kiro、Sourcegraph Amp、Mistral AI、Databricks、字节 TRAE 等。这是当前 Skills 领域唯一形成跨厂商共识的格式规范。
为什么是它跑出来了?因为它简单到几乎无门槛。
1.3 SKILL.md 的标准长什么样
一个 Skill 就是一个文件夹 + 一份 SKILL.md(带 YAML frontmatter) + 可选的脚本、参考资料、模板。以微信读书 Skill 为例,文件夹长这样:
weread-skills/
├── SKILL.md # 主入口:能力总览 + 通用规则
├── search.md # 搜索书籍
├── book.md # 书籍信息
├── shelf.md # 书架管理
├── readdata.md # 阅读统计
├── notes.md # 笔记划线
├── review.md # 书籍点评
├── discover.md # 推荐好书
└── profile.md # 用户画像
SKILL.md 顶部是机器可读的 frontmatter:
---
name: weread-skills
description: 微信读书助手 — 搜索书籍、管理书架、查看笔记划线、浏览书评、阅读统计、发现推荐好书
version: 1.0.3
---
这份格式背后还有个关键设计——渐进披露(Progressive Disclosure)。AI 助手不会一次性把所有子文件全部读进上下文,而是按三级触发加载:
- Discovery(发现):启动时只把所有 Skill 的
name + description注入系统提示,每个约 80 token - Activation(激活):任务匹配到某个 Skill 时,把完整 SKILL.md 主体读入上下文(平均约 2k token)
- Execution(执行):真正执行某个具体能力时,才按需加载对应的子文件(如查阅读时长加载
readdata.md)
这个机制是 Skill 区别于"塞满工具的超大 system prompt"的关键——它让一个 Skill 包里装一百个能力也不会撑爆上下文。
1.4 同一份格式,两种执行范式
但是,SKILL.md 只规定了格式,没规定执行。同样一份 SKILL.md,在不同 Skill 里指向的"能力实现路径"可以完全不同。
回头看微信读书的 SKILL.md,它的"接口调用规范"那一段写着:
POST https://i.weread.qq.com/api/agent/gateway
Authorization: Bearer $WEREAD_API_KEY
也就是说,weread-skills 的真实能力在远程 HTTP Gateway 里。AI 助手只是按 Skill 说明书构造 HTTP 请求,真正"做事"的是微信读书服务端。这是一种 API 代理型 Skill。
而 Anthropic 官方仓库里的另一些 Skill,比如 pdf-editor、md-to-html,则完全不依赖任何远程服务——它们用本地 Bash、Python 脚本组合出能力,模型本身就是执行者。这是另一种 操作手册型 Skill。
两种范式都合规、都能跑、都遵守同一份开放标准。这件事的意义在于:
标准是格式标准,不是执行标准。 同一份 SKILL.md 协议可以承载完全不同的能力实现路径——本地脚本可以,远程 API 也可以,未来还会出现更多形态。
这就给企业留出了关键的"接入弹性":内部老系统不需要重写,套一层 Skill 说明就能接入 Agent 生态;新系统不需要起一套 MCP server 也能被复用;甚至连"教 AI 怎么读公司 OKR 文档"这种纯知识型能力,也能用同一种格式封装。
1.5 一个判断的升级
理解了上面这些,就能引出本章最重要的一个观念升级:
Skill 不应被当成"提示词附件",而应被当成"受治理的软件制品"。
"提示词附件"意味着:写完就扔到某个目录里、谁想用谁拷贝、出问题没人改、没人知道总共有几份。
"受治理的软件制品"意味着:可注册、可发现、可审批、可灰度、可审计、可下线、可追溯。
这两种心态,决定了一家企业的智能体生态会走向"碎片堆"还是"中台"。
而要让"软件制品"这个定义真正立住,就需要一套配套的注册、发现、版本、生命周期、权限机制。而且这个机制不止要管 Skill,还要同时管它依赖的 Agent 和 Tool——这正是接下来要展开的"统一治理控制面 + 三类资产中心"的全部内容。
第二章:为什么需要"统一治理控制面"
前记里那个"链接分享 + API 注册"的别扭,本质上是 三类资产同时散落 的典型症状:
- Agent 散落——Dify、百炼、扣子、自研 LangGraph 各跑各的,谁也不知道总共有几个、各自跑得怎么样
- Skill 散落——同一个能力(发票提取、报销审核、客户画像)被三五个团队重复实现,互相不知道对方的存在
- Tool 散落——每个平台连各自的 MCP server 和内部 API,权限分散,谁能调谁、谁说了算
而且这三种散落是 相互拖垮 的:
- Agent 看着可控,可调用的 Tool 实际不可控
- Skill 写得很规范,但 Skill 依赖的 Tool 权限、版本、风险等级没人统一管理
- 审计时只能看到 Agent 调用了什么,追不到 Tool 的责任人和审批状态
这就引出本章的核心判断:
大企业上 AI 应用最常见的失败模式,不是技术能力不足,而是没有人真正对某个 agent、某个 skill、某个 tool 的行为、权限、成本和生命周期负责。
要有人负责,就必须先让这三类资产从"散落"变成"可被注册、可被发现、可被追溯"的对象——它们必须先进入某个"治理控制面",被那里的注册中心收下来。
国际四大厂商已经在走这条路
不同口径,同一方向:
- AWS:Bedrock AgentCore Gateway + Agent Registry(2025-10-13 GA),统一目录原生支持 MCP / A2A,可注册自建与第三方 Agent
- Google Cloud:Gemini Enterprise Agent Platform = Agent Registry + ADK + Managed Agents + MCP + A2A 较完整 substrate;未注册资源默认阻断
- Microsoft:Entra Agent ID 自动为每个 Agent 颁发企业身份,Foundry + Copilot Studio 双平面通过 A2A 互联
- 华为云 Versatile:资产中心可跨空间复用 App / MCP / Plugin / Prompt + MCP 市场 + 模型中心——国内最接近"完整 Agent 治理面"的方案
注意:这些"中央目录"不是某一家厂商的产品特性,而是企业级智能体落地的 共同方向——四大厂商都把 Registry / Catalog 升到了与产品同等的战略地位。
国内金融行业的数据更能说明问题
银行 | 智能体规模 | 关键数据 |
|---|---|---|
工商银行"工银智涌" | 1,000+ 专业智能体 | 日均 800 亿 token 消耗,累计调用 15 亿次 |
建设银行"方舟计划" | 193 场景 | 7,000+ 研发技能 |
邮储银行"邮智" | 230+ 场景 | 邮小宝(投行询价效率 +95%),智能审贷助手日均 3 万笔 |
浦发银行 + 火山引擎 | 2 个月孵化 1,026 个智能体 | 处理时长从 30 分钟降至 6 分钟 |
数字看起来很亮,但所有这些银行公开披露的 共同痛点都是同一个:智能体散落在各业务条线、缺乏统一注册/发现/审计。建行 7,000+ 技能里有多少是重复的?工行日均 800 亿 token 里有多少是低质量重复对话?没人能准确回答。
散落不是"没起步"的问题,而是"起步太快、治理跟不上"的问题。智能体越多,治理面越缺失,浪费越严重。
所以控制面要管的不止 Agent 和 Skill,还有 Skill 真正去触发的 MCP Tool。三类资产共同构成一个闭环——
- Agent 决策"做不做"
- Skill 规范"怎么做"
- Tool 执行"调什么系统、查什么数据、做什么动作"
任何一类不进治理面,闭环都不完整,企业最终还是会回到"碎片堆"。下一章详细讲,这个控制面怎么搭、和数据面怎么分。
第三章:核心架构观——统一治理控制面 + 三类资产中心
先看一张全景图。后面所有讨论都围绕这张图展开。
┌──────────────────────────────────────────────────────┐
│ 业务体验层(手机端 / Web / 飞书 / 钉钉 / 监管报送) │
└──────────────────────────────────────────────────────┘
│ A2A / OpenAPI / WebSocket
▼
┌──────────────────────────────────────────────────────┐
│ 统一治理控制面 (Control Plane) │
│ ┌────────────┐ ┌────────────┐ ┌────────────────┐ │
│ │ Agent │ │ Skills │ │ MCP Tool │ │
│ │ Registry │ │ Registry │ │ Registry │ │
│ └────────────┘ └────────────┘ └────────────────┘ │
│ + 统一编排 API(A2A 兼容)+ 评测流水线 + 灰度发布 │
│ + 合规中心(算法备案 / 内容标识) │
└──────────────────────────────────────────────────────┘
│ MCP / A2A
▼
┌──────────────────────────────────────────────────────┐
│ 数据面 (Data Plane) │
│ ┌──────────┐ ┌──────────┐ ┌────────┐ ┌──────────┐ │
│ │ 高代码 │ │ 低代码 │ │ 第三方 │ │ 遗留 │ │
│ │ LangGraph│ │ 百炼/扣子 │ │ SaaS │ │ API │ │
│ └──────────┘ └──────────┘ └────────┘ └──────────┘ │
│ + 企业级 MCP Gateway(运行时鉴权 / 限流 / 熔断 / 审计) │
└──────────────────────────────────────────────────────┘
│
▼
┌──────────────────────────────────────────────────────┐
│ 基础设施(IAM / API Gateway / 日志 / 监控 / 密评) │
└──────────────────────────────────────────────────────┘
这张图里有三件最关键的事,必须逐一讲清楚。
3.1 控制面包含三类资产中心
控制面不是某一个具体的服务,而是 三个分管不同资产类型的注册中心 + 一组横向治理能力:
- Agent Registry——智能体注册中心。负责能力注册、发现、版本、责任人、审批、上下架。每个 Agent 上线必须推送一份 AgentCard 到这里。
- Skills Registry——技能仓库。负责领域知识、操作手册、流程经验的结构化沉淀。每个 Skill 都是一个签名的 SKILL.md 包。
- MCP Tool Registry——工具治理中心。负责工具元数据、归属、版本、权限、风险等级、输入输出 Schema、调用审计与生命周期。
围绕这三个中心还有四组横向能力:统一编排 API(A2A 兼容)、评测流水线(pre-release gate)、灰度发布与紧急下架、合规中心(算法备案 / 内容标识对接)。
3.2 MCP 的"两副面孔"必须分清
这是企业架构师最容易踩坑的地方——"MCP" 不是一个东西,是两个东西:
MCP Gateway | MCP Tool Registry | |
|---|---|---|
位置 | 数据面(运行时) | 控制面(治理面) |
负责什么 | 工具调用瞬间的鉴权、限流、熔断、防注入、Token 经济、审计 | 工具元数据、归属、版本、权限、风险等级、依赖关系、审批、退役 |
触发时机 | 每次 Agent 调用 Tool | Tool 上线、变更、退役 |
关键能力 | 实时拦截 | 一次注册、长期治理 |
很多企业把 MCP 当成"工具接入层"——只建了网关,没建注册中心。结果是:
- 网关只能拦截"已知的"调用,不知道全公司一共有几个 Tool
- Tool 没有责任人,出问题找不到负责团队
- 同一个内部 API 被三个团队各自包了三个 MCP server,描述不一致、参数错位
- 升级时下游 Agent 全部隐式失败,故障像幽灵一样飘
网关解决的是"调用瞬间的合规",注册中心解决的是"工具作为企业资产的责任归属"。两者必须分开建,缺一不可。
3.3 五条核心设计原则
- 控制面与数据面分离——所有平台(Dify / 百炼 / 扣子 / LangGraph / 自研)都只是"数据面 Worker",控制面唯一负责"谁能注册、谁能调用、谁能下架"
- 元数据强制规范——上线 = 推送三件套(AgentCard / SKILL.md / MCP Tool Manifest)到对应 Registry;未注册不得进入生产
- 三层鉴权——用户身份(OIDC / Entra)→ 智能体身份(Entra Agent ID / DID:WBA)→ 工具身份(MCP 网关 OAuth),层层落地
- 策略与推理解耦——所有写操作(写库、转账、发邮件)由网关在 LLM 推理回路之外做确定性鉴权,杜绝"通过 Prompt 绕过"
- 可观测性贯穿——OTel 是标准,每一次智能体调用必须有 trace_id,与企业等保审计日志联动
3.4 三个"不要做"
- 不要把控制面建在任何一个开发平台内部——平台是数据面,控制面建在平台内部 = 换平台就换治理
- 不要把 Skills 与 Agent 强绑定——开放标准的核心价值是跨平台复用
- 不要把 MCP 仅当作技术接入层——它是真正高风险动作的发生地,必须有治理身份
第四章:元数据三件套——三类资产 × 三套规范
控制面三个资产中心,对应着行业里已经形成共识的三套元数据规范。这是企业级智能体治理真正的基石。
资产中心 | 元数据规范 | 由谁制定 | 内容形式 |
|---|---|---|---|
Agent Registry | AgentCard(A2A 协议) | Linux 基金会(A2A.org) | JSON @ /.well-known/agent.json,描述身份、能力、技能列表、认证方式 |
Skills Registry | SKILL.md(Anthropic Agent Skills) | Anthropic + 社区开放标准 | 文件夹 + SKILL.md(YAML frontmatter)+ 渐进披露子文件 |
MCP Tool Registry | MCP Tool Manifest | Anthropic(2024-11 提出) | JSON-RPC schema,描述 Tool 输入输出、调用约束 |
4.1 三者的职责分层
只看格式还不够,关键是想清楚三者在调用链上的分工:
用户意图 → Agent 决策"做什么任务"
└─ AgentCard 说: 我能干什么
▼
Agent 选 Skill
└─ SKILL.md 说: 这件事怎么做
▼
Skill 触发 MCP Tool
└─ Tool Manifest 说: 真正调什么、传什么参数
▼
Tool 改变世界状态(写库 / 发邮件 / 查接口)
换一种说法:
- Agent:"由什么能力组成"——身份和能力集合
- Skill:"怎么做"——工作流知识、操作手册,可触发一组 MCP Tool
- MCP Tool:"做什么"——可执行函数,真正改变世界状态的那一层
- Function Calling:模型层原语,所有上面的最终落到这里
- Plugin:厂商私有封装,不开放、不可移植
理解这个层次很重要——它解释了为什么三件套缺一不可:
- 只有 AgentCard 没有 Skill:Agent 不知道"具体步骤"
- 只有 Skill 没有 Tool Manifest:AI 知道"该调什么"但不知道"参数怎么传"
- 只有 Tool Manifest 没有 Skill:AI 知道有这个工具,但不知道"什么时候、怎么组合用"
4.2 五协议横向对比
企业讨论里常被混淆的协议除了上面三个,还有 ANP 和 OpenAPI:
AgentCard | MCP Tool | SKILL.md | ANP | OpenAPI | |
|---|---|---|---|---|---|
定位 | Agent 能力发现 | Tool 能力描述 | Skill 专长(Procedural Knowledge) | 跨企业 Agent 互联 | 传统 API 描述 |
格式 | JSON | JSON-RPC schema | 文件夹 + Markdown | JSON-LD over HTTP | YAML/JSON |
认证 | Bearer/OAuth/APIKey | OAuth/API Key | 平台层 | W3C DID + 端到端加密 | OAuth |
托管 | Linux Foundation | Anthropic + 社区 | agentskills.io | W3C CG | OpenAPI Initiative |
企业建议 | 首选元数据协议 | 首选工具协议 | 首选 Skill 协议 | 跨机构联邦备选 | 必备底层 |
企业内部一律以 "AgentCard 描述 Agent + SKILL.md 描述 Skill + MCP Manifest 描述 Tool" 三件套作为强制元数据规范,OpenAPI 用于对接遗留系统,ANP 用于未来跨机构互联预研。
4.3 一个关键判断
协议开放是基石。三件套 ↔ 三资产中心的对称结构,是企业治理的真正底座。 但协议只解决"长什么样",不解决"上线后怎么管"——下一章讲生命周期。
第五章:Skill 的版本与生命周期管理
一个 Skill 上线后,会经历更新、依赖变化、被新 Agent 引用、最终退役。如果只有"上传入口"没有"生命周期管理",Skill 中台在 6 个月内必然腐化成"无主代码堆"。
这一章以 Skill 为主线讲生命周期管理。这套方法学同样适用于 Agent 和 Tool,但 Skill 是企业里数量增长最快、最容易失控的资产,所以最值得讲透。
5.1 完整生命周期 8 个阶段
创建/注册 → 评测/审批 → 发布/灰度 → 版本演进
↑ ↓
←─ 归档 ← 退役/下线 ← 变更管理 ← 依赖管理
分配 skill_id,提交初版元数据(owner、business_domain、risk_tier 必填)5.2 双版本指针:default_version 与 latest_version
OpenAI Skills 的成熟实践是同时维护两个指针:
- default_version:稳定生产版本,默认被所有 Agent 调用
- latest_version:最新发布版本,可被显式指定(如
weread-skills@latest)用于试用
双轨制的好处:新版本可以先以 latest_version 发布,少数 Agent 试用一段时间,验证稳定后再把 default_version 切到新版。下游不知情的 Agent 不会被新版本的 bug 误伤。
5.3 紧急下架的"一键熔断"
Registry 必须提供 30 秒内禁用任一 Skill / Tool 所有调用的能力。
这不是"加分项",是合规要求。监管"清源行动"式突发检查会要求"立即停用某个能力",没有熔断能力就只能拔网线。
熔断触发后,下游 Agent 应该回退到 fallback skill 或显式失败提示——绝不能"静默继续用旧版本"。
5.4 三层分发覆盖完整生命周期
Anthropic 的三层分发结构正好对应生命周期的三个阶段:
- 个人级(
~/.claude/skills/):开发者本地试用——对应"创建/注册"前的探索期 - 项目级(
.claude/skills/):随代码版本化、跟 PR 走评审——对应"评测/审批"阶段 - 企业级(managed settings 下发):经过完整评测/审批的全员可用 Skill——对应"发布/灰度"之后的运行期
这个分层让 Skill 的成熟度自然递进,避免"个人未验证的玩具直接进生产"。
5.5 一个判断
Skill 发布流程必须像服务发布流程一样——有基线、有门槛、有回滚。 没有生命周期管理的 Skill 中台,6 个月内必然腐化成"无主代码堆"。
第六章:让"全员沉淀 Skills"真正跑起来
控制面架构搭好、版本机制建好之后,剩下的关键问题是:怎么让全员真正参与进来?
一个 Skills 中台最容易失败的地方,是把"中台"等同于"上传入口"——开放一个 Web 表单让员工提交 SKILL.md 包,然后期待数百个高质量 Skill 自然涌现。
实际会发生的是:
- 头 3 个月:热心员工上传 50+ Skill,大部分描述潦草,AI 无法正确识别
- 6 个月后:库里有 200+ Skill,但 80% 没人用过——因为"找不到"或"不知道怎么调"
- 1 年后:没人愿意上传新 Skill——"反正也没人用"
要避免这个剧本,必须解决三个机制问题。
6.1 发现机制:让 AI 能找到正确的 Skill
当 Skill 库超过 30-50 个,纯靠 LLM 推理选择会失准——这是一个有"相变点"的现象。
Anthropic 官方建议的渐进披露能解决一部分:Discovery 阶段只注入每个 Skill 的 name + description(约 80 token)。但当 Skill 数量到 100+ 时,1.4k token 的描述池本身就成了上下文负担,且模型选择准确率会断崖式下降。
这时必须引入 embedding-based 检索(RAG 层):对每个 Skill 的 description 做 embedding,根据用户输入语义匹配 top-K 候选,再注入系统提示。
这件事的工程结论很反直觉:
决定一个 Skill 能不能被用起来的,不是它的实现质量,而是它的 description 写得够不够好。
description 是召回率的全部来源。中台必须有一个"description 质量门禁"——含糊不清的 description 在评测阶段就要被打回。
6.2 质量门禁:三段式不可省
Skill 发布流程必须经过三道门:
- 离线评测:用预置测试集回归 Skill 功能、安全性、合规性。未通过不进入下一步。
- 线上灰度:通过的 Skill 先发到 canary 环境,限定 ≤5% 的 Agent 调用。
- 运行期反馈:监控调用成功率、错误模式、用户负面反馈,指标异常自动触发回滚。
三道门跳过任何一道都是灾难——
- 跳过离线:低质量 Skill 直接污染生产
- 跳过灰度:一次性影响所有 Agent,故障域大到不可控
- 跳过运行期反馈:问题 Skill 一直在跑,但没人知道
6.3 激励机制:把"沉淀"做成内部市场
仅靠"领导要求"驱动的 Skill 沉淀不可持续。可参考阿里百炼"应用广场"、蚂蚁 Tbox"智能体市场"的做法:
- 每个 Skill 注册时绑定原始作者团队
- 按月度调用量、跨团队复用次数计算积分
- 积分定期结算成绩效或预算
这个机制的本质是把 Skill 当成"公司内部的开源贡献"——让贡献者获得可见的回报,让使用者承认贡献的价值。
6.4 Subagent 还是 Skill?取舍指南
这是经常被混淆的问题。判断标准:
- 用 Subagent:任务需要独立的上下文窗口、独立的模型选择、长时间运行的子工作流
- 用 Skill:任务是一组指令 + 资源 + 脚本,可以在父 Agent 的上下文里执行
LangChain 的实战建议很务实:先用单 Agent + 好的提示,再加工具,再加 Skill,最后才加 Subagent。
6.5 一个判断
全员参与不是"全员上传",而是"业务方在低代码平台搭 → 推送至 Registry → 自动评测 → 治理委员会审批 → 灰度发布"的标准化流程。 Skills 中台的真正价值不在于"沉淀了多少",而在于"沉淀的能不能被找到、被复用、被改进"。
第七章:安全与治理的硬底线
回到本文一直强调的判断:真正高风险的动作往往不在 Agent 本身,而在 Agent 调用的 Tool。
- 查询客户信息——Tool
- 修改生产配置——Tool
- 执行自动化任务——Tool
- 发起审批流——Tool
- 调用交易 / 风控 / 营销系统——Tool
- 写数据库、发邮件、触达客户——Tool
如果 Tool 治理只停留在网关层(运行时拦截),不进入注册层(资产治理),Agent 看着可控,可调用的工具范围实际不可控——任何一个团队搭一个 MCP server 就可能把高敏数据暴露给上百个 Agent。
7.1 四层防线
层 | 关键能力 |
|---|---|
身份与最小权限 | 用企业身份(Entra ID/RBAC、SPIFFE)替代裸 API Key;OBO 或用户委托凭证 |
策略与审批 | 敏感动作走审批流;外部 MCP 默认禁用、按白名单启用;策略网关 + 自然语言约束 |
执行隔离 | bash / 文件 / 浏览器进沙箱(gVisor / Firecracker);默认禁出网 |
审计与可观测性 | 每次调用必须有 trace_id + actor_id + policy_verdict + 数据分类标签 |
7.2 授权升级:从 Agent 到 Action
权限矩阵必须落到调用面,而不是停留在"谁能访问聊天界面"。
传统做法是"按 Agent 授权"——允许某个 Agent 调用某组工具。但实际场景里,同一个 Agent 调用同一个工具,做不同动作时风险差异巨大:
- 调"客户信息查询"Tool 的"读账户余额"——L1 低风险
- 调"客户信息查询"Tool 的"导出全量客户列表"——L3 高风险
授权必须细到 tool / skill / action / path 这一层。
7.3 默认安全策略五条
- 可执行技能一律进沙箱
- 默认无外网(按 allowlist 开放)
- 默认只读(写操作单独审批)
- 默认禁密钥直传
- 默认手动审批高影响动作
这五条是企业 AI 系统的"天条"——任何一个 Skill / Tool 的发布默认遵循这五条,要破例必须显式申请并被记录。
7.4 三层治理映射
层 | 框架 | 作用 |
|---|---|---|
第一层 | ISO/IEC 42001 | AI 管理体系,确保治理被纳入组织级制度 |
第二层 | NIST AI RMF GAI Profile | Govern / Map / Measure / Manage 四类动作的具体实践 |
第三层 | 司法辖区法规 | 欧盟 AI Act、国内《标识办法》《银行业保险业数字金融实施方案》等作为外层约束 |
三层映射比单做一份"AI 政策"更易长期执行——上层是国际标准,中层是落地框架,下层是合规底线。
7.5 不能忽视的成本陷阱
Anthropic 公开数据:多智能体系统大约可能比单智能体多消耗一个数量级的 tokens。
只有当并行探索、深度研究或强领域分工带来的收益足够高,才值得承担这部分成本。否则真正的节流不是"禁用强模型",而是——
- 减少不必要的 Agent 拆分
- 减少无差别暴露工具
- 减少重复上下文
- 减少无目标的长对话
第八章:落地方法论
从"零散试点"到"受治理规模化",建议分三个阶段推进。不按时间逼进度,按出口条件解锁下一阶段——前一阶段的底座没夯实,就不要急着开下一阶段的口子。
阶段一:先建最小可用治理面
把"治理面"先立起来,让所有新上线的 Agent / Skill / Tool 都能被注册。关键动作:
- 冻结元数据三件套规范(AgentCard / SKILL.md / MCP Tool Manifest 的强制字段清单)
- 自研三个 Registry(轻量自研即可,无需重型平台)
- 现有 MCP 网关增强:集成策略引擎;网关与 Tool Registry 联动——未注册 Tool 不得被任何 Agent 调用
- 发布 3 个核心场景(客服 / 营销 / 合规)的评测金标集
进入下一阶段的条件:三类资产注册中心覆盖 ≥80% 在产对象;评测流水线接入率 ≥60%;高敏场景 Skill 100% 完成评测绑定。
阶段二:再做跨平台编排与自动化
底座立起来之后,重点解决"平台之间不通"的问题:
- 高代码(LangGraph / Dify)与低代码(百炼 / 扣子)之间实现 A2A 互调用,由控制面统一鉴权与审计
- 灰度发布与紧急下架机制全面投产
- 建立 智能体内部市场:业务方按"领域"浏览、订阅、复用智能体,激励复用而非重复开发
- 内容标识自动化(监管合规相关行业)
阶段三:最后做运营驱动与生态共建
跨平台跑通之后,把治理面变成业务价值的放大器:
- 度量 ROI(调用量、节省人力、客户 CSAT、风险事件减少率)
- 与监管沙盒对接(金融、医疗等强监管行业)
- 评估接入 ANP 等协议做 跨机构智能体协作(清算、反欺诈情报等)
- 在合规允许范围内向同业输出技术
一个关键判断
只要中央注册表、身份权限、审计观测、评测门禁这四个基础没建好,就不要大规模开放自助式 Agent build。 急于规模化等于把治理债转嫁给未来——而 AI 系统的治理债会复利增长。
结语:
回到最初的问题:智能体散落、技能重复、工具失管,企业真正缺的不是再多一个开发平台,而是一个独立于所有平台的统一治理控制面——把 Agent、Skill、MCP Tool 三类资产收进对应的 Registry,用 AgentCard / SKILL.md / MCP Tool Manifest 三套开放规范作为元数据底座,按"注册—评测—审批—灰度—审计—下架"的标准流程管起来。这件事做好的关键不在技术能力,而在有没有人真正对每一个 agent、skill、tool 的行为、权限、成本和生命周期负责。
智能体不缺。
缺的是治理。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-23,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号