
矩阵乘法性能,int对偶数
我正在使用MPI来尝试矩阵乘法,并想寻求一些帮助来解决一个问题。该机器有6核,32 L3 L1缓存,256 L3 L2缓存和15 L3 L3缓存。乘法是这样的:
vector<vector<double>> mult_mpi(vector<vector<double>> m,
vector<vector<double>> n) {
int rows = m.size();
int size = n.size();
vector<vector<double>> r(rows, vector<double>(size));
for (int i = 0; i < rows; ++i)
for (int k = 0; k < size; ++k)
for (int j = 0; j < size; ++j)
r[i][j] += m[i][k] * n[k][j];
return r;
}我对int也有同样的要求
vector<vector<int>> mult_mpi(vector<vector<int>> m, vector<vector<int>> n);然后我做了一些情节,不同的线条颜色表示节点的数量。
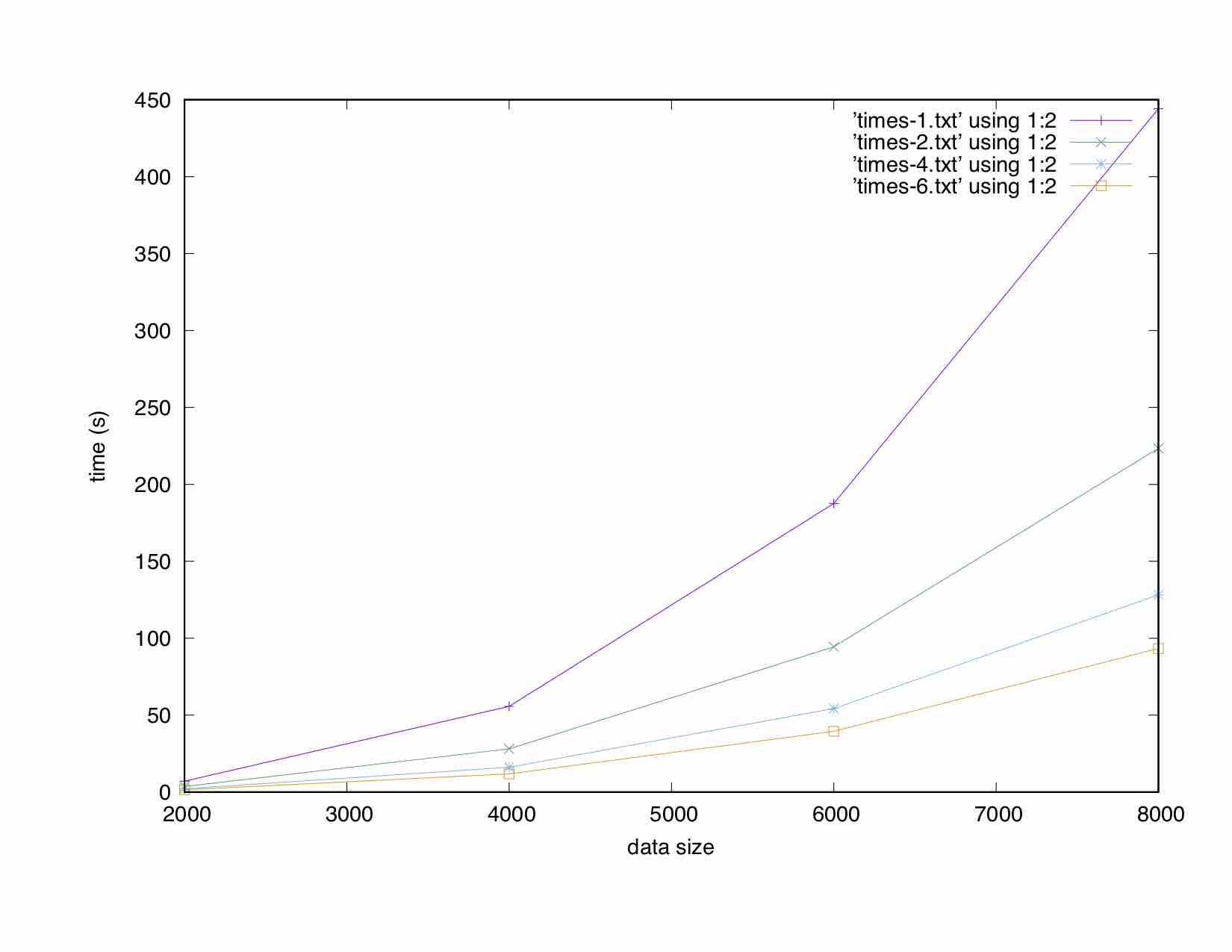
下面的图显示了两个int矩阵相乘所花费的时间:
下面的图显示了两个双矩阵相乘所花费的时间:
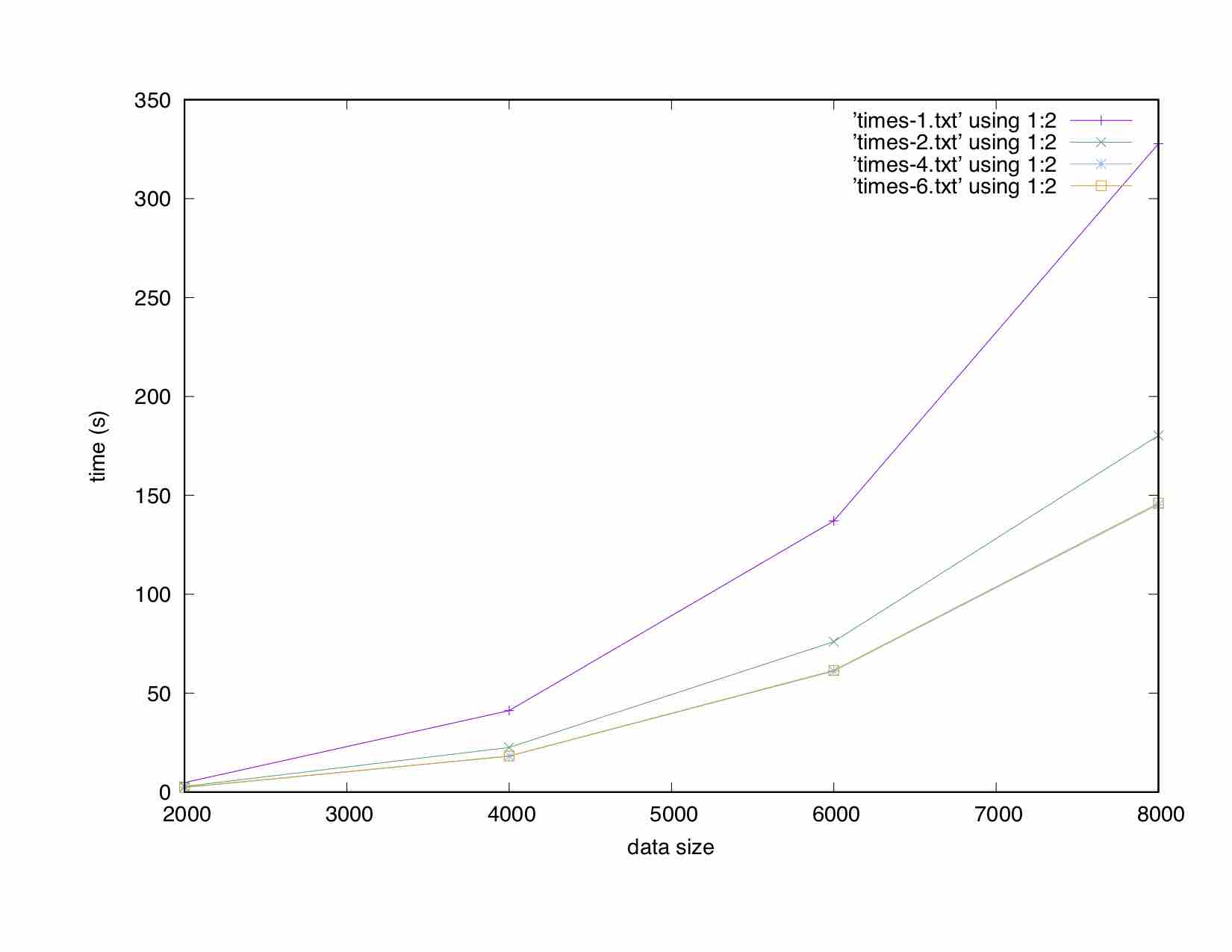
为什么在双情况下,4节点和6节点的时间相同?我是不是遇到了内存带宽的限制?
最后一个小时我试了好几次,结果一样。还检查了top的机器负载,但在我看来,我是孤独的。

回答 1
Stack Overflow用户
发布于 2018-07-25 11:22:25
你确定你没有计时4K向量的分配<‘>的…?
vector<vector< >>不是一种适合于挤压最佳性能的类型。矩阵乘法是关于内存访问的可扩展性和“计算密度”的最佳操作之一。实际上,操作规模为O(N^3),而数据数为O(N^2)。
实际上,它是用来对top500最快系统进行基准测试的:HPL是用于“高性能linpack”的,是linpack的一个线性代数的参考实现。猜怎么着..。基准测试中使用的操作是DGEMM,即“双精度GEneral矩阵乘”。
DGEMM是BLAS库中运算的名称,是线性代数的事实上的标准.现在有许多本地优化的BLAS库(INTEL MKL,IBM ESSL,.)和开源(阿特拉斯),但它们都使用相同的原始(最初的fortran,现在也是C)的BLAS接口。(注意:最初的实施没有优化)
基于BLAS,也有LAPACK库:系统求解器,特征系统,.也有优化的lapack库,但是通常90%的性能是通过使用优化的BLAS库来压缩的。
我很清楚一个(不是唯一一个.HPL是另一个功能强大的基于MPI的并行库,即SCALAPACK,它包含PBLAS (PBLAS)。一个优化和并行版本的DGEMM和其他东西。
SCALAPACK附带鼻涕虫,您可以找到块循环分布的极好解释,这是用于挤压并行系统上最优性能排列线性代数问题的数据分配策略。
然而,要获得最佳性能,您需要将MPI可执行文件与本地优化的BLAS库链接起来。或者写你自己的,但你并不孤单,所以不要重新发明轮子。
局部优化不是按行访问矩阵,也不是按列访问矩阵,而是通过块访问矩阵。随着块大小的调整,以优化缓存和/或TLB的使用(我还记得刚才的libgoto,另一个blas库,为了最小化TLB错误而优化的),达到并超过了一些系统英特尔MKL.很久以前)。例如,在此阿特拉斯纸中查找更多信息。
无论如何,如果你真的想.在尝试制造我的车轮之前,我会开始分析其他车轮是如何锻造的;)
https://stackoverflow.com/questions/51514536
复制







腾讯云开发者
