一行文本,生成3D动态场景:Meta这个「一步到位」模型有点厉害


机器之心报道
机器之心编辑部
不再需要任何 3D 或 4D 数据,来自 Meta 的研究者首次提出了可以从文本描述中生成三维动态场景的方法 MAV3D (Make-A-Video3D)。
仅输入一行文本,就能生成 3D 动态场景?
没错,已经有研究者做到了。可以看出来,目前的生成效果还处于初级阶段,只能生成一些简单的对象。不过这种「一步到位」的方法仍然引起了大量研究者的关注:

在最近的一篇论文中,来自 Meta 的研究者首次提出了可以从文本描述中生成三维动态场景的方法 MAV3D (Make-A-Video3D)。

- 论文链接:https://arxiv.org/abs/2301.11280
- 项目链接:https://make-a-video3d.github.io/
具体而言,该方法运用 4D 动态神经辐射场(NeRF),通过查询基于文本到视频(T2V)扩散的模型,优化场景外观、密度和运动的一致性。任意机位或角度都可以观看到提供的文本生成的动态视频输出,并可以合成到任何 3D 环境中。
MAV3D 不需要任何 3D 或 4D 数据,T2V 模型只对文本图像对和未标记的视频进行训练。

让我们看一下 MAV3D 从文本生成 4D 动态场景的效果:
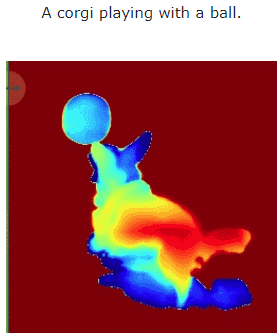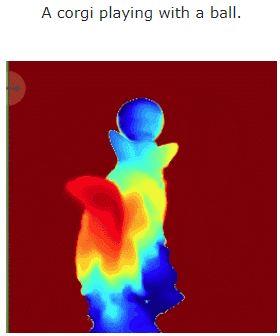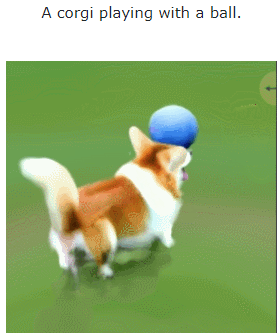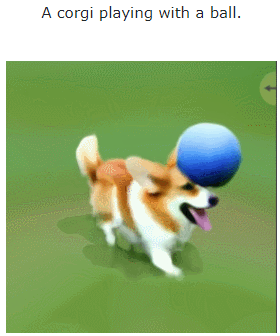
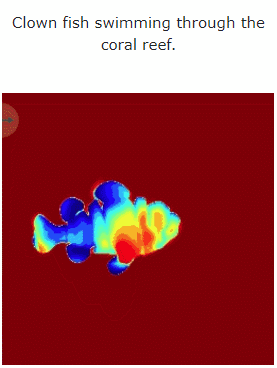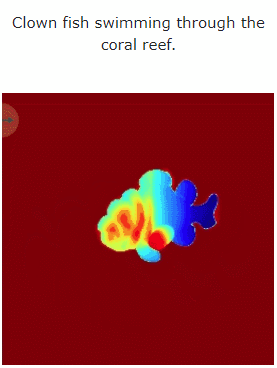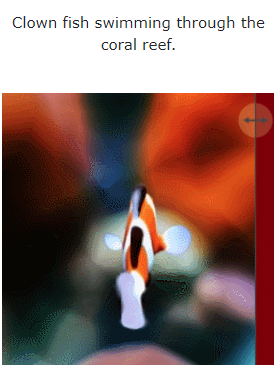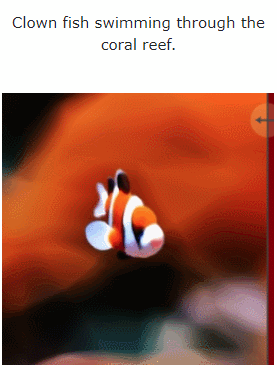
此外,它也能从图像直接到 4D,效果如下:


研究者通过全面的定量和定性实验证明了该方法的有效性,先前建立的内部 baseline 也得到了改进。据悉,这是第一个根据文本描述生成 3D 动态场景的方法。
方法
该研究的目标在于开发一项能从自然语言描述中生成动态 3D 场景表征的方法。这极具挑战性,因为既没有文本或 3D 对,也没有用于训练的动态 3D 场景数据。因此,研究者选择依靠预训练的文本到视频(T2V)的扩散模型作为场景先验,该模型已经学会了通过对大规模图像、文本和视频数据的训练来建模场景的真实外观和运动。
从更高层次来看,在给定一个文本 prompt p 的情况下,研究可以拟合一个 4D 表征
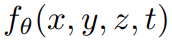
,它模拟了在时空任意点上与 prompt 匹配的场景外观。没有配对训练数据,研究无法直接监督
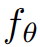
的输出;
然而,给定一系列的相机姿势
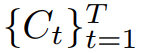
就可以从
渲染出图像序列
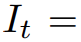
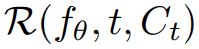
并将它们堆叠成一个视频 V。然后,将文本 prompt p 和视频 V 传递给冻结和预训练的 T2V 扩散模型,由该模型对视频的真实性和 prompt alignment 进行评分,并使用 SDS(得分蒸馏采样)来计算场景参数 θ 的更新方向。
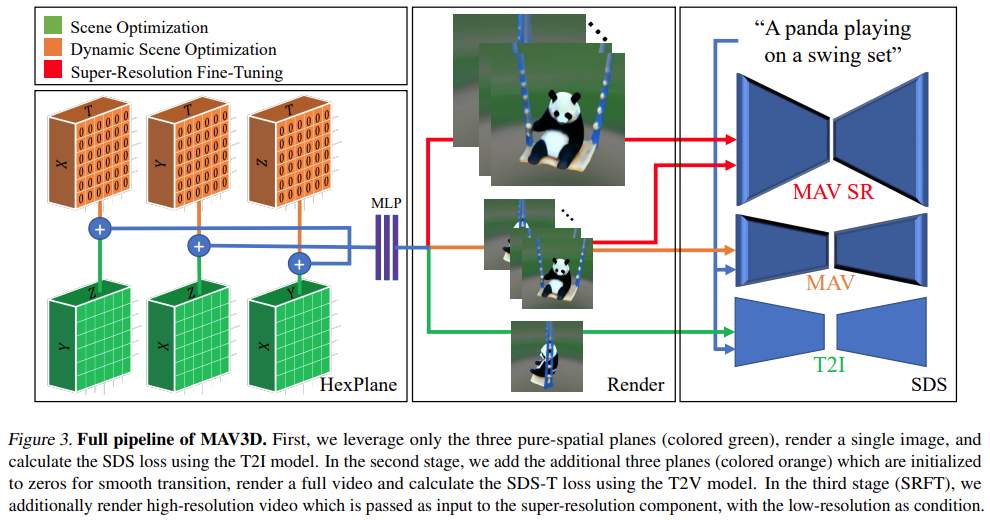
上面的 pipeline 可以算作 DreamFusion 的扩展,为场景模型添加了一个时间维度,并使用 T2V 模型而不是文本到图像(T2I)模型进行监督。然而,要想实现高质量的文本到 4D 的生成还需要更多的创新:
- 第一,需要使用新的、允许灵活场景运动建模的 4D 表征;
- 第二,需要使用多级静态到动态优化方案来提高视频质量和提高模型收敛性,该方案利用几个 motion regularizer 来生成真实的运动;
- 第三,需要使用超分辨率微调(SRFT)提高模型的分辨率。
具体说明见下图:
实验
在实验中,研究者评估了 MAV3D 从文本描述生成动态场景的能力。首先,研究者评估了该方法在 Text-To-4D 任务上的有效性。据悉,MAV3D 是首个该任务的解决方案,因此研究开发了三种替代方法作为基线。其次,研究者评估了 T2V 和 Text-To-3D 子任务模型的简化版本,并将其与文献中现有的基线进行比较。第三,全面的消融研究证明了方法设计的合理性。第四,实验描述了将动态 NeRF 转换为动态网格的过程,最终将模型扩展到 Image-to-4D 任务。
指标
研究使用 CLIP R-Precision 来评估生成的视频,它可以测量文本和生成场景之间的一致性。报告的指标是从呈现的帧中检索输入 prompt 的准确性。研究者使用 CLIP 的 ViT-B/32 变体,并在不同的视图和时间步长中提取帧,并且还通过询问人工评分人员在两个生成的视频中的偏好来使用四个定性指标,分别是:(i) 视频质量;(ii) 忠实于文本 prompt;(iii) 活动量;(四) 运动的现实性。研究者评估了在文本 prompt 分割中使用的所有基线和消融。
图 1 和图 2 为示例。要想了解更详细的可视化效果,请参见 make-a-video3d.github.io。

结果
表 1 显示了与基线的比较(R - 精度和人类偏好)。人工测评以在特定环境下与该模型相比,赞成基线多数票的百分比形式呈现。
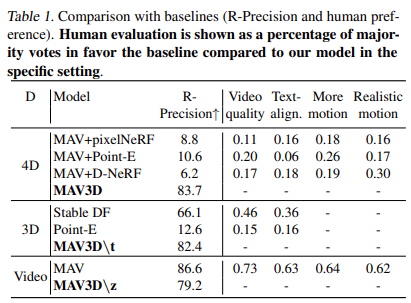
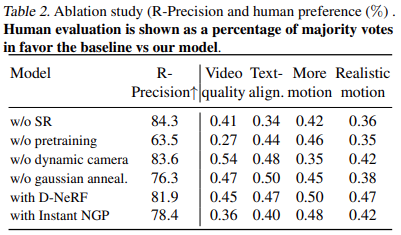
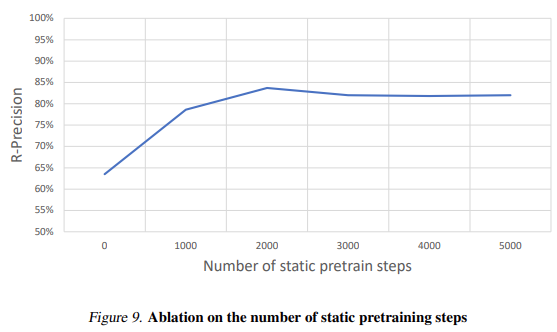
表 2 展示了消融实验的结果:
实时渲染
使用传统图形引擎的虚拟现实和游戏等应用程序需要标准的格式,如纹理网格。HexPlane 模型可以轻易转换为如下的动画网格。首先,使用 marching cube 算法从每个时刻 t 生成的不透明度场中提取一个简单网格,然后进行网格抽取(为了提高效率)并且去除小噪声连接组件。XATLAS 算法用于将网格顶点映射到纹理图集,纹理初始化使用以每个顶点为中心的小球体中平均的 HexPlane 颜色。最后,为了更好地匹配一些由 HexPlane 使用可微网格渲染的示例帧,纹理会被进一步优化。这将产生一个纹理网格集合,可以在任何现成的 3D 引擎中回放。
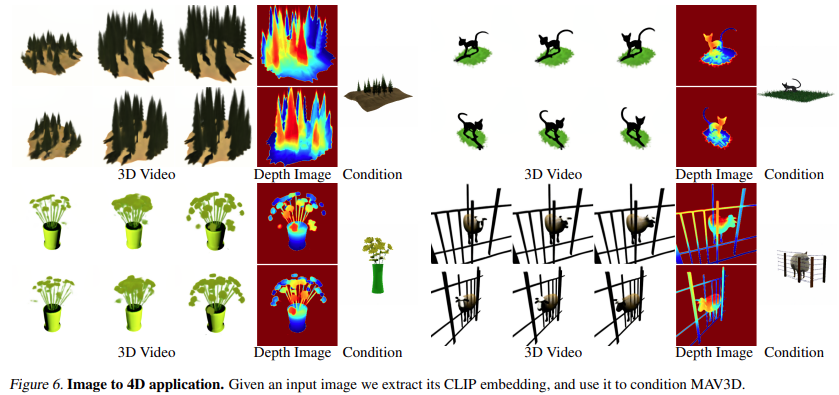
图像到 4D
图 6 和图 10 展示了该方法能够从给定的输入图像产生深度和运动,从而生成 4D 资产。



更多研究细节,可参考原论文。
探寻隐私计算最新行业技术,「首届隐语开源社区开放日」报名启程
春暖花开之际,诚邀广大技术开发者&产业用户相聚活动现场,体验数智时代的隐私计算生态建设之旅,一站构建隐私计算产业体系知识:
- 隐私计算领域焦点之性
- 分布式计算系统的短板与升级策略
- 隐私计算跨平台互联互通
- 隐语开源框架金融行业实战经验
3月29日,北京·798机遇空间,隐语开源社区开放日,期待线下面基。
点击阅读原文,立即报名。

© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-03-19,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号