登顶开源榜首,阿里Ovis2.5深度解读,多模态模型如何拥有原生视觉与深度思考能力?

登顶开源榜首,阿里Ovis2.5深度解读,多模态模型如何拥有原生视觉与深度思考能力?

唐国梁Tommy
发布于 2026-06-25 20:59:46
发布于 2026-06-25 20:59:46
今天,我们要聊一个多模态大语言模型(MLLM)领域的重磅玩家——来自阿里巴巴的 Ovis2.5。

在AI圈,MLLM早已不是什么新鲜词,它们能看、能听、能聊,正在逐步改变我们与数字世界的交互方式。然而,看似全能的背后,许多模型其实都有两个“阿喀琉斯之踵”:一是“视力不佳”,在处理复杂图表或高清大图时,往往需要把图片切成小块,像通过一根吸管看世界,丢失了全局信息;二是“思维线性”,习惯于一步到位的“思维链”(Chain-of-Thought),缺乏自我反思和纠错的能力,遇到复杂问题容易“一条道走到黑”。

这正是Ovis2.5团队想要解决的核心痛点。他们的新作不仅要让AI看得更清、看得更全,还要教会它如何“三思而后行”。这篇技术报告,就是他们交出的答卷。接下来,就让我们一起深入探索,Ovis2.5究竟带来了哪些突破,又是如何实现的。
核心亮点速览:Ovis2.5带来了什么?
在深入技术细节之前,我们先用几句话概括Ovis2.5最核心的四大贡献,让你对它的能力有个直观的印象:
1. 原生分辨率感知:看得清,看得全
Ovis2.5最大的革新之一,就是整合了原生分辨率视觉变换器(NaViT)。这意味着它不再需要将图片“大卸八块”,而是可以直接处理任意原始尺寸和长宽比的图像。这就像从一个定焦镜头升级到了一个能自由变焦、拥有超广角的全能相机,无论是精细的图表数据点还是复杂的全局页面布局,都能一览无余。
2. 深度推理能力:引入可选的“思考模式”
为了突破线性思维的局限,Ovis2.5在训练中引入了一种特殊的“反思式”数据,教会模型在回答前进行自我检查和修正。这个能力在推理时以一个可选的“思考模式”(Thinking Mode)开放给用户。对于简单问题,可以关闭它追求速度;对于复杂难题,可以开启它,让模型“多想一会儿”,以延迟换取更高的准确率。
3. SOTA性能表现:登顶开源模型榜单
Ovis2.5-9B在权威的OpenCompass多模态综合排行榜上,以78.3分的平均成绩,登顶40B参数规模以下的开源模型榜首。更令人印象深刻的是,其2B版本也取得了73.9的高分,在同量级模型中一骑绝尘,完美诠释了“小模型,大性能”的理念。
4. 高效训练架构:速度与规模兼得
如此强大的模型背后,是一套高效的训练基础设施。通过多模态数据打包和混合并行等优化技术,Ovis2.5的端到端训练速度提升了3到4倍,为模型快速迭代和扩展提供了坚实的基础。
架构与方法解析:Ovis2.5是如何炼成的?
1. Ovis的基石:一个优雅的“视觉翻译”系统
首先,Ovis2.5继承了Ovis系列一贯的优雅架构。我们可以把它理解为一个精密的“视觉翻译系统”,由三个核心部件协同工作:
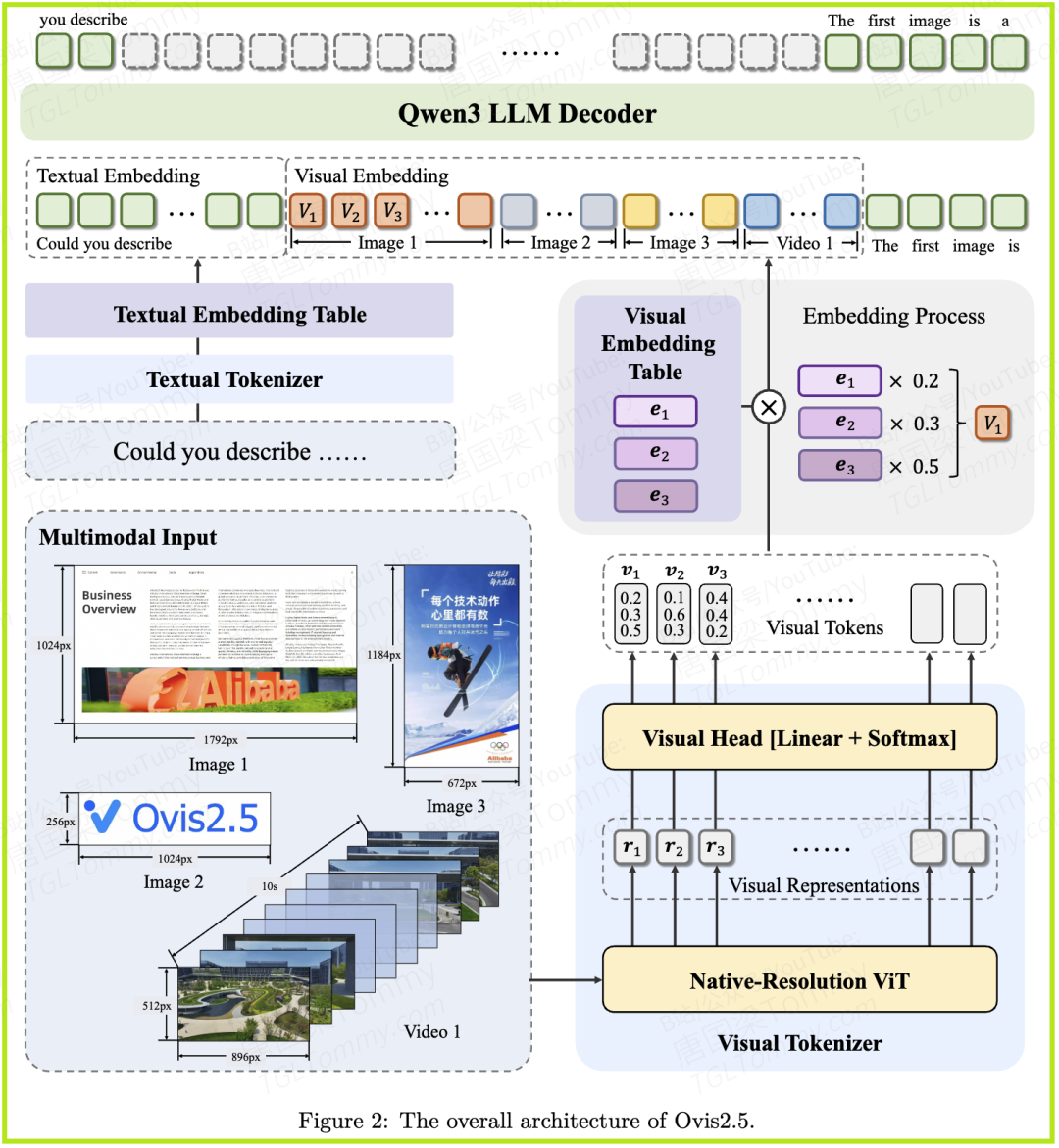
- • 视觉分词器 (Visual Tokenizer, VT):这是模型的“眼睛”。它不是简单地把图像像素变成向量,而是像一个高级图像分析师,将图像切分成小块(patches),然后为每个小块分析出其最可能代表的“视觉概念”,并输出一个概率分布。比如,图像中的一块蓝色区域,可能有70%的概率是“天空”,20%是“海洋”,10%是“蓝色布料”。
- • 视觉嵌入表 (Visual Embedding Table, VET):这是连接视觉与语言的“核心词典”。它为成千上万个“视觉概念”(或称“视觉词”)都预设了一个独特的嵌入向量。VT分析出的概率分布,会作为权重,对VET中对应的向量进行加权求和。最终,一张复杂的图像就被“翻译”成了一系列LLM能够理解的、蕴含丰富语义的向量。这个设计的精妙之处在于,它解决了传统方法中视觉特征(连续)和文本特征(离散)之间的结构性不对齐问题。
- • 大语言模型 (LLM):这是模型的“大脑”,负责将“翻译”好的视觉信息和用户输入的文本信息融合在一起,进行理解、推理,并最终生成答案。
2. 两大关键升级:从“优秀”到“卓越”
在稳固的基石之上,Ovis2.5进行了两大革命性的升级,彻底解决了前文提到的两大痛点。
升级一:NaViT——给AI一双“鹰之眼”
传统的视觉编码器(如标准ViT)处理图像的方式非常死板:不管图片多大、长宽比如何,都必须先缩放、裁剪成固定尺寸(如224x224),或者切成同样大小的图块。这种“一刀切”的做法,对于信息密度极高的图表或文档来说是灾难性的。
Ovis2.5引入的NaViT (Native-resolution ViT)则完全不同。它的核心思想是“输入即所见”,能够直接处理任意分辨率和长宽比的图像。
- • 如何工作? NaViT通过一种巧妙的序列打包(sequence packing)策略,将不同尺寸的图像块灵活地拼接成一个统一长度的序列送入Transformer。为了让模型在处理这种可变分辨率的输入时,依然能准确感知空间位置信息,Ovis2.5还在NaViT的每一个Transformer块中都集成了旋转位置编码(Rotary Position Embeddings, )。是一种先进的位置编码技术,它通过旋转矩阵来编码相对位置,对于处理高分辨率、长序列的输入尤其有效。
- • 类比理解: 如果说传统ViT看图就像是用固定的网格去套一张照片,网格外的部分被裁掉,网格内的信息被拉伸或压缩;那么NaViT则像是拥有一双能自由聚焦的眼睛,既能一览无余地看清整张照片的全貌,又能放大到任何一个角落去观察细节,而不会破坏原图的结构。
升级二:Qwen3 + “思考模式”——教会AI“三思而后行”
强大的感知能力需要匹配强大的推理能力。Ovis2.5将LLM底座升级为推理能力更强的Qwen3,并在此基础上,通过一种创新的训练方法,教会了模型进行深度思考。
传统的“思维链”(CoT)训练,是让模型学习模仿“问题 → 步骤1 → 步骤2 → 答案”这样的线性过程。但如果步骤1就错了,模型很难自我发现并纠正。
Ovis2.5的解决方案是构建一种“反思式”的训练数据。这些数据的格式不再是简单的线性链条,而是包含了显式的自我反思和修正过程,并用特殊的<think>...</think>标签包裹起来。
• 训练数据示例:
问题:[一个复杂的数学问题]
回答:
<think>
好的,我们来分析这个问题。首先,我需要识别出所有的已知条件...
第一步,我尝试用公式A来计算,得到结果X。
等一下,我检查一下这个结果。似乎公式A在这里的应用前提不满足,这会导致错误。
我应该换个思路,使用公式B。
好的,用公式B重新计算第一步... 这样就合理了。
接下来进行第二步...
</think>
[最终的、经过修正的解题步骤和答案]• 训练效果:通过学习大量这样的样本,模型不仅学会了如何解决问题,更学会了如何评估自己的解题过程。它的大脑里仿佛内置了一个“监察员”,会时常审视自己的推理链路是否合理,从而在遇到复杂问题时表现得更加鲁棒和可靠。这就是“思考模式”的由来。
3. 五阶段训练课程:AI的“精英成长计划”
拥有了顶级的硬件(架构)和教材(数据),还需要一套科学的“教学计划”。Ovis2.5设计了一个精密的五阶段训练课程,像培养一个精英学生一样,逐步构建模型的能力。

第一阶段:VET预训练 (视觉基础启蒙)
- • 目标:教会模型最基础的“看图识物”,即训练好VET这个“视觉词典”。
- • 方法:使用海量“图像-标题”数据对。为保证学习稳定,此阶段会冻结视觉编码器的大部分参数,只微调最后几层和VET。分辨率较低,且暂时关闭。
第二阶段:多模态预训练 (图文对话入门)
- • 目标:打通视觉和语言的连接,让模型具备基础的对话和理解能力。
- • 方法:开放所有模块的参数进行全量训练,并引入OCR、定位等更多样的任务。关键是,大幅提升了支持的图像分辨率,并全面启用了,为处理复杂视觉任务打下基础。
第三阶段:多模态指令微调 (能力全面拓展)
- • 目标:让模型学会听懂并执行各种复杂的指令,并掌握深度推理能力。
- • 方法:在这一阶段,训练数据变得极其丰富,包括单图、多图、视频、纯文本等多种模态。最重要的是,正式引入了带有
<think>...</think>标签的反思式推理数据,开始培养模型的“思考模式”。
第四阶段:多模态 DPO (与人类对齐)
- • 目标:让模型的输出更符合人类的偏好和价值观。
- • 方法:采用当前主流的**直接偏好优化(Direct Preference Optimization, DPO)**技术。通过学习人类对不同回答的偏好数据(哪个回答更好,哪个更差),对模型进行微调,使其言行举止更像一个可靠的助手。
第五阶段:多模态强化学习 (推理能力冲刺)
- • 目标:在已对齐的基础上,进一步拔高模型的逻辑推理上限。
- • 方法:使用组相对策略优化(Group Relative Policy Optimization, GRPO),在大量可验证答案的推理任务(如数学题)上进行强化学习。此阶段会冻结视觉模块,将全部优化资源集中在LLM的“大脑”上,进行最后的推理能力冲刺。
这套环环相扣、层层递进的训练流程,确保了Ovis2.5在成长的每个阶段都打下了坚实的基础,最终成长为一个能力全面且特长突出的多模态模型。
实验结果分析:用数据说话
Ovis2.5的实际表现如何?论文通过一系列详尽的实验给出了答案。
1. 综合实力:登顶OpenCompass排行榜
OpenCompass是一个综合性的多模态能力评测套件,涵盖了从常识问答、幻觉评估到专业学科推理的8个主流基准。
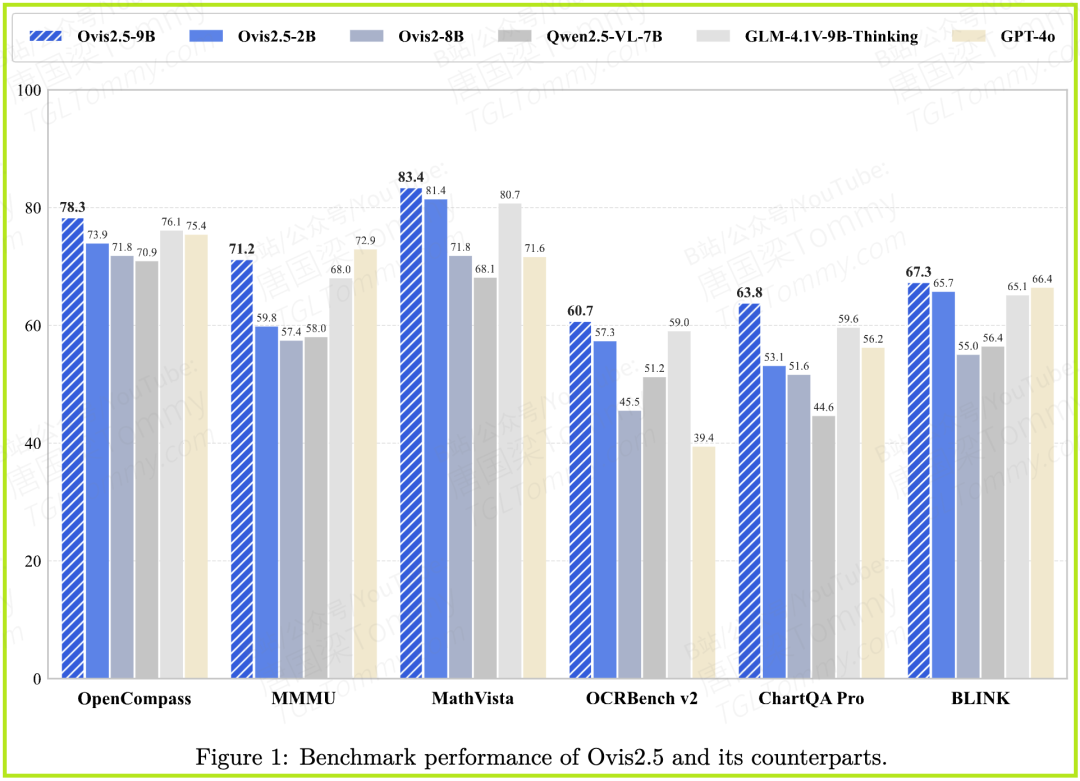
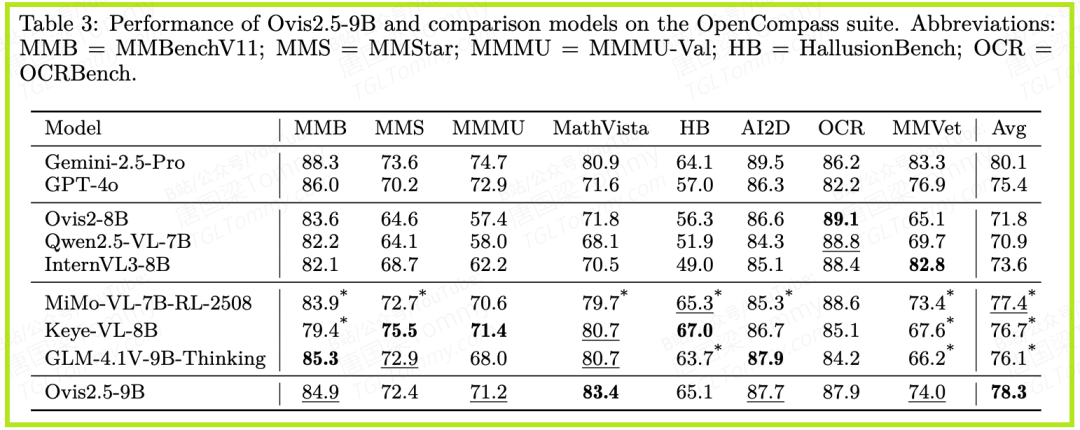
- • Ovis2.5-9B:取得了78.3分的惊人成绩,不仅远超其前代Ovis2-8B(71.8分),也超过了包括GLM-4.1V-9B-Thinking(76.1分)、Keye-VL-8B(76.7分)在内的所有同级别开源对手。
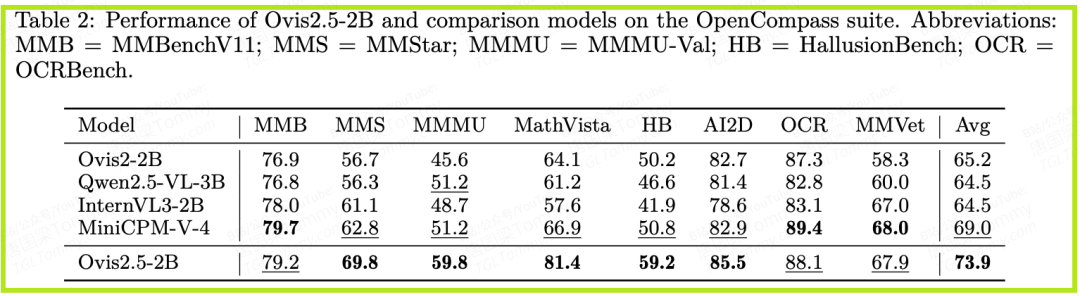
- • Ovis2.5-2B:以73.9分的成绩,刷新了2B级别模型的SOTA记录,甚至超过了许多体量远大于它的模型,展现出极高的效率。
这些综合分数证明,Ovis2.5的各项改进是系统性的、全面的,而非在个别任务上的“偏科生”。
2. 核心场景:在“专攻领域”展现统治力
Ovis2.5是为解决特定问题而设计的,它在这些核心场景下的表现更能体现其技术的先进性。
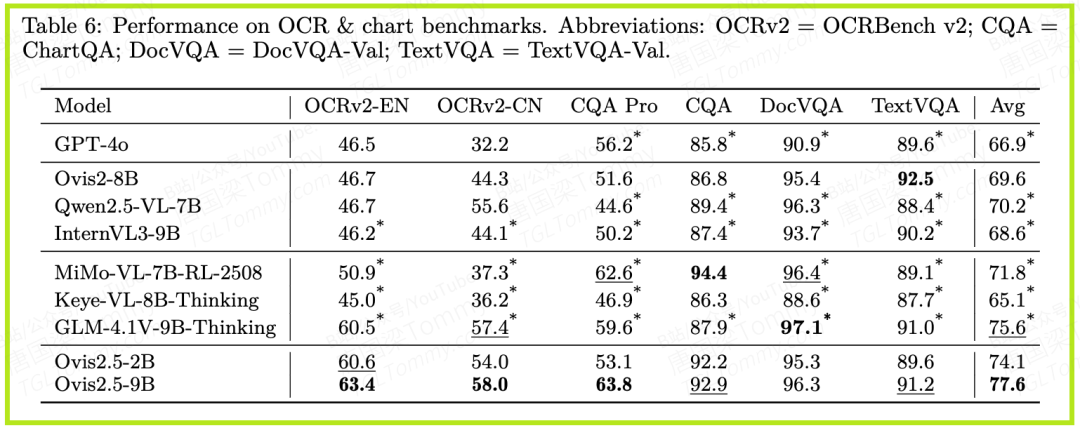
- • OCR与图表分析:这是最能体现原生分辨率感知优势的领域。在论文的图1和表6中,我们可以看到:
- • 在极具挑战性的ChartQA Pro基准上,Ovis2.5-9B获得了63.8分,大幅领先。
- • 在包含7个OCR和图表相关任务的综合评测中,Ovis2.5-9B的平均分高达77.6,位列第一。
- • 这些结果强有力地证明,不切图,真的能看得更清楚。
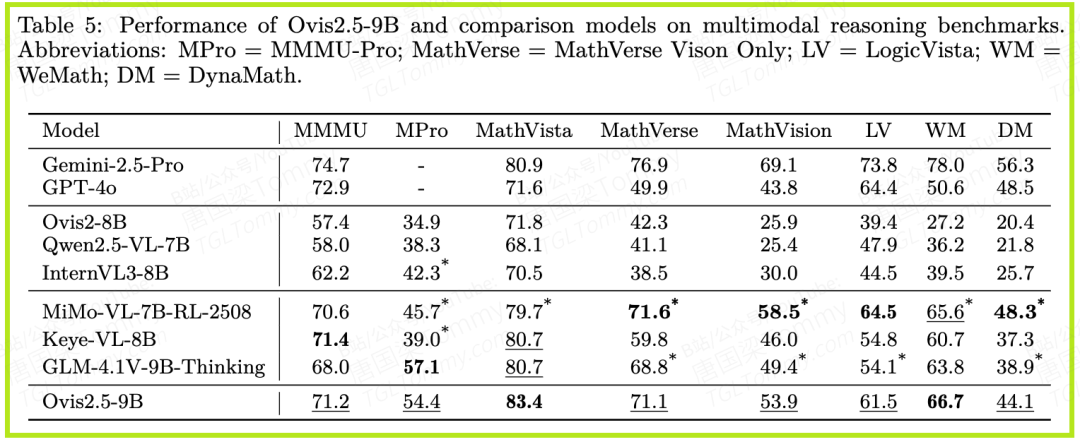
- • STEM与深度推理:这是检验 “思考模式” 成色的试金石。在表5中,我们可以看到:
- • 在视觉数学推理基准MathVista上,Ovis2.5-9B取得了83.4分的SOTA成绩。
- • 在大学水平的多学科问答MMMU上,它获得了71.2分,同样名列前茅。
- • 这些需要严密逻辑和多步推理的硬核任务,恰恰是Ovis2.5深度思考能力的最佳体现。
3. 其他能力:全面发展的“六边形战士”
除了上述两大核心优势领域,Ovis2.5在其他多模态任务上也表现出色:
- • 视觉定位(Grounding):在RefCOCO系列数据集上,Ovis2.5展现了精准的“指哪看哪”能力,平均分达到90.1,尤其在描述更复杂的RefCOCOg上优势明显。
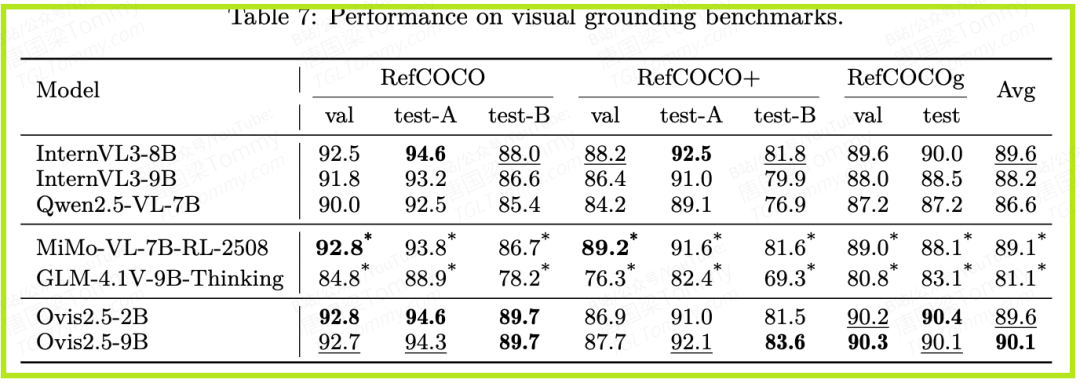
- • 视频理解:在VideoMME、MVBench等多个视频基准上,Ovis2.5同样保持了强劲的竞争力,证明其能力可以从静态图像平滑迁移到动态视频序列。
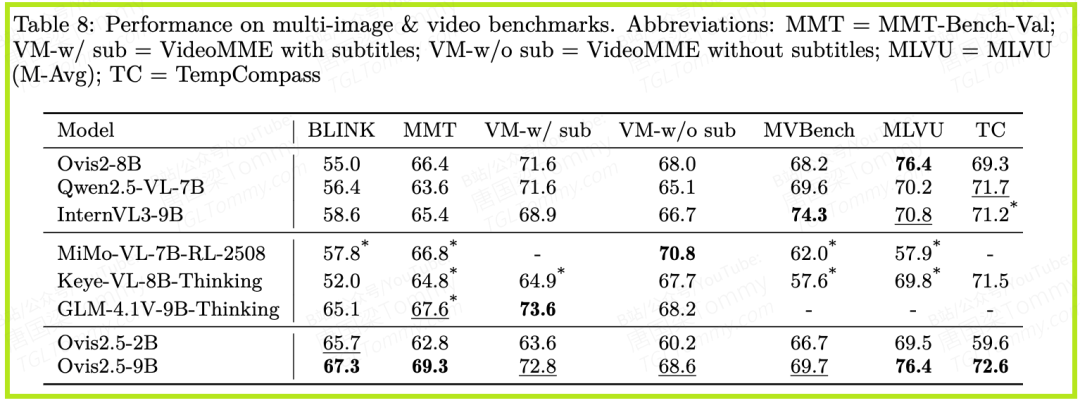
总而言之,实验数据清晰地描绘了Ovis2.5的画像:它不仅是一个在综合能力上领先的“通才”,更是在其设计的核心应用领域——复杂视觉感知和深度推理上,拥有绝对优势的“专才”。
总结与未来展望
这篇报告清晰地告诉我们,要构建更强大的MLLM,必须双管齐下:一方面,要不断打磨模型的“感知器官”,让它拥有更接近物理世界的、不受限制的感知能力;另一方面,则要精心设计其“思维模式”,引导它从简单的模式匹配走向复杂的、带反思的认知过程。
当然,探索永无止境。Ovis2.5团队也坦诚地指出了未来的研究方向:
- • 更高清的视觉:将感知能力从目前的高分辨率进一步推向4K级别的超高清领域。
- • 更长程的理解:处理更长的视频输入,捕捉和推理更复杂的时间动态。
- • 更开放的交互:将模型与外部工具(如计算器、搜索引擎)紧密结合,构建能够“动手”解决问题的智能体。
我们有理由相信,随着这些方向的不断突破,一个真正像人一样看世界、想问题的通用多模态智能,正离我们越来越近。而Ovis2.5,无疑是这条道路上一个坚实而闪亮的里程碑。
论文名称:Ovis2.5 Technical Report
第一作者:阿里 - Ovis Team
论文链接:https://arxiv.org/pdf/2508.11737
最新日期:2025年8月15日
github:https://github.com/AIDC-AI/Ovis.git本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2025-08-20,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号