MoR如何通过动态递归深度实现模型轻量化与高性能?参数共享与自适应计算的完美融合

MoR如何通过动态递归深度实现模型轻量化与高性能?参数共享与自适应计算的完美融合

唐国梁Tommy
发布于 2026-06-25 20:36:56
发布于 2026-06-25 20:36:56
今天我们要深入探讨一篇来自KAIST、Mila和Google等顶尖机构的最新研究——《Mixture-of-Recursions》(混合递归,简称MoR)。在当前这个“模型越大,能力越强”的时代,我们几乎每天都在见证参数量刷新纪录的巨型模型诞生。但随之而来的是令人咋舌的训练成本和部署难题,这道无形的墙将许多创新者挡在了门外。

我们不禁要问:除了无止境地“堆料”,还有没有更聪明的路径?有没有办法让模型既“节俭”又“强大”?这篇论文给出了一个响亮而优雅的回答。MoR框架首次将两大主流效率优化技术——参数共享与自适应计算——无缝地融合在了一个统一的架构中,为我们描绘了一幅“少劳多得”的美好蓝图。
一、 背景概述:当“节俭”遇上“智能”
要理解MoR的价值,我们首先需要了解当前大模型效率优化的两条主要技术路线。
1. 参数共享:这条路线的核心思想是“节俭”。它试图通过让模型中的不同部分共享同一套参数(权重),来大幅减少模型的总参数量和内存占用。最典型的代表就是递归网络(Recursive Networks)。这种方法虽然大大减小了模型体积,但其“一刀切”的计算方式往往会限制模型的性能上限。
2. 自适应计算:这条路线的核心思想是“智能”。它认为,对于输入的一段文本,并非所有词语都同等重要。例如,处理thermodynamics(热力学)显然比处理冠词“a”需要更多的思考。因此,自适应计算允许模型根据输入的复杂度动态地分配计算资源。典型的技术是早退机制(Early Exiting),即让简单的token提前毕业,不必走完整个计算流程。这种方法能有效减少总计算量(FLOPs),但通常不减少模型的参数规模。
一直以来,这两个方向如同两条平行线,各自发展。研究者们要么选择一个更小的模型(参数共享),要么选择一个计算更快的模型(自适应计算)。而MoR的开创性就在于,它大胆地提出了一个问题:我们为什么不能两者兼得呢?
MoR的目标,就是构建一个既能通过参数共享保持“身材苗条”,又能通过自适应计算实现“智能思考”的统一框架。这不仅是一个技术上的挑战,更可能引领下一代高效语言模型的设计潮流。
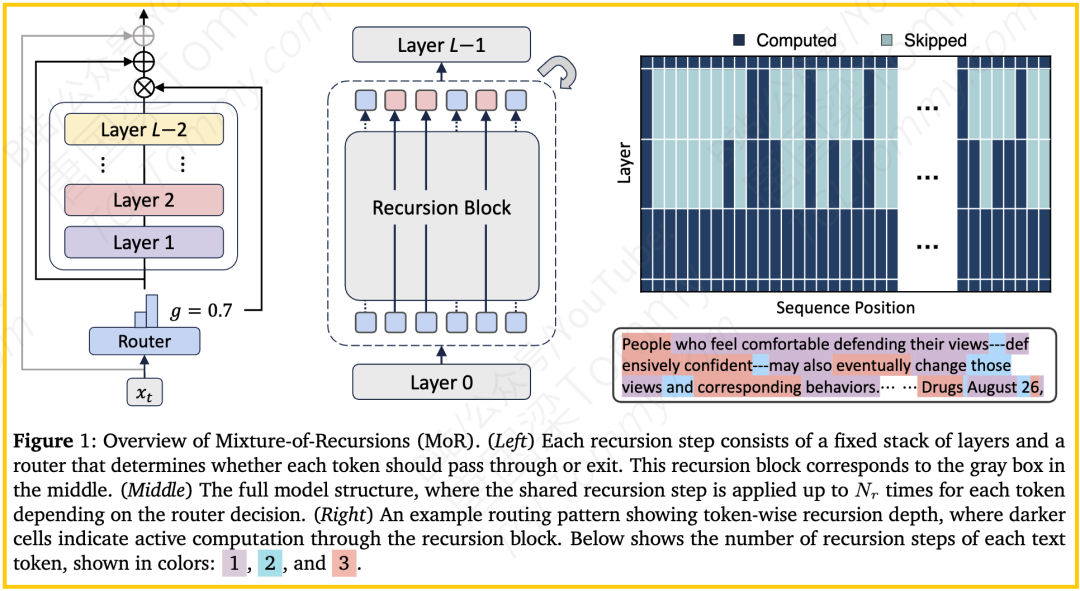
二、 核心内容:MoR的三大创新贡献
MoR的创新可以总结为三大核心贡献,它们共同构建了一个高效且强大的语言模型架构。
1. 统一的效率框架:MoR是第一个将参数共享和token级自适应计算这两个效率范式优雅地统一起来的架构。它不是两种技术的简单堆砌,而是一个内在协同的系统。其基础是一个递归Transformer,通过重复使用一个共享的层堆栈来实现参数效率;其灵魂则是一个轻量级的路由器,通过动态地为每个token分配不同的递归深度来实现计算效率。
2. 精细的token级自适应计算:MoR将自适应计算的粒度推进到了前所未有的token级别。传统的早退机制通常是让整个序列在某个中间层退出,而MoR则为序列中的每一个token独立决策其所需要的思考深度(即递归次数)。这意味着模型可以将宝贵的计算资源精确地分配给那些最需要深度处理的、语义信息最丰富的词语,从而在整体计算量受限的情况下,最大化模型的性能。
3. 高效的系统级架构设计:MoR不仅是一个理论上的漂亮模型,更是一个充分考虑了实际部署效率的工程杰作。它提出了一套与动态递归深度完美匹配的键值缓存(KV Caching)策略,有效解决了因token提前退出而导致的缓存管理难题。这一设计,结合其固有的参数共享特性,使得MoR能够在实际推理中获得比传统模型高得多的吞吐量,这对于在线服务等实际应用场景至关重要。
总而言之,MoR通过一个设计精巧的框架,同时在模型大小、训练/推理计算量和内存占用这三个维度上实现了显著优化,建立了一个全新的性能与效率的帕累托前沿(Pareto Frontier)。
三、 方法解析:深入MoR的内部运作
要理解MoR的魔力,我们需要深入其内部,探究它的三大关键组件:参数共享策略、动态路由策略和键值缓存策略。
1. 参数共享策略
MoR的基础是递归Transformer,其核心在于参数共享。但这并非简单的重复,如何共享大有学问。论文通过详尽的实验,最终确定了一种名为“中间循环(Middle-Cycle)”的最佳策略。
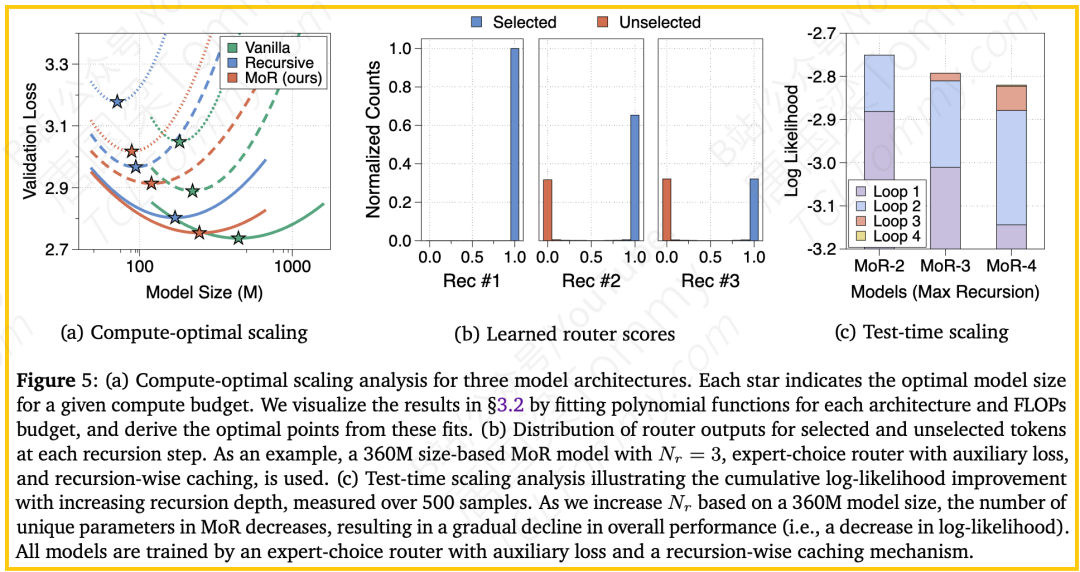
我们可以用一个公司组织结构来类比:
- 传统模型:就像一个拥有32个不同部门的大公司,每个部门(层)都有自己独特的员工和工具(参数),臃肿且昂贵。
- MoR的“中间循环”策略:则像一家精干高效的创业公司。它拥有:
- 一个独特的“前台接待部门”(第一层),负责接收原始输入(token embeddings)并进行标准化预处理。
- 一个独特的“总裁办公室/发货部”(最后一层),负责将最终的内部思考结果转化为对外输出(预测的logits)。
- 一个“核心项目组”(中间共享的递归块),这个项目组由少数几个高度通用的专家(例如2个层)组成。所有的核心业务都由这个项目组通过循环迭代的方式来完成。
2. 动态路由策略
如果说参数共享是MoR的骨架,那么动态路由就是它的灵魂。它让模型学会了因材施教。MoR的路由器就像一个智能调度员,决定每个token需要在这个“核心项目组”里循环思考多少次。论文重点探讨了两种路由机制:
a) 专家选择路由 (Expert-choice Routing)
这个策略可以理解为“工位选择零件”。
- 机制:每个递归步骤(例如第1、2、3次循环)都被视为一个“专家”。在每个步骤开始时,该步骤的“专家”(路由器)会审视所有还在处理流程中的token,给它们打一个“复杂度”分,然后只选择分数最高的top-k个token进入本轮计算。
- 类比:在一个精密仪器加工厂,第一道工序(递归步骤1)对所有零件进行粗加工。到了第二道工序(递归步骤2),工头(路由器)会检查所有零件,发现其中一些(如简单的螺丝)已经合格,就让它们直接出厂(提前退出)。他只挑选那些还需要精加工的核心部件(如齿轮、轴承),让它们进入第二道工序。每深入一道工序,被处理的零件就越少,但都是最关键的。
- 优缺点:它的优点是计算负载完美均衡,因为每一步处理的token数量是固定的,GPU利用率极高。缺点是存在因果性问题(训练时需要看到所有token才能排序),论文通过引入辅助损失(auxiliary loss)来巧妙地解决了这个问题,训练路由器学会在没有全局信息的情况下做出正确的局部判断。
b) 令牌选择路由 (Token-choice Routing)
这个策略则相反,可以理解为“零件选择自己的加工路线”。
- 机制:在计算开始时,路由器就为每一个token一次性地预测它总共需要经历多少次递归。
- 类比:在工厂入口,每个零件(token)都会被贴上一张“工艺路线卡”,上面明确写着它需要经过1、2还是3道工序。然后每个零件就按部就班地走完自己的专属路线。
- 优缺点:它的优点是因果性好,完全符合自回归的生成模式。缺点是可能导致负载不均衡,如果某一时刻大部分token都被分配去走3道工序,那么负责第3道工序的设备就会不堪重负,而负责第1道工序的设备则可能闲置。
实验证明,专家选择路由凭借其高效的负载管理能力,在整体性能上更胜一筹,成为了MoR架构的首选。
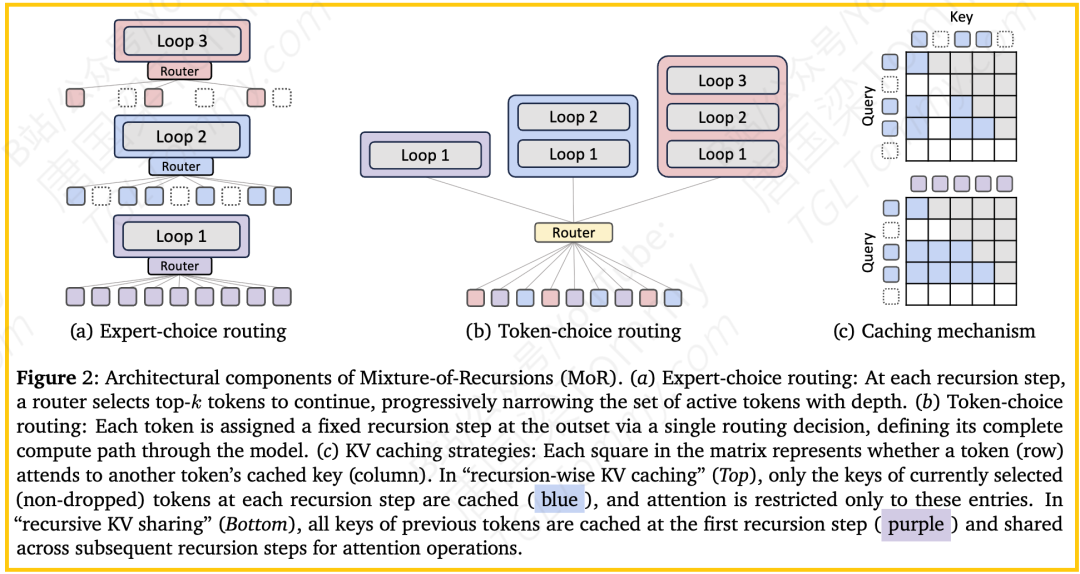
3. 键值缓存策略
KV缓存是Transformer高效推理的基石,但MoR的动态性给它带来了新挑战——缓存中会出现因token提前退出而产生的“空洞”。为此,论文设计了两种专门的缓存策略。
a) 逐递归缓存 (Recursion-wise Caching)
可以比喻成“部门内部的笔记本”。
- 机制:为每一个递归步骤维护一个独立的KV缓存。在这个步骤中,token的注意力计算只在当前还活跃的token之间进行。
- 例子:在递归步骤3,只有那些被路由到深度3的token存在于这个缓存中,它们也只和彼此计算注意力。
- 优缺点:优点是计算量大大减少(注意力计算的复杂度与序列长度的平方成正比),且概念清晰。缺点是可能丢失部分上下文信息(深层token无法“看到”已退出的token)。
b) 递归共享缓存 (Recursive Sharing)
可以比喻成“全公司共享的公共白板”。
- 机制:只在第一次递归时创建一个完整的KV缓存。后续所有步骤都共享和重用这个初始的、完整的缓存。
- 例子:在递归步骤3,活跃的token仍然可以读取并使用在步骤1时所有token(包括那些早已退出的)的K和V值。
- 优缺点:优点是内存占用极低,且上下文信息完整。缺点是深层token使用的是“陈旧”的上下文信息,可能影响性能,并且计算量节省不如前者。
这两种策略提供了在计算、内存和性能之间的灵活权衡。总的来说,MoR通过这三大组件的精妙配合,构建了一个既紧凑又强大、既智能又高效的计算框架。
四、 实验结果与分析:数据证明实力
理论的优雅最终需要实验数据来证明。MoR在一系列严格的实验中展现了其卓越的性能。
实验设置:
- 模型规模:覆盖从135M到1.7B的四种参数规模。
- 数据集:在高质量的FineWeb-Edu数据集上进行预训练。
- 评测基准:在包括HellaSwag、MMLU在内的六个主流少样本(few-shot)任务上进行评测。
- 对比对象:标准的Vanilla Transformer模型和传统的递归Transformer模型。
关键结果解读:
- 用更少的参数,实现更强的性能:这是MoR最令人振奋的结果。如论文表3所示,在相同的16.5e18 FLOPs训练计算预算下,一个仅有167M参数的MoR模型,其少样本平均准确率达到了43.1%,超过了一个参数量是其近两倍(315M)的Vanilla Transformer模型(42.3%)。这有力地证明了MoR的计算效率——它能将每一份计算力都转化为更高的性能。
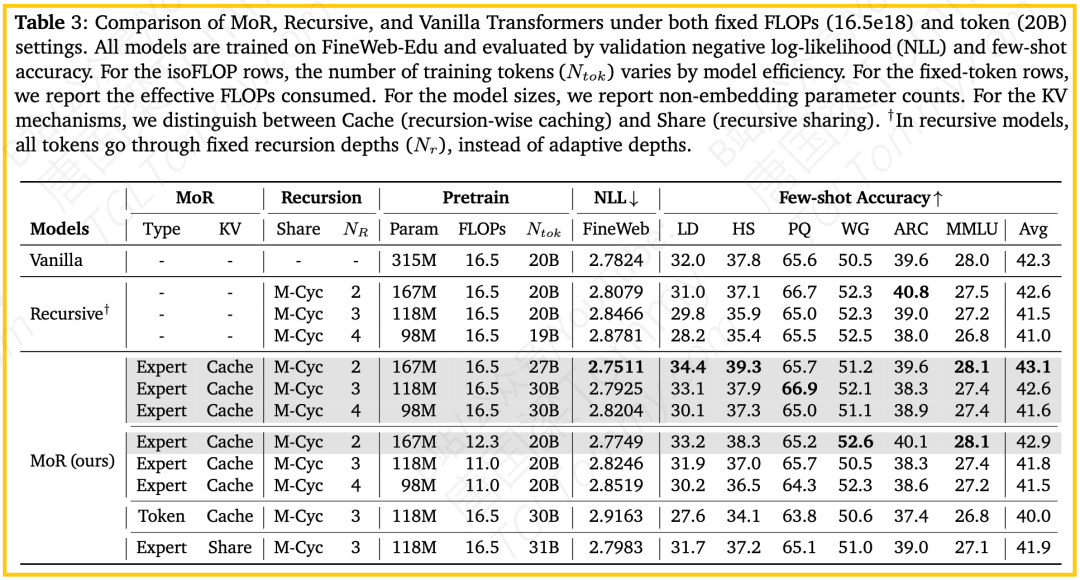
- 用更少的计算,达到同样的效果:从另一个角度看,当训练数据量相同时(20B tokens),MoR模型仅用了12.3e18 FLOPs的计算量就达到了42.9%的准确率,而Vanilla模型则需要16.5e18 FLOPs。这意味着MoR能够将训练时间缩短近19%,同时将峰值内存使用降低25%。
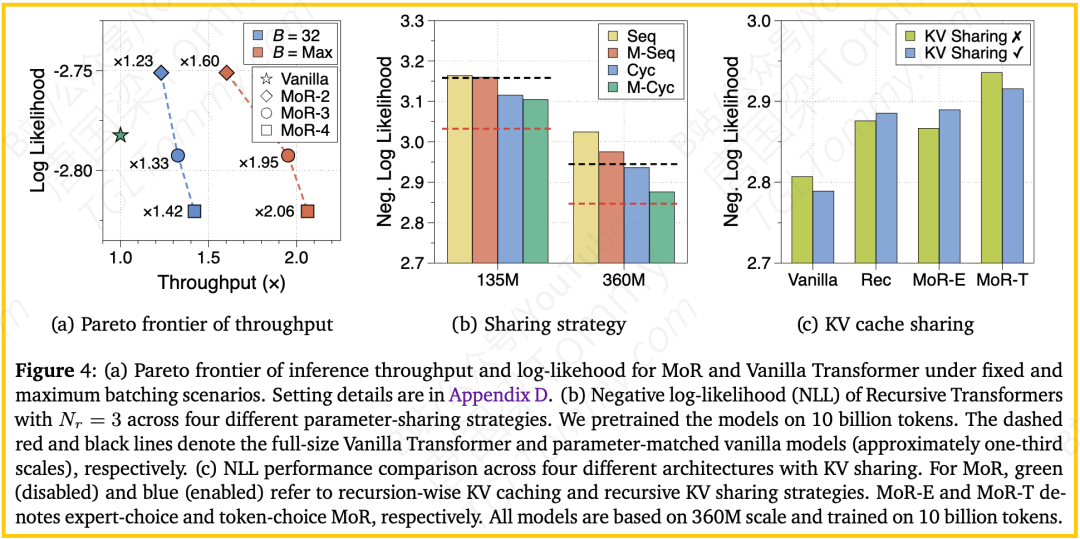
- 推理速度大幅提升:在实际部署中,吞吐量是关键指标。论文图4a展示了MoR在推理速度上的巨大优势。得益于其自适应计算和高效的缓存管理,MoR模型最多可以实现2.06倍于标准模型的推理吞吐量。这意味着在提供在线服务时,一台部署了MoR的服务器可以处理相当于过去两台服务器的请求量。
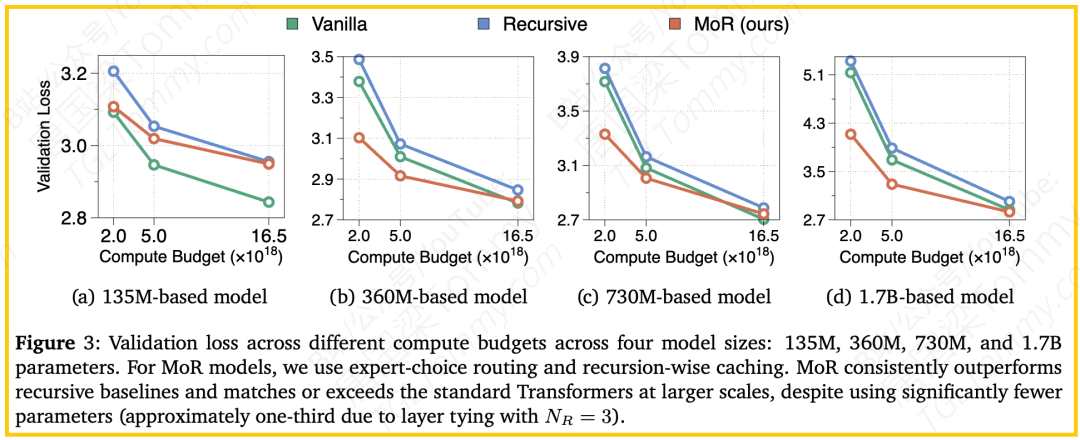
- 良好的可扩展性:通过在不同模型尺寸上的isoFLOP分析(见图3),研究表明MoR的优势并非昙花一现。随着模型规模从135M增长到1.7B,MoR始终稳定地优于传统的递归基线,并且与Vanilla模型的性能差距逐渐缩小甚至反超。这证明MoR是一种具有普适性和良好扩展性的架构。
- 路由机制的有效性验证:模型真的学会了“智能”分配吗?论文图1右侧的可视化给出了肯定的答案。模型确实学会了为“People”、“defensively confident”、“Drugs”等语义丰富的词分配更多的递归深度(3次),而为“and”、“---”等功能性或结构性的词分配较少的深度。这证实了MoR的核心假设是成立的。
五、 启示:通往更高效AI的未来之路
MoR的研究为我们揭示了通往更高效、更普惠AI的一条光明大道。它不仅仅是一个新模型,更是一种新的设计哲学。基于此,未来有几个令人兴奋的研究方向:
- 更大规模的探索:将MoR架构扩展到百亿甚至千亿参数规模,验证其在更大模型上的有效性。
- 复杂推理任务的应用:探索MoR在需要多步推理(如思维链,Chain-of-Thought)的任务上的表现,研究其路由器能否学会为复杂的推理步骤动态分配计算。
- 与其他稀疏技术的融合:一个极具吸引力的方向是将MoR与专家混合(Mixture-of-Experts, MoE)技术相结合。想象一个“MoE-MoR”混合体,它不仅能为每个token选择不同的思考深度,还能在每个思考步骤中选择一小组最合适的“专家”来进行计算,这将实现两个正交维度上的动态性,有望带来效率的指数级提升。
总而言之,《Mixture-of-Recursions》是一项里程碑式的工作。它告诉我们,模型的强大并非只来自于庞大的身躯,更可以来自于其内部计算过程的智慧与优雅。在追求通用人工智能的漫漫征途上,MoR无疑是向着“更智能,而不仅仅是更大”这一目标迈出的坚实而重要的一步。
参考文献
论文名称: Mixture-of-Recursions: Learning Dynamic Recursive Depths for Adaptive Token-Level Computation
第一作者: KAIST AI & Google Research
论文链接: https://arxiv.org/abs/2507.10524
发表日期: 2025年7月14日
GitHub:https://github.com/raymin0223/mixture_of_recursions
你好,我是唐国梁Tommy,专注于分享AI前沿技术。
#AI #大模型 #LLM #AI技术论文 #AI前沿技术 #唐国梁Tommy #检索增强生成 #RAG #大模型推理
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-07-23,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号