Hermes Agent 记忆架构:一座"记忆工厂"

Hermes Agent 记忆架构:一座"记忆工厂"

唐国梁Tommy
发布于 2026-06-25 21:40:21
发布于 2026-06-25 21:40:21
很多 AI 产品一谈 memory,都给人一种"只要加一个记忆模块就够了"的错觉。但把 Hermes Agent 的系统设计和源码对着看下来,你会发现一件反直觉的事:真正能落地的 Agent 记忆系统,从来不是一个模块,而是一套分层得非常克制的组合结构。
它既要记住你是谁、你有什么偏好,又要能想起上次到底改了哪几个函数、试过哪些失败方案,还不能因为"多写了一条记忆"就把整个 prompt cache 打碎。这事看起来不大,做下来很硬。

为什么记忆必须分层
一上来,Hermes 要同时满足三件互相冲突的事:
- 要持久化,不然用户每次都要重复讲清自己是谁;
- 要可控,不然 memory 文件很快会变成一堆乱七八糟的日志;
- 要尽量稳住 prompt cache,不然 system prompt 每轮都变,成本、时延、调试全会变差。
于是 Hermes 的核心判断不是"尽量多记",而是**"哪些东西该怎么记,才既留得下来,又不把系统拖垮"**。它的记忆至少有四层——当前工作记忆(run_conversation() 里流动的 messages)、内建长期记忆(MEMORY.md 装环境/项目/工具约定,USER.md 装用户画像和偏好)、完整会话历史(state.db + FTS5 搜索 + gateway 的 JSONL transcript)、可插拔外部 memory provider。稳定事实进 curated memory,完整过程进 transcript,需要时再用 session_search 回忆。一混就会互相污染。
最反直觉的一刀:新写入不立刻生效
这是整套设计里最反直觉、也最能体现工程味的一点。
Session 启动时,Hermes 会立刻把 MEMORY.md 和 USER.md 读出来,冻结成一份 system prompt snapshot。如果当前 session 中途调了 memory 工具写入新内容,文件会马上落盘,但那份快照不会动——这条新记忆真正出现在 prompt 里,一般要到下一次 session 启动。
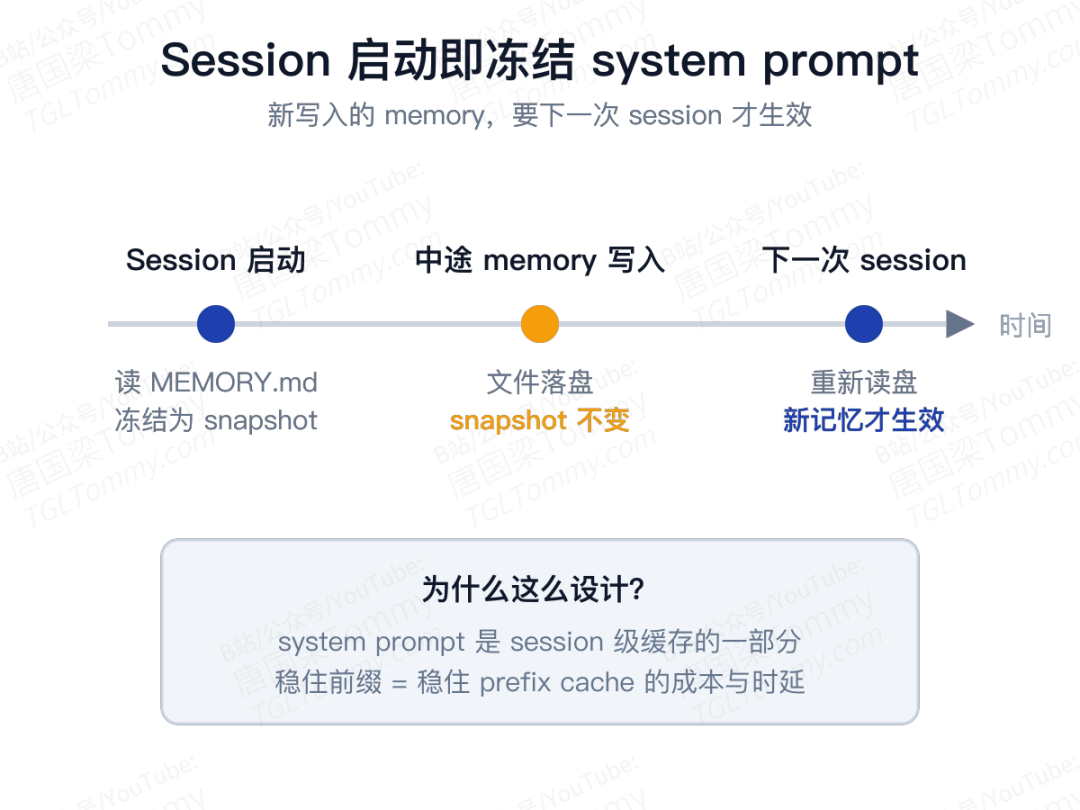
为什么这么做?因为在 Hermes 里,system prompt 是 session 级缓存的一部分。第一次请求前构建一次,之后整个 session 复用,只有 context compression 才会让它失效。甚至在 gateway 这种每条消息都可能新建 AIAgent 的场景里,它也会优先去 session DB 里读上一轮已保存的 system prompt,而不是根据磁盘上最新的 memory 文件重新拼一次。
换句话说:宁可牺牲一点实时体验,也要稳住 session 内的 system prompt 前缀。这不是功能没做完,是一个非常清楚的成本决策——尤其对吃 prefix cache 的模型链路,收益非常实际。
克制到骨子里的长期记忆
Hermes 不只是在原则上说"长期记忆要精炼",它在机制上把这件事做得很硬:
- 没用结构化数据库,就两份纯文本文件;
- 字符预算设了硬上限:
MEMORY.md默认 2200 字符,USER.md默认 1375 字符; - 单条记忆只有
add/replace/remove三种操作,没有知识图谱,没有自动 embedding; -
replace和remove不靠 entry id,靠短子串匹配目标条目,匹配到多条直接报歧义。

这些选择合在一起非常一致:人能看懂,调试容易解释,memory 文件还能手工编辑,不会被一套过度结构化的内部 id 体系绑死。
写入路径上的细节也值得讲。Hermes 每次写 memory 前,会先在锁内重新读一遍磁盘,把别的 session 或进程刚写入的变化吸收进来再修改;落盘不是 open('w') 覆盖,而是 temp file + os.replace() 的原子写。这是为了避免"你只是写一条记忆,却让别的会话读到空文件"这种竞态。
安全也不是点到为止。长期 memory 最终会被注入 system prompt——它本质上是一个持久化 prompt 入口。所以写入前会做 threat scanning,扫 prompt injection、角色劫持、诱导读取密钥、SSH 后门式暗示,甚至隐形 Unicode。恶意内容只出现在单次对话里影响有限;一旦进 memory 文件,后续每个 session 都会被污染。
完整历史:另一条主线
Hermes 的思路不是"把所有过去浓缩成几条记忆",而是先把完整会话轨迹老老实实存下来。
state.db 里不只有 role 和 content,还会存 tool_call_id、tool_calls、tool_name、finish_reason,以及 reasoning、reasoning_details、codex_reasoning_items 这些字段。

为什么连 reasoning 都要存?因为在一些 provider 或模型接口里,多轮推理上下文本来就是连续的,在持久化层把 reasoning 丢了,下一轮恢复时模型看到的上下文就会断层。所以 state.db 在 Hermes 里更像一份运行时档案库,而不是单纯的聊天记录备份。
检索基座做得也扎实。SQLite 开了 WAL,多读单写;写事务走 BEGIN IMMEDIATE 加应用层随机 jitter retry;messages_fts 这张 FTS5 虚表通过 trigger 和主表同步,搜索时不只给命中片段,还会带上前后邻近消息。

这让 session_search 变成一个"先粗搜、再重构上下文"的回忆管线:FTS5 拿候选 → 归并到各自 session → 读完整 transcript → 交给辅助模型做 focused summary。它还特意把 delegation 产生的 child session 一路 resolve 到 parent,再把当前 session 的 lineage 整条排除掉——防止模型把"自己当前链路上的上下文"又当成"过去历史"重复召回。
这里还有一个非常"有生产味"的细节:gateway 现在同时保留 SQLite 和 JSONL,加载 transcript 时会选消息更多的那一份,避免迁移期间只读到最近几条、让模型误以为历史只有一小段。不优雅,但不丢数据。
外部 recall 的"正确注入姿势"
再往外一层,是可插拔外部 memory provider。Hermes 把它抽成 MemoryProvider + MemoryManager,给第三方后端留了完整生命周期。但它加了两个非常值得注意的约束:
- 同一时间只允许一个外部 provider 生效——多个 provider 同时塞工具、同时召回、同时抢 prompt 空间,几乎必然冲突。
- 外部 recall 不写回 transcript。召回结果只在构造
api_messages时被临时包进一个<memory-context>fenced block,附到当前轮 user message 后面。真实的会话messages不动。

第二点是整套架构里最不该被忽视的设计之一。如果召回结果被再次写进历史,以后 session_search 搜出来的东西里就会混进"系统自己以前召回出来的内容"——时间一长,系统分不清哪些是原始事实,哪些是临时补进去的解释。这是一种非常糟糕的自我污染。
压缩边界:最精彩的一段
最精彩的部分,是 Hermes 怎么处理"上下文马上要丢"的时刻。
很多系统在 compression 或 reset 时就是直接压缩、直接清空。Hermes 会先做一件事——flush_memories():在消息列表末尾临时追加一条系统风格的 user message,大意是"这段上下文马上要被压缩,请优先保存值得长期记住的东西,尤其是用户偏好、纠正和重复模式";然后发起一次只开放 memory 工具的模型调用;写入完成后,再把这条 flush message 连同临时痕迹一起剥掉,确保 transcript 不被这次归档动作污染。

这次调用还优先走 auxiliary client——"临时归档"没必要占主模型链路,还能绕开一些 API 兼容性麻烦。如果启用了外部 provider,真正压缩前还会再跑一次 on_pre_compress(messages)。Hermes 把压缩边界当成一个应该主动做知识转移的时刻,而不是一次简单的丢内容。
compression 本身也不是重写当前 session,而是结束旧 session,生成新的 session_id,建一条带 parent_session_id 的 continuation session,把压缩后的消息写进去。旧 transcript 还在,新对话又能继续,整条 lineage 保住。

这点非常关键——后续 session_search 正是靠 lineage 感知,来避免把当前链路当成历史重复召回。
子代理保守,会后秘书兜底
子代理这里,Hermes 保守得让人印象深刻:child agent 默认没有 memory 工具,构造时显式 skip_memory=True,连 clarify、递归 delegation、跨平台消息发送都默认挡掉。子代理上下文更窄,容易把局部偶然情况误当长期事实;而且子代理往往并发执行,直接让它们写共享 memory 几乎一定会制造噪声。
但"这件事值不值得进长期记忆"的判断,Hermes 没有放弃,它留在父级上下文——父代理的 provider 可以在 delegation 完成后收到 on_delegation(task, result)。探索下放给子代理,价值判断留给父代理。
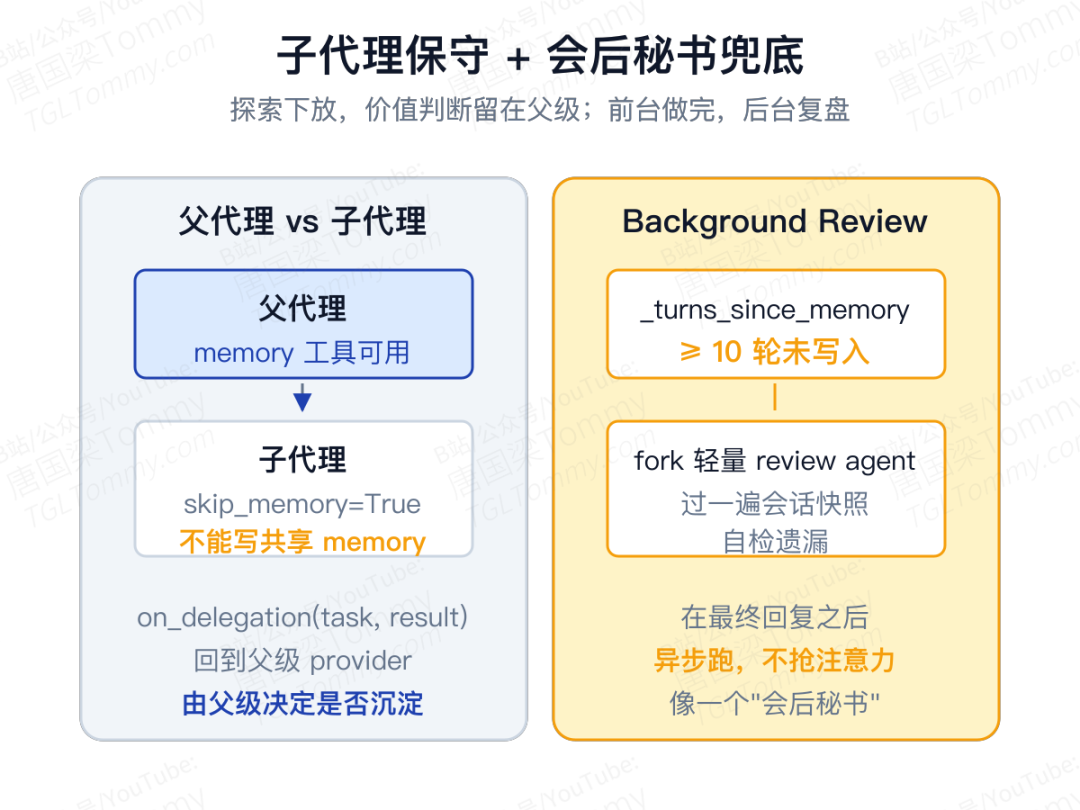
自动化治理还有第二层。Hermes 不完全相信主代理每次都会主动调 memory 工具。源码里 _turns_since_memory 会持续计数,连续很多轮没发生写入(默认阈值 10 轮)就触发 background review:fork 一个轻量 review agent,把刚才这段快照再过一遍,附一段专门的 review prompt,让它自己检查"有没有什么本该记住却没记下来的事实"。这一步是在用户收到最终回复之后异步跑的,不跟主任务抢注意力。
我很喜欢这个设计,它像一个"会后秘书":前台把活干完,后台再有人帮你复盘有没有值得沉淀的东西。
局限与下一步
Hermes 这套架构的优点不在"某个 memory backend 特别先进",而在边界划得很清楚:什么是稳定事实,什么是完整历史,什么是临时召回,什么是当前工作上下文,什么是压缩前必须抢救的信息,什么是子代理不该碰的共享长期记忆——全部显式建模。很多 agent 系统最后不是输在能力不够,而是输在上下文层次混了、历史污染了、session 边界不清楚。
但它的局限也同样清楚:
- 体感滞后:内建 memory 要下次 session 才生效;
- 结构化治理弱:curated memory 仍只是文本条目,不好做冲突检测、字段合并和优先级管理;
- 回忆风格单一:
session_search更像摘要式回忆,适合回答"上次发生了什么",还不够适合 agent 继续拿它做结构化执行; - 内建与外部弱耦合:内建 memory 和外部 provider 之间只是桥接,不是强一致。
如果让我提下一步最值得补什么,我不会选"再接一个新的 memory backend"。更值得做的是两件事——一是给 curated memory 加一点轻量结构化元信息(scope / 来源 / 更新时间 / 置信度);二是做一个 session 内可见、但不打碎 system prompt 前缀的 overlay 记忆层,既保留现有缓存策略,又缓解"我刚记住,当前 session 为什么还看不到"的尴尬。
另外,把 session_search 从"摘要模式"推进到能产出 artifacts / commands / decisions 这种结构化回忆,对 agent 继续做事帮助会更大——agent 真正需要的很多时候不是"上次聊了什么",而是"上次到底执行了哪些命令、改了哪些文件、做了什么决定"。从现有 transcript 基座看,这条路是成立的。
结语:不是一个脑子,是一座记忆工厂
Hermes 到底是不是"有一个很强的记忆模块"?更准确的说法是:它不是一个脑子,而是一座记忆工厂。
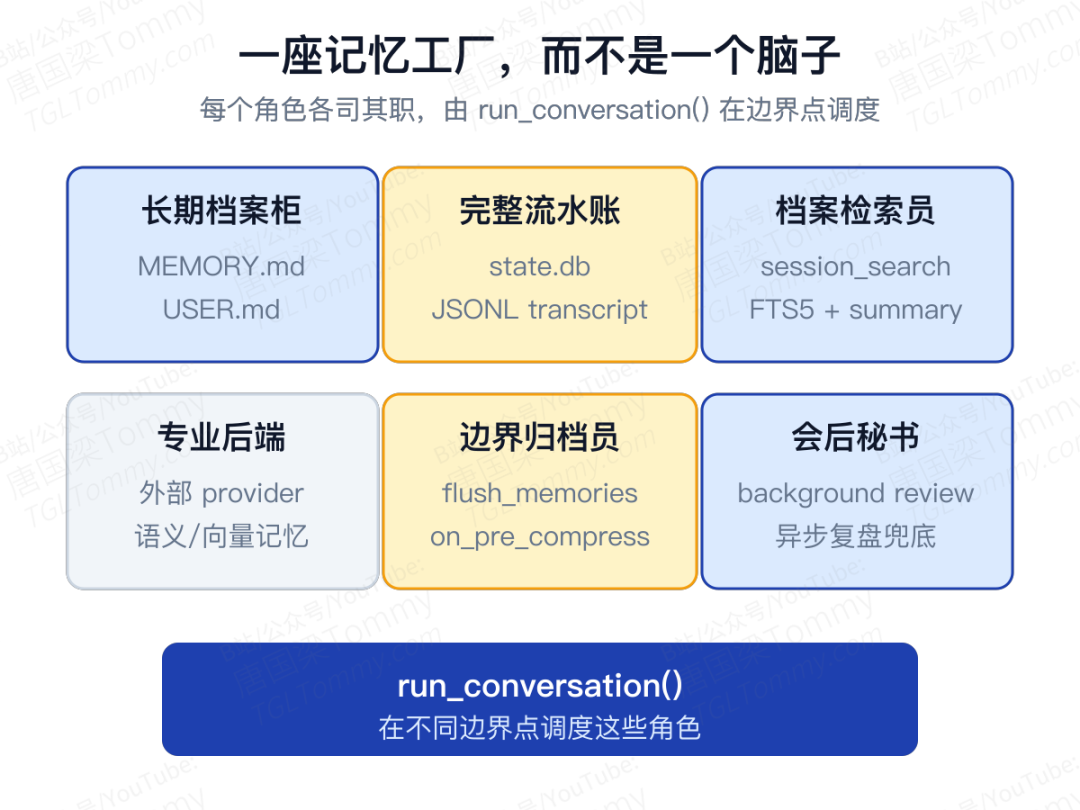
MEMORY.md 和 USER.md 是长期档案柜,state.db 是完整流水账,session_search 是档案检索员,外部 provider 是可插拔的专业记忆后端,flush_memories() 是上下文丢失前的归档员,background review 则是事后复盘的会后秘书。run_conversation() 做的事情,是在不同边界点把这些角色调度起来,让它们各干各的活。
这套设计不一定最统一、最优雅,它甚至保留了不少演进痕迹——JSONL 和 SQLite 并存、内建 MemoryStore 和外部 provider 并行。但也正因为它没有为了"抽象统一"去硬拉平现实,所以更接近一个真实复杂系统在生产环境里能长期工作的样子。
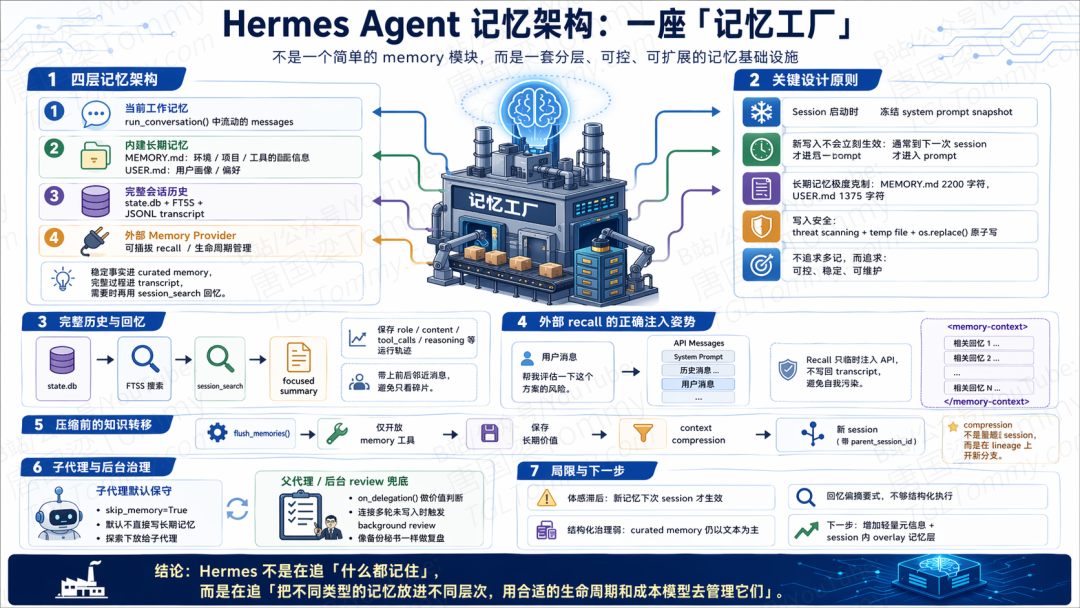
一句话总结:Hermes 不是在追"什么都记住",而是在追把不同类型的记忆放进不同层次,用合适的生命周期和成本模型去管理它们。它真正的价值不是做了一个 memory tool,而是把长期事实、完整历史、外部 recall、压缩和重置这些边界事件,都组织成了一套能落地、能扩展、也能自我约束的记忆基础设施。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-04-22,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号