把真实世界重放一遍,看 Agent 还能不能跟得上

把真实世界重放一遍,看 Agent 还能不能跟得上

唐国梁Tommy
发布于 2026-06-25 21:43:32
发布于 2026-06-25 21:43:32
论文名称 : FutureSim:Replaying World Events to Evaluate Adaptive Agents
一个不太常见的实验场
设想这样一个场景:你把一个最新的前沿模型扔回 2025 年 12 月 24 日的"虚拟时间隧道"里,把它的网络断掉,只允许它读到那一天之前的新闻档案。然后,环境每天往里灌一批真实世界发生过的新报道;模型可以搜索、可以做笔记、可以改主意,但唯一被允许的两个动作只有"提交预测"和"翻到下一天"。88 天之后,1 月到 3 月真实世界里发生过的 330 件事,会一件一件揭晓答案。
模型猜对了多少?
最强的那一个——GPT 5.5 跑在 Codex 里——拿到了 25% 的 top-1 准确率;其余几个开源旗舰,Brier skill score(一种同时奖励"猜得对"和"概率写得诚实"的分数)甚至跌到负数:还不如什么都不预测。
这就是 FutureSim:一个把"真实世界重放给 AI 看"的 benchmark,今天我们来拆一拆它到底测了什么、又测出了什么。
为什么不直接刷题,要这么折腾?
现有的 agent benchmark 大都在测"会不会做":会不会写代码,会不会用浏览器,会不会一气呵成完成一个任务。但今天我们部署 agent 的真实环境,远不只是"做题"——它是动态的、开放的、信息每分钟都在涌入的。在这种环境里,更值钱的是另一种能力:能不能随着世界推进,不断更新自己的判断。
人类的"超级预测者"研究在过去十年里反复说明:那些最准的预测专家,不是天才,而是会一小步一小步频繁修正自己信念的人。那么,前沿模型在跨度长达数月的真实信息流里,能做到这件事吗?
要回答这个问题,作者认为最干净的设定是 预测未来事件:
- 任务的正确答案藏在未来的现实里,与训练数据无关,天然没法靠"刷题"的方式背下来;
- agent 的"动作"是预测而非行动,不会改变环境,所以可以重放真实历史,逐日复盘;
- 同一份历史可以让任意模型、任意 harness 反复跑,方便消融。
这就有了 FutureSim。
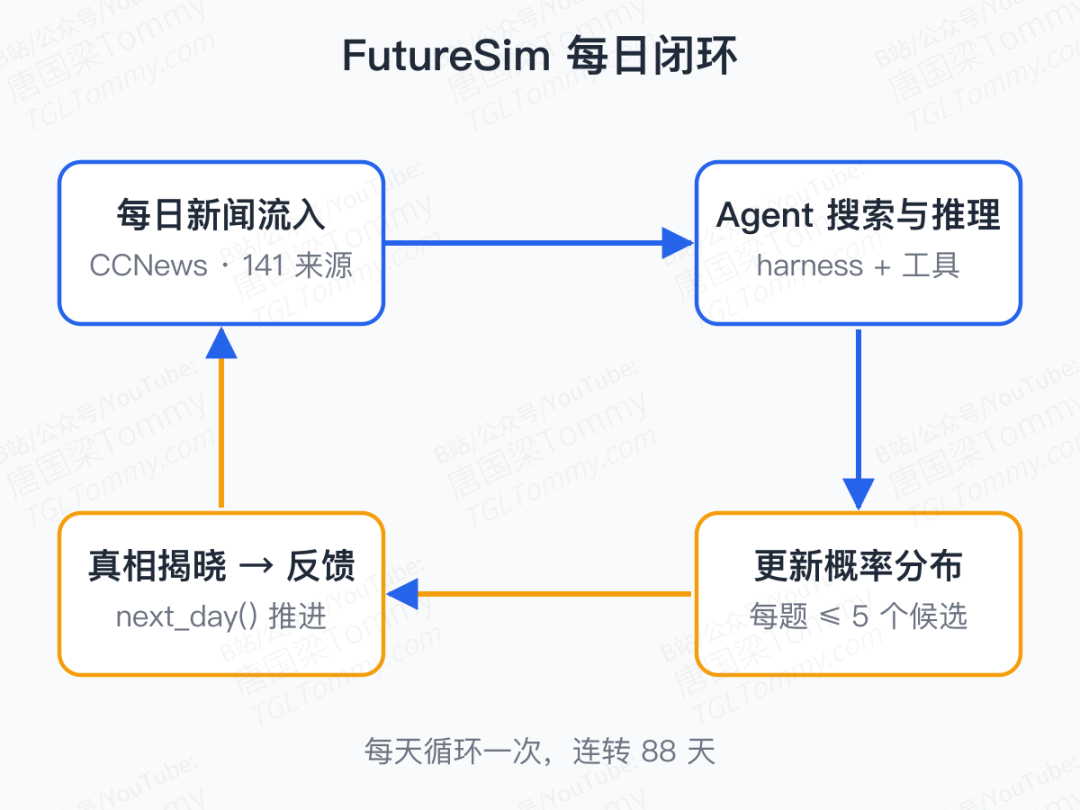
一个故意"做得很瘦"的环境
FutureSim 的设计哲学,是把环境本身做到最薄,把"会不会用"完全留给 agent 自己。它对外只暴露两个 API:submit_forecast() 把概率分布写进任务表,next_day() 把时钟推进一天。任何模型、任何 harness 都能接进来。

模型每一天能拿到什么呢?背景是一个 7.36M 篇真实新闻的离线语料(Common Crawl News 上 141 家媒体),全部带准确时间戳;agent 拿到一个语义 + 关键词混合搜索工具(Qwen3 8B 向量索引、LanceDB、每次返回 5 段 512 token),可以指定时间窗口去捞证据。题目本身是按"Chandak 等人"提出的方法从新闻里自动抽出来的,最后筛出 330 道答案落在 2026 年 1 月 1 日到 3 月 28 日之间的预测题,源自半岛电视台的新闻线。沙箱会拦住一切"未来信息":禁止外网、关 curl、新闻文件夹只允许读"今天为止"那部分。
题目的形式也跟传统 benchmark 不同。不是选择题,而是 自由回答——agent 自己想出多种可能结果,再给每种结果分配一个概率。这种自由度逼着模型暴露它对世界真正的"信念分布",而不是把概率全押在一个候选上。
为了同时评估"猜对"和"概率诚实",作者把多类别 Brier score 改造成了 Brier Skill Score:

简单说就是:押对了越自信越高分;什么都不押拿 0 分;自信地押在错答案上要被扣到 −1 分。负分的含义很扎心:你不如闭嘴。
主结果:差距大得出乎意料
作者把当前几个最强的 agent 都按"官方推荐 harness"拉到 FutureSim 上跑了一遍:GPT 5.5 跑在 Codex,DeepSeek V4 Pro / Claude Opus 4.6 / GLM 5.1 跑在 Claude Code,Qwen3.6 Plus 跑在 OpenCode,每个模型都开到最高推理档、跑 3 个不同随机种子。最长的一次单次运行(GPT 5.5 + Codex),消耗了 3700 个对话回合、1240 万个 token,中间触发了好几次 context window 的压缩——这就是"长跑"四个字的字面含义。
终值准确率长这样:
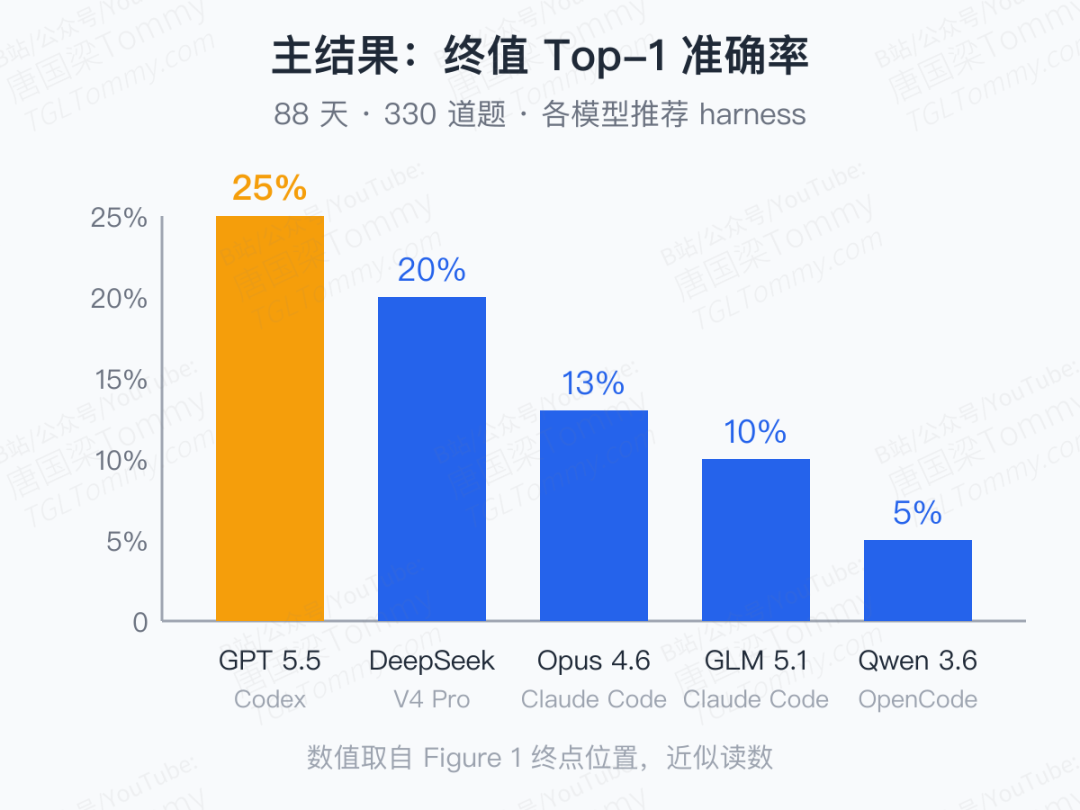
GPT 5.5 领先一个数量级是肉眼可见的。但作者真正想让我们盯住的,是另一条曲线:Brier skill score 的走势。
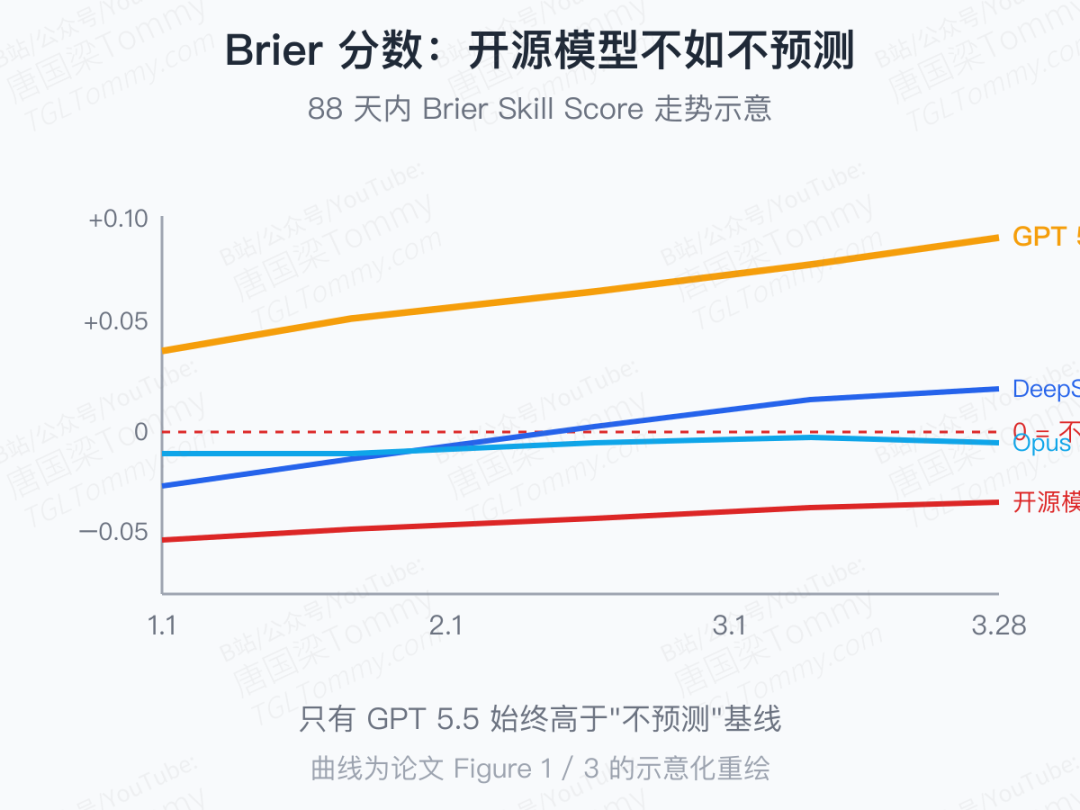
只有 GPT 5.5 全程稳定为正、并且随时间继续涨。开源模型在它们的推荐 harness 上跑出来的曲线常年在 0 以下徘徊;换上作者自己写的"略加 hand-holding"的 harness(包含上下文消耗反馈、强制记忆更新阶段、按问题分桶的记忆工具等),它们才慢慢翻到 0 以上。
这是一组带着钩子的数据:harness 写得好不好,能把同一个开源模型从"不如不预测"拉到"勉强能下注"。这意味着,所谓"前沿模型的能力天花板",其实仍然被它们的脚手架严重欠拟合。
把成绩单往下拆:四个能力的真实成色
光看终点分数容易让人误以为这只是又一份"模型排行榜"。FutureSim 真正值钱的地方,是它的"轴"——只要你设计相应的消融,就能从同一条 88 天的时间线里抽出不同能力的截面。
第一刀:测试时适应力。作者做了一个很狠的实验:把所有模型的起点全部统一压到"最差模型 Qwen3.6 Plus 的初始预测",然后看 88 天里谁能爬回来。
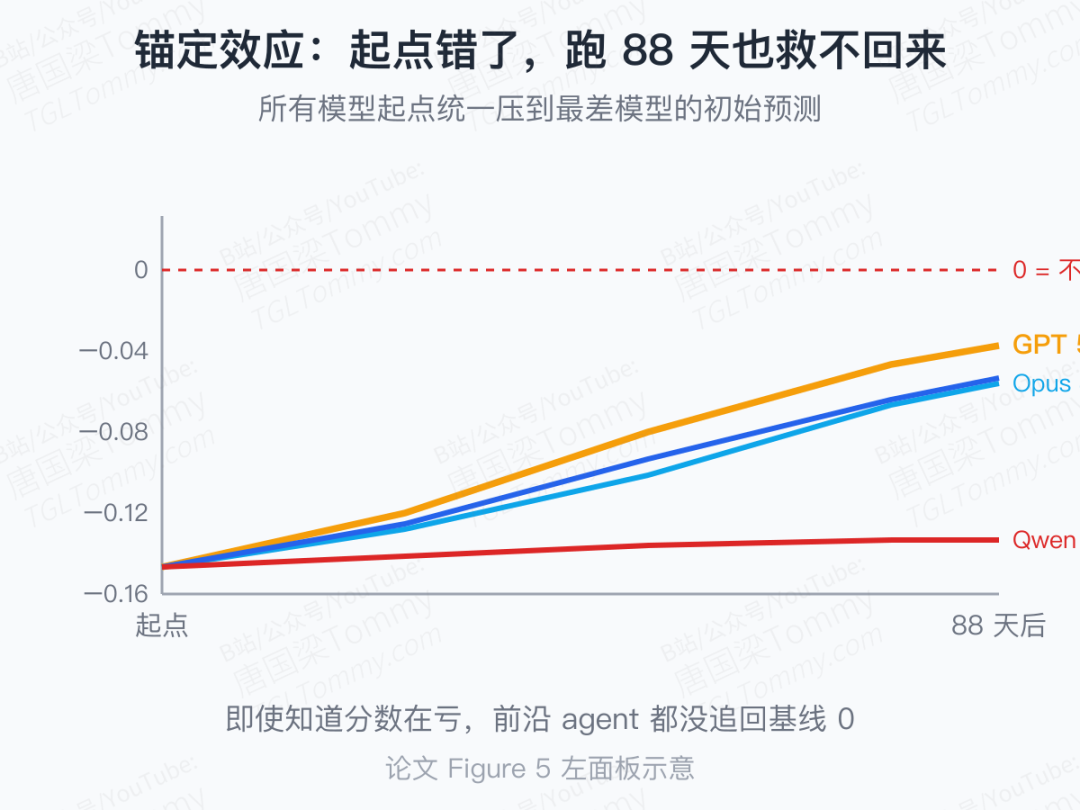
结果是:包括 GPT 5.5、Opus 4.6、DeepSeek V4 Pro 在内的几个强模型,到最后仍然没能爬回 0 分基线——它们明知道自己每天都在亏分,仍然被起点的"坏锚"拖住。作者把这种现象叫做 self-conditioning:模型把自己早期写进记忆里的判断当成"已知事实",越往后越不愿意撤。
更尖锐的对照来自另一组实验:让 GPT 5.5 在每道题"解题前一天"直接一次性看到所有历史信息、独立作答,准确率冲到 31.2%;而它在 FutureSim 里"一天天攒证据、一天天改预测"的版本只有 24.8%。两个数字间那 6.4 个百分点的差,就是"在线适应"目前距离"事后回看"还差的距离。
第二刀:长期记忆。把"读写记忆"的工具关掉之后,三个被测模型不约而同变差。
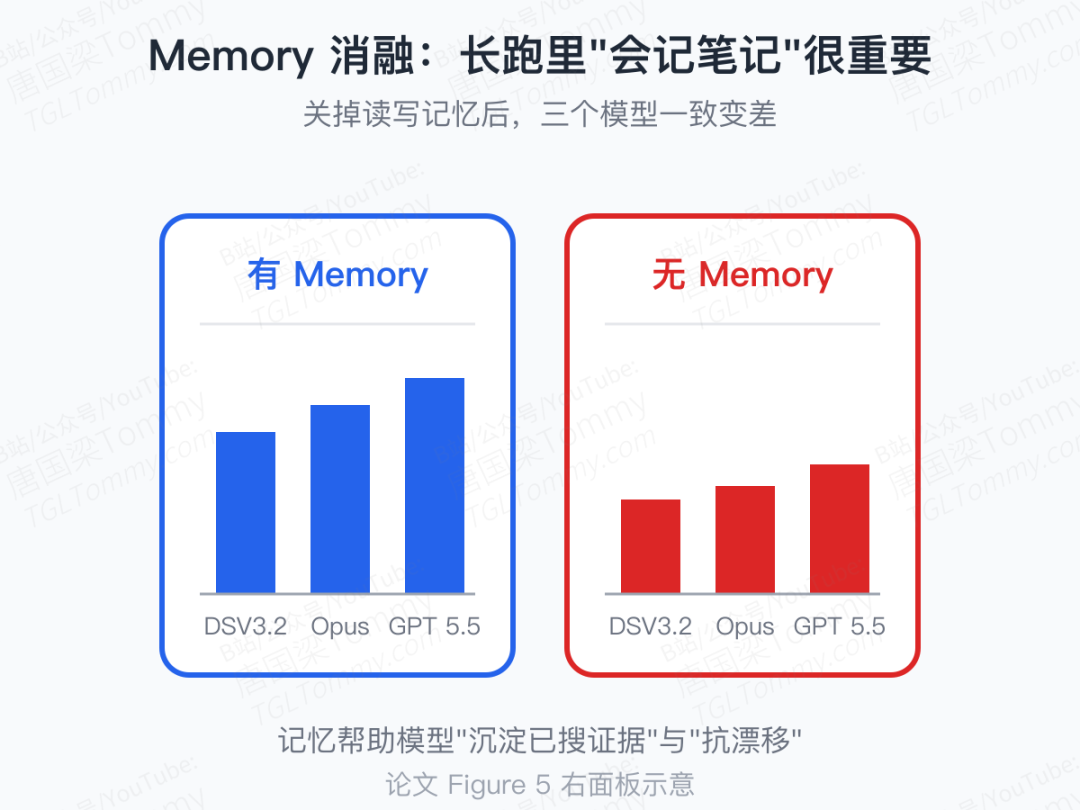
定性看,记忆主要兜住了两件事:一是已搜过的有用证据不必每天重新搜一遍;二是"上一次为什么这么判断"的复盘可以在搜索结果飘忽时充当一个稳定先验,避免被一段弱证据带着大幅过度更新。
第三刀:自主搜索。这是 FutureSim 反差最大的一组消融。在解题前一天给 agent 完整语境、让它自主多轮搜索,准确率 31.2%;如果只用问题原文去做一次语义检索,跌到 14.2%——刚好一半。
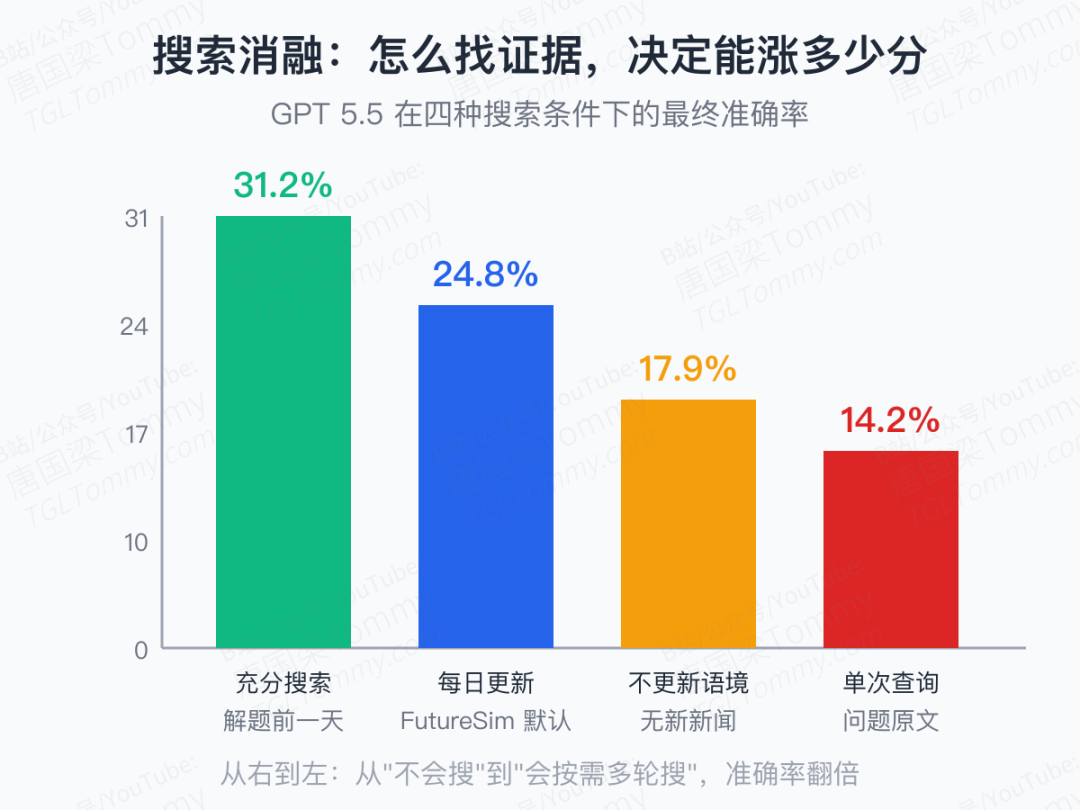
中间那个 17.9%,是关掉"每天新闻入库"得到的结果——意思是说,如果环境里没有新证据流入,agent 哪怕保持搜索能力,最终分数也会显著掉。这两组对比连起来读,就是 FutureSim 想说的关键信号:在动态环境里,"搜什么"比"会不会搜"更难,而"愿不愿意一遍遍搜"决定了你能拿多少分。
第四刀:推理预算。GPT 5.5 在 5 档 reasoning_effort 下的曲线相当干净:
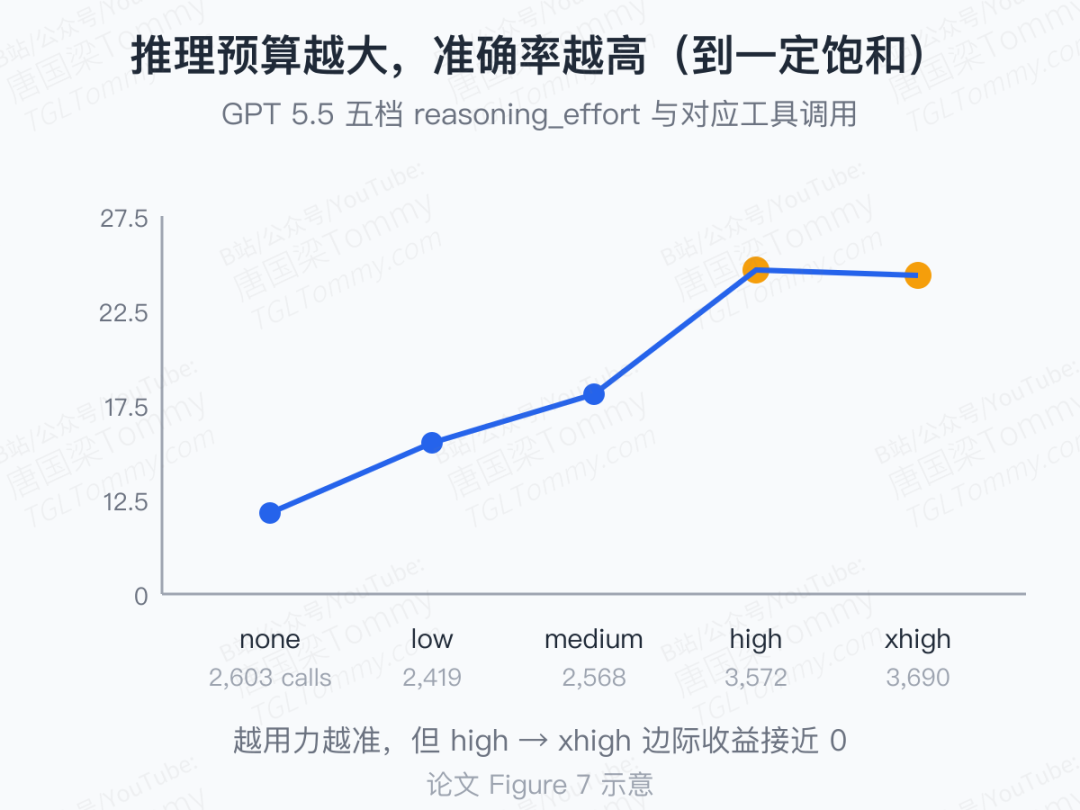
钱花到 high 档之前,准确率几乎线性涨;high 到 xhigh 那一步,差不多就是收益饱和点。换算成实际消耗:xhigh 一次跑要 3690 次工具调用,比 none 多出 40%;准确率却几乎不变。FutureSim 的另一面价值就在这里——它能告诉你"这一刀切下去,到底值不值"。
三个 agent 同场,反而都更像彼此了
作者还顺手做了一个小实验:三个一模一样的 DeepSeek v3.2 agent 同时跑,唯一的"通讯方式"是它们能看到彼此的聚合预测,类似真实预测市场上的"人群均值"。

结果是:单独跑时三个 agent 的概率分布会越拉越散;一旦能看到聚合,它们就开始集体收敛——哪怕系统提示里明确说"你会按差异化得分被奖励",模型还是抗拒不了"往均值靠"的冲动。这种"群体趋同"的发现,对未来研究多 agent 互动、研究 prompt 中的"反思机制"如何稳定不同观点,都是一个干净的起点。
这套测法还有什么限制?
作者自己点了两个边界。第一,FutureSim 只能测 预测性 任务:agent 的行为不能反过来改变环境。一旦预测会引起价格变动(performative prediction)、或者动作会直接改变世界(比如开关物理设备),FutureSim 就不再适用,因为你无法忠实重放一个"被自己改写过的现实"。第二,它对"信息流"的真实程度依赖外部新闻语料;社交媒体上的实时舆情、行情数据这类高频信号,目前不在覆盖范围内——这也是论文里 GPT 5.5 在 Polymarket 类问题上仍稍微滞后人群均值的原因之一。
不过,这两条边界并不削弱 benchmark 的价值。预测一件未发生事件的能力,本身就是衡量 agent 世界模型的最直接方式之一——它要求模型既知道"过去是什么样",也敢于推断"接下来更可能往哪走"。
结语
如果说过去两年 agent benchmark 已经把"做任务"这件事卷得相当饱和,那 FutureSim 想测的,是另一道更不容易被堆参数蛮过去的关:面对一个会自己继续往前长的世界,模型能不能跟着它一起前进。
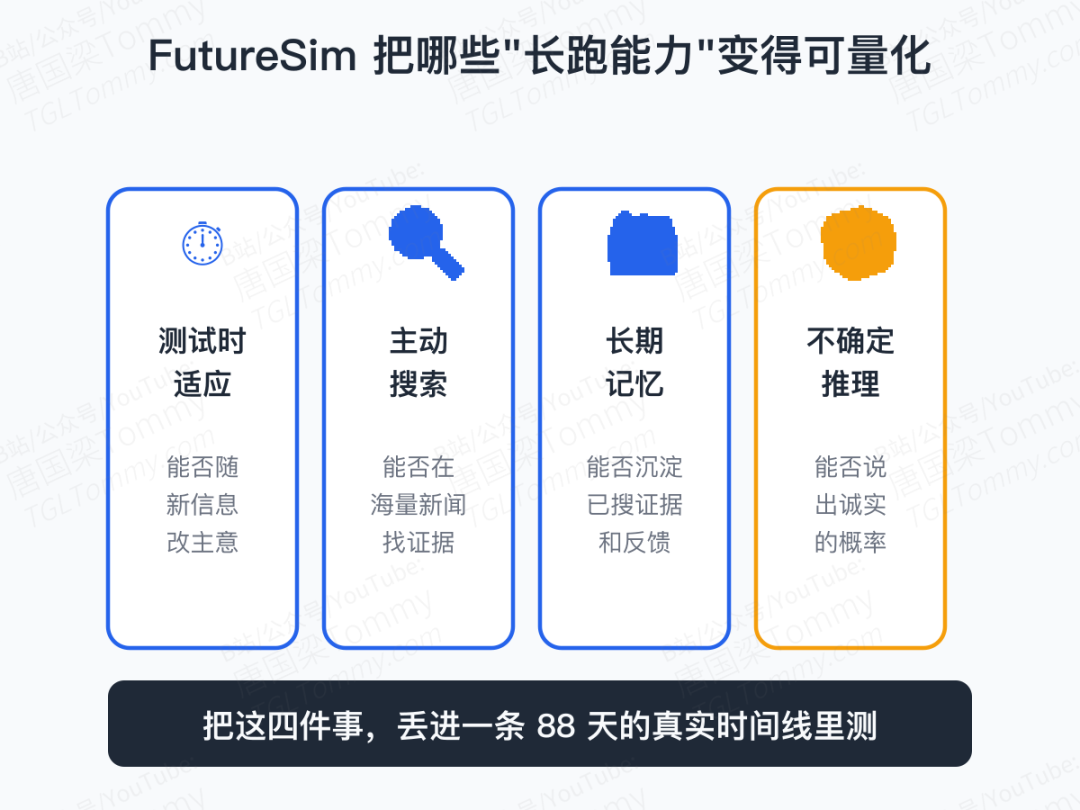
把四个东西捏在一起测——测试时适应、主动搜索、长期记忆、不确定推理——再丢进一条 88 天的真实时间线。然后我们发现:最聪明的那个,也只对了 25%;许多还以为自己很聪明的,干脆不如沉默。
这不是一份排名表,更像一份地图。它告诉我们:在"知识截止日之后"的世界里,前沿模型距离"会推理"还差得很远;而每一项现在被开发者拿来弥补这道差距的工具——更强的 harness、更细的记忆、更主动的搜索、更多的推理 token——都能被这台模拟器干净地量出来。
下一代真正"能跟得上世界"的 agent,多半就会在这种环境里被反复磨。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-05-19,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号