AI绘画爆火背后:扩散模型原理及实现

Datawhale干货
技术:Diffusion扩散模型
最近爆火的AI绘图,相信大家并不陌生了。
从AI绘图软件生成的作品打败一众人类艺术家,斩获数字艺术类冠军,到如今DALL.E、Imagen、novelai等国内外平台遍地开花。也许你也曾点开过相关网站,尝试让AI描绘你脑海中的风景,又或者上传了一张自己帅气/美美的照片,然后对着最后生成的糙汉哭笑不得。那么,在你感受AI绘图魅力的同时, 有没有想过 (不你肯定想过),它背后的奥妙究竟是什么?

美国科罗拉多州技术博览会中获得数字艺术类冠军的作品——《太空歌剧院》
一切,都要从一个名为DDPM的模型说起…
话说DDPM
DDPM模型,全称Denoising Diffusion Probabilistic Model,可以说是现阶段diffusion模型的开山鼻祖。不同于前辈GAN、VAE和flow等模型,diffusion模型的整体思路是通过一种偏向于优化的方式, 逐步从一个纯噪音的图片中生成图像。
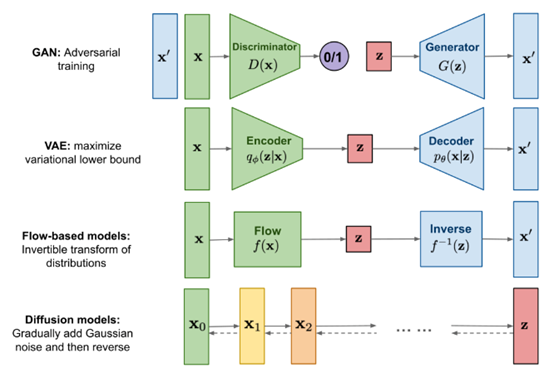
现在已有生成图像模型的对比
没有相关机器学习背景的小伙伴可能会问了,什么是纯噪音图片?
很简单,老式电视机没信号时,伴随着"刺啦刺啦"噪音出现的雪花图片,就属于纯噪音图片。而DDPM在生成阶段所做的事情,就是把这些个"雪花"一点点移除,直到清晰的图像露出它的庐山真面目,我们把这个阶段称之为"去噪"。

纯噪音图片:老电视的雪花屏
通过描述,大家可以感受到,去噪其实是个相当复杂的过程。没有一定的去噪规律,可能你忙活了好半天,到最后还是对着奇形怪状的图片欲哭无泪。当然,不同类型的图片也会有不同的去噪规律,至于怎么让机器学会这种规律,有人灵机一动,想到了一种绝妙的方法。
"既然去噪规律不好学,那我为什么不先通过加噪的方式,先把一张图片变成纯噪音图像,再把整个过程反着来一遍呢?"
这便奠定了diffusion模型整个训练-推理的流程, 先在前向过程( forward process )通过逐步加噪,将图片转换为一个近似可用高斯分布的纯噪音图像,紧接着在反向过程( reverse process )中逐步去噪,生成图像,最后以增大原始图像和生成图像的相似度作为目标,优化模型,直至达到理想效果 。

DDPM的训练-推理流程
到这里,不知道大家的接受度怎样?如果感觉没问题,轻轻松的话。准备好,我要开始上大招(深入理论)啦。
1.前向过程(forward process)
又称为扩散过程(diffusion process),整体是一个参数化的 马尔可夫链(Markov chain) 。从初始数据分布 出发,每步在数据分布中添加高斯噪音,持续T次。其中从第t-1步到第t步的过程可以用高斯分布表示为:
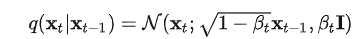
通过合适的设置,随着t不断增大,原始数据会逐渐失去他的特征。我们可以理解为,在进行了无限次的加噪步骤后,最终的数据会变成没有任何特征,完全是随机噪音的图片,也就是我们最开始说的"雪花屏"。
在这个过程中,每一步的变化是可以通过设置 超参 来控制,在我们知晓最开始的图片是什么的前提下,前向加噪的整个过程可以说是 已知且可控的 ,我们完全能知道每一步的生成数据是什么样子。
但问题在于,每次的计算都需要从起始点出发,结合每一步的过程,慢慢推导至你想要的某步数据,过于麻烦。好在因为高斯分布的一些特性,我们可以一步到位,直接从得到。
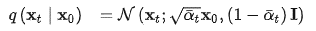
(这里的

为组合系数 ,本质上是超参的表达式)
2.反向过程(reverse process)
和前向过程同理,反向过程也是一个 马尔可夫链(Markov chain), 只不过这里用到的参数不同,至于具体参数是什么,这个就是我们需要机器来学习的部分啦。
在了解机器如何学习前,我们首先思考,基于某一个原始数据,从第t步,精准反推回第t-1步的过程应该是怎样的?
答案是,这个仍可以用高斯分布表示:
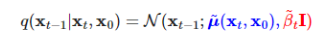
注意这里必须要考虑,意思是反向过程最后生成图像还是要与原始数据有关。输入猫的图片,模型生成的图像应该是猫,输入狗的图片,生成的图像也应该和狗相关。若是去除掉,则会导致无论输入哪种类型的图片训练,最后diffusion生成的图像都一样,"猫狗不分"。
经过一系列的推导,我们发现,反向过程中的参数和,竟然还是可以用,,以及参数 , 表示出来的,是不是很神奇~
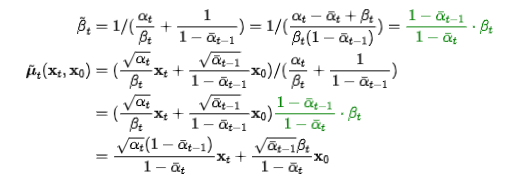
当然,机器事先并不知道这个真实的反推过程,它能做到的,只是用一个大概近似的估计分布去模拟,表示为

3.优化目标
在最开始我们提到,需要通过 增大原始数据和反向过程最终生成数据的相似度 来优化模型。在机器学习中,我们计算该相似度参考的是 交叉熵( cross entropy ) 。
关于交叉熵,学术上给出的定义是"用于度量两个概率分布间的差异性信息"。换句话讲,交叉熵越小,模型生成的图片就越和原始图片接近。但是,在大多数情况下,交叉熵是 很难或者无法通过计算得出 的,所以我们一般会通过优化一个更简单的表达式,达到同样的效果。
Diffusion模型借鉴了VAE模型的优化思路,将 variational lower bound ( VLB ,又称 ELBO )替代cross entropy来作为最大优化目标。通过无数步的分解,我们最终得到:
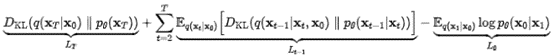
看到这么复杂的公式,好多小伙伴肯定头都大了。但不慌,这里需要关注的,只是中间的 罢了,它表示的是 和之间估计分布和真实分布的差距 。差距越小,模型最后生成图片的效果就越好。
4.上代码
在了解完DDPM背后的原理,接下来就让我们看看DDPM模型究竟是如何实现…
才怪啦。相信看到这里的你,肯定也不想遭受成百上千行代码的洗礼。好在MindSpore已经为大家提供了开发完备的DDPM模型, 训练推理两手抓,操作简单,单卡即可运行 ,想要体验效果的小伙伴,可以先pip install denoising-diffusion-mindspore后,参考如下代码配置参数:

对重要的参数进行一些解析:
- GaussianDiffusion
- image_size: 图片大小
- timesteps: 加噪步数
- sampling_timesteps: 采样步数,为提升推理性能,需小于加噪步数
- Trainer
- folder_or_dataset: 对应图片中的path, 可以是已下载数据集的路径(str),也可以是已做好数据处理的VisionBaseDataset, GeneratorDataset 或 MindDataset
- train_batch_size:batch大小
- train_lr: 学习率
- train_num_steps: 训练步数
话说MindDiffusion
DDPM只是Diffusion这个故事的开篇。目前,已有无数的研究人员被其背后瑰丽的世界所吸引,纷纷投身其中。在不断优化模型的同时,也逐渐开发了Diffusion在各个领域的应用。
其中,包括了计算机视觉领域的图像优化、inpainting、3D视觉,自然语言处理中的text-to-speech,AI for Science领域的分子构象生成、材料设计等,更有来自斯坦福大学计算机科学系的博士生Eric Zelikman大开脑洞,尝试将DALLE-2与最近另一个大火的对话模型ChatGPT相结合,制作出了温馨的绘本故事。

DALLE-2 + ChatGPT合力完成的,关于一个名叫"罗比"的小机器人的故事
不过最广为大众所知的,应该还是它在文生图(text-to-image)方面的应用。输入几个关键词或者一段简短的描述,模型便可以为你生成相对应的图画。
比如,输入"城市夜景 赛博朋克 格雷格.路特科夫斯基",最后生成的便是一张色彩鲜明,颇具未来科幻风格的作品。

再比如,输入"莫奈 撑阳伞的女人 月亮 梦幻",生成的便是一张极具有朦胧感的女人画像,色彩搭配的风格有木有让你想起莫奈的《睡莲》?

想要写实风格的风景照作为屏保?没问题!

乡村 田野 屏保
想要二次元浓度多一点的?也可以!

来自深渊 风景 绘画 写实风格
以上这些图片,均是由 MindDiffusion 平台的下的悟空画画 制作而成的哦,悟空画画是基于扩散模型的中文文生图大模型,由 华为诺亚团队 携手 中软分布式并行实验室 , 昇腾计算产品部联合开发。模型基于Wukong dataset训练,并使用昇思框架(MindSpore)+昇腾(Ascend)软硬件解决方案实现。
跃跃欲试的小伙伴先别着急,为了让大家拥有更好的体验,更多自行开发的空间,我们打算让MindDiffusion中的模型同样也具备可训练、可推理的特性,预计在明年就要和大家见面啦,敬请期待,欢迎大家头脑风暴,生成各种别具风格的作品哦~
(据去内部打探情报的同事说,有人已经开始尝试"张飞绣花"、"刘华强砍瓜"、"古希腊神大战哥斯拉"了。ummmm,怎么办,突然就很期待成品了呢(ಡωಡ))
一个突然正经的结语
最后的最后,在Diffusion爆火的如今,有人也曾发出过疑问,它为什么可以做到如此的大红大紫,甚至风头开始超过GAN网络?Diffusion的优势突出,劣势也很明显;它的诸多领域仍是空白,它的前方还是一片未知。为什么却有那么多的人在孜孜不倦地对它进行研究呢?
兴许,马毅教授的一番话,可以给我们提供一种解答。
"但diffusion process的有效性以及很快取代GAN也充分说明了一个简单道理: 几行简单正确的数学推导,可以比近十年的大规模调试超参调试网络结构有效得多。"
或许,这就是Diffusion模型的魅力吧。
Reference
- https://medium.com/mlearning-ai/ai-art-wins-fine-arts-competition-and-sparks-controversy-882f9b4df98c
- Jonathan Ho, Ajay Jain, and Pieter Abbeel. Denoising Diffusion Probabilistic Models. arXiv:2006.11239, 2020.
- Ling Yang, Zhilong Zhang, Shenda Hong, Runsheng Xu, Yue Zhao, Yingxia Shao, Wentao Zhang, Ming-Hsuan Yang, and Bin Cui. Diffusion models: A comprehensive survey of methods and applications. arXiv preprint arXiv:2209.00796, 2022.
- https://lilianweng.github.io/posts/2021-07-11-diffusion-models
- https://github.com/lvyufeng/denoising-diffusion-mindspore
- https://zhuanlan.zhihu.com/p/525106459
- https://zhuanlan.zhihu.com/p/500532271
- https://www.zhihu.com/question/536012286
- https://mp.weixin.qq.com/s/XTNk1saGcgPO-PxzkrBnIg
- https://m.weibo.cn/3235040884/4804448864177745
腾讯云开发者
