数据湖计算 DLC 提供的 SQL 编辑器支持使用统一的 SQL 语句进行数据查询,兼容 SparkSQL,您使用标准 SQL 即可完成数据查询任务,详细语法说明可参见 SQL 语法。
您可以通过数据探索进入 SQL 编辑器,在编辑器内可完成简单的数据管理、多 Session 的数据查询、查询记录管理、下载记录管理。
数据管理
数据管理支持新增数据源、数据库管理及数据表管理。
新建数据目录
目前数据湖计算 DLC 支持管理 COS 及 EMR Hive 的数据目录。操作步骤如下。
1. 登录 数据湖计算 DLC 控制台,选择服务地域,登录角色需要管理员权限。
2. 进入数据探索,鼠标移入库表列表上方的
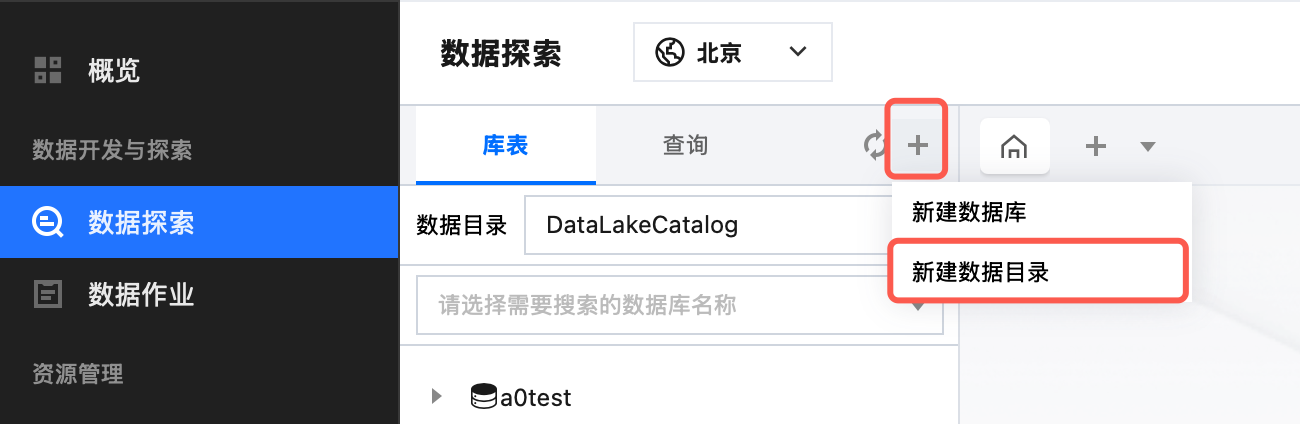
数据库管理
数据表管理
默认数据库切换
使用 SQL 编辑器时,可以指定查询任务的默认数据库,指定后若在查询语句中未声明数据库,则查询将在默认数据库下执行。
1. 登录 数据湖计算 DLC 控制台,选择服务地域。
2. 进入数据探索,鼠标悬停需指定的数据库名称,单击
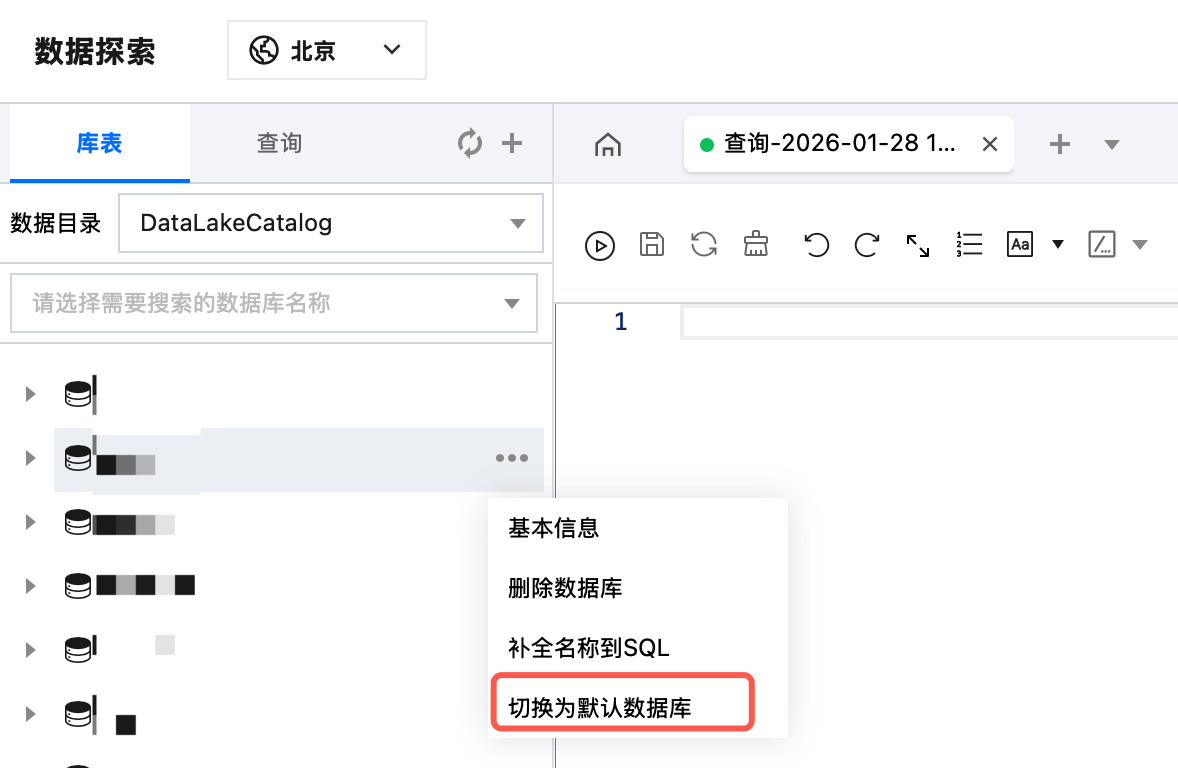
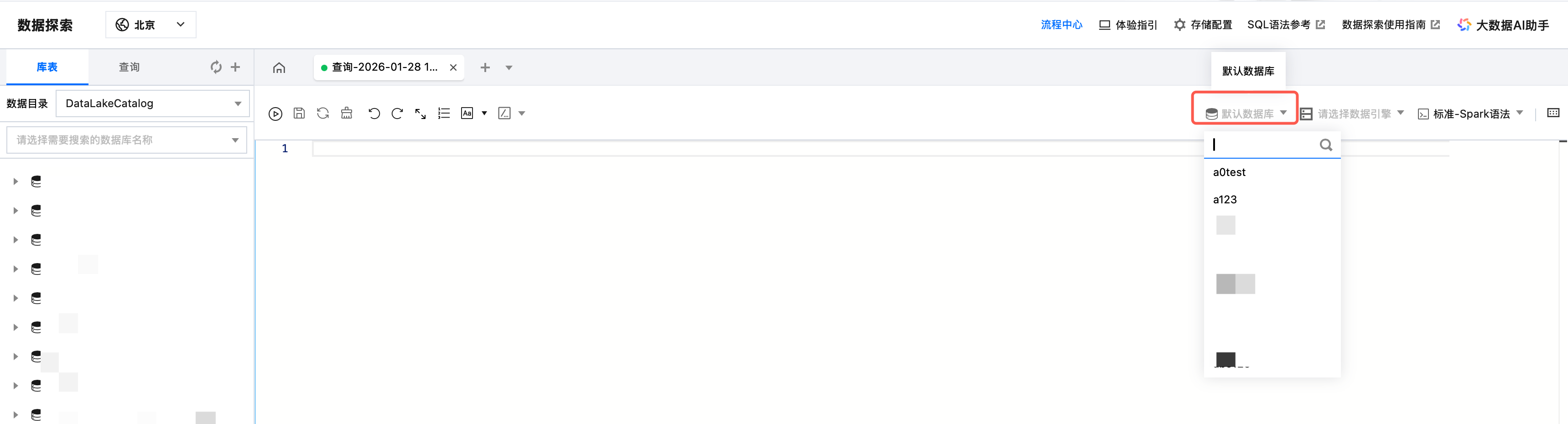
3. 也可直接在默认数据库选择框切换。
数据查询
添加查询页面
SQL 编辑器支持添加多个页面进行数据查询,每个查询页面内的配置独立(默认数据库、使用的计算引擎、查询记录等),方便用户进行多个任务运行及管理。
您可以通过单击

为了方便您的查询使用,常用的查询页您可以单击保存按钮进行保存,同时您可以通过单击

针对已保存的查询页面信息,您可以单击刷新按钮来更新同步已保存的信息,保证查询语句的准确性。
编辑器支持同时运行多个不同的 SQL 语句,单击运行按钮将会把编辑器内所有的 SQL 语句运行,同时拆分为多个 SQL 任务。
如需运行部分语句,可选中需运行的语句后单击运行。
引擎参数配置
选择数据引擎后,支持对数据引擎进行参数配置,选择数据引擎后,在高级设置单击添加即可进行配置。
引擎 | 配置名称 | 初始值 | 配置说明 |
SparkSQL | spark.sql.files.maxRecordsPerFile | 0 | 写入单个文件的最大记录数。 如果该值为零或为负,则没有限制。 |
| spark.sql.autoBroadcastJoinThreshold | 10MB | 配置执行连接时,将广播到所有工作节点的表的最大字节大小。 通过将此值设置为“-1”,可以禁用广播功能。 |
| spark.sql.shuffle.partitions | 200 | 默认分区数。 |
| spark.sql.sources.partitionOverwriteMode | static | 该值为 static 且不指定分区时,在执行覆盖写操作之前,会删除所有符合条件的分区。 举例说明:分区表中有一个“2022-01”的分区,当使用 INSERT OVERWRITE 语句向表中写入“2022-02”这个分区的数据且不指定partition分区时,会把“2022-01”的分区数据也覆盖掉。如果指定“2021-02”分区写入那么“2021-01”不会被覆盖。 当该值为 dynamic 时,不会提前删除分区,而是在运行时覆盖那些有数据写入的分区。 |
| spark.sql.files.maxPartitionBytes | 128MB | 读取文件时要打包到单个分区中的最大字节数。 |
Presto | use_mark_distinct | true | 决定引擎在执行 distinct 函数时是否进行数据重分布。 如果查询中多次调用 distinct 函数,推荐将该参数设置为 false。 |
| USEHIVEFUNCTION | true | 执行查询时是否使用 Hive 函数;如需使用 Presto 原生函数,请将参数设置为 false。 |
| query_max_execution_time | - | 用于设置查询超时,在查询执行的时间超过设置的时间后,查询会被终止。单位支持 d-天,h-小时,m-分钟,s-秒,ms-毫秒(举例:1d 代表1天,3m 代表3分钟)。 |
| dlc.query.execution.mode | async | 引擎查询执行模式,默认为 async 模式, 该模式任务会完成全量查询计算,并将结果保存到 COS,再返回给用户,允许用户在查询完成后下载查询结果。 用户也可以将该值改为 sync,在 sync 模式下,查询不一定会执行全量计算,部分结果可用后,会直接由引擎返回给用户,不再保存到 COS。因此用户可获得更低查询延迟和耗时, 但结果只在系统中保存30s。推荐不需要从 COS 下载完整查询结果,但期望更低查询延迟和耗时使用该模式,例如查询探索阶段、BI 结果展示。 |
说明:
presto 引擎已下线,仅供存量用户使用。
Presto 运行模式
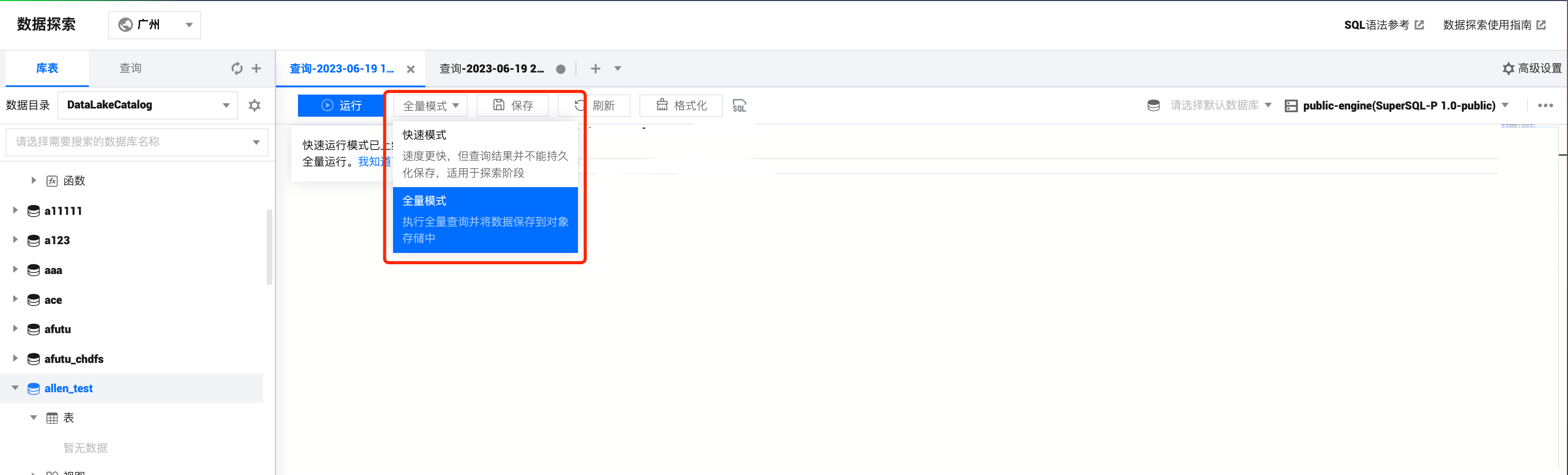
当用户选择的引擎为 Presto 引擎时,数据探索运行支持用户选择“快速模式”运行或“全量模式”运行
快速查询:速度更快,但查询结果并不能持久化保存,适用于探索阶段。
全量模式:执行全量查询并将数据保存到对象存储中。
查询结果
通过 SQL 编辑器可直接查看查询结果,可以通过单击

控制台单个任务最多会返回1000条结果,如需更多结果可使用 API。API 相关操作说明可参见 API 文档。
查询结果在未指定 COS 存储路径情况下支持下载到本地,详细说明可参见 获取任务结果。
查询统计数据
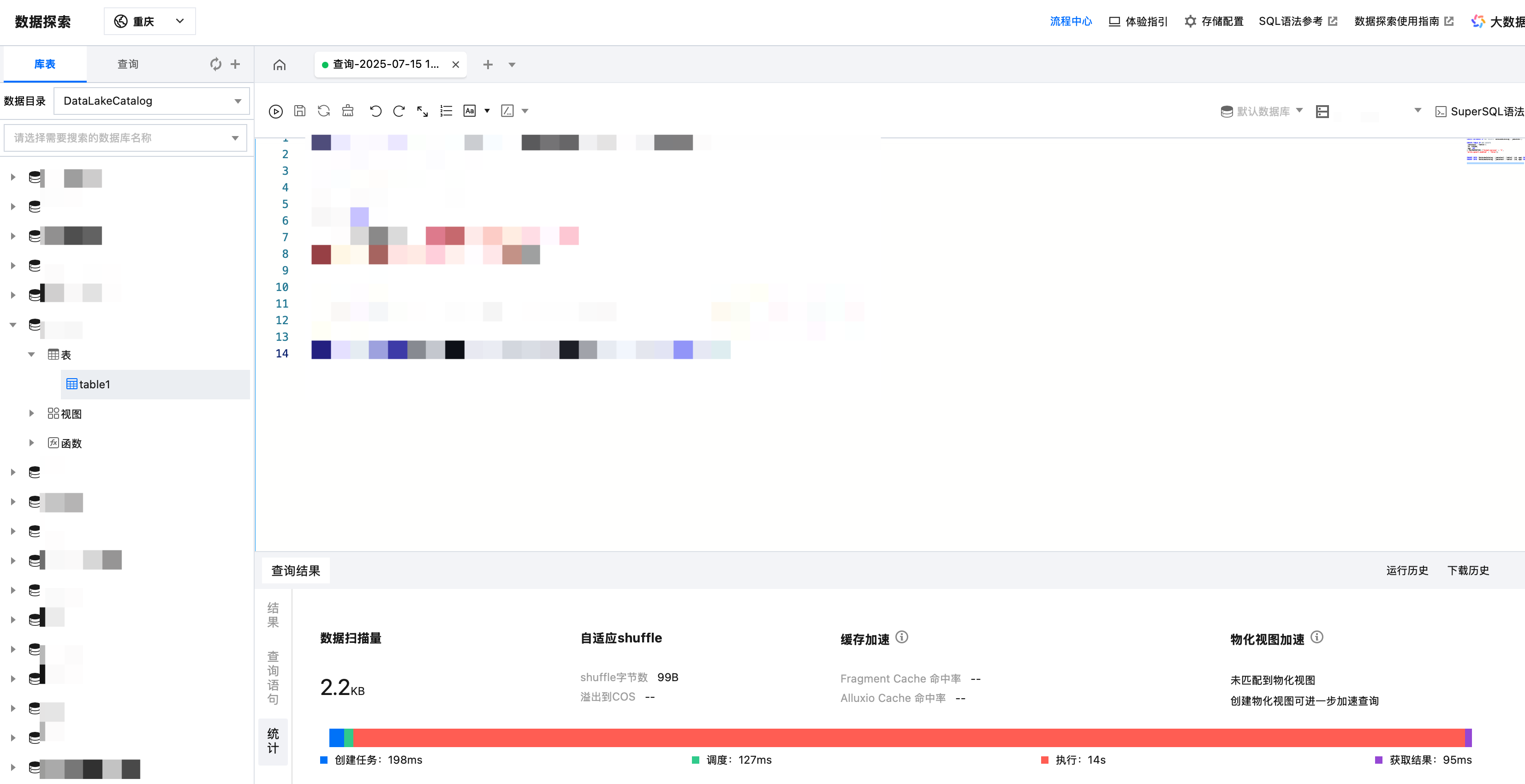
Presto 引擎和 SparkSQL 引擎下的查询结果,支持展示不同特性的优化量化。
SparkSQL 引擎支持查看:
1. 数据扫描量
2. 缓存加速
3. 自适应 shuffle
Presto 引擎支持查看:
1. 数据扫描量
2. 缓存加速
单击统计数据栏,即可查阅查询结果的统计数据与优化建议。
历史运行查询
下载历史管理
每个查询结果的下载任务可在下载历史中查看,可查询下载任务状态及相关参数信息。




