
时间序列/滴答数据集的火花变换
我们有表格在蜂巢,存储交易订单数据的每一天结束作为order_date。其他重要专栏有:product、contract、price(订单价格)、ttime (交易时间)状态(插入、更新或删除)E 110价格e 211(订单价格)
我们必须在主表上以滴答数据的方式建立一个图表表,每一行(订单)的最高价格和最低价格订单都是从市场开放到那时为止的。也就是说,对于给定的订单,我们将有4列填充为maxPrice(目前为止的最高价格)、maxpriceOrderId(最高价格的顺序)、minPrice和minPriceOrderId。
这必须是每个产品,合同,即最高和最低价格之间的产品,合同。
在计算这些值时,我们需要从聚合中排除所有已关闭的订单。到目前为止,不包括“删除”状态的订单,即最高和最低的订单价格。
我们正在使用:火花2.2和输入数据格式是地板。输入记录
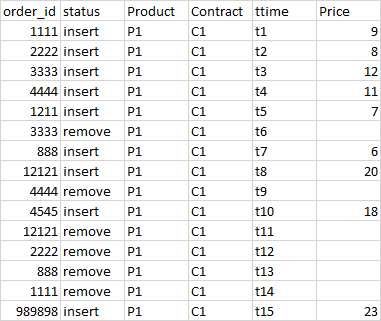
输出记录
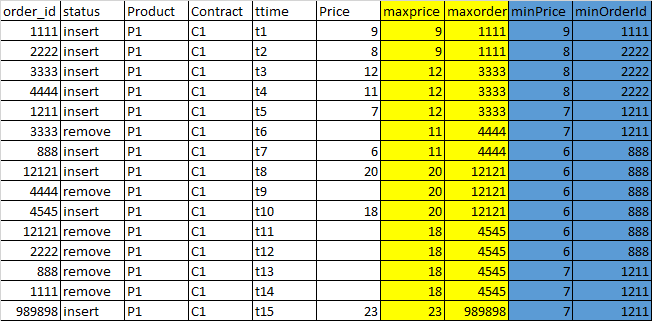
为了给出一个简单的SQL视图--这个问题是用一个自联接解决的,并且看起来是这样的:使用ttime上的有序数据集,我们必须得到特定产品的最高和最低价格,从早上到那个订单的时间,每一行(订单)都有合同。这将在批处理的每个爆炸物处理(order_date)数据集上运行:
select mainSet.order_id, mainSet.product,mainSet.contract,mainSet.order_date,mainSet.price,mainSet.ttime,mainSet.status,
max(aggSet.price) over (partition by mainSet.product,mainSet.contract,mainSet.ttime) as max_price,
first_value(aggSet.order_id) over (partition by mainSet.product,mainSet.contract,mainSet.ttime) order by (aggSet.price desc,aggSet.ttime desc ) as maxOrderId
min(aggSet.price) over (partition by mainSet.product,mainSet.contract,mainSet.ttime) as min_price as min_price
first_value(aggSet.order_id) over (partition by mainSet.product,mainSet.contract,mainSet.ttime) order by (aggSet.price ,aggSet.ttime) as minOrderId
from order_table mainSet
join order_table aggSet
ON (mainSet.produuct=aggSet.product,
mainSet.contract=aggSet.contract,
mainSet.ttime>=aggSet.ttime,
aggSet.status <> 'Remove')写作在火花:
我们从星星之火sql开始,如下所示:
val mainDF: DataFrame= sparkSession.sql("select * from order_table where order_date ='eod_date' ")
val ndf=mainDf.alias("mainSet").join(mainDf.alias("aggSet"),
(col("mainSet.product")===col("aggSet.product")
&& col("mainSet.contract")===col("aggSet.contract")
&& col("mainSet.ttime")>= col("aggSet.ttime")
&& col("aggSet.status") <> "Remove")
,"inner")
.select(mainSet.order_id,mainSet.ttime,mainSet.product,mainSet.contract,mainSet.order_date,mainSet.price,mainSet.status,aggSet.order_id as agg_orderid,aggSet.ttime as agg_ttime,price as agg_price) //Renaming of columns
val max_window = Window.partitionBy(col("product"),col("contract"),col("ttime"))
val min_window = Window.partitionBy(col("product"),col("contract"),col("ttime"))
val maxPriceCol = max(col("agg_price")).over(max_window)
val minPriceCol = min(col("agg_price")).over(min_window)
val firstMaxorder = first_value(col("agg_orderid")).over(max_window.orderBy(col("agg_price").desc, col("agg_ttime").desc))
val firstMinorder = first_value(col("agg_orderid")).over(min_window.orderBy(col("agg_price"), col("agg_ttime")))
val priceDF= ndf.withColumn("max_price",maxPriceCol)
.withColumn("maxOrderId",firstMaxorder)
.withColumn("min_price",minPriceCol)
.withColumn("minOrderId",firstMinorder)
priceDF.show(20)卷统计:
每组(产品、合同)的平均计数为600 K=600 K
这项工作持续了几个小时,但还没有完成,我试着增加内存和其他参数,但没有运气。作业被卡住了,很多次我都有内存问题,Container killed by YARN for exceeding memory limits. 4.9 GB of 4.5 GB physical memory used. Consider boosting spark.yarn.executor.memoryOverhead
另一种方法:
对我们的最低组列(Product)进行重新分区,然后按时在分区中进行排序,这样我们就可以及时收到为mapPartition函数排序的每一行。
在分区级别执行映射分区,同时维护集合(键为order_id,价格为值),以计算最大和最小价格及其顺序。
我们将继续删除状态为“移除”的订单,当我们收到它们时,我们将从收集中删除它们。一旦集合被更新到指定的行中,我们就可以从集合中计算出最大值和最小值,并返回更新后的行。
val mainDF: DataFrame= sparkSession.sql("select order_id,product,contract,order_date,price,status,null as maxPrice,null as maxPriceOrderId,null as minPrice,null as minPriceOrderId from order_table where order_date ='eod_date' ").repartitionByRange(col("product"),col("contract"))
case class summary(order_id:String ,ttime:string,product:String,contract :String,order_date:String,price:BigDecimal,status :String,var maxPrice:BigDecimal,var maxPriceOrderId:String ,var minPrice:BigDecimal,var minPriceOrderId String)
val summaryEncoder = Encoders.product[summary]
val priceDF= mainDF.as[summary](summaryEncoder).sortWithinPartitions(col("ttime")).mapPartitions( iter => {
//collection at partition level
//key as order_id and value as price
var priceCollection = Map[String, BigDecimal]()
iter.map( row => {
val orderId= row.order_id
val rowprice= row.price
priceCollection = row.status match {
case "Remove" => if (priceCollection.contains(orderId)) priceCollection -= orderId
case _ => priceCollection += (orderId -> rowPrice)
}
row.maxPrice = if(priceCollection.size > 0) priceCollection.maxBy(_._2)._2 // Gives key,value tuple from collectin for max value )
row.maxPriceOrderId = if(priceCollection.size > 0) priceCollection.maxBy(_._2)._1
row.minPrice = if(priceCollection.size > 0) priceCollection.minBy(_._2)._2 // Gives key,value tuple from collectin for min value )
row.minPriceOrderId = if(priceCollection.size > 0) priceCollection.minBy(_._2)._1
row
})
}).show(20)这是运行良好,并在20分钟内完成较小的数据集,但我发现23磨记录(有17个不同的产品和合同),结果似乎不正确。我可以看到来自一个分区(输入分割)的数据正在转到另一个分区,从而扰乱了值。
如我所知,map分区在每个星火分区上执行函数(类似于映射减少中的输入分块),所以我如何才能强制spark创建具有该产品和契约组的所有值的inputsplits/分区。
->
当我们被困在这里的时候,我会很感激你的帮助。

回答 2
Stack Overflow用户
发布于 2019-10-07 23:08:16
编辑:这是一个关于为什么许多小文件是坏的文章
为什么压缩不好的数据是坏的?压缩得不好的数据对Spark应用程序不利,因为处理起来非常慢。继续我们前面的例子,每当我们想要处理一天的事件时,我们必须打开86,400个文件才能到达数据。这极大地减缓了处理速度,因为我们的Spark应用程序实际上只花了大部分时间打开和关闭文件。我们通常希望我们的Spark应用程序将大部分时间用于实际处理数据。接下来,我们将进行一些实验,以说明在使用适当压缩的数据时,性能与压缩性能差的数据之间的差异。
我敢打赌,如果你正确地将你的源数据分区到你加入和摆脱所有这些窗口的时候,你最终会在一个更好的地方结束。
每次你点击partitionBy,你都会强迫你洗牌,每次你点击orderBy,你都会迫使你付出昂贵的代价。
我建议您查看Dataset API,并学习一些用于O(n)时间计算的groupBy和平台flatMapGroups/减/滑动。你可以一次就得到你的最小/最高分。
此外,听起来您的驱动程序由于许多小文件问题而耗尽了内存。尽量压缩源数据,并正确划分表。在这种特殊情况下,我建议使用order_date进行分区(可能每天进行?)然后是产品和合同的子分区。
这里有一个片段,我花了大约30分钟编写,并且可能比你的窗口函数运行得更好。它应该在O(n)时间内运行,但如果您有许多小文件问题,它无法弥补。如果有什么遗漏请告诉我。
import org.apache.spark.sql.{Dataset, Encoder, Encoders, SparkSession}
import scala.collection.mutable
case class Summary(
order_id: String,
ttime: String,
product: String,
contract: String,
order_date: String,
price: BigDecimal,
status: String,
maxPrice: BigDecimal = 0,
maxPriceOrderId: String = null,
minPrice: BigDecimal = 0,
minPriceOrderId: String = null
)
class Workflow()(implicit spark: SparkSession) {
import MinMaxer.summaryEncoder
val mainDs: Dataset[Summary] =
spark.sql(
"""
select order_id, ttime, product, contract, order_date, price, status
from order_table where order_date ='eod_date'
"""
).as[Summary]
MinMaxer.minMaxDataset(mainDs)
}
object MinMaxer {
implicit val summaryEncoder: Encoder[Summary] = Encoders.product[Summary]
implicit val groupEncoder: Encoder[(String, String)] = Encoders.product[(String, String)]
object SummaryOrderer extends Ordering[Summary] {
def compare(x: Summary, y: Summary): Int = x.ttime.compareTo(y.ttime)
}
def minMaxDataset(ds: Dataset[Summary]): Dataset[Summary] = {
ds
.groupByKey(x => (x.product, x.contract))
.flatMapGroups({ case (_, t) =>
val sortedRecords: Seq[Summary] = t.toSeq.sorted(SummaryOrderer)
generateMinMax(sortedRecords)
})
}
def generateMinMax(summaries: Seq[Summary]): Seq[Summary] = {
summaries.foldLeft(mutable.ListBuffer[Summary]())({case (b, summary) =>
if (b.lastOption.nonEmpty) {
val lastSummary: Summary = b.last
var minPrice: BigDecimal = 0
var minPriceOrderId: String = null
var maxPrice: BigDecimal = 0
var maxPriceOrderId: String = null
if (summary.status != "remove") {
if (lastSummary.minPrice >= summary.price) {
minPrice = summary.price
minPriceOrderId = summary.order_id
} else {
minPrice = lastSummary.minPrice
minPriceOrderId = lastSummary.minPriceOrderId
}
if (lastSummary.maxPrice <= summary.price) {
maxPrice = summary.price
maxPriceOrderId = summary.order_id
} else {
maxPrice = lastSummary.maxPrice
maxPriceOrderId = lastSummary.maxPriceOrderId
}
b.append(
summary.copy(
maxPrice = maxPrice,
maxPriceOrderId = maxPriceOrderId,
minPrice = minPrice,
minPriceOrderId = minPriceOrderId
)
)
} else {
b.append(
summary.copy(
maxPrice = lastSummary.maxPrice,
maxPriceOrderId = lastSummary.maxPriceOrderId,
minPrice = lastSummary.minPrice,
minPriceOrderId = lastSummary.minPriceOrderId
)
)
}
} else {
b.append(
summary.copy(
maxPrice = summary.price,
maxPriceOrderId = summary.order_id,
minPrice = summary.price,
minPriceOrderId = summary.order_id
)
)
}
b
})
}
}Stack Overflow用户
发布于 2019-10-05 05:38:57
用于重新划分数据的方法-- repartitionByRange在这些列表达式上对数据进行分区,但执行范围分区。您想要的是这些列上的散列分区。
将方法更改为repartition并将这些列传递给它,它应该确保相同的值组在一个分区中结束。
https://stackoverflow.com/questions/58027080
复制







腾讯云开发者
