
在Python中基于交集合并两个表
提问于 2015-08-23 08:38:26
假设我有两张桌子A和B
A是
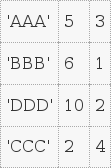
而B是
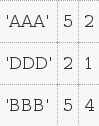
我必须将它们合并,使新表看起来像这样
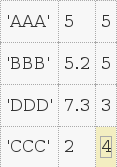
对于A和B中常见的第一元素,我取具有公共第一元素的两行中间元素的加权平均值。例如:
A和B有共同的'AAA',所以我将使用(5 *3+ 5 * 2) / (3 + 2) = 5来计算中间元素。因此第三表的第一行变成'AAA‘,5,3+2=5。
我知道,如果我使用列表,可以通过迭代所有元素来完成这一任务,但是有更快的方法吗?
从注释中编辑:我还在寻找一种使用pandas.DataFrame的更简单的方法

回答 2
Stack Overflow用户
回答已采纳
发布于 2015-08-23 09:52:07
最简单的纯python解决方案是使用类似字典的数据结构,键是您的标签,值对(value = quantity *权重,quantity):
from collections import defaultdict
A = [
('A', 5, 3),
('B', 6, 1),
('D', 10, 2),
('C', 2, 4),
]
B = [
('A', 5, 5),
('D', 2, 1),
('B', 5, 4),
]
# we need to calculate (value, quantity) for each label:
a = {key: [weight * quantity, quantity] for key, weight, quantity in A}
b = {key: [weight * quantity, quantity] for key, weight, quantity in B}
# defaultdict is a dictionary like structure, but able to create
# a new item if key is not found, in our case a new [0, 0] list:
merged = defaultdict(lambda: list((0, 0)))
# let's sum quantities and
for key, pair in a.items() + b.items():
# add both value and quantity respectively
quantity, value = map(sum, zip(merged[key], pair))
merged[key] = [quantity, value]
# now let's calculate means
for key, (quantity, value) in merged.items():
mean = quantity / float(value)
merged[key] = [mean, value]
for item in merged.items():
print item更简单的是它使用的是pandas
import pandas as pd
# first let's create dataframes
colnames = 'label weight quantity'.split()
A = pd.DataFrame.from_records([
('A', 5, 3),
('B', 6, 1),
('D', 10, 2),
('C', 2, 4),
], columns=colnames)
B = pd.DataFrame.from_records([
('A', 5, 2),
('D', 2, 1),
('B', 5, 4),
], columns=colnames)
# we can just concatenate those DataFrames and do calculation:
df = pd.concat([A, B])
df['value'] = df.weight * df.quantity
# sum each group with the same label
df = df.groupby('label').sum()
del df['weight'] # it got messed up anyway and we don't need it
# and calculate means:
df['mean'] = df.value / df.quantity
print df
print(df[['mean', 'quantity']])
# mean quantity
# label
# A 5.000000 5
# B 5.200000 5
# C 2.000000 4
# D 7.333333 3Stack Overflow用户
发布于 2015-08-23 11:21:38
您可以做得更好,但是这里有一个pandas解决方案
In [1]: import pandas as pd
In [2]: import numpy as np
In [3]: df1 = pd.DataFrame({'AAA':np.array([5,3]),'BBB':np.array([6,1]),
.....: 'DDD':np.array([10,2]),'CCC':np.array([2,4])})
In [4]: df2 = pd.DataFrame({'AAA':np.array([5,2]),'DDD':np.array([2,1]),
.....: 'BBB':np.array([5,4])})
In [5]: df = pd.concat([df1,df2])
In [6]: df.transpose()
0 1 0 1
AAA 5 3 5 2
BBB 6 1 5 4
CCC 2 4 NaN NaN
DDD 10 2 2 1
In [7]: vals = np.nan_to_num(df.values)
In [8]: _mean = (vals[0,:]*vals[1,:]+vals[2,:]*vals[3,:])/(vals[1,:]+vals[3,:])
In [9]: _sum = (vals[1,:]+vals[3,:])
In [10]: result = pd.DataFrame(columns = df.columns,data = [_mean,_sum], index=['mean','sum'])
In [11]: result.transpose()
mean sum
AAA 5.000000 5
BBB 5.200000 5
CCC 2.000000 4
DDD 7.333333 3这可能不是最优雅的解决方案,但能完成任务。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/32168968
复制相关文章








点击加载更多


腾讯云开发者
