Skills 如何实现精准回归测试选择

Skills 如何实现精准回归测试选择

AI智享空间
发布于 2026-06-25 19:27:16
发布于 2026-06-25 19:27:16
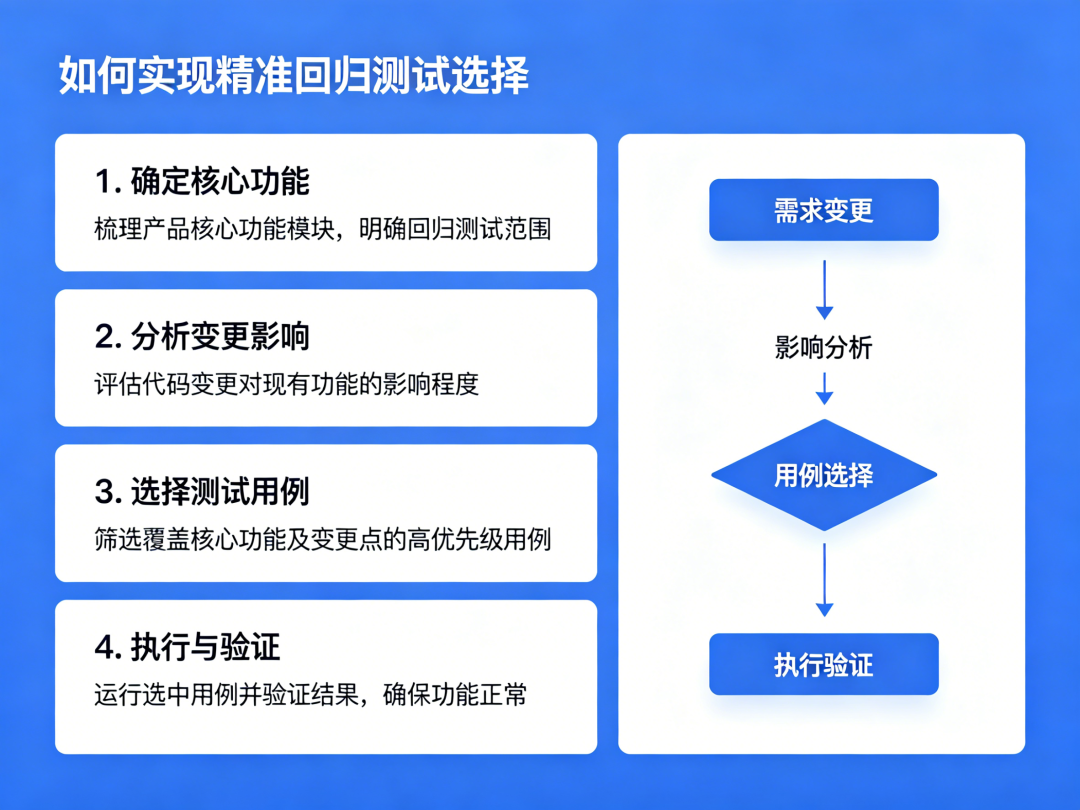
“这次改动不大,但为了稳妥,我们跑一遍全量回归吧。”
这句话在无数团队的每个发布周期里都在上演。全量回归曾经是保障质量的黄金标准,但随着系统规模膨胀、迭代节奏加快,它正在变成一个越来越沉重的负担。
某头部互联网团队曾做过统计:全量回归测试集包含 4000+ 用例,单次执行耗时 6 小时,而每次发布实际改动的代码量平均不超过整体的 5%。换句话说,95% 的测试时间花在了验证“没有变化的部分”上。
这不是效率问题,是方法论问题。全量回归的逻辑预设是“我不知道哪里会出问题,所以全测”——这本质上是一种对不确定性的妥协。而精准回归的逻辑则相反:通过分析改动影响范围,只测真正需要测的部分。
Skills 框架正是实现精准回归的关键工具。它让 AI 系统性地分析代码变更、依赖关系和历史数据,自动生成“本次发布最应该测什么”的优先级清单,把 6 小时的工作压缩到 1 小时以内,同时不降低风险覆盖率。
一、精准回归的核心挑战:影响范围识别
全量回归之所以盛行,是因为影响范围识别太难了。代码改动的影响不是线性的,它沿着调用链、依赖关系、数据流向四散传播,人工很难追溯完整。
精准回归需要解决三个核心问题:
问题一:直接影响识别 哪些测试用例直接覆盖了被改动的代码?这是最基础的映射关系,但在大型项目中,维护“用例—代码”映射关系本身就是巨大的工程量。
问题二:间接影响识别 改动了函数 A,调用 A 的函数 B 也可能受影响,调用 B 的模块 C 也可能受影响。这条传播链有多深?人工追踪极易断链。
问题三:历史风险加权 同样是“受影响模块”,历史上经常出问题的模块和从未出过问题的模块,应该分配不同的测试优先级。但这需要持续积累的历史数据支撑。
这三个问题叠加在一起,使得精准回归长期停留在“理论可行,实践困难”的阶段。Skills 的价值,在于用 AI 系统性地解决这三个问题。
二、精准回归 Skill 的设计模型:DRIFT 框架
针对精准回归的特殊需求,可以构建一个专用的分析框架——DRIFT 模型:
- D(Diff Analysis):变更差异分析——识别本次改动涉及的所有文件和函数
- R(Reachability):影响可达性分析——追踪改动沿调用链的传播深度
- I(Impact Scoring):影响评分——综合依赖度和改动规模计算影响分
- F(Failure History):历史故障加权——叠加模块历史缺陷密度
- T(Test Mapping):测试用例映射——将风险模块映射到具体测试用例
五个维度串联成一条分析流水线,输入是 Git Diff,输出是带优先级的测试用例清单。
Skill 提示词核心设计
# Skill: 精准回归测试选择
## 角色定义
你是一名精通代码架构和测试策略的高级 QA 工程师。
你的核心能力是通过分析代码变更,快速识别最小化但足够安全的回归测试范围。
## 分析流程(DRIFT 模型)
### Step 1 - Diff Analysis(变更分析)
分析提供的 Git Diff,提取:
- 改动的文件列表及改动类型(新增/修改/删除)
- 改动的关键函数/类/接口
- 改动的性质(逻辑变更/重构/配置修改/依赖升级)
### Step 2 - Reachability(可达性分析)
基于改动文件,分析:
- 直接调用者(一级影响)
- 间接调用者(二级影响,最深追踪 3 层)
- 共享数据结构/数据库表的关联模块
### Step 3 - Impact Scoring(影响评分)
对每个受影响模块打分(0-100):
- 被依赖数量权重:40%
- 改动规模权重:30%
- 改动性质权重:30%(逻辑变更 > 重构 > 配置)
### Step 4 - Failure History(历史加权)
若提供历史缺陷数据,对评分进行加权:
- 近 90 天有缺陷记录:分数 × 1.5
- 近 30 天有缺陷记录:分数 × 2.0
### Step 5 - Test Mapping(测试映射)
输出:
- 必测用例(影响分 > 70):本次发布的最小安全测试集
- 建议测试(影响分 40-70):时间充裕时执行
- 可跳过(影响分 < 40):本次可豁免三、真实案例:电商结算模块的精准回归实践
背景
某电商平台结算系统共有测试用例 1800 条,全量回归需要 4.5 小时。某次迭代的核心改动是:优化了运费计算逻辑,修改了 freight_calculator.py 中的阶梯运费算法。
传统做法:全量回归,4.5 小时,测试 1800 条用例。
使用 DRIFT Skill 的做法:
分析过程
Step 1 - 变更分析
改动文件:freight_calculator.py
改动函数:calculate_freight()、get_weight_tier()
改动性质:逻辑变更(阶梯运费算法调整)
改动规模:47 行Step 2 - 可达性分析
一级影响(直接调用 calculate_freight):
- order_service.py → create_order()
- cart_service.py → preview_total()
- admin/order_adjust.py → manual_recalculate()
二级影响(调用上述函数的模块):
- checkout_flow.py(调用 create_order)
- mini_program/cart.py(调用 preview_total)
- coupon_service.py(与 cart_service 共享价格计算上下文)
三级影响(边界评估):
- payment_service.py(接收 create_order 结果,但只读取总价字段)
- → 判定:间接影响极低,不纳入必测范围Step 3 + Step 4 - 评分与历史加权
模块 | 基础评分 | 历史加权 | 最终评分 | 优先级 |
|---|---|---|---|---|
order_service.py | 85 | ×1.5(近 90 天有 Bug) | 100 | 🔴 必测 |
cart_service.py | 78 | ×1.0 | 78 | 🔴 必测 |
checkout_flow.py | 72 | ×2.0(近 30 天有 Bug) | 100 | 🔴 必测 |
coupon_service.py | 55 | ×1.5 | 82 | 🔴 必测 |
mini_program/cart.py | 60 | ×1.0 | 60 | 🟡 建议测 |
admin/order_adjust.py | 45 | ×1.0 | 45 | 🟡 建议测 |
payment_service.py | 20 | ×1.0 | 20 | 🟢 可跳过 |
Step 5 - 测试用例映射结果
必测用例:243 条(覆盖 4 个高风险模块的核心路径)
建议测试:178 条(2 个中风险模块)
可跳过:1379 条
预计执行时间:必测 45 分钟,含建议测试 90 分钟
节省时间:相比全量回归减少 67%~83%这次实践中,精准回归用 45 分钟发现了原来全量回归才能发现的 2 个缺陷:一个在 checkout_flow.py 中(因为历史有记录,被加权到必测),另一个在 coupon_service.py 中(运费变化影响了满减门槛的边界计算)。
四、工程实现:让 Skill 自动跑起来
核心脚本:从 Git Diff 到测试清单
import subprocess
import anthropic
import json
DRIFT_SKILL_PROMPT =“”“
你是一名精准回归测试专家,请按照 DRIFT 模型分析以下信息,
输出 JSON 格式的测试优先级清单。
Git Diff 摘要:
{diff_summary}
项目模块依赖关系:
{dependency_graph}
历史缺陷记录(近 90 天):
{bug_history}
请输出:
{{
“must_test”: [“{{“module”: “模块名”, “reason”: “原因”, “score”: 分数}}“],
“suggest_test”: [...],
“skip”: [...],
“estimated_time_minutes”: 数字,
“risk_summary”: “一句话风险摘要”
}}
“”“
def get_git_diff_summary(base_branch: str=“main”) ->str:
“”“获取本次改动的文件和函数摘要”“”
diff = subprocess.run(
[“git”, “diff”, base_branch, “--stat”],
capture_output=True, text=True
).stdout
# 获取函数级别的改动
diff_detail = subprocess.run(
[“git”, “diff”, base_branch, “--unified=0”],
capture_output=True, text=True
).stdout
returnf“文件改动统计:\n{diff}\n\n详细改动:\n{diff_detail[:3000]}“
def load_dependency_graph(project_path: str) ->dict:
“”“解析项目依赖关系图(示例:基于 Python import 分析)”“”
import ast, os
graph = {}
for root, _, files in os.walk(project_path):
forfilein files:
ifnotfile.endswith(“.py”):
continue
filepath = os.path.join(root, file)
rel_path = os.path.relpath(filepath, project_path)
try:
withopen(filepath) as f:
tree = ast.parse(f.read())
imports = [
node.module for node in ast.walk(tree)
ifisinstance(node, ast.ImportFrom) and node.module
]
graph[rel_path] = imports
exceptException:
pass
return graph
def run_drift_analysis(base_branch: str=“main”,
project_path: str=“.”,
bug_history_path: str=“bug_history.json”) ->dict:
client = anthropic.Anthropic()
diff_summary = get_git_diff_summary(base_branch)
dep_graph = load_dependency_graph(project_path)
try:
withopen(bug_history_path) as f:
bug_history = json.load(f)
exceptFileNotFoundError:
bug_history = {}
prompt = DRIFT_SKILL_PROMPT.format(
diff_summary=diff_summary,
dependency_graph=json.dumps(dep_graph, ensure_ascii=False, indent=2)[:2000],
bug_history=json.dumps(bug_history, ensure_ascii=False, indent=2)
)
message = client.messages.create(
model=“claude-opus-4-5”,
max_tokens=2048,
messages=[{“role”: “user”, “content”: prompt}]
)
response_text = message.content[0].text
# 提取 JSON 部分
start = response_text.find(“{”)
end = response_text.rfind(“}”) +1
return json.loads(response_text[start:end])
def generate_regression_report(result: dict) ->str:
“”“生成 Markdown 格式的回归测试报告”“”
lines = [
“# 精准回归测试报告”,
f“\n**风险摘要**:{result.get('risk_summary', 'N/A')}“,
f“**预计执行时间**:{result.get('estimated_time_minutes', 'N/A')} 分钟\n“,
“## 🔴 必测模块”,
]
for item in result.get(“must_test”, []):
lines.append(f“- **{item['module']}**(评分:{item['score']}):{item['reason']}“)
lines.append(“\n## 🟡 建议测试模块“)
for item in result.get(“suggest_test”, []):
lines.append(f“- **{item['module']}**(评分:{item['score']}):{item['reason']}“)
lines.append(“\n## 🟢 本次可豁免模块“)
for item in result.get(“skip”, []):
lines.append(f“- {item['module']}:{item['reason']}“)
return“\n“.join(lines)
if__name__==“__main__”:
result = run_drift_analysis(
base_branch=“main”,
project_path=“./src”,
bug_history_path=“./data/bug_history.json”
)
report = generate_regression_report(result)
withopen(“regression_plan.md”, “w”, encoding=“utf-8”) as f:
f.write(report)
print(report)
print(f“\n✅ 报告已生成:regression_plan.md“)与 CI/CD 集成的流水线配置
# .github/workflows/smart-regression.yml
name: Smart Regression Analysis
on:
pull_request:
branches:[main, release/*]
jobs:
drift-analysis:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v3
with:
fetch-depth: 0 # 需要完整历史记录
- name: Run DRIFT Analysis
env:
ANTHROPIC_API_KEY: ${{ secrets.ANTHROPIC_API_KEY }}
run: |
python scripts/drift_analysis.py \
--base ${{ github.event.pull_request.base.sha }} \
--output regression_plan.md
- name: Comment Regression Plan on PR
uses: marocchino/sticky-pull-request-comment@v2
with:
path: regression_plan.md五、使用注意:精准回归的边界与前提
精准回归不是银弹,它有两个重要前提需要提前建立:
前提一:测试用例必须有模块标签 DRIFT 模型的最后一步是“测试映射”,前提是每条测试用例知道自己覆盖哪个模块。如果现有用例库没有这个元数据,需要先做一次补标工作。通常可以用 AI 辅助批量打标,半天内完成千条用例的标注。
前提二:需要建立缺陷历史数据库 历史故障加权是 DRIFT 模型中区分度最高的维度。建议从现在开始,将每次线上缺陷和测试阶段发现的 Bug,都记录到一个结构化的 JSON 文件中,字段包括:模块路径、发现时间、严重等级。数据积累 1-2 个月后,Skill 的分析精度会有显著提升。
一个不能省略的安全底线:对于核心交易链路(支付、下单、账户),无论 DRIFT 评分多低,建议设置强制必测标记,不允许被豁免。精准回归是提效工具,不是风险转移工具。
总结:从“测得多”到“测得准”
这篇文章的核心是一次测试理念的升级:从覆盖驱动转向风险驱动。
全量回归的本质是用时间换确定性,在迭代缓慢的年代这是合理的。但当系统规模和发布频率都上了一个数量级,这个等式就不再成立——你没有那么多时间,但你可以拥有更好的判断力。
DRIFT 模型给了 AI 一套结构化的分析框架,把“影响范围识别”这件原本依赖经验和直觉的事情,变成了可计算、可量化、可自动化的流程。它不是要替代测试工程师的判断,而是在每次发布前,给测试工程师一份数据支撑的决策参考。
精准回归的终极目标不是“少测”,而是把每一分测试资源都花在最有价值的地方。当你能在 1 小时内完成原来 6 小时的工作,多出来的 5 小时,可以用来做探索性测试、写更好的自动化用例、或者在上线后守护监控大盘——这才是质量工作应有的样子。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-12,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号