操作场景
操作步骤
实例环境准备
1. 参见 创建 NVIDIA GPU 实例 创建一台实例。其中:
实例:计算型 PNV6,类型选择 PNV6.32XLARGE1280 或 PNV6.96XLARGE2304,两规格均搭载 8 块 GPU 卡。
镜像:推荐使用 TencentOS Server 3.1 (TK4)。
驱动:推荐您使用 535 以上 GPU 驱动 + 12.4 CUDA。
1. 进入 CVM 购买页,计费模式选择按量计费、选择地域可用区,架构选择异构计算,实例族选择 GPU 机型,类型选择 8卡 PNV6 规格。
2. 镜像选择 TencentOS Server 3.1 (TK4) 镜像,勾选后台自动安装 GPU 驱动。如下图所示:
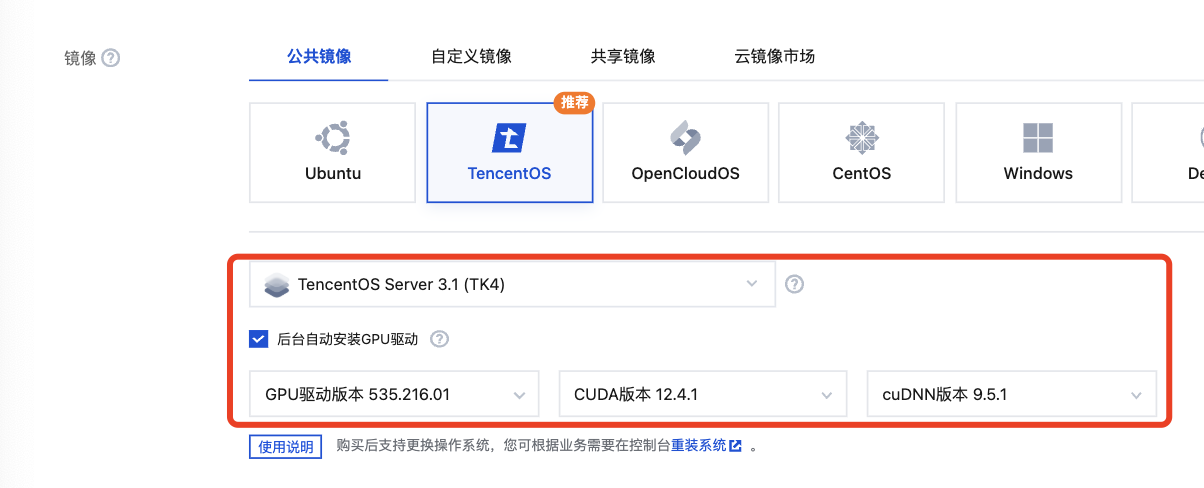
3. 云盘规格按需选择,建议准备大于 800G 的存储空间。完成 VPC 网络、公网资源、安全组、实例名称、登录方式等配置后提交订单。
2. 配置容器环境。
curl -s -L http://mirrors.tencent.com/install/GPU/taco/get-nvidia-docker2.sh | sudo bash
3. 准备存储空间。
方式一:使用 CFS Turbo 文件系统 挂载到实例内 /cfs 目录。
方式二:如果使用云硬盘存储模型,建议准备大于 800G 的存储空间,需要 初始化云硬盘,将该磁盘挂载到实例内 /data 挂载点。
下载模型权重
1. 进入准备好的存储目录 /data 或 /cfs,根据需要选择命令下载模型权重:
# 上海地域 DeepSeek R1wget https://haihub-model-1251001002.cos.ap-shanghai.myqcloud.com/DeepSeek-R1_1739186633750.zip# 南京地域 DeepSeek R1wget https://haihub-model-nj-1251001002.cos.ap-nanjing.myqcloud.com/DeepSeek-R1_1739186633750.zip# 上海地域 DeepSeek V3wget https://haihub-model-1251001002.cos.ap-shanghai.myqcloud.com/DeepSeek-V3_1739186651905.zip# 南京地域 DeepSeek V3wget https://haihub-model-nj-1251001002.cos.ap-nanjing.myqcloud.com/DeepSeek-V3_1739186651905.zip# 可选,附加下载,上面四个必选其一下载# 注意:当前 DeepSeek R1 权重为旧版本,可能无法触发思维链,如有强制思维链的需求,使用最新版 tokenizer.json 替换即可wget https://haihub-model-1251001002.cos.ap-shanghai.myqcloud.com/tokenizer_config.json
2. 解压下载好的模型权重:
UNZIP_DISABLE_ZIPBOMB_DETECTION=TRUE nohup unzip DeepSeek-R1_xxxxxxxxxxxxx.zip -d ./DeepSeek-R1 &
3. 解压完毕后,检查模型权重文件解压文件序号是否连续完整。
部署推理服务
1. 拉取推理容器镜像。
# -v 映射到容器里面的目录根据实际情况调整# 将宿主机内下载地址 /data 或 /cfs 映射到 docker 目录docker run \\-itd \\--gpus all \\--privileged --cap-add=IPC_LOCK \\--ulimit memlock=-1 --ulimit stack=67108864 \\-v /data0:/data \\-v /cfs:/cfs \\--net=host \\--ipc=host \\--name=sglang_tencent aicompute.tencentcloudcr.com/aibench/sglang:0.4.3post4_tencent
2. 进入容器镜像。
docker exec -it sglang_tencent bash
3. 启动推理服务。
# --model-path 修改为模型权重所在地址# --tp 8 单机部署为8# 如果测试性能指标,可以使用 --disable-radix-cache 参数以禁用 prefill cache,避免因为缓存命中率影响nohup python3 -m sglang.launch_server --model-path /data/DeepSeek-R1 --tp 8 --disable-radix-cache --trust-remote-code --mem-fraction-static 0.9 --host 0.0.0.0 --port 30030 2>&1 > ds_infer_$(date +'%Y%m%d_%H%M%S').log &
在当前路径查看日志文件
ds_infer_$(date +'%Y%m%d_%H%M%S').log,检查节点启动日志查看推理服务是否正常启动以及监听端口是否正常,若日志中有以下提示,则表明推理服务已正常部署:
模型互动体验
打开一个新的终端页面,向刚部署的推理服务发送请求:
# 若在其他服务器访问推理服务,127.0.0.1可以改成部署服务节点 eth0 对应 IP ,访问端口号需要与启动推理服务的端口号保持一致,推理服务使用的是30030# model 需要指定为 server 的 model 名 /data0/DeepSeek-R1# stream 参数开启决定是否流式输出,以下为流式输出交互命令curl -X POST \\-H "Content-Type: application/json" \\-H "Authorization: Bearer ''" \\-d '{"model": "/data0/DeepSeek-R1","messages": [{"role": "user", "content": "你好!请帮我制定一个去大理游玩的计划!"}],"temperature": 0.7,"stream": true}' \\"http://127.0.0.1:30030/v1/chat/completions"# stream 参数开启决定是否流式输出,以下为非流式输出交互命令curl -X POST \\-H "Content-Type: application/json" \\-H "Authorization: Bearer ''" \\-d '{"model": "/data0/DeepSeek-R1","messages": [{"role": "user", "content": "你好!请帮我制定一个去大理游玩的计划!"}],"temperature": 0.7}' \\"http://127.0.0.1:30030/v1/chat/completions"
若选择非流式输出,可以看到如下返回:




