【Linux】Linux 项目自动化构建工具 -- make/makefile 的使用
【Linux】Linux 项目自动化构建工具 -- make/makefile 的使用

文章目录
一、什么是 make/makefile
什么是 makefile
在我们以后的工作环境中,一个工程中的源文件不计数,其按类型、功能、模块分别放在若干个目录中;那么如何对这些源文件进行管理呢?比如哪些文件需要先编译,哪些文件需要后编译,哪些文件需要重新编译,甚至于进行一些更复杂的功能操作。
Linux 提供了项目自动化构建工具 – makefile 来帮助我们解决这个问题;makefile 定义了一系列的规则来指定如何对众多的源文件进行管理;makefile带来的好处就是 – “自动化编译”,即 makefile 一旦写好,以后我们就只需要一个 make 命令,整个工程就可以完全自动编译,极大的提高了软件开发的效率。
在一个企业中,会不会写makefile,从一个侧面说明了一个人是否具备完成大型工程的能力。
什么是 make
make 是一个用来解释 makefile 中指令的命令工具,一般来说,大多数的 IDE 都有这个命令,比如:Delphi的 make,Visual C++的 nmake,Linux下 GNU 的 make;可见,makefile 已经成为了一种在工程方面的编译方法。
总结:make是一条命令,makefile是一个文件,二者搭配使用,实现项目自动化构建。
二、如何编写 makefile
编写 makefile,最重要的是编写 依赖关系和依赖方法;依赖关系是指一个文件依赖另外一个文件,即想要得到一个文件,目录下必须先有另外一个文件;依赖方法则是指如何根据依赖文件来得到目标文件。
在编写 makefile 时有几个需要注意的地方:
- makefile 的文件名必须是 makefile/Makefile,不能是其他名称,否则 make 识别不了;
- 依赖文件可以有多个,也可以没有;
- 依赖方法必须以 [Tab] 键开头,特别注意不能是四个空格;
下面我们一个C语言的例子来说明应如何编写 makefile:
test.c:
#include <stdio.h>
int main()
{
printf("hello makefile\n");
printf("hello makefile\n");
printf("hello makefile\n");
return 0;
}test.c 对应的 makefile:
test.out:test.c #依赖关系
gcc test.c -o test.out #依赖方法
.PHONY:clean #伪目标
clean:
rm -f test.out如上:test.out 依赖 test.c,依赖方法是 gcc 编译;clean 不依赖任何文件,依赖方法是 rm -f 指令;其中 .PHONY 修饰 clean 表示其是一个伪目标,总是被执行 (具体细节下文解释)。
三、make 的工作原理
1、make 的使用
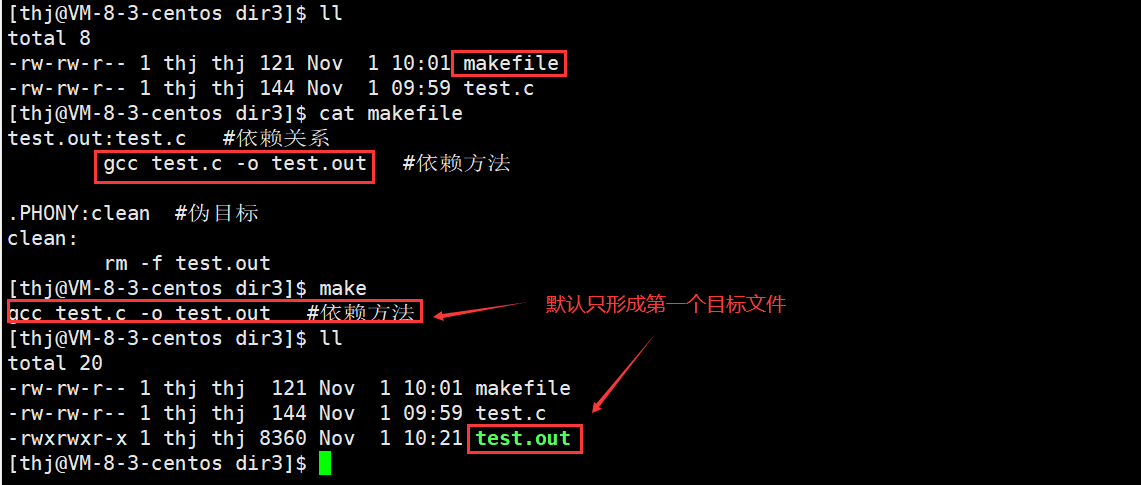
在Linux下,我们输入 make 命令后,make 会在当前目录下找寻名为 “Makefile” 或 “makefile” 的文件;如果找到,它会把文件中的第一个目标文件作为最终的目标文件;如果找不到,就打印提示信息。
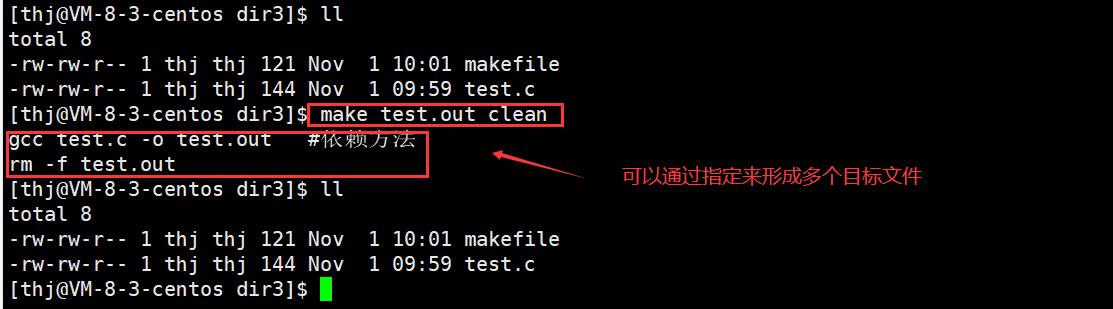
在上面的C语言例子中,makefile 中一共有两个目标文件 – test.out 和 clean;如下,我们输入 make 它默认只会执行第一个目标文件;当然,我们也可以通过指定多个目标文件来让它形成多个目标文件;

2、make 的依赖性
关于 make 的依赖性,我们还是以上面这个例子来说明,只不过我们需要修改它的 makefile 文件:
test.out:test.o
gcc test.o -o test.out
test.o:test.s
gcc -c test.c -o test.o
test.s:test.i
gcc -S test.i -o test.s
test.i:test.c
gcc -E test.c -o test.i
.PHONY:clean
clean:
rm -f test.i test.s test.o test.out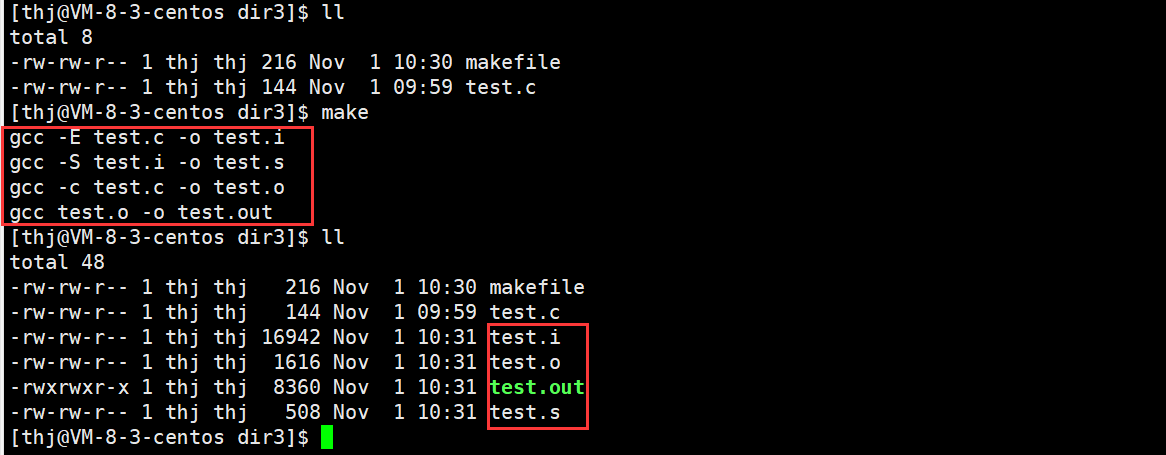
我们知道,我们输入 make 命令后,make 会在当前目录下找寻名为 “Makefile” 或 “makefile” 的文件;如果找到,它会把文件中的第一个目标文件作为最终的目标文件 (上面例子中的 test.out),但是如果 test.out 所依赖的 test.o 文件不存在,那么 make 会在当前文件中找目标为 test.o 文件的依赖性,再根据该一个规则来生成 test.o 文件 (类似于数据结构栈 – 后进先出);
如果 test.o 的依赖文件也不存在,则继续执行该规则,直到找到存在依赖文件的目标文件,得到目标文件后层层返回形成路径上的其他目标文件;或者最后被依赖的文件找不到,直接退出并报错;
这就是整个 make 的依赖性,make 会一层又一层地去找文件的依赖关系,直到最终编译出最开始我们需要的目标文件。
在上面的例子中,test.out 依赖的 test.o 不存在,make 会去寻找以 test.o 为目标文件的依赖关系;test.o 依赖的 test.s 也不存在,make 又会去找 以 test.s 为目标文件的依赖关系;然后 test.s 依赖 test.i,最后,test.i 的依赖文件 test.c 终于存在了,make 就会根据 test.i 的依赖方法形成 test.i,再逐步形成 test.s、test.o,直到最后形成 test.out。
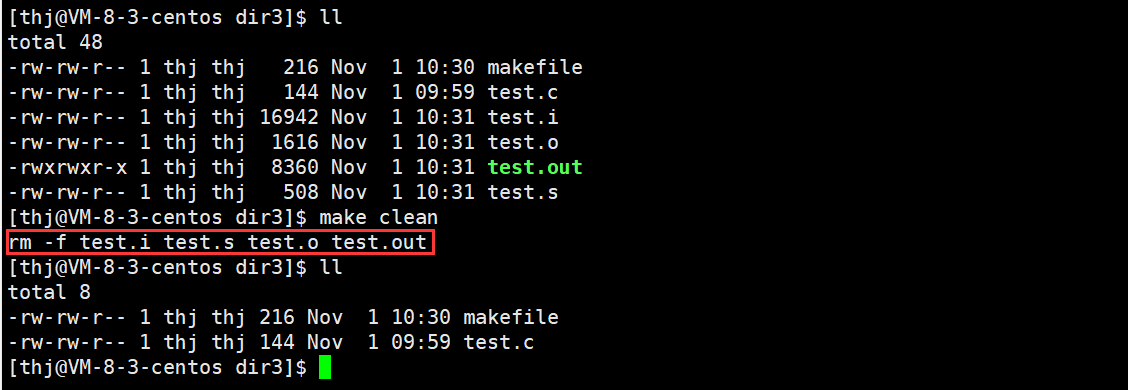
3、项目清理
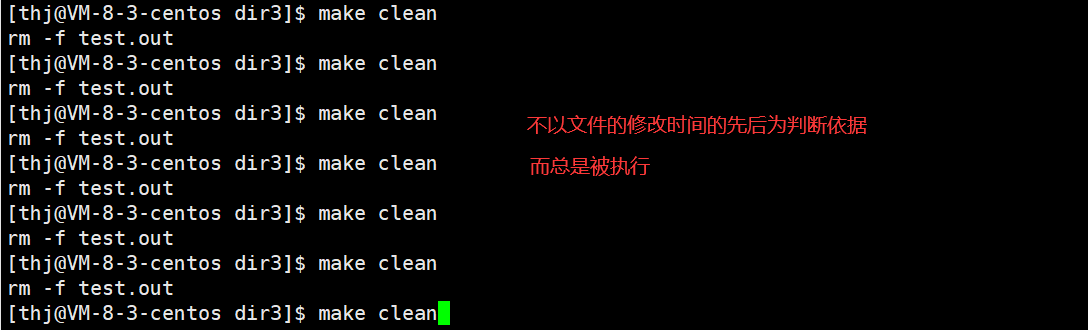
一个工程是需要清理的,在 makefile 中,我们常用 clean 来作为项目清理的目标文件,同时,由于项目清理不需要依赖其他文件,所以 clean 也不存在依赖关系。
另外,由于 clean 没有被第一个目标文件直接或间接关联,那么它后面所定义的命令将不会被自动执行,所以我们需要显示指定 – make clean;
最后,像 clean 这种目标文件,我们一般都会用 .PHONY 将其设置为伪目标,伪目标的特性是:该目标文件总是被执行。
4、.PHONY 伪目标
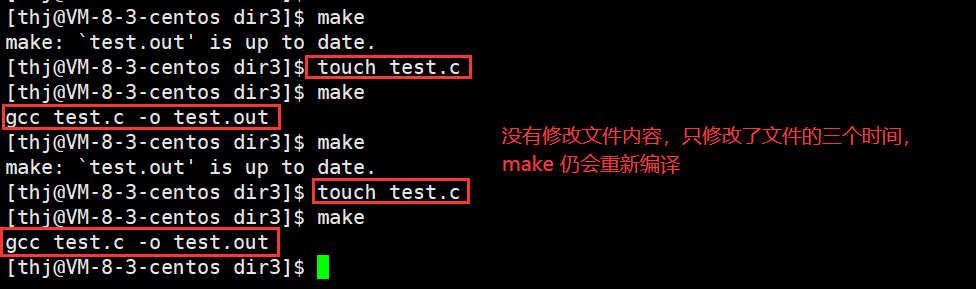
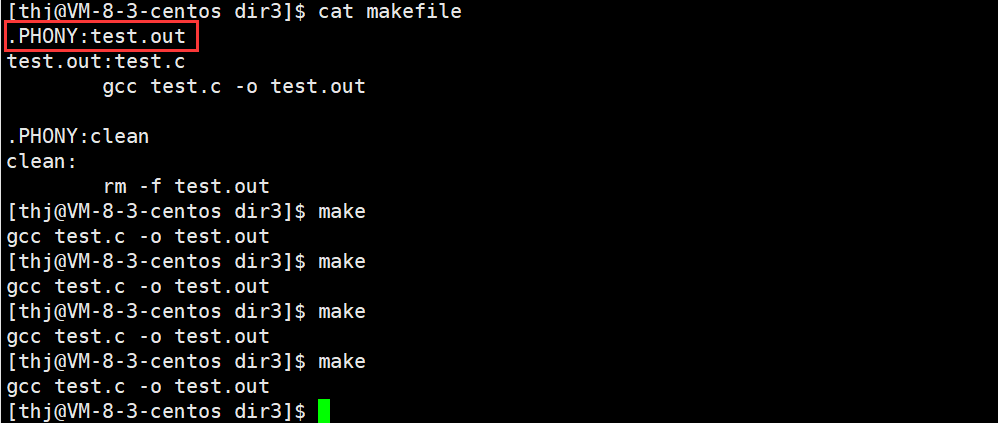
当我们对同一个源文件多次 make,我们会发现第一次程序正常编译,但第二次及以后就不再编译,而是提示:“make: `test.out’ is up to date.”;
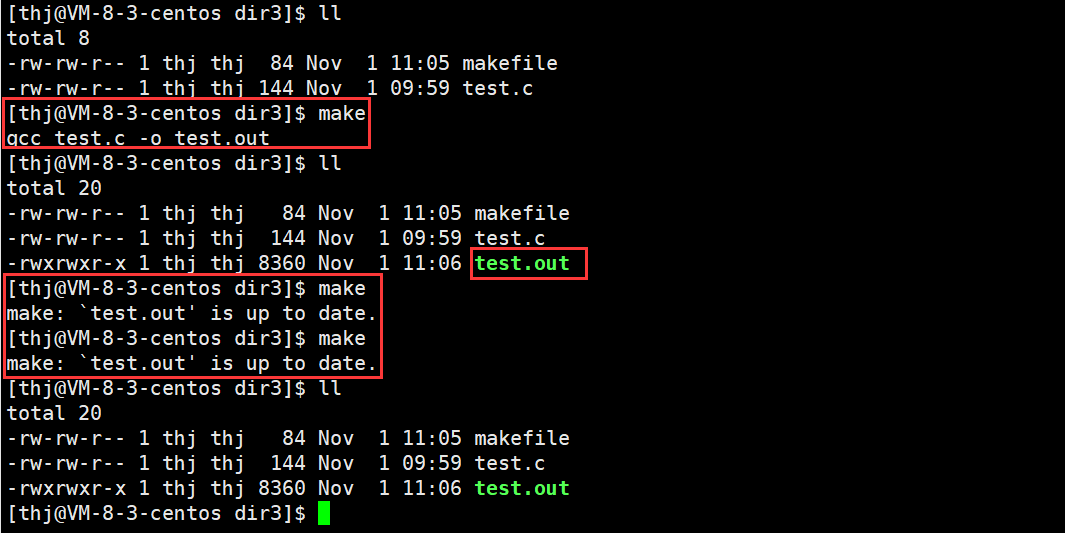
但是当我们把 test.c 中的内容修改过后,我们发现尽管可以再次 make 了,但是仍然不能多次 make:

实际上,上面这种现象是 make 为了防止我们对已经编译好且未做修改的源文件重复编译而浪费时间;也就是说,如果 test.c 已经编译得到了 test.out,并且我们并没有对 test.c 做改动,那么我们再次 make 时 make 不会被执行;实际上 make 这样做是很有必要的,因为在工作中,编译一个工程往往需要几十分钟甚至几个小时,如果我们 make 每次都重新编译,势必会浪费很多时间。
那么 make 是如何判断源程序不需要重新编译的呢?答案是根据文件的修改时间 (modify time) 来判定。
在Linux中,文件一共有三种时间:
- 访问时间 (Access):当我们查看文件内容后该时间改变,比如 cat、vim、less;
- 修改时间 (Modify):当我们修改文件内容后改时间改变,比如 nano、vim;
- 改动时间 (Change):当我们修改文件属性或权限后改时间改变,比如 nano/vim (文件大小改变),chmod/chown/chown (文件权限改变);
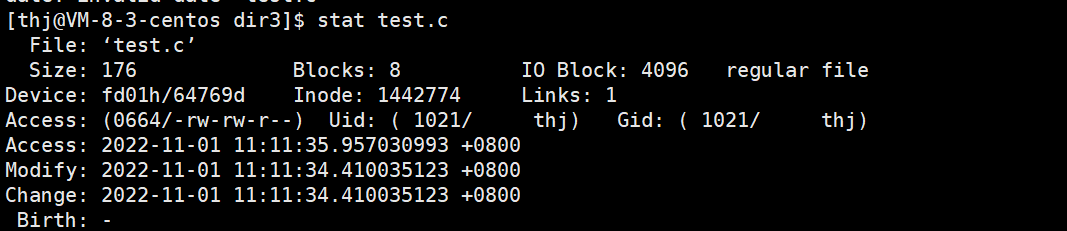
实际上,我们访问文件内容并不一定会改变文件的访问时间,主要有以下两方面的原因:
1、在 Linux 下,访问文件内容的操作十分频繁,而修改文件的访问时间是需要对文件进行 IO 操作的,如果我们每次访问文件都修改文件的访问时间,会增大系统的负担; 2、一个文件是否能被读取是由文件的权限决定的,而既然该文件是可读的,那么说明文件的拥有者/所属组并不在意我们对文件进行读取,所以也没必要每次都修改文件的访问时间;
基于上面这两点,Linux 下并不会每次访问文件内容都更新件的访问时间,而是累积一定访问次数或者累积一段时间才更新:
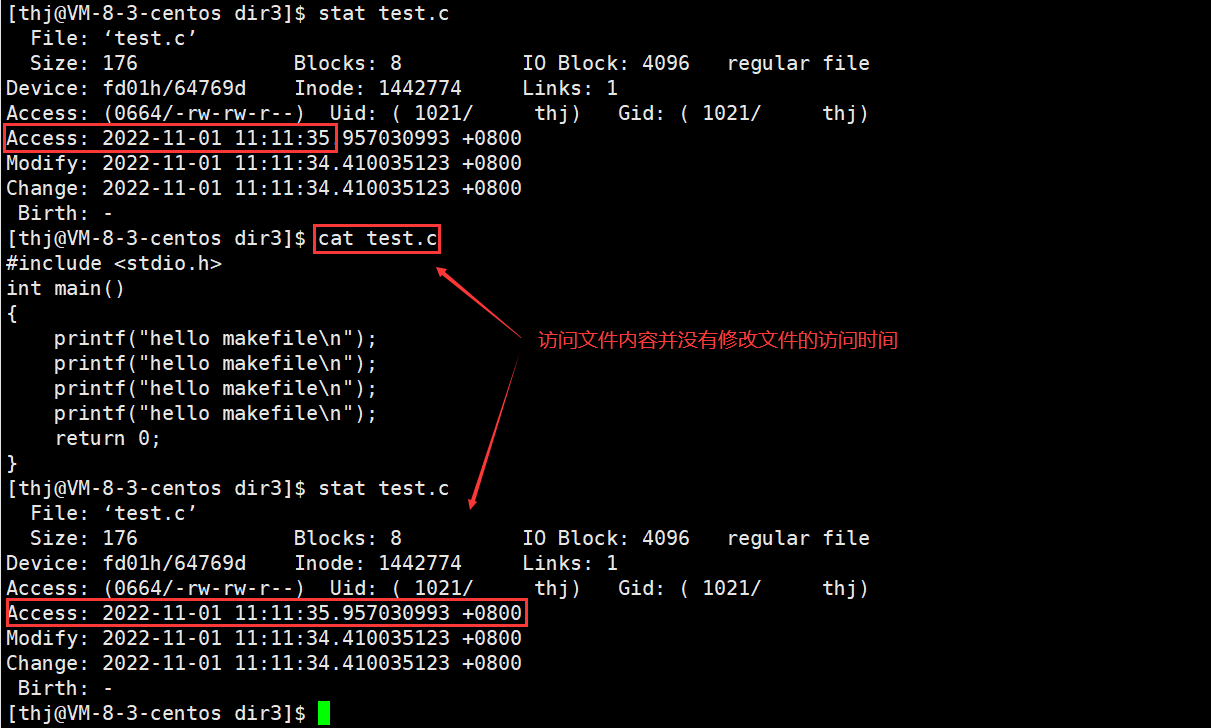
而 make 则是根据可执行程序的修改时间 (modify time) 与源文件的修改时间的对比来判断源程序是否需要重新编译:
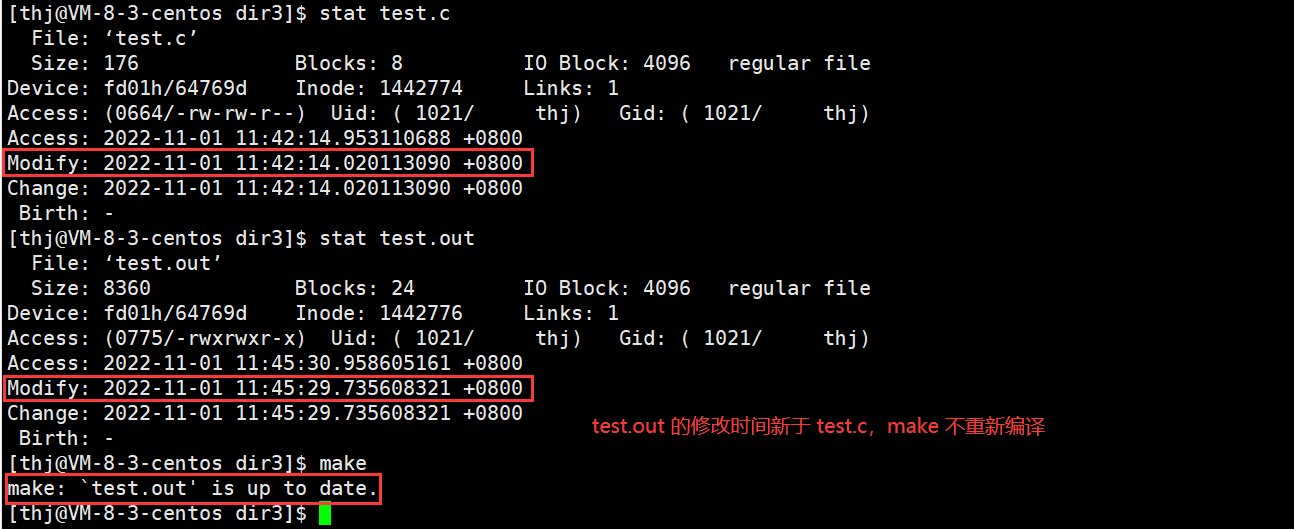
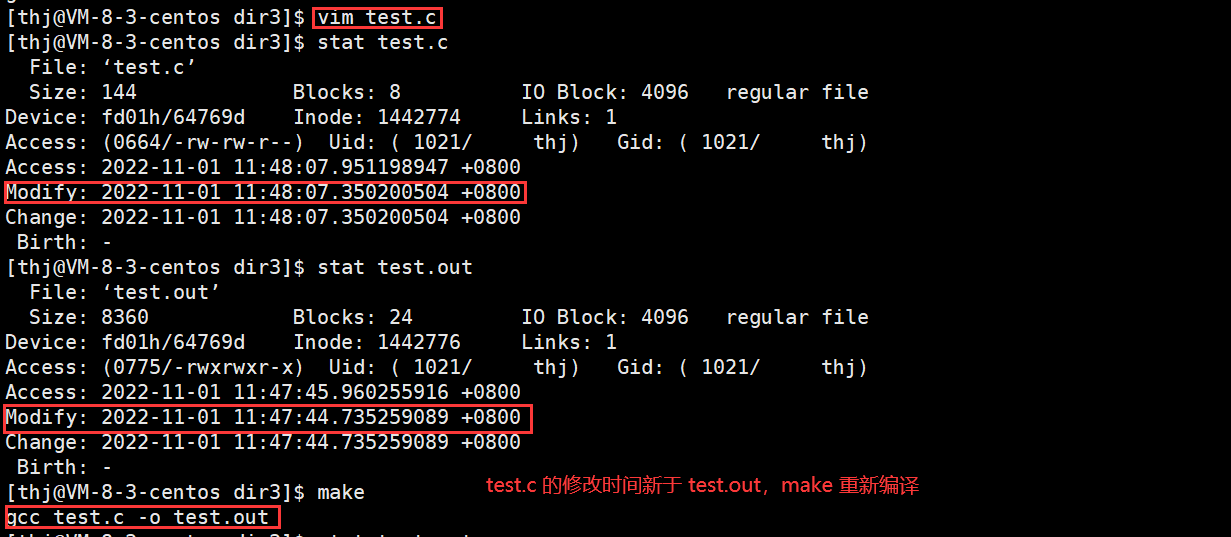
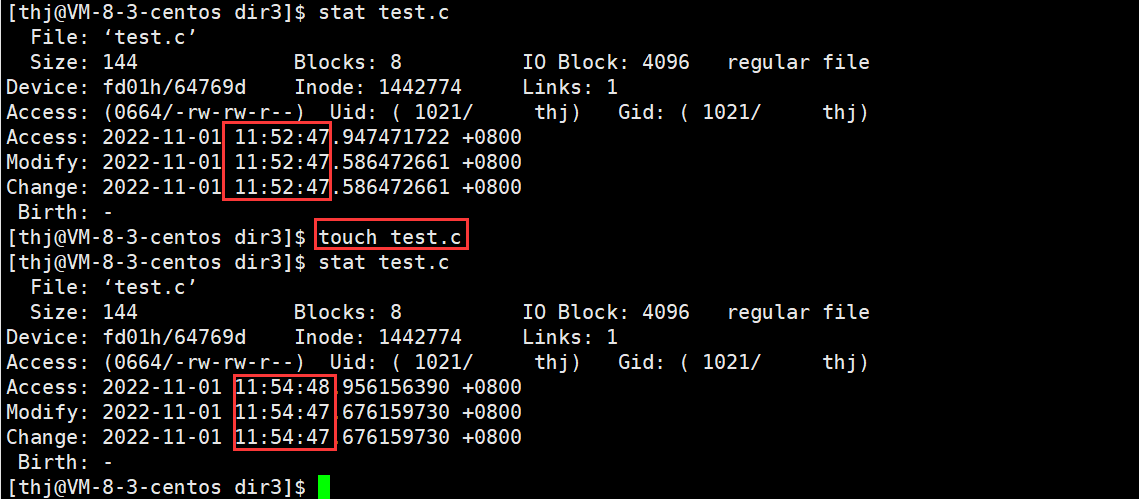
注:make 判断源文件是否需要重新编译只与源文件的修改时间变动有关,与源文件的内容改动无关,我们可以通过 touch 命令来验证:(touch file:如果 file 已存在,则更新 file 的所有时间)
在了解了 make 是如何判断是否要重新执行依赖方法形成目标文件之后,.PHONY 的原理和作用也显而易见了 – 被 .PHONY 修饰的目标文件不根据文件的修改时间先后来判断是否需要重新执行,从而达到总是被执行的效果。
我们也可以使用 .PHONY 来修饰 test.out,使得 test.out 每次都被重新编译:
四、Linux第一个小程序 - 进度条
1、\r && \n
对于 ‘\n’ 想必大家已经很熟悉了,因为在C语言的 printf 函数中我们会频繁的用到它,但是实际上我们C语言学习的 ‘\n’ 是 ‘\r’ + ‘n’;
- ‘\r’:回车,即将光标移动到当前行的行首;
- ‘\n’:换行,即将光标移动到下一行;
可以看到,我们C语言中的 ‘\n’ 的作用是 回车 + 换行,而不仅仅是换行,这也是为什么许多台式机的 enter 键是下面这样的:
2、行缓冲
在C语言 getchar 函数的正确使用 中我们就已经知道 – 我们从键盘输入的字符以及向显示器输出的内容,并不会直接读入或输出,而是会先被存放到输入缓冲区与输出缓冲区中,待缓冲区刷新时数据才会才会被读入或输出;
而行缓冲是缓冲区类型的一种,在行缓冲下,当 在输入和输出中遇到换行符时,才执行真正的I/O操作;即我们输入的字符会先存放在缓冲区,等按下回车键时才进行真正的I/O操作。
我们可以用两份不同的代码来验证上述结论的正确性:
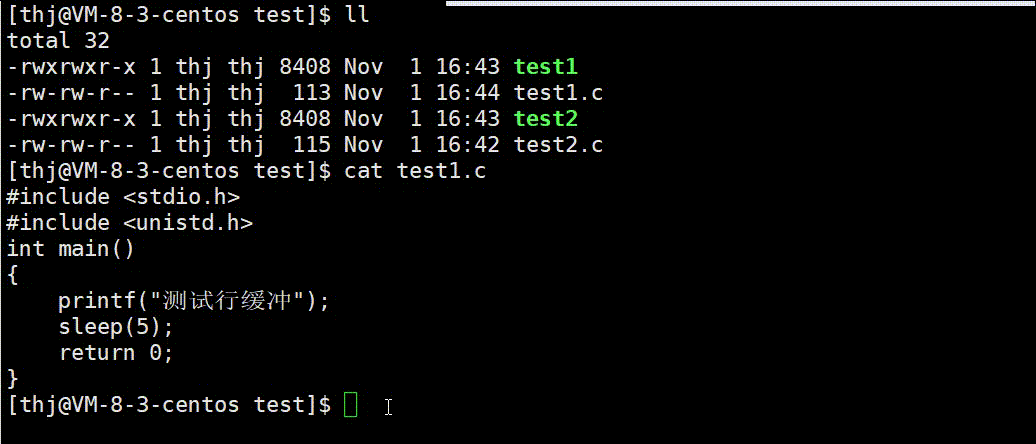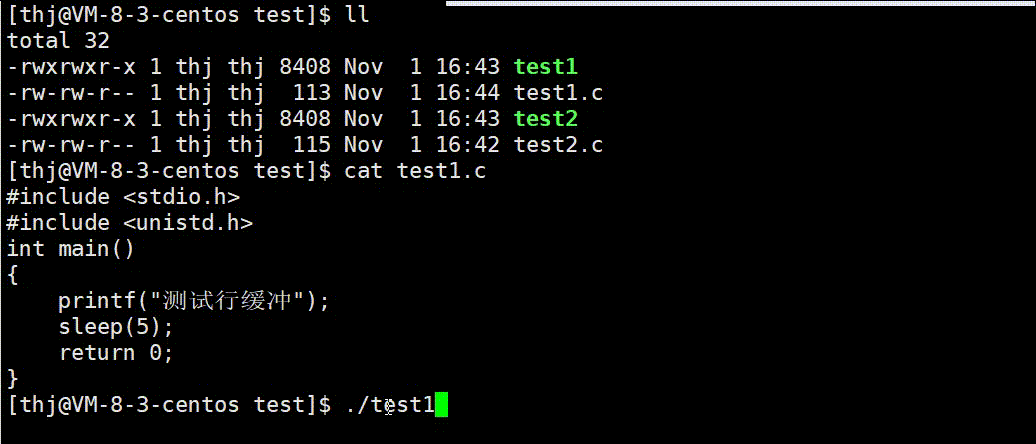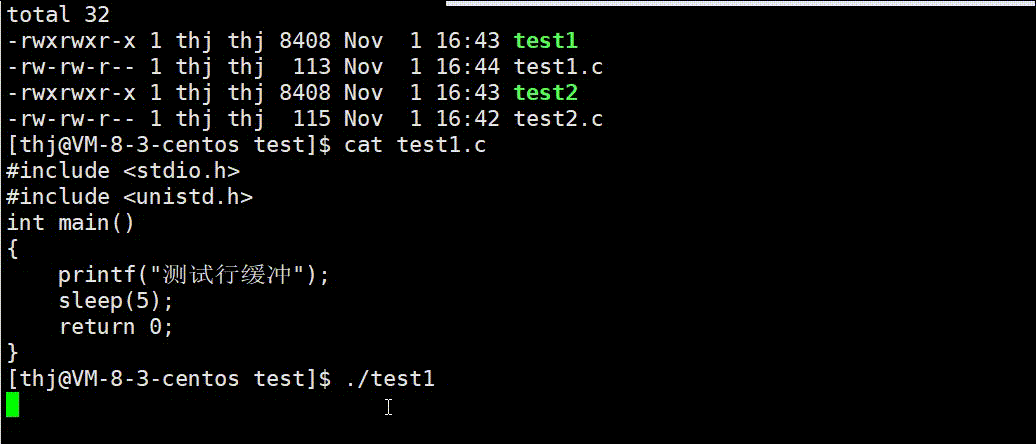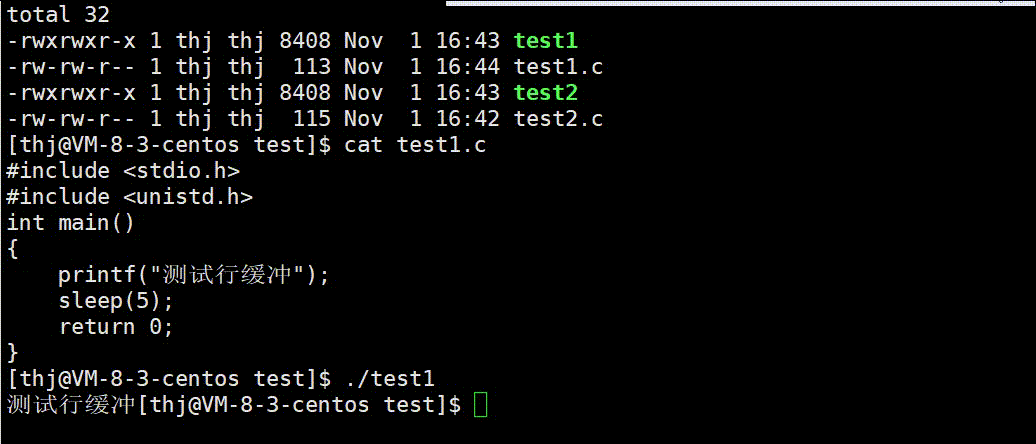
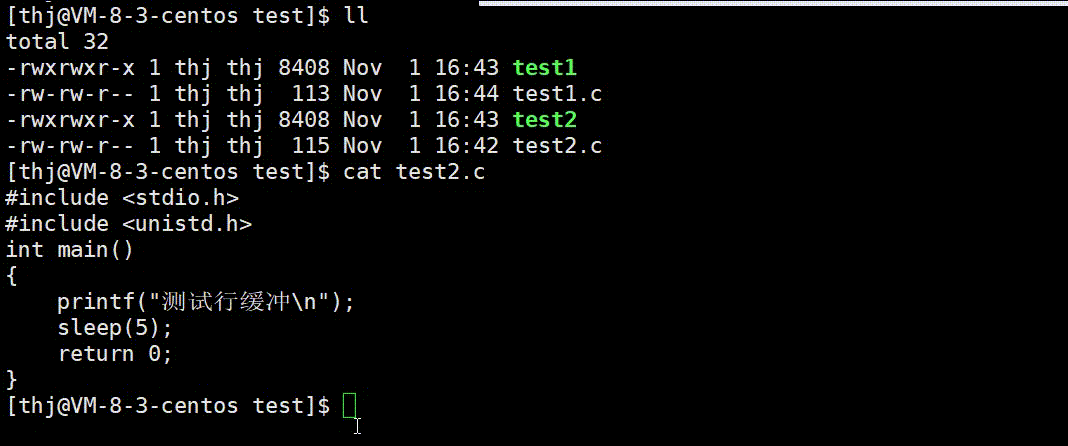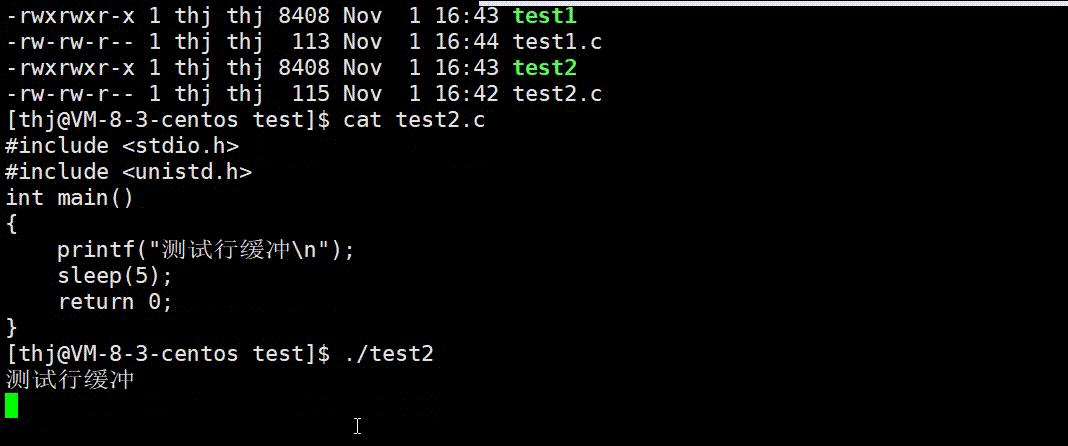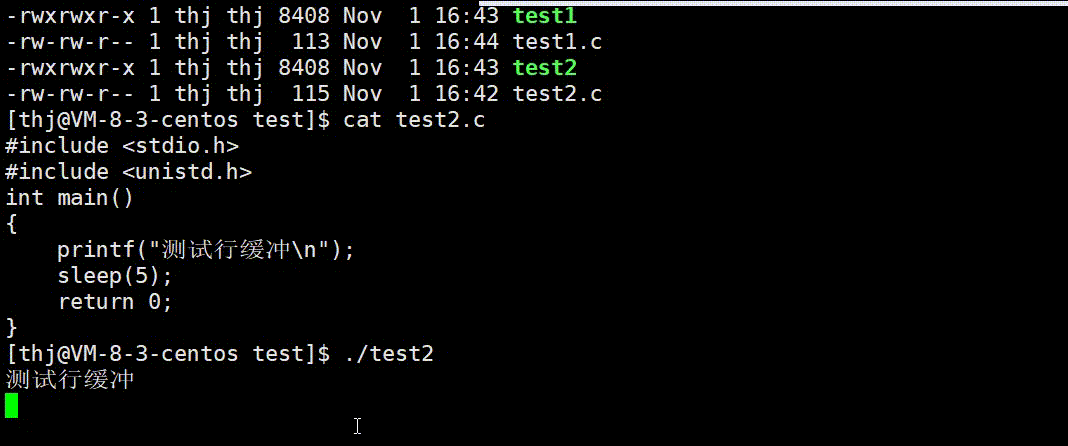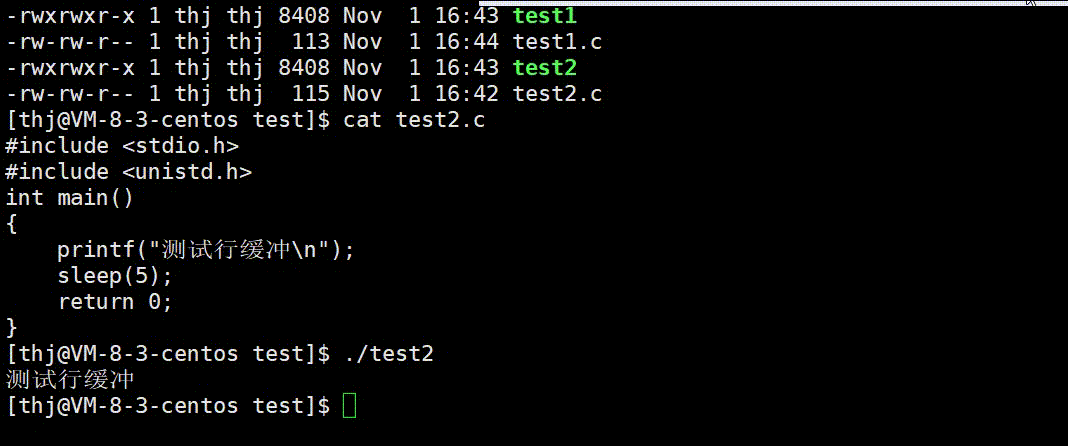
可以看到,test1.c 的数据 printf 后并没有直接显示到终端上,而是待程序结束缓冲区刷新后才显示;而 test2.c 中的数据由于 ‘\n’ 可以刷新行缓冲,所以直接显示到了终端。
3、进度条
有了回车换行和行缓冲的概念之后,我们就可以编写我们的进度条代码了;
process.h:
#pragma once
#include <stdio.h>
#include <unistd.h>
#include <string.h>
const char style[] = { '#', '$', '>', '-', '*' };
#define N 0process.c:
#include "process.h"
int main()
{
int i = 0;
char bar[101];
const char* label = "|\\-/";
memset(bar, 0, sizeof(bar));
while(i <= 100)
{
printf("[%-100s][%d%%][%c]\r", bar, i, *(label+(i%4)));
fflush(stdout);
bar[i++] = style[N];
usleep(100000);
}
printf("\n");
return 0;
}makefile:
process:process.c
gcc process.c -o process
.PHONY:clean
clean:
rm -f process在 proces.c 中,我们每次打印数据之后让光标回到行首,然后刷新缓冲区,再增加 bar 数组里面的标志字符,这样使得我们下一次打印数据时可以直接覆盖掉之前的数据,并且增加一格,从而达到进度条的效果;
同时,为了使进度条更加真实,我们还增加了一个进度值 i 和 旋转光标 label,以及每次打印后让程序休眠0.1秒,使得进度条有一个加载进度以及一个旋转的等待符号;
最后,为了丰富进度条字符的样式,我们把进度条字符设置成了一个字符数组,用户可以根据自己的需要通过调整 N 的值来改变进度条的字符样式。
注意:在 printf 函数中,% 具有特殊意义,所以我们需要输入 %% 来对其进行转义;同样,在 label 数组中,字符 ‘\’ 也是特殊字符,我们需要输入 ‘\\’;
最终得到的进度条的运行效果如下:


腾讯云开发者
