NeurlPS2022 | 基于偏差感知间隔的对比学习协同过滤推荐算法

NeurlPS2022 | 基于偏差感知间隔的对比学习协同过滤推荐算法

TLDR:本文提出将偏差感知的间隔纳入到对比损失中,并提出了一个简单而有效的新损失函数。它通过鼓励相似的用户/物品的紧凑性和扩大不相似的用户/物品的分散性,来同时学习更好的头部和尾部表示。

论文: https://arxiv.org/abs/2210.11054
代码: https://github.com/anzhang314/BC-Loss
视频: https://www.koushare.com/video/videodetail/37794
协同过滤模型很容易受到流行度偏差的影响,这使得推荐系统偏离了用户的实际偏好。
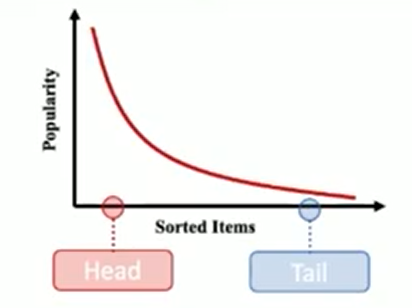
然而,目前大多数去偏策略(比如基于重排序的后处理、平衡训练损失等)都容易在头部和尾部物品性能之间进行权衡博弈,从而不可避免地降低了整体推荐的准确性。

为了减少流行度偏差对协同过滤模型的负面影响,本文将偏差感知的间隔(Bias-aware margin)纳入到对比损失(Contrastive loss)中,并提出了一个简单而有效的BC Loss,其中间隔量根据每个用户-物品交互的偏向程度进行定量调整。
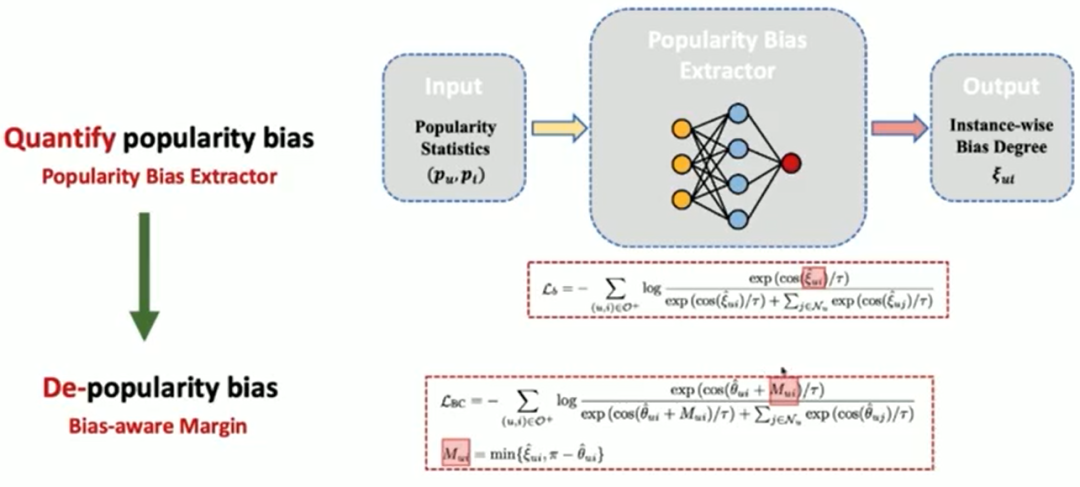
本文以softmax损失作为模型的学习策略:
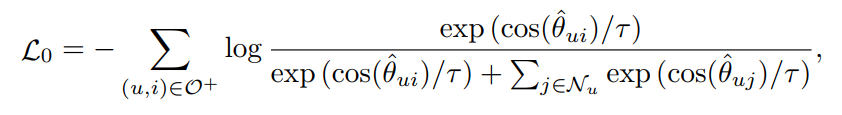
其中 表示用户的交互集合,表示用户采样的负样本。 表示softmax中的温度系数。基于以上公式,修改softmax损失以增强表征的判别能力并减轻流行度偏差带来的影响在很大程度上仍未被探索。因此,本文的工作旨在为协同过滤算法设计一种更通用、更广泛适用的softmax损失变体,从根本上提高长尾性能。
为了能够度量偏差,本文提出了利用流行度偏差提取器(Popularity Bias Extractor),并通过以下公式来进行优化。
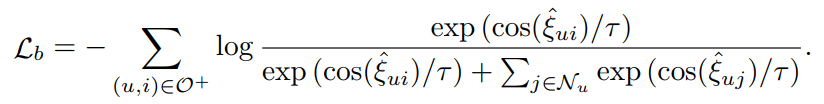
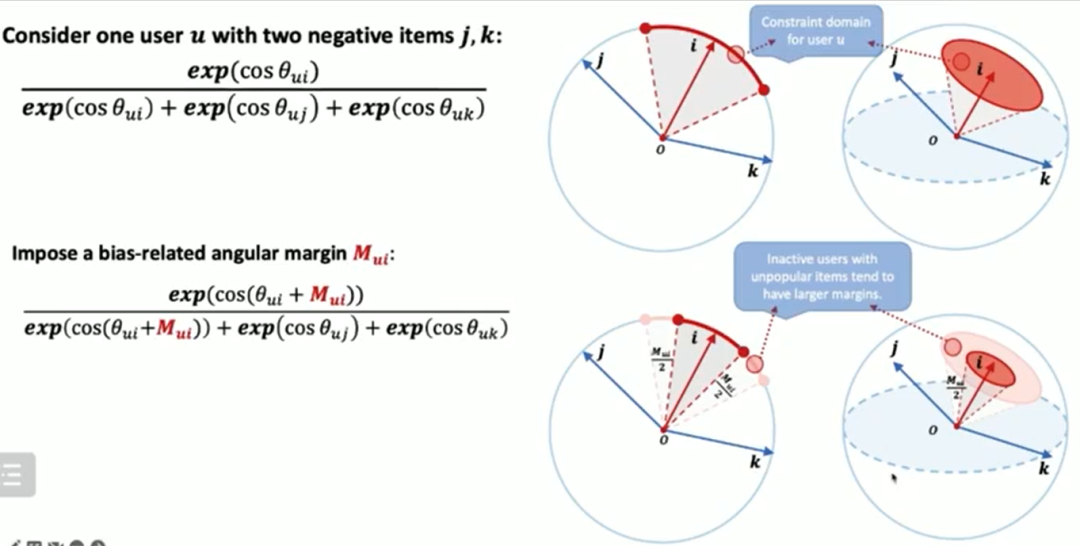
最后,本文为协同过滤模型设计一个新的间隔感知的对比损失BC loss。所提出的BC loss将相互作用偏差转换为表示之间的偏差感知角间隔,以增强特征表示的判别能力。具体的损失函数为:
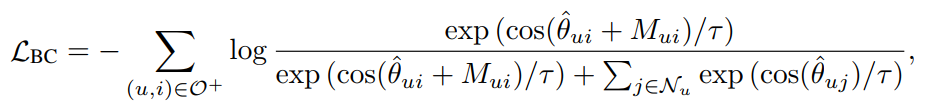
其中是相互作用的偏差感知角间隔,具体的间隔函数如下所示:
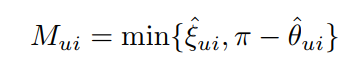
其中,是由流行度偏差提取器计算得来。
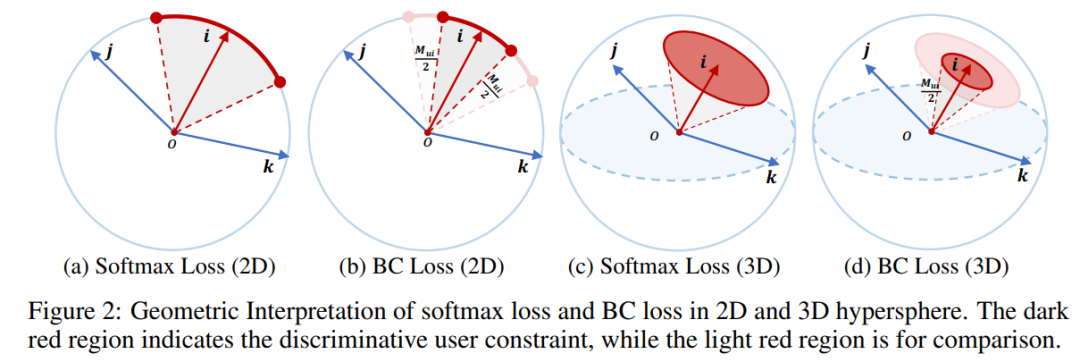
本文研究了BC loss的几何解释,然后进一步可视化并从理论上证明,它通过鼓励相似的用户/物品的紧凑性和扩大不相似的用户/物品的分散性,同时学会了更好的头部和尾部表示。
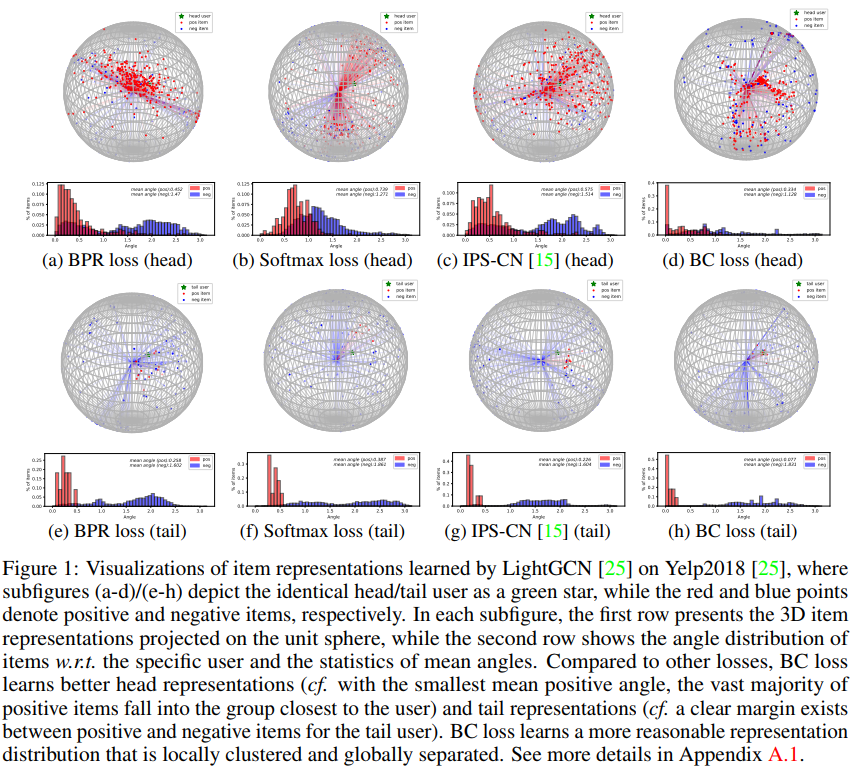
最后在八个基准数据集上,本文使用BC损失来优化两个高性能的CF模型,即MF和LightGCN。在各种评估设置(即不平衡/平衡、时间分割、完全观察无偏、尾部/头部测试评估)中,BC损失以显著的改进胜过最先进的去偏和非去偏方法。
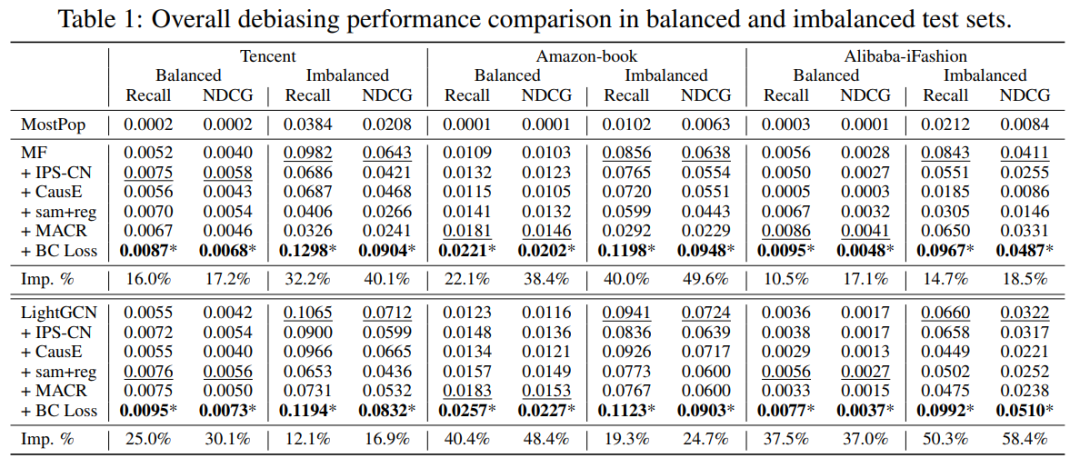
考虑到BC损失的理论保证和实验上的成功,本文认为不仅将其作为去偏策略,而且还可以作为推荐模型的标准损失。
腾讯云开发者
