Coinbase把AI支出砍了近一半,Token用量却还在涨

Coinbase把AI支出砍了近一半,Token用量却还在涨

用户11563501
发布于 2026-06-29 12:28:15
发布于 2026-06-29 12:28:15
6月,Coinbase CEO Brian Armstrong 对外公开了一套公司内部的AI成本优化方案,直接晒出了过去三年的AI支出与Token用量对比图。
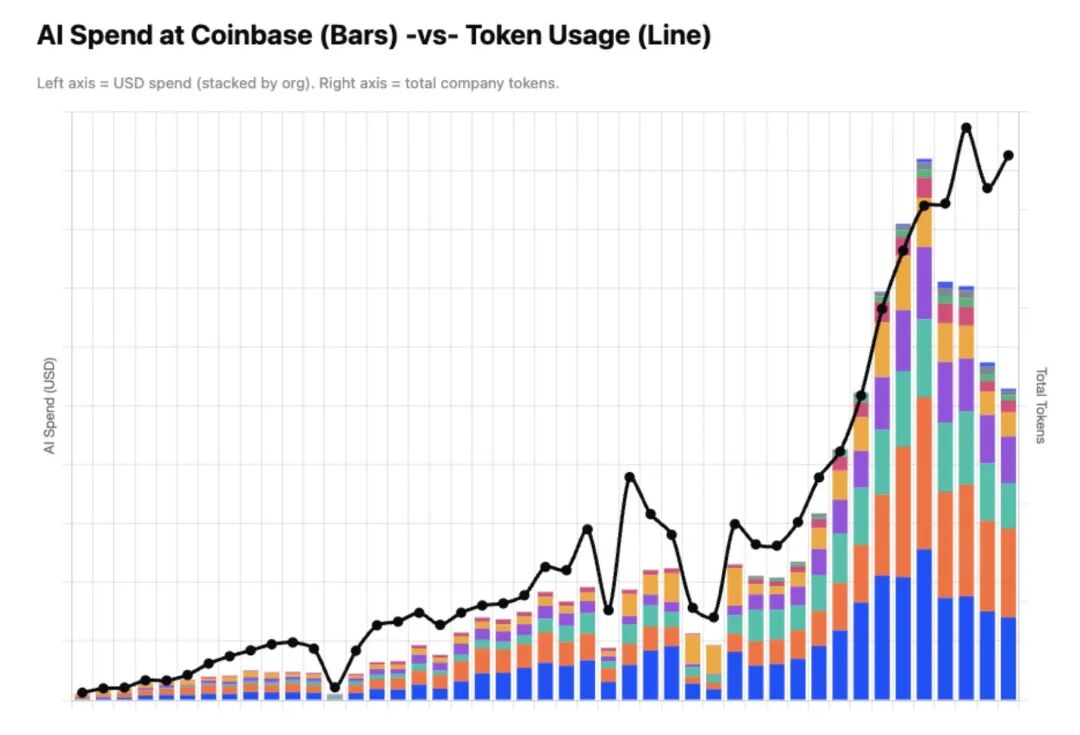
图里的折线是公司总Token用量,全程保持高速增长,堆叠柱状图是各部门的AI美元支出,在方案落地后不涨反降。Brian给出的数据是,整套措施落地后,Coinbase的AI支出直接砍了近一半,Token用量还在持续保持指数级增长。
很多公司控AI成本的第一反应是设用量上限、弹超支告警,Coinbase没有走这条路。他们的核心逻辑并非压制员工用AI,靠的是搭好底层基础设施,让用量的增长是可持续的,具体做了5件事:
1. 优化默认模型配置,而非设置用量上限。工程师可以自由选择任何模型,但系统默认会通过内部LLM网关调用GLM 5.2、Kimi 2.7这类性价比更高的开源模型,只有任务需要时再切换到更贵的前沿大模型。Brian提到,之前公司91%的员工根本碰不到设定的用量上限,设限本质是给自己添堵,不如直接把默认的高成本模型换成更适配大部分场景的平价选项。为了避免效果下降,代码评审环节还会用多模型交叉校验结果。
2. 智能路由匹配模型。他们在自定义的工作流套件里,会先预处理给大模型的指令(Prompt),再根据任务类型、缓存命中情况、不同模型的定价,自动分配最合适的模型。比如做复杂任务规划可以用前沿大模型,但简单执行阶段再用就是浪费。最终目标是完全不用人工选择模型,全部由AI自动完成。
3. 提升缓存复用率。缓存未命中是AI成本飙升的最隐形原因,Coinbase把所有大模型请求都做了缓存感知,尽量复用热缓存,仅在内部LibreChat工具上,缓存命中率就从5%提升到了60%。
4. 保持上下文精简。切换任务就开新会话,文件上下文只纳入必要范围,不用的工具立刻断开连接。核心并非压缩Token用量,是避免浪费Token。
5. 透明的用量可视机制。工程师想用多少Token、用什么模型都可以,但所有人的用量都是公开的,花的AI预算越多,对应的产出预期也越高。
Box CEO Aaron Levie对此的判断更偏向行业层面。他说这些成本优化的方法看起来都是实操细节,但要落地有个前提:你得对具体的业务工作有非抽象的深度理解,光靠调大模型参数没用。
这背后藏着现在所有应用AI公司的核心机会:在具体工作流和底层大模型之间,必须有一层中间层,深度适配企业的业务流程、上下文、内部工作习惯。单个企业自己搭这个层,很难做到规模化复用,所以专门做这个中间层的公司会有极大的市场空间。
这个中间层的核心价值并非来自大模型本身,主要来自针对具体场景做模型效果评估、吃透垂直领域知识、做适配场景的产品功能,再靠现场交付团队(FDE)帮客户完成内部落地和组织适配。对企业客户来说,有了这个适配层,每一块钱的AI预算能买到的有效智能反而更多,ROI会直接拉高。不管是做通用型还是垂直行业型的适配层,现在都是巨大的窗口期。
这条讨论很快引来了上千条行业人士的回复,有踩过坑的,有提不同意见的,也有做相关产品的。
有开发者晒出了一张"无意义指标博物馆"的插图,把"消耗Token数"和"代码行数""故事点""拉取请求数"这些早就被证伪的虚荣指标放在同一个展柜里,暗指很多公司把Token用量当AI落地的KPI,根本不管有没有产生实际价值。

有开发者分享踩坑经验,说前几天自己搭了个Agent集群,忘了加路由规则指定用平价模型,直接跑了一整夜的昂贵大模型,平白烧了一大笔预算。
也有人提出不同意见,有开发者说做这种智能路由的中间层没那么简单,每个大模型的指令规范都不一样,如果不给每个模型单独做适配,最终的效果会很差,波动也不可控。也有人反驳说,大模型的接口和行为规范会慢慢趋同,这个问题长期来看会被解决。
还有投资人提到USV合伙人Nick Grossman之前写的AI栈分层文章,同时指出并非所有中间层都能赚到钱,就像安卓占了手机市场70%的销量,苹果却拿走了行业大部分利润,AI栈里的不同层价值捕获能力天差地别,身份和结算层会集中大部分利润,其他层很快会被竞争拉薄利润。
有做相关产品的公司也下场留言,Redis的团队说他们专门做了面向Agent的Prompt缓存工具Langcache,就是解决缓存复用的问题;还有做开源LLM网关的创业者说自己团队也有类似的落地经验,愿意给Coinbase提供支持。
好的工程本质上就是别开法拉利去买菜。现在很多公司的AI支出还处在野蛮生长阶段,要么舍不得用直接限死配额,要么闭着眼烧钱不看ROI,这套已经跑通的实操方案,不管是对要控成本的企业,还是想做AI中间层的创业者,都是现成的参考。
公司如此,个人开发者其实面临一模一样的问题,只是规模小、没人管、更容易被忽视。订了好几个LLM服务,月底一看账单说不清Token花哪了;Groq免费额度、GitHub Models配额月月过期,OpenAI账单却一直涨;本地跑着Ollama,AI工具还是默认走付费API。开源项目Token Bank (https://github.com/wink-run/local-llm-proxy)做的就是个人版的LLM网关,架在AI工具和各个模型供应商之间,一键接入Claude Code、Cursor、Codex CLI等主流工具,自动做智能路由、缓存压缩、用量可视化,闲置的本地算力还能接入社区P2P网络换积分。
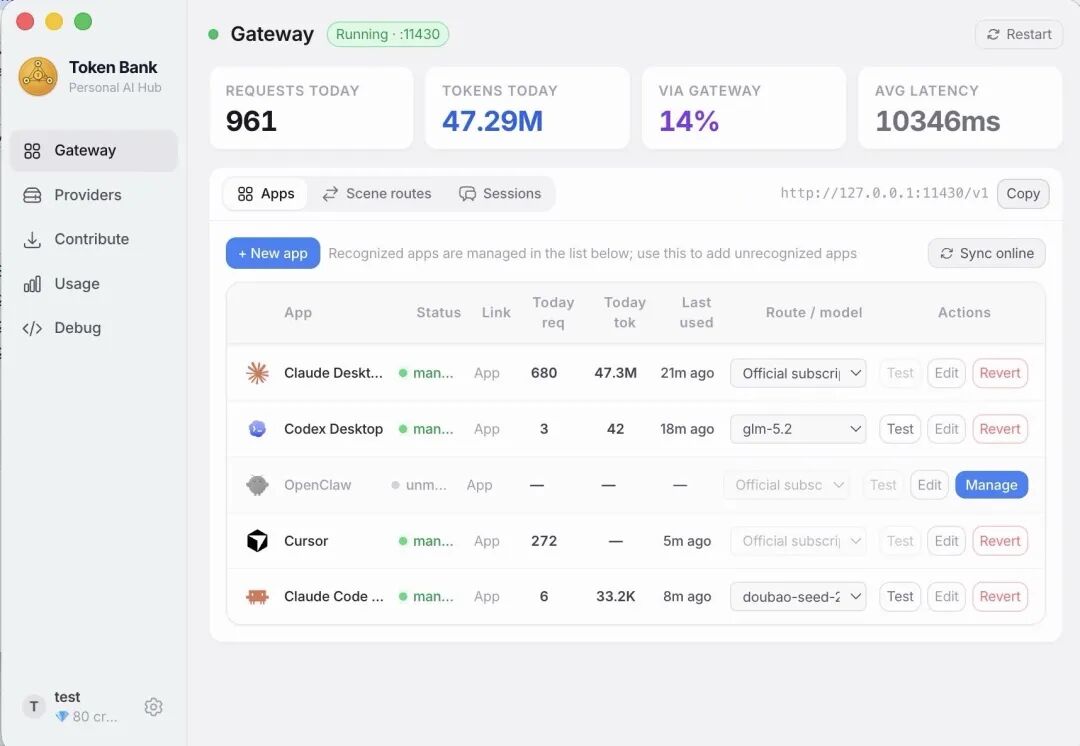
思路跟Coinbase这套企业方案如出一辙,只是做成了个人开箱即用的工具。
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2026-06-29,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号