
条件which.min函数
提问于 2018-01-09 14:21:49
我有两套数据,一组是机器坐标,一组是最近的修理厂的坐标。
我有一个工作模型,把每台机器分配到最近的商店。然而,一个商店只有一台机器,而另一家商店有7台机器分配给它。
我想要的是添加一个条件,以便为每个商店分配至少2台机器,但不超过4台。
library(geosphere)
library(ggplot2)
#machine Locations
machine.x <- c(-122.37, -111.72, -111.87, -112.05, -87.17, -86.57, -86.54, -88.04, -86.61, -88.04, -86.61)
machine.y <- c(37.56, 35.23, 33.38, 33.57, 30.36, 30.75, 30.46, 30.68, 30.42, 30.68, 30.42)
machines <- data.frame(machine.x, machine.y)
#store locations
store.x <- c(-121.98, -112.17, -86.57)
store.y <- c(37.56, 33.59, 30.75)
stores <- data.frame(store.x, store.y)
centers<-data.frame(x=stores$store.x, y=stores$store.y)
pts<-data.frame(x=(machines$machine.x), y=(machines$machine.y))
#allocate space
distance<-matrix(-1, nrow = length(pts$x), ncol= length(centers$x))
#calculate the dist matrix - the define centers to each point
#columns represent centers and the rows are the data points
dm<-apply(data.frame(1:length(centers$x)), 1, function(x){ replace(distance[,x], 1:length(pts$x), distGeo(centers[x,], pts))})
#find the column with the smallest distance
closestcenter<-apply(dm, 1, which.min)
#color code the original data for verification
colors<-c(stores)
#create a scatter plot of assets color coded by which fe they belong to
plot(pts, col=closestcenter, pch=9)
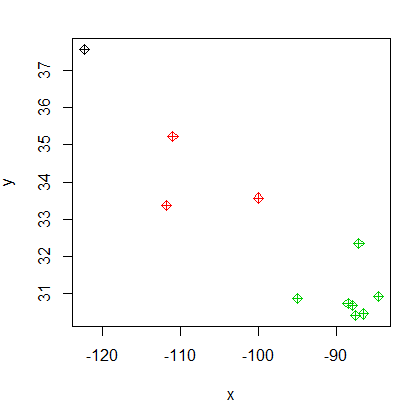
所以,我想让每个小组的最小计数为2,最大计数为4,我试着在最近的中心变量中添加一个if get语句,但它甚至没有达到我认为的那样。我已经在网上查看过了,但是找不到任何方法将计数条件添加到which.min语句中。
注意:我的实际数据集有几千台机器和100多个商店。

回答 1
Stack Overflow用户
回答已采纳
发布于 2018-01-09 16:20:12
如果M是一个11×3的0-1矩阵,其中Mi,j=1,如果机器I被分配存储j和0,那么M的行必须每个和为1,列必须每个和到2到4(含2到4),我们希望选择这样一个M,它可以最小化距离sum(M * dm)的和。这将给我们0-1线性规划,如下所示。在A下面,A %*% c(M)和rowSums(M)是一样的。而且,B是这样的,B %*% c(M)和colSums(M)是一样的。
library(lpSolve)
k <- 3
n <- 11
dir <- "min"
objective.in <- c(dm)
A <- t(rep(1, k)) %x% diag(n)
B <- diag(k) %x% t(rep(1, n))
const.mat <- rbind(A, B, B)
const.dir <- c(rep("==", n), rep(">=", 3), rep("<=", 3))
const.rhs <- c(rep(1, n), rep(2, k), rep(4, k))
res <- lp(dir, objective.in, const.mat, const.dir, const.rhs, all.bin = TRUE)
res
## Success: the objective function is 9025807
soln <- matrix(res$solution, n, k)这个解决方案:
> soln
[,1] [,2] [,3]
[1,] 1 0 0
[2,] 1 0 0
[3,] 0 1 0
[4,] 0 1 0
[5,] 0 1 0
[6,] 0 0 1
[7,] 0 0 1
[8,] 1 0 0
[9,] 0 0 1
[10,] 0 1 0
[11,] 0 0 1或者根据分配给每台机器的存储号向量:
c(soln %*% (1:k))
## [1] 1 1 2 2 2 3 3 1 3 2 3页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/48177489
复制相关文章







腾讯云开发者
