python爬虫学习:爬虫与反爬虫
python爬虫学习:爬虫与反爬虫


点击蓝字“python教程”关注我们哟!
前言
Python现在非常火,语法简单而且功能强大,很多同学都想学Python!所以小的给各位看官们准备了高价值Python学习视频教程及相关电子版书籍,欢迎前来领取!
一.简介
万维网上有着无数的网页,包含着海量的信息,有些时候我们需要从某些网站提取出我们感兴趣、有价值的内容。但是不可能靠人工去点击网页复制粘贴。我们需要一种能自动获取网页内容并可以按照指定规则提取相应内容的程序,这就是爬虫。
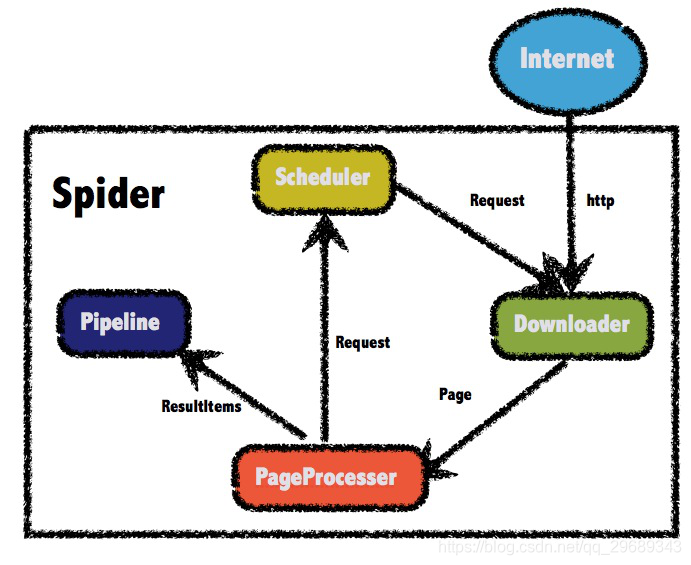
网络爬虫本质就是http请求,浏览器是用户主动操作然后完成HTTP请求,而爬虫需要自动完成http请求,网络爬虫需要一套整体架构完成工作。
一般来说一个完整的爬虫生命周期包括:URL管理、页面下载、内容抽取、持久化。

URL管理
首先url管理器添加了新的url到待爬取集合中,判断了待添加的url是否在容器中、是否有待爬取的url,并且获取待爬取的url,将url从待爬取的url集合移动到已爬取的url集合。
页面下载
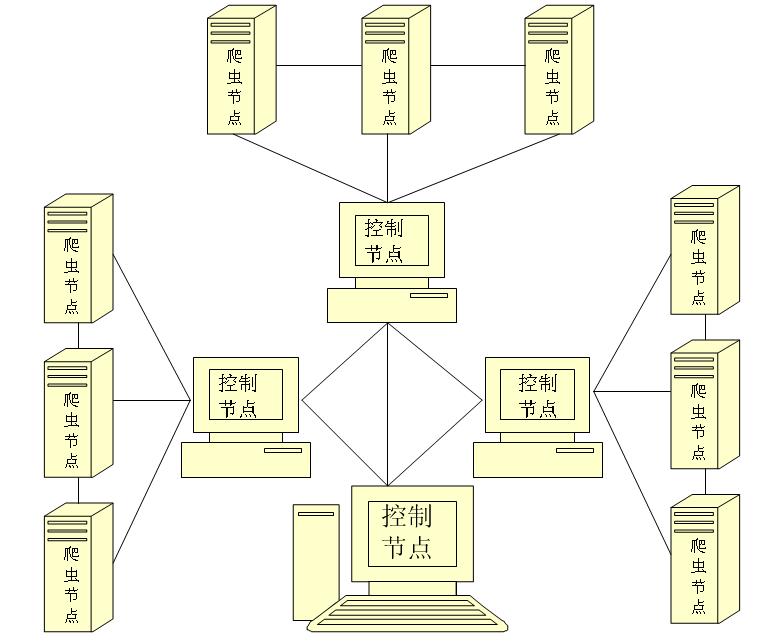
下载器将接收到的url传给互联网,互联网返回html文件给下载器,下载器将其保存到本地,一般的会对下载器做分布式部署,一个是提交效率,再一个是起到请求代理作用。
内容抽取
页面解析器主要完成的是从获取的html网页字符串中取得有价值的感兴趣的数据和新的url列表。数据抽取比较常用的手段有基于css选择器、正则表达式、xpath的规则提取。一般提取完后还会对数据进行一定的清洗或自定义处理,从而将请求到的非结构数据转化为我们需要的结构化数据。
数据持久化
数据持久化到相关的数据库、队列、文件等方便做数据计算和与应用对接。
二.爬虫分类
网络爬虫按照实现的技术和结构一般分为通用网络爬虫、聚焦网络爬虫。从特性上也有增量式网络爬虫和深层网络爬虫等类别,在实际的网络爬虫中,通常是这几类爬虫的组合体。
通用网络爬虫
通用网络爬虫(General Purpose Web Crawler)。通用网络爬虫又叫作全网爬虫,顾名思义,通用网络爬虫爬取的目标资源在全互联网中。通用网络爬虫所爬取的目标数据是巨大的,并且爬行的范围也是非常大的,正是由于其爬取的数据是海量数据,故而对于这类爬虫来说,其爬取的性能要求是非常高的。这种网络爬虫主要应用于大型搜索引擎中,有非常高的应用价值。

通用网络爬虫主要由初始URL集合、URL队列、页面爬行模块、页面分析模块、页面数据库、链接过滤模块等构成。通用网络爬虫在爬行的时候会采取一定的爬行策略,主要有深度优先爬行策略和广度优先爬行等策略。
聚焦网络爬虫
聚焦网络爬虫(Focused Crawler)也叫主题网络爬虫,顾名思义,聚焦网络爬虫是按照预先定义好的主题有选择地进行网页爬取的一种爬虫,聚焦网络爬虫不像通用网络爬虫一样将目标资源定位在全互联网中,而是将爬取的目标网页定位在与主题相关的页面中,此时,可以大大节省爬虫爬取时所需的带宽资源和服务器资源。聚焦网络爬虫主要应用在对特定信息的爬取中,主要为某一类特定的人群提供服务。
聚焦网络爬虫主要由初始URL集合、URL队列、页面爬行模块、页面分析模块、页面数据库、链接过滤模块、内容评价模块、链接评价模块等构成。内容评价模块可以评价内容的重要性,同理,链接评价模块也可以评价出链接的重要性,然后根据链接和内容的重要性,可以确定哪些页面优先访问。

增量式网络爬虫
增量式网络爬虫(Incremental Web Crawler),所谓增量式,对应着增量式更新。增量式更新指的是在更新的时候只更新改变的地方,而未改变的地方则不更新,所以增量式网络爬虫,在爬取网页的时候,只爬取内容发生变化的网页或者新产生的网页,对于未发生内容变化的网页,则不会爬取。增量式网络爬虫在一定程度上能够保证所爬取的页面,尽可能是新页面。
深层网络爬虫
深层网络爬虫(Deep Web Crawler),常规的网络爬虫在运行中无法发现隐藏在普通网页中的信息和规律,缺乏一定的主动性和智能性。深层网络爬虫则可以抓取到深层网页的数据。一般网络页面分为表层网页和深层网页。 表层网页是指传统搜索引擎可以索引的页面,而深层页面是只有用户提交一些关键词才能获得的页面,例如那些用户注册后内容才可见的网页就属于深层网页。

三.爬虫与反爬虫
爬虫目的是自动化的从目标网页获取数据,但是这个行为会对目标站点造成一定压力,对方出于对站点性能或数据的保护,一般都会有反爬手段。所以在开发爬虫过程中需要考虑反反爬。
爬虫开发过程中常见分布式(代理IP)、异步数据解析(内置浏览器内核)、光学图片识别、模拟验证(模拟请求Header、User-Agent、Token)等手段。网络爬虫会为Web服务器带来巨大的资源开销,当我们编写的爬虫数据不能给我们带来价值时,我们应停止没必要的网络请求来给互联网减少干扰。
站点反爬一般会考虑后台对访问进行统计,对单个IP,Session、单种User-Agent访问超过阈值或 Referer缺失的请求进行封锁,Robots协议,异步数据加载,页面动态化,请求验证拦截等。高端的反反爬包括混淆、不稳定代码、给假数据(投毒)、行为分析、假链陷阱、字符转图片等。一般反爬虫策略多数用在比较低级的爬虫上,这类爬虫多为简单粗暴的不顾服务器压力不停访问,再一种为失控的或被人遗忘的爬虫,这类爬虫一般需要在第一时间封锁掉。
鉴于爬虫爬取的数据为目标网站发布于互联网的公开数据,所以理论上是不可能完全阻止掉爬虫的。站点能做的只是增加爬虫的爬取难度,让爬虫的开发成本增高从而知难而退。越是高级的爬虫,越难被封锁,相应高级爬虫的开发成本也越高。
在对高级爬虫进行封锁时,如果成本高到一定程度,并且爬虫不会给自己带来大的性能压力和数据威胁时,这时就无需继续提升成本和爬虫对抗了。目前大多热门站点在与爬虫的博弈中,多维持着一个爬虫与反爬虫的平衡,毕竟双方都是为了在商业市场中获取利益,而不是不计成本的干掉对方。
注意事项
01
对Python开发技术感兴趣的同学,欢迎加下方的交流群一起学习,相互讨论。
02
学习python过程中有不懂的可以加入我的python零基础系统学习交流秋秋qun:934109170,与你分享Python企业当下人才需求及怎么从零基础学习Python,和学习什么内容。相关学习视频资料、开发工具都有分享
好啦!文章就给看官们分享到这儿
最后,如果觉得有帮助,记得关注、转发、收藏哟









![基于python-scrapy框架的爬虫系统[通俗易懂]](https://ask.qcloudimg.com/http-save/yehe-8223537/8433f2d7eebdd70d8c6f4c341d83d1f2.png)


腾讯云开发者

