LLM 服务部署的挑战
与传统 AI 场景不同,大语言模型服务关注多个维度的性能指标,它们最终对应不同层次的用户体验和服务质量。这些指标大体概括起来分为4个:
首字延迟(L1)
定义为 LLM 服务处理完 prompt 输出第一个 token 的延时,决定了用户从输入请求到获得响应的时间。对于实时的在线应用,低延迟很重要。但对偏离线的应用则该指标没有那么重要。该指标的好坏通常取决于推理引擎处理 prompt 并生成首字的时间。
解码延迟(L2)
定义为每个用户请求生成后续输出的平均响应时间,也是用户直观体验模型执行快慢的时间。假设执行速度是平均每 Token 100毫秒,则用户平均每秒可以得到10个 Tokens 的输出,每分钟 450 左右英文词。
请求延迟(L3)
定义为对给定用户产生完整响应的延迟。计算规则:L3 = L1 + L2 × 生成的 Token 数。
吞吐
定义为推理服务器面对全部用户和他们请求的流量时每秒可以生成的 Token 数量。
部分推理引擎只关注或对上述某个指标有较好效果。而 TACO-LLM 均衡关注上述全部指标,并对各指标的实际部署效果均实现了全流程的优化。
LLM 部署的挑战来源于几个方面:
当前主流的 decoder-only 模型都具备自回归解码属性。模型生成输出是一个串行的计算过程。下一个输出依赖上一个输出。因此很难发挥出 GPU 或其他加速硬件的并行加速能力。同时,较低的 Arithmetic Intensity 对显存带宽的利用也提出了挑战。
大模型的大对显存容量提出了最直接的挑战。
传统的 Transformer 推理框架将 KV-Cache 按 batchsize 和 sequence length 维度组织数据,这会导致两个潜在的性能陷阱:
请求的输出有长有短。这种数据组织方式需要等一个 Batch 中最长输出长度的请求计算完才能完成整个 Batch 的计算。在此之前,新的请求无法开始计算。而已计算完的请求,只能进行无效计算,消耗有效算力。同时,这种方式管理显存效率较低,无法做到“实用实销”,且随着不同请求计算过程中的显存使用,会造成显存碎片,进一步加剧资源瓶颈。
目前很多优秀的 attention 加速技术实际上是按上述数据 layout 来实现的。例如 flash-attention、flash-decoding 等。这意味着更高效的重新设计,例如下文中提到的 Paged Attention 技术将无法直接享受到社区优化红利,仍给我们留出了进一步的优化空间。
为了有效应对上述挑战,腾讯云异构计算研发团队倾力打造了一款面向生产的 LLM 推理引擎。全方位应对上述挑战。
Continuous Batching
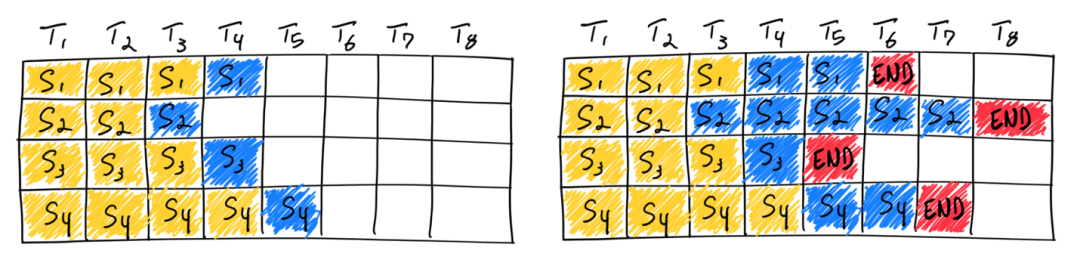
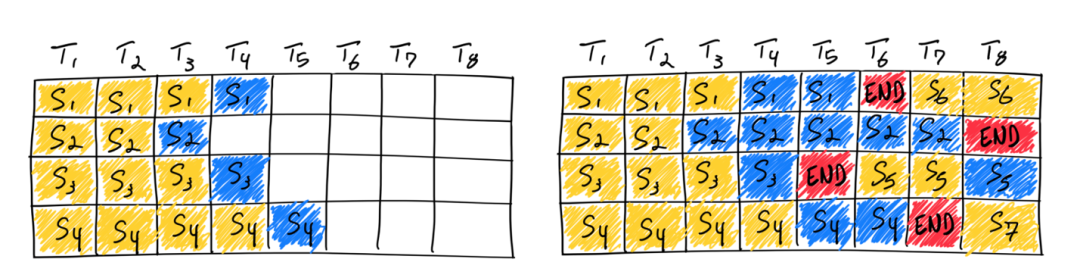
传统的 Batching 方式被称为 Static Batching。如上文所述,Static Batching 方式需要等一个Batch 中最长输出长度的请求完成计算,整个 Batch 才完成返回,新的请求才能重新 Batch 并开始计算。因此,Static Batching 方式在其他请求计算完成,等待最长输出请求计算的过程中,严重浪费了硬件算力。TACO-LLM 通过 Continuous Batching 的方式来解决这个问题。Continuous Batching 无需等待 Batch 中所有请求都完成计算,而是一旦有请求完成计算,即可以加入新的请求,实现迭代级别的调度,提高计算效率。从而实现较高的 GPU 计算利用率。
Static Batching
Continuous Batching
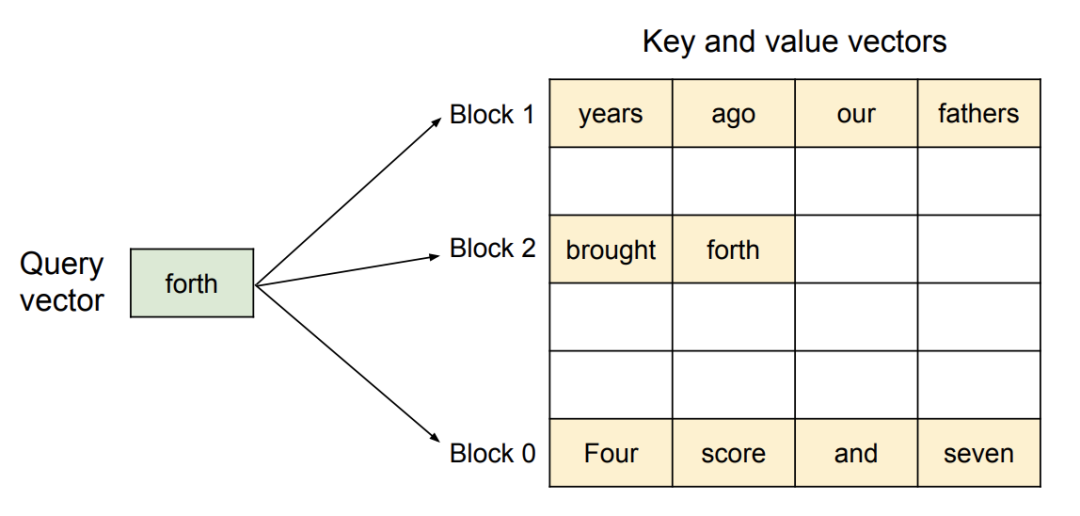
Paged Attention
大模型推理计算性能优化一个常用的方式是 KV-Cache 技术。Transformer 层的 attention 组件计算当前 Token value 值时,需要依赖之前 Token 序列的 Key 和 Value 值。KV-Cache 通过存储之前 Token 序列的 Key 和 Value 的值,避免后续计算中,重复计算 Key 和 Value 值,提高整体计算性能,是一种以空间换时间的优化策略。
传统的 KV-Cache 实现机制是在显存中提前预留一块连续的存储空间来存储 Key 和 Value 值。但是,随着存储资源的分配和释放,显存中会存在很多“碎片”。某些情况下,虽然剩余的显存总量大于 KV-Cache 所需,但是由于不存在一块连续的存储空间可以满足 KV-Cache,计算也无法进行。
Paged Attention 是一种新的 KV-Cache 实现方式,它从传统操作系统的概念中获得灵感,例如分页和虚拟内存,允许 KV-Cache 通过分配固定大小的“页”或“块”在物理非连续内存上实现逻辑连续。然后可以将注意力机制重写为在块对齐的输入上运行,从而允许在非连续的内存范围内执行注意力计算。TACO-LLM 通过 Paged Attention 技术,实现了较高的显存利用效率。
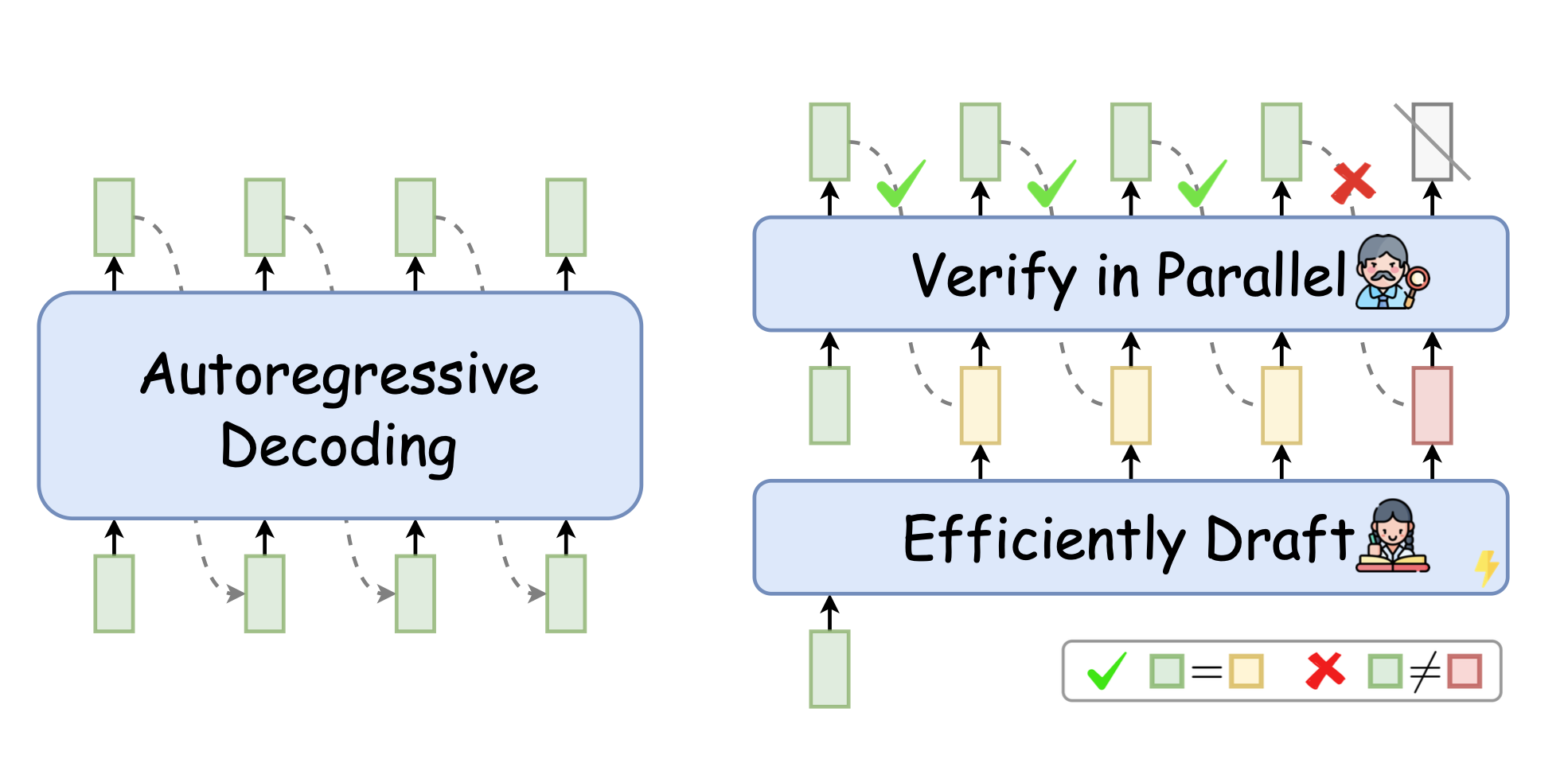
投机采样
大语言模型的自回归解码属性要求每次生成新的 Token,都需要依赖所有已解码的 Token,且需要重新加载模型全部权重进行串行解码。这种计算方式无法充分利用 GPU 的算力,计算效率不高,解码成本高昂。而 TACO-LLM 通过投机采样的方式,从根本上解决了计算访存比的问题。通过引入一个高效的 Draft 辅助解码,可以让真正部署的大模型实现“并行”解码,从而大幅提高解码效率。我们称之为 Spective Sampling(SpS)技术。
TACO-LLM 支持多种投机采样技术,如基于上下文的 Lookahead-Cache 和基于模型的 Eagle/Medusa 等,在多种业务场景中,均能实现高效的 LLM 推理计算。关于 Lookahead-Cache 的详情和使用方式请参见 Lookahead Cache。
Auto Prefix Caching
LLM 推理计算主要分为两个过程:Prefill 阶段(Prompt 计算)和 Decode 阶段。这两个阶段的计算特性存在不同,Prefill 阶段是计算受限的,而 Decode 阶段是访存受限的。为了避免重复计算,Prefill 阶段主要作用就是给 Decode 阶段准备 KV Cache。但这些 KV Cache 通常只是为单条推理请求服务的,当请求结束,对应的 KV-Cache 就会清除。
KV Cache 能不能跨请求复用?在某些 LLM 业务场景下,多次请求的 Prompt 可能会共享同一个前缀(Prefix),比如少量样本学习,多轮对话等。在这些情况下,很多请求 Prompt 的前缀的 KV Cache 计算的结果是相同的,可以被缓存起来,给之后的请求复用。TACO-LLM 的 Auto Prefix Cache 技术可以针对这种场景进行优化,使得具有相同 Prompt 前缀的 KV-Cache 可以跨请求复用,降低计算开销,提升推理计算性能。详情和使用方式请参见 Auto Prefix Cache。
量化
随着以 Transformer 为基石的大语言模型规模的快速增大,LLM 的推理部署对 GPU 显存和算力的需求激增。如何减少大语言模型部署的 GPU 显存需求,提高计算效率,降低推理部署成本就显得愈发重要。模型量化是解决这个问题非常重要的一种手段。业界提出了多种适用于LLM的量化算法,如GPTQ、AWQ、FP8 等,在保证模型精度损失满足业务需求的情况下,显著提升 LLM 推理计算的效能,降低部署成本。TACO-LLM 对业界主要的 LLM 量化算法均进行了适配支持,详情和使用方式请参见 量化。
CPU 辅助加速
传统的投机采样使用 GPU 作为 Draft Model 的计算资源,而 GPU 的成本高昂。为了进一步降低计算成本,TACO 团队与 Intel 团队合作,基于 AMX 指令集对 CPU 上的矩阵乘法做了优化,使得使用 CPU 作为 Draft Model 成为可能,从而在进行推理加速的同时,显著降低了推理成本。详情和使用方式请参见 CPU 辅助加速。
长序列并行
在 LLM 大模型推理中,长序列场景应用越来越广泛。目前业界对长序列的优化主要有 KV-Cache 量化、稀疏化等,这些都对模型精度有一定的影响。TACO LLM 自研长序列并行方案,可以在长序列场景进行精度无损的加速。在长序列推理场景,LLM 推理的首字延迟较高。针对该问题,序列并行在 Prefill 阶段采用了 Ring Attention 类的方案,可以通过扩展机器,降低首字延迟。而对于推理阶段,我们可以使用 Lookahead 等投机采样技术加速。详情和使用方式请参见 长序列优化。
参考文献



