
按字长计算单词的Python
提问于 2021-04-13 23:46:38
我收到了一个带有文本的.txt文件。我已经清理了文本(去掉标点符号、大写字母、符号),现在我有了一个带有单词的字符串。现在,我正在尝试获取字符串中每个项的字符len()的计数。然后绘制一个图,其中N个字符位于X轴上,Y轴是具有这样N个字符len()的单词数。
到目前为止,我已经:
text = "sample.txt"
def count_chars(txt):
result = 0
for char in txt:
result += 1 # same as result = result + 1
return result
print(count_chars(text))到目前为止,这是在寻找文本的总len(),而不是按单词。
我想得到类似于函数计数器Counter()的东西,它返回单词,并计算它在整个文本中重复的次数。
from collections import Counter
word_count=Counter(text)我想得到每个字的字符#。一旦我们有了这样的数字,策划就会容易一些。
谢谢,一切都有帮助!

回答 2
Stack Overflow用户
回答已采纳
发布于 2021-04-14 02:22:27
看起来被接受的答案并没有解决问题,因为它是由查询者提出的
然后,
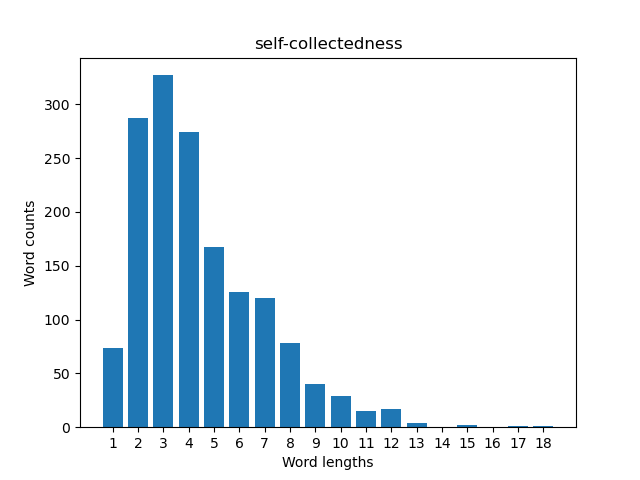
绘制一个图,其中N个字符位于X轴上,Y轴是具有这样N个字符的字数。
import matplotlib.pyplot as plt
# ch10 = ... the text of "Moby Dick"'s chapter 10, as found
# in https://www.gutenberg.org/files/2701/2701-h/2701-h.htm
# split chap10 into a list of words,
words = [w for w in ch10.split() if w]
# some words are joined by an em-dash
words = sum((w.split('—') for w in words), [])
# remove suffixes and one prefix
for suffix in (',','.',':',';','!','?','"'):
words = [w.removesuffix(suffix) for w in words]
words = [w.removeprefix('"') for w in words]
# count the different lenghts using a dict
d = {}
for w in words:
l = len(w)
d[l] = d.get(l, 0) + 1
# retrieve the relevant info from the dict
lenghts, counts = zip(*d.items())
# plot the relevant info
plt.bar(lenghts, counts)
plt.xticks(range(1, max(lenghts)+1))
plt.xlabel('Word lengths')
plt.ylabel('Word counts')
# what is the longest word?
plt.title(' '.join(w for w in words if len(w)==max(lenghts)))
# T H E E N D
plt.show()
Stack Overflow用户
发布于 2021-04-13 23:56:51
好的,首先您需要打开sample.txt文件。
with open('sample.txt', 'r') as text_file:
text = text_file.read()或
text = open('sample.txt', 'r').read()现在我们可以数一下课文中的单词,例如,放在一个小块里。
counter_dict = {}
for word in text.split(" "):
counter_dict[word] = len(word)
print(counter_dict)页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/67087535
复制相关文章









点击加载更多


腾讯云开发者
