DeepMind-代码:元学习认知模型 Meta-Learned Models of Cognition
DeepMind-代码:元学习认知模型 Meta-Learned Models of Cognition



https://github.com/marcelbinz/meta-learned-models(本文缺点是未考虑生物的非BP优化的生物本地优化的神经网络)
摘要
简而言之:近年来,元学习已经成为建立人类认知模型的一个有前途的工具。然而,一个连贯的研究项目
认知的元学习模型仍然缺失。本文的目的就是开发这样一个研究项目。我们通过指出元学习可以用来构造贝叶斯最优学习算法来实现这一点,允许我们与认知的理性分析建立强有力的联系。然后,我们讨论了元学习框架优于传统贝叶斯方法的几个优点,并在这些新见解的背景下重新检查了以前的工作。
long:元学习是一个通过与环境的反复交互来学习学习算法的框架,而不是手工设计它们。近年来,这个框架已经成为建立人类认知模型的一个有前途的工具。然而,围绕认知的元学习模型的连贯研究项目仍然缺失。这篇文章的目的是综合以前在这一领域的工作,并建立这样一个研究计划。我们依靠三大支柱来实现这一目标。我们首先指出元学习可以用来构造贝叶斯最优学习算法。这一结果不仅意味着任何可以用贝叶斯模型解释的行为现象也可以用元学习模型来解释,而且还允许我们与认知的理性分析建立强有力的联系。然后,我们讨论了元学习框架优于传统贝叶斯方法的几个优点。特别是,我们认为元学习可以应用于贝叶斯推理不可能的情况,它使我们能够通过整合有限的计算资源或神经科学知识,使理性的认知模型更加现实。最后,我们重新审视了心理学和神经科学中应用元学习的先前研究,并将它们放入这些新见解的背景中。总之,我们的工作强调了元学习极大地扩展了理性分析的范围,从而更广泛地扩展了认知理论的范围。
认知的元学习模型
很难想象没有计算模型的认知心理学和神经科学——它们是研究、分析和理解人类思维的无价工具。
传统上,这种计算模型是由专家研究人员手工设计的。例如,在认知架构中,研究人员提供了一组固定的结构以及这些结构如何相互作用的定义(Anderson,2013b)。在贝叶斯认知模型中,研究人员指定一个先验函数和一个似然函数——结合贝叶斯法则——完全决定模型的行为
(L .格里菲斯、肯普和B .特南鲍姆出版社,2008年)。元学习的框架(本吉奥,本吉奥,& Cloutier,1991;施密德胡伯,1987;Thrun & Pratt,1998年)提供了一种完全不同的方法来构建计算模型,通过与环境的反复交互来学习它们,而不是需要研究人员的先验规范。
最近,心理学家开始将元学习应用于人类学习的研究(Griffiths et al .,2019)。已有研究表明,元学习模型可以捕捉大量经验观察到的现象,这些现象无法用其他方法解释。
其中,他们复制了人类在概率推理中的偏见(Dasgupta,Schulz,Tenenbaum,& Gershman,2020),发现了人们使用的启发式决策策略(Binz,Gershman,Schulz,& Endres,2022),并以类似人类的方式对复杂的语言任务进行综合概括(Lake,2019)。本文的目标是围绕认知的元学习模型开发一个研究项目,并在这样做的过程中,提供一个先前工作的综合和概述新的研究方向。
为了建立这样一个研究项目,我们将利用机器学习社区的一个最新成果,该成果表明元学习可以用来构建
贝叶斯最优学习算法(Mikulik,Delétang等人,2020;奥尔特加等人,2019;Rabinowitz,2019)。从心理学的角度来看,这种对应是有趣的,因为它允许我们将元学习与另一种已经确立的学习联系起来
框架:认知的理性分析(安德森,2013a查特&奥克福德,1999年)。在一个理性的分析中,首先必须指定一个代理的目标,以及这个代理与之交互的环境的描述。然后基于这些假设推导出手头任务的贝叶斯最优解,并根据经验数据进行测试。如果需要,假设被修改并且整个过程被重复。这种构建认知模型的方法对心理学产生了巨大的影响,因为它解释了“在给定自然任务和环境结构的情况下,通过将其视为理想统计推断的近似,认知为什么会起作用”(Tenenbaum,2021)。对元学习模型可以实现贝叶斯推理的观察表明,元学习模型可以在理性分析中用作相应贝叶斯模型的替代,从而表明可以被贝叶斯模型捕获的任何行为现象也可以被元学习模型捕获。
我们的文章首先介绍了Ortega等人(2019年)最初提出的一个论点的简化版本,从而使他们的结果能够为更广泛的受众所接受。已经确定元学习产生可以模拟贝叶斯推理的模型,我们继续讨论元学习框架提供。毕竟,为什么一个人不应该只是坚持屡试不爽的贝叶斯方法?我们通过提供支持元学习框架的四个原始论点来回答这个问题(参见图1中的可视化概要):
1.元学习可以产生近似最优的学习算法,即使精确的贝叶斯推理在计算上是难以处理的。
2.元学习可以产生近似最优的学习算法,即使它不可能在第一时间表达相应的推理问题。
3.元学习使得操纵学习算法的复杂性变得容易,因此可以用来构建资源合理的学习模型。
4.元学习允许我们将神经科学的见解整合到理性分析中通过将这些见解整合到模型架构中。

前两点强调了元学习模型可以用于理性分析而传统贝叶斯模型不能的情况。后两点提供了元学习如何使我们能够通过整合有限的计算资源或神经科学见解来使认知的理性模型更加现实的例子。综上所述,这些论点表明元学习极大地扩展了理性分析的范围,从而更广泛地扩展了认知理论的范围。
我们将详细讨论这四点中的每一点,并提供插图来突出它们的相关性。然后,我们重新审视心理学和神经科学中应用元学习的先前研究,并将它们放入我们的环境中获得见解。对于每一个回顾的研究,我们强调它如何与四个提出的论点相关,并讨论为什么它的发现不能用经典的贝叶斯模型获得。接下来,我们描述在什么条件下传统模型优于通过元学习获得的模型。我们通过推测元学习的未来来结束我们的文章。在此,我们关注如何元学习可能是建立人类认知领域通用模型的关键。
1.元学习理性
前缀meta-通常用于自指意义:元规则是关于规则的规则,元讨论是关于讨论的讨论,等等。

因此,元学习指的是关于学习的学习。因此,在更详细地讨论元学习之前,我们需要首先建立一个学习的通用定义。对于本文,我们采用Mitchell (1997)的以下定义:
为了说明这个定义,考虑下面的例子,我们将在整个文本中返回:你是一个生物学家,刚刚发现了一个新的昆虫物种,现在给自己设定的任务是预测这个物种的成员有多大。你已经观察到三个野生样本,长度分别为16厘米、12厘米和15厘米。这些数据相当于你的训练经验。理想情况下,你可以利用这一经验更好地预测你遇到的下一个人的长度。如果你在看到数据后的表现比之前更好,就说你学到了东西。此示例问题的典型性能指标,包括均方误差或(负)对数似然。
1.1.理性分析的贝叶斯推理
在对认知的理性分析中,研究人员试图将人类行为与最佳学习算法的行为进行比较。然而,事实证明,在所有可能的问题上,没有一种学习算法比另一种算法更好(Wolpert,1996;Wolpert & Macready,1997),这意味着我们首先必须对要解决的问题做出额外的假设,以获得一个明确定义的最优性概念。对于我们的运行示例,可能会做出以下有点不现实的假设:
1.每个观察到的昆虫长度xk从具有平均值的正态分布中取样
和标准差σ。
2.一个昆虫物种的平均长度不能直接观察到,但标准差σ已知为2厘米。
3.所有昆虫物种的平均长度按照正态分布,平均值为10厘米,标准偏差为3厘米。
在这种假设下,对新的观测值进行预测的最佳方法是贝叶斯推理。贝叶斯推理需要访问先验分布p()和似然p(x1:t,先验分布p()定义了代理在观察任何数据之前对可能的参数值的初始信念,而似然捕获了代理关于如何为给定的一组参数生成数据的知识。在我们的运行示例中,先验和似然性可以确定如下:

其中x1:t = x1,x2,.。。xt表示观察到的昆虫长度的序列,并且等式2中的乘积是由于给定参数时观察是独立的这一附加假设而产生的。
贝叶斯推理的结果是一个后验预测分布p(xt+1x1:t,代理可以使用它对假设的未来进行概率预测
观察。为了获得这种后验预测分布,代理首先通过应用贝叶斯定理将先验和似然结合成参数的后验分布:

在随后的步骤中,代理然后对所有可能的参数值进行平均,这些参数值通过它们的后验概率进行加权,以获得后验预测分布:
多种论点证明贝叶斯推理是一种规范的程序,从而将其用于理性分析(Corner & Hahn,2013)。这包括荷兰书的论点(刘易斯,1999;M. Rescorla,2020),自由能最小化(Friston,2010;Hinton & Van Camp,1993),以及基于绩效的理由(Aitchison,1975;Rosenkrantz,1992)。对于本文,我们主要对后一类基于性能的论证感兴趣,因为这些可以用于——正如我们将在后面演示的——派生元学习算法,学习贝叶斯推理的近似。
基于绩效的理由是基于频率统计的概念。
他们断言,在某个性能指标上,没有任何学习算法能比贝叶斯推断更好。与本文特别相关的是Aitchison (1975)首先证明的一个定理。它指出,后验预测分布是(来自所有可能分布的集合)在对数据生成分布求平均时,使假设的未来观测值的对数似然最大化的分布
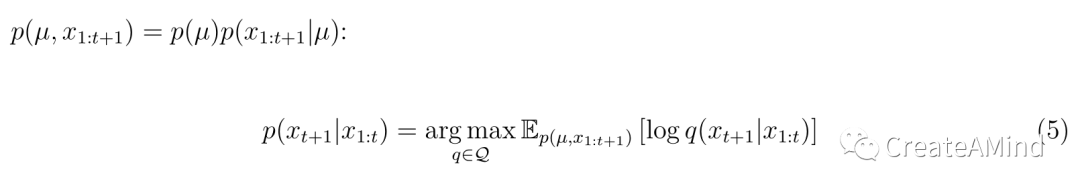
等式5意味着,如果一个主体想要预测一个特定昆虫物种的尚未观察到的样本的长度,并使用对数似然来衡量其表现,那么——在所有可能遇到的物种中平均——没有比使用后验预测分布更好的方法了。我们决定在方框1中为好奇的读者提供这个定理的简短证明,因为它没有出现在概率机器学习的流行教科书中(Bishop,2006;Murphy,2012)也没有出现在关于贝叶斯认知模型的调查文章中。请注意,虽然定理本身是我们后面讨论的核心,但完成它的证明并不是本文后面部分所必需的。
1.2.元学习
总结了贝叶斯最优学习背后的一般概念后,我们现在可以开始更详细地描述元学习。从形式上来说,元学习算法被定义为“使用其经验来改变学习算法或学习方法本身的某些方面,以使修改后的学习者在从额外经验中学习方面比原始学习者更好”的任何算法(Schaul & Schmidhuber,2010)。
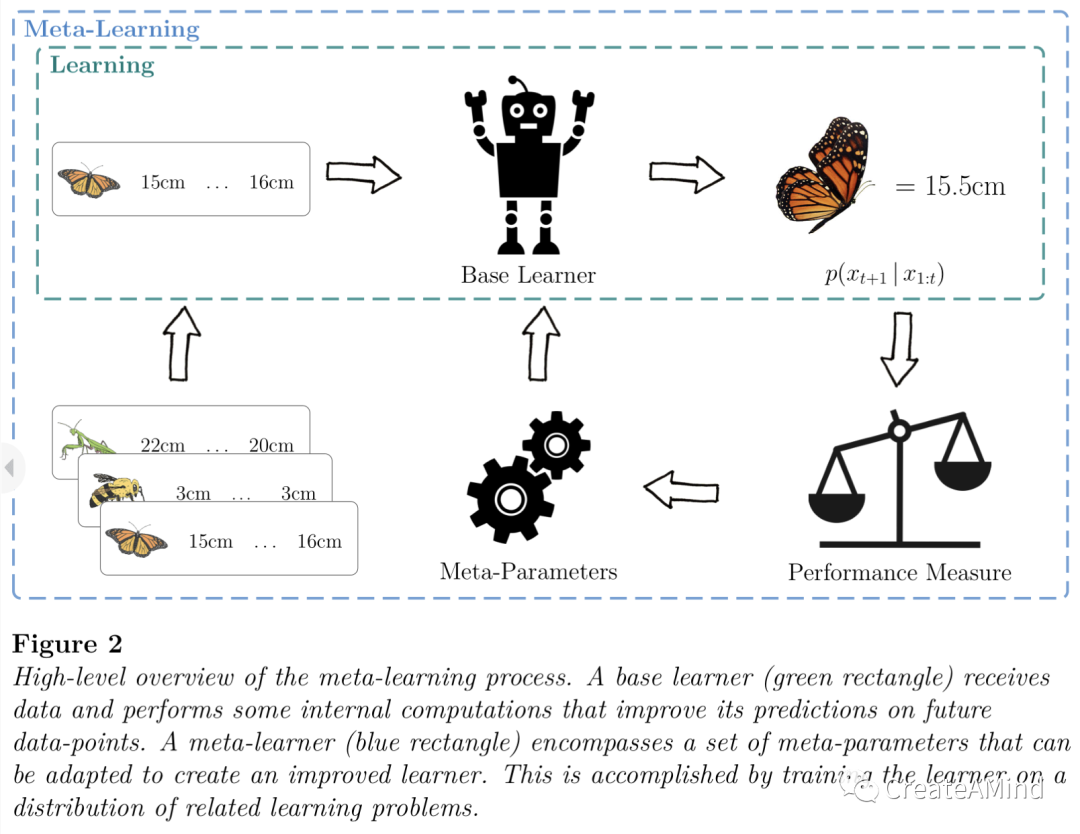
为了实现这一点,首先决定一个内循环(或基础)学习算法,并确定它的哪些方面可以修改。我们也将这些可修改的方面称为元参数。在外循环(或元学习)过程中,系统然后在一系列学习问题上被训练,使得内循环学习算法在解决它遇到的问题方面变得更好。我们在图2中提供了这个框架的高级概述。
前面的定义相当宽泛,包括各种方法。
示例,元学习的可能性:
•基本学习算法的超参数,例如学习速率、批量大小或训练时期的数量(Doya,2002;福雷尔&赫特,2019;李,周,陈,&李,2017)。
•通过随机梯度下降训练的神经网络的初始参数(Finn,Abbeel和Levine,2017;尼科尔、阿奇姆和舒尔曼,2018年)。
•概率图形模型中的先验分布(巴克斯特,1998;格兰特、芬恩、莱文、达雷尔&格里菲斯,2018)。
•整体学习算法(Hochreiter,Younger,& Conwell,2001;桑托罗,
巴图诺夫、博特维尼克、威斯特拉和莉莉卡普,2016年)。
虽然所有这些方法都有各自的优点,但我们将主要关注后一种方法。从零开始学习整个学习算法可以说是元学习中最普遍和最雄心勃勃的类型,这也是本文的重点,因为它是上述方法中唯一一种可以产生可用于理性分析的贝叶斯最优学习算法的方法。
1.3.元学习推理
从头开始学习整个学习算法似乎是一个令人生畏的目标,但我们在下面讨论的方法背后的核心思想非常简单:我们不是使用贝叶斯推理来获得后验预测分布,而是教导一个通用函数逼近器来进行这种推理。以前的工作主要集中在在这种情况下使用递归神经网络作为函数逼近器,因此我们将——不失一般性——集中讨论这类模型。
像后验预测分布一样,递归神经网络处理来自特定昆虫物种的观察长度序列,并产生来自相同物种的潜在未来观察长度的预测分布。更具体地,元学习预测分布采用预定的函数形式,其参数由网络输出给出。例如,如果我们决定使用正态分布作为元学习预分布的函数形式,网络的输出将对应于预期长度mt+1及其标准偏差st+1。图3a图示了这种设置。
最初,递归神经网络执行随机初始化的学习算法。1元学习过程的目标是将这个系统变成一个
1根据我们之前的定义,严格来说,它在这一点上根本不是一个学习算法,因为它不会随着额外的数据而改进。
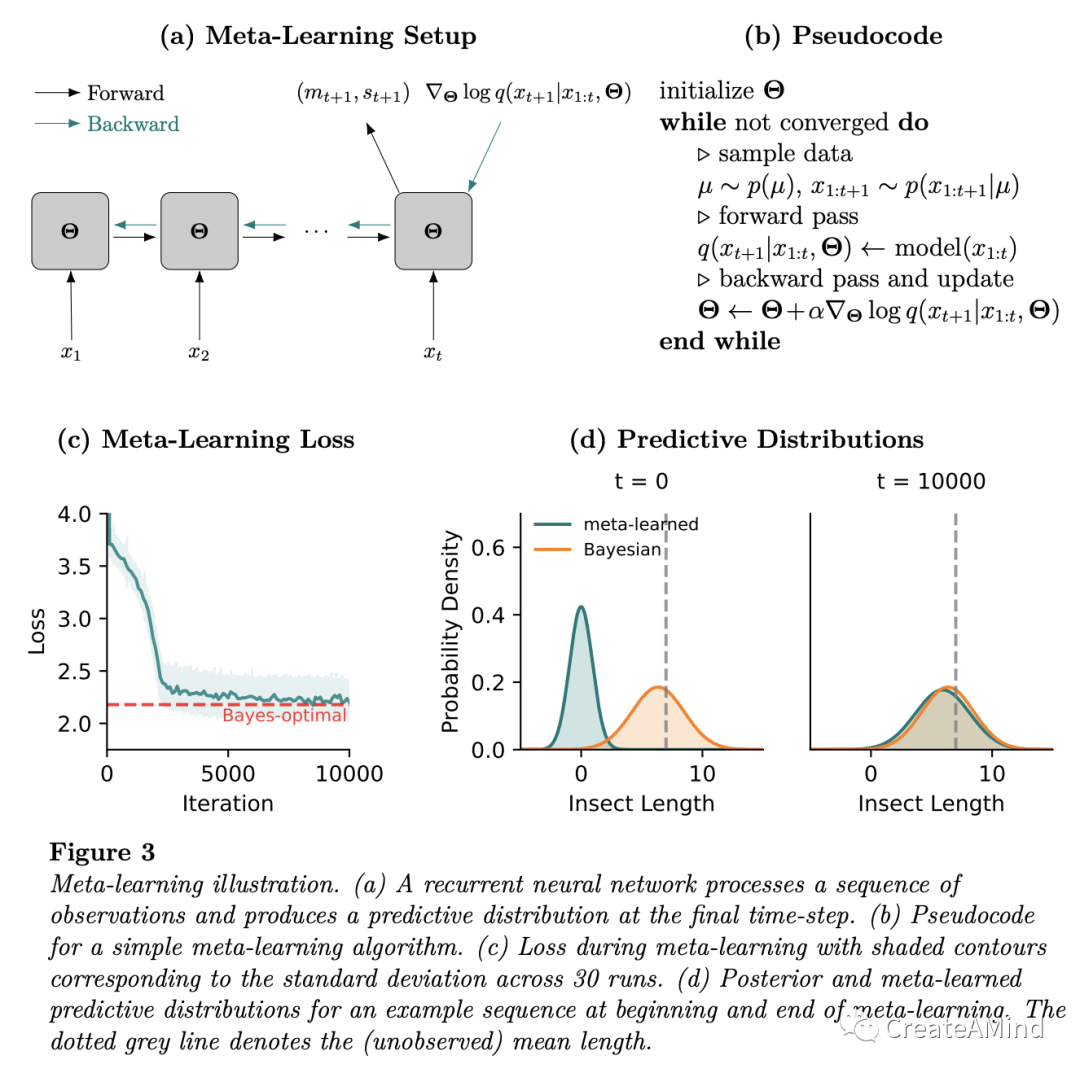
改进的学习算法。最终结果是学习或训练的学习算法,而不是由practitioner指定的。为了创建学习信号来进行这种训练,我们需要一种可以用来优化网络的性能测量。
等式5提出了一种用于设计这种测量的简单策略,即通过用元参数上的最大化来代替所有可能分布上的最大化
θ(在我们的例子中,是递归神经网络的权重):

图3b给出了使等式7最大化的简单的基于梯度的过程的伪代码。整个元学习算法可以在
大约30行自包含PyTorch代码(Paszke等人,2019)。我们在本文附带的github存储库上提供了一个带注释的参考实现。22https://github.com/marcelbinz/meta-learned-models
1.4.元学习算法有多好?
我们之前已经表明,等式7的全局最优是通过后验预测分布实现的。因此,通过最大化该性能测量,网络被积极地鼓励实现精确贝叶斯推断的近似。重要的是,在完成元学习之后,产生对后验预测分布的近似不需要对网络权重进行任何进一步的更新。为了进行推理,我们只需在提供给网络一个特定的观察序列后,查询网络的输出。
如果我们想使用完全优化的网络进行理性分析,我们必须问
我们自己:最终的模型有多接近贝叶斯推理?回答这个问题需要考虑两个方面。首先,网络必须具有足够的表达能力,以便为所有输入序列产生精确的后验预测分布。足够宽的神经网络是通用函数逼近器(Hornik,Stinchcombe和White,1989),这意味着它们可以以任意精度逼近任何连续函数。所以这方面对于最优性论证来说问题不大。第二个方面有点复杂:假设网络强大到足以表示等式7的全局最优,所采用的优化过程也必须找到它。虽然我们不知道任何可以提供这种保证的定理,但在实践中,已经观察到类似于这里讨论的元学习程序经常导致非常接近贝叶斯推理的网络(Mikulik,Delétang等人,2020;Rabinowitz,2019)。我们提供了一个可视化的例子,展示了元学习模型的预测非常类似于图3c-d中我们的昆虫长度例子的精确贝叶斯推断的预测。
虽然我们在本节中的论述集中在监督学习的情况下,但同样的想法也可以很容易地扩展到强化学习设置(段等人,2016;王等,2016)。方框2概述了元强化学习框架背后的一般思想。
1.5.工具还是理论?
把元学习和正常学习分开,往往不是那么微不足道的事情。我们认为,这种混乱的部分原因是由于对所研究的内容不够明确。特别是,元学习框架为解决两个不同的研究问题提供了机会:
1.它可以用来研究人们如何随着时间的推移提高他们的学习能力。
2.它可以被用作一种方法工具来构建具有感兴趣的属性的学习算法(然后将新兴的学习算法与人类行为比较)。
历史上,行为心理学家主要对前一方面感兴趣(Doya,2002;哈洛,1949)。例如,在20世纪40年代,Harlow (1949)已经研究了猴子的学习能力如何随着时间的推移而提高。他发现,在与具有共同结构的任务进行足够多的互动后,他们会调整自己的学习策略,从而显示出学习对学习的效果。到目前为止,这种现象的例子已经在自然界的许多不同物种中发现,包括人类(王,2021)。
最近,心理学家开始将元学习视为一种方法工具,用于构建贝叶斯最优学习算法的近似值(Binz等人,2022;Kumar,Dasgupta,Cohen,Daw和Griffiths,2020a),并随后利用产生的算法来研究人类认知。与前一种方法的主要区别是,在这种情况下,人们从元学习的过程中抽象出来,而是关注其结果。从这个角度来看,只有完全收敛的模型才是我们感兴趣的。
重要的是,这种方法允许我们从理性的角度研究人类的学习,因为我们已经证明了元学习可以用来构造贝叶斯最优学习的近似。
在本文中,我们将重点放在第二个方面,并提倡使用完全收敛的元学习算法——作为相应贝叶斯模型的替代——对认知进行理性分析。3在下一节中,我们将概述支持这种方法的几个论点。然而,值得一提的是,我们认为元学习也是理解学会学习过程本身的一个有价值的工具。在这种背景下,出现了几个有趣的问题:人类的元学习发生在什么时间尺度上?有多少是由特定任务引起的
3在认知心理学中有一个长期的概念性争论,即是否将贝叶斯模型视为规范性标准或描述性工具。我们认为这一争论超出了本文的范围,因此建议读者参考早期的工作进行深入讨论(Griffiths,Chater,Norris,& Pouget,2012;琼斯&洛夫,2011;陶贝尔、纳瓦罗、普勒斯&斯泰弗斯,2017;zed Nik & jkel,2016)。我们只想补充一点,这里概述的框架对这个问题是不可知的——元学习模型既可以作为规范性标准,也可以作为描述性工具。
改编?有多少是基于进化或发展过程的?虽然我们同意这些是重要的问题,但它们不是本文的重点。
2.为什么不是贝叶斯推理?
我们刚刚论证了元学习贝叶斯最优学习算法是可能的。这个结果意味着什么?如果有两种不同的理论可以做出相同的预测,那么哪一种更受青睐?近几十年来,贝叶斯推理已经成为建立认知模型的重要工具。因此,证明的责任可以说是在元学习框架上。
在这一部分,我们提供了四个不同的论点,强调了元学习在建立认知模型方面的优势。这些论点中有许多是新颖的,在以前的文献中没有明确提出过。前两个论点强调了元学习模型可以用于理性分析的情况,但是
传统的贝叶斯模型不能。后两者提供了元学习如何让我们通过整合有限的计算资源或神经科学见解,使认知的理性模型更加现实的例子。
2.1.难以理解的推理

贝叶斯推理很快变得难以处理,因为计算出现在分母中的归一化常数的复杂性随着未观察参数的数量呈指数增长。此外,对于先验和似然性的某些组合,只可能找到后验分布的封闭形式的表达式。在我们运行的例子中,我们假设先验和似然性都遵循正态分布,这反过来导致正态分布的后验概率。然而,如果取而代之的是假设平均长度上的先验服从指数分布——这可能是一个更合理的假设,因为它强制长度为正——已经不可能找到后验分布的解析表达式。
各学科的研究人员已经认识到这些挑战,并进而开发出可以近似贝叶斯推理而不会遇到计算困难的方法。这方面的主要例子是变分推理(约旦,Ghahramani,Jaakkola和索尔,1999年)和马尔可夫链蒙特卡罗(MCMC)方法(格曼和格曼,1984年)。在变分推断中,一个阶段的推断作为一个优化问题,通过定位一个变分近似,其参数是拟合的,以尽量减少分歧的措施,以真正的后验分布。另一方面,MCMC方法从以后验分布为平衡分布的马尔可夫链中抽取样本。认知科学的先前研究表明,人类的学习表现出这种近似的特征(库维尔&道,2008;达斯古普塔,舒尔茨,&格什曼,2017;道、库维尔和达扬,2008年;A. N .桑伯恩、格里菲斯和纳瓦罗,2010年;A. N .桑伯恩和席尔瓦,2013年)。
元学习推理也从不需要精确的后验或后验预测分布的显式计算。相反,它通过网络的单次前向传递来执行近似最佳的推断。在这种情况下,推断是近似的,因为我们必须确定预测分布的函数形式。所选择的形式可能偏离后验预测分布的真实形式,从而导致近似误差。4在某种意义上,这种近似类似于变分推断:两种方法都涉及优化,并要求定义各自分布的函数形式。然而,两种方法中的优化过程使用不同的损失函数,并且发生在不同的时间尺度。
4原则上,人们可以选择任意灵活的函数形式,如正态分布的混合或具有小面元大小的离散分布,这将减少伴随的近似误差。
虽然变分推断使用负证据下限作为其损失函数,但是元学习直接最大化可以预期很好地推广到看不见的观察的模型(使用来自等式5的基于性能的测量)。此外,元学习推理只涉及外环元学习过程中的优化,而不涉及实际学习本身。为了更新元学习模型如何根据新数据做出预测,我们只需通过网络执行简单的正向传递。与此相反,标准的变分推理要求我们在每次观察到新的数据点时从头开始重新运行整个优化过程。5
总之,元学习近似贝叶斯最优学习算法是可能的。如果精确的贝叶斯推理不容易处理,那么这种模型是我们进行理性分析的最佳选择。然而,用于近似推理的许多其他方法,例如变分推理和MCMC方法,也共享这一特征,因此这最终将是一个经验问题,即这些近似中的哪一个提供了对人类学习的更好描述。
2.2.未指明的问题

贝叶斯推理很难,但提出正确的推理问题可能更难。我们这样说到底是什么意思?为了执行贝叶斯推理,我们需要指定一个先验和一个可能性。这两个对象一起完全指定了假设的数据生成分布,从而指定了推断问题。理想情况下,指定的数据生成分布应该与环境实际生成数据的方式相匹配。在人工场景中满足这一要求相当简单,但是对于许多人来说
5这仅适用于标准的变分推断,但不适用于包括摊销的更高级方法,如变分自动编码器(Kingma & Welling,2013)。
现实世界的问题,并不是。以我们正在运行的例子为例:平均长度的先验真的遵循正态分布吗?如果是,这个分布的均值和方差是什么?潜在的参数实际上是不随时间变化的吗?或者说,它们是随季节而变化的吗?这些问题没有一个可以肯定地回答。
在他关于贝叶斯决策理论的开创性工作中,Savage (1972)区分了小世界和大世界问题。小世界问题是指“所有相关的替代方案、其后果和概率都是已知的”(Gigerenzer & Gaissmaier,2011)。另一方面,一个大的世界问题是先验的、可能性的或两者都不能被识别的问题。Savage对小世界和大世界的区分与人类认知的理性分析相关,因为其批评者指出,贝叶斯推理只为小世界问题中的最优推理提供了一个理由(Binmore,2007年),并且“认知科学、行为科学和社会科学感兴趣的问题很少能满足[这个]条件”(Brighton & Gigerenzer,2012年)。
一旦我们处理更复杂的问题,确定正确的假设集就变得特别具有挑战性。为了说明这一点,考虑由Lucas、Griffiths、Williams和Kalish (2015)进行的一项研究,他们试图构建人类功能学习的贝叶斯模型。这样做需要他们指定一个人们期望遇到的先验函数。由于无法直接获得这样的分布,他们选择了启发式解决方案:98.8%的函数是线性的,1.1%是二次的,0.1%是非线性的。从经验上看,这一选择带来了良好的结果,但从理性的角度来看很难证明这一点。我们只是不知道这些函数在现实世界中出现的频率,也不知道给定的选择是否完全覆盖了参与者期望的函数集。
还存在推断问题,其中不可能指定或计算似然函数。这些问题已经在机器学习社区中以基于模拟或无似然推理的名义进行了广泛的研究
(克兰默、布雷默和卢佩,2020年;吕克曼,伯尔茨,格林伯格,冈萨尔维斯和马克,2021年)。在这种情况下,通常假设我们可以根据给定参数设置的可能性对数据进行采样,但计算相应的可能性是不可能的。以我们的昆虫长度为例。应该清楚的是,昆虫的长度不仅取决于其物种的平均值,还取决于许多其他因素,如气候、遗传和个体年龄。即使所有这些因素都是已知的,将它们映射到一个似然函数似乎也几乎是不可能的。但是,我们可以通过观察野外的昆虫很容易地获得样本。如果我们可以访问不同物种昆虫长度测量的大型数据库,这可以直接用于元学习近似贝叶斯最优学习算法来预测它们的长度,同时绕过似然函数的显式定义。
在我们无法获得先验或可能性的情况下,我们既不能应用精确的贝叶斯推理,也不能应用近似推理方案,如变分推理或MCMC方法。与此相反,元学习推理不需要我们明确定义先验或可能性。它只需要来自数据生成分布的样本来元学习近似贝叶斯最优的学习算法——这是一个弱得多的要求(穆勒、霍尔曼、阿兰戈、格拉博卡和赫特,2021)。为大世界问题构建贝叶斯最优学习算法的能力是元学习框架的一个独特特征,我们相信它可以为构建人类认知的理性模型开辟全新的途径。举一个具体的例子,有可能收集现实世界的决策任务,如Czerlinski、Gigerenzer、Goldstein等人(1999年)提出的任务,并使用它们来获得一个元学习代理,该代理适应人们在日常生活中实际遇到的决策问题。这种算法可以作为一种规范性标准,我们可以根据它来比较人类的决策。
2.3.资源合理性

贝叶斯推理已经成功地应用于许多领域的人类行为建模,包括感知(克尼尔和理查兹,1996年),运动控制(柯尔丁和沃伯特,2004年),日常判断(格里菲斯和特南鲍姆,2006年),以及逻辑推理(奥克福德,查特等人,2007年)。尽管有这些成功的故事,但也有证据充分的偏离贝叶斯推理所规定的最优概念。例如,人们对先验信息反应不足(Kahneman & Tversky,1973),忽视证据(Benjamin,2019),依赖启发式决策策略(Gigerenzer & Gaissmaier,2011)。
贝叶斯推理的艰巨性——以及经验观察到的偏离——导致研究人员推测人们只是试图近似贝叶斯推理。人们对计算资源的构成提出了许多不同的概念,如记忆(Dasgupta & Gershman,2021年)、思考时间(Ratcliff & McKoon,2008年)或物理努力(Hoppe & Rothkopf,2016年)。
Cover (1999)提出了一个二分法,这将有助于我们下面的讨论。他将算法的复杂度称为实现算法所需的位数。相比之下,他将算法的计算复杂性称为执行它所需的空间、时间或努力。有可能将许多近似推理方案转换为资源合理算法(A. N. Sanborn,2017)。产生的模型通常考虑某种形式的计算复杂性。在MCMC方法中,计算复杂度可以用抽取样本的数量来衡量:抽取的样本越少,推断速度越快,但代价是引入了偏差(库维尔&道,2008;A. N. Sanborn等人,2010年)。另一方面,在变分推理中
另一方面,可以引入一个额外的参数,该参数允许在性能和将先验分布转换为后验分布的计算复杂度之间进行权衡(Binz & Schulz,2022b奥尔特加、布劳恩、戴尔、金和蒂什比,2015年)。同样,构建资源理性模型的其他框架,如理性元推理(Lieder & Griffiths,2017年),也只针对计算复杂性。
基于计算复杂性的资源合理模型的流行可能是因为基于算法复杂性构建类似的模型要困难得多。测量算法复杂性历史上依赖于Kolmogorov复杂性的概念,它是产生特定数据序列的最短计算机程序的大小(Chaitin,1969;Kolmogorov,1965;Solomonoff,1964)。Kolmogorov复杂性通常是不可计算的,因此实际意义有限
元学习为我们提供了一种直接的方法,通过调整底层神经网络模型的大小,在一个通用的框架中操纵算法和计算的复杂性。限制网络权重的复杂性限制了算法的复杂性(因为减少权重的数量减少了存储它们所需的比特数量,因此也减少了存储学习算法所需的比特数量)。另一方面,限制激活的复杂性限制了计算复杂性(例如,减少隐藏单元的数量,减少了执行元学习模型所需的内存)。
以前,这两种形式的复杂性约束都是在元学习模型中实现的。Dasgupta等人(2020)减少了元学习推理算法的隐藏单元数量,有效地降低了其计算复杂性。相比之下,Binz等人(2022)对神经网络权重的描述长度进行了限制,这实现了一种形式的算法复杂性。据我们所知,没有其他阶级资源合理模型的存在,允许我们考虑算法和计算的复杂性,使这种能力成为元学习框架的独特特征。
2.4.神经系统科学

除了为理解行为的许多方面提供一个框架,元学习还提供了一个观察大脑结构和功能的强有力的镜头。例如,Wang等人(2018)提出了支持前额叶回路可能构成元强化学习系统的假设的观察结果。从计算的角度来看,元学习试图通过在较慢的外环学习过程中调整神经网络的权重来学习更快的内环学习算法。在大脑中,一个类似的过程很可能在缓慢时发生,
多巴胺驱动的突触变化引发了强化学习过程,这一过程发生在前额叶网络的活动动态中,允许在更快的时间尺度上适应。这一观点重新诠释了多巴胺功能在基于奖励的学习中的作用,并能够解释一系列先前令人困惑的神经科学发现。举例来说,Bromberg-Martin、Matsumoto、Hong和Hikosaka (2010)发现,多巴胺信号不仅反映了目标的经验价值,也反映了目标的推断价值。值得注意的是,一个接受过相同任务训练的元强化学习代理也恢复了这种模式。有…的映射
对现有大脑区域的元强化学习组件还允许我们应用直接干扰神经活动的实验操作,例如通过使用光遗传技术。王等人(2018年)利用这一想法修改了他们最初的元强化学习架构,以模仿阻断或增强
多巴胺能奖赏预测误差信号,与传递给执行双臂强盗任务的大鼠的光遗传刺激直接类比(Stopper,Maric,Montes,Wiedman,& Floresco,2014)。
重要的是,交换的方向也可以在另一个方向上起作用,神经科学的发现限制并激发了元学习架构的新形式。例如,Bellec,Salaj,Subramoney,Legenstein和Maass (2018)表明,SNN脉冲神经元的循环网络能够显示令人信服的学习对学习行为,包括在强化学习领域。情景元强化学习(Ritter et al .,2018)架构也深受大脑中互补学习系统的神经科学账户的启发(麦克莱兰、麦克诺顿和奥莱利,1995)。这两个例子都证明了元学习可以用来构建更具生物学合理性的学习算法,从而突出了它可以作为Marr的计算和实现级别之间的桥梁(Marr,2010)。
最后,元学习的观点不仅允许我们通过架构设计选择来连接机器学习和神经科学,还允许我们通过感兴趣的任务类型来连接机器学习和神经科学。例如,Dobs,Martinez,Kell和Kanwisher (2022)认为,在生物大脑中广泛观察到的神经回路中的功能专门化是任务需求的结果。特别是,他们发现在人脸和物体识别上训练的卷积神经网络描述了基于这些任务的紧急隔离。同样,G. R. Yang,Joglekar,Song,和Wang (2019)发现,训练单个递归神经网络来执行广泛的认知任务会产生沿着不同功能认知过程聚集的单元。换句话说,通过在多项任务上训练神经网络来实现功能专业化似乎是合理的。虽然到目前为止这还没有被测试过,我们推测这在元学习环境中也成立,因为它涉及到设计的多任务训练。如果这是真的,我们可以看看元学习模型中的新兴领域,并使用由此产生的见解来生成关于个体大脑区域发生的过程的新颖预测(Kanwisher,Khosla和Dobs,2023)。
3.之前的研究
今天,元学习模型已经开始改变认知科学。
它们允许我们对传统模型难以捕捉的事物进行建模,例如组合概括、语言理解和基于模型的推理。在这一节中,我们概述了在以前的工作中借助元学习所取得的成就。我们将这篇综述分成不同的主题分类。对于其中的每一个,我们总结了通过元学习获得的关键发现,并通过借鉴上一节的见解,讨论了为什么使用传统的学习模型难以获得这些结果。
3.1.启发式和认知偏差
元学习之前已经被用于发现计算预算有限的算法,这些算法显示了我们之前已经提到的类似人类的认知偏差。Dasgupta等人(2020年)在控制隐藏单元数量的同时,就概率推理问题的分布训练了一个神经网络。他们发现,他们的模型——当仅限于单个隐藏单元时——捕捉到了人类推理中的许多偏差,包括保守主义偏差和基本速率忽略。同样,Binz等人(2022年)训练了一个关于决策问题分布的神经网络,同时控制了表示网络所需的位数。他们的模型在特定环境中发现了两种先前建议的启发式方法,并对这些启发式方法何时应用做出了精确的预测。具体来说,知道特征的正确排序导致决策的一个原因,知道特征的方向导致等权重启发式,而不知道它们中的任何一个导致使用特征的加权组合的策略(也参见图4a-b)。
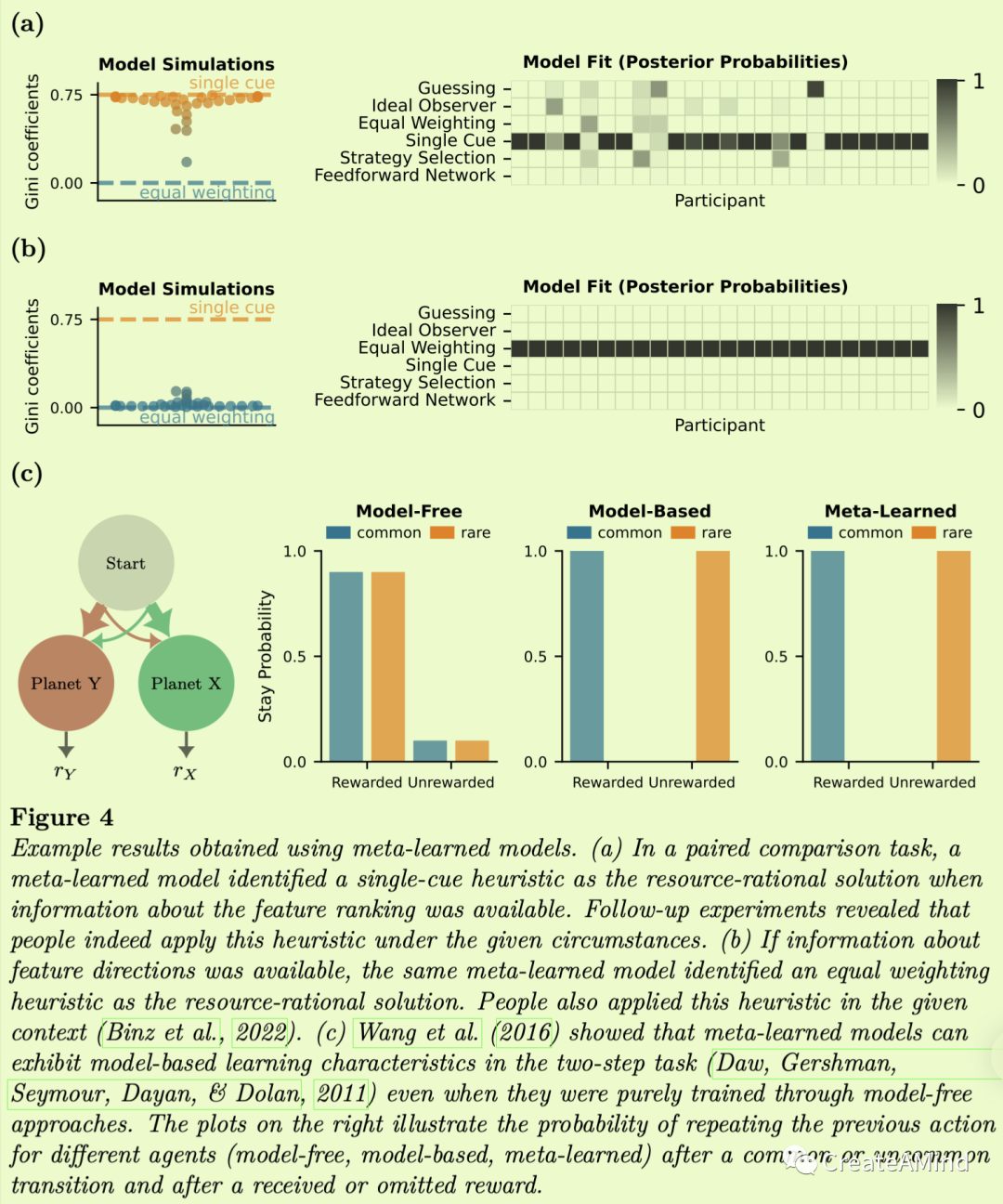
使用元学习模型获得的示例结果。(a)在成对比较任务中,当关于特征排序的信息可用时,元学习模型将单线索启发式确定为资源合理的解决方案。后续的实验表明,人们确实在给定的情况下运用了这种启发法。(b)如果关于特征方向的信息是可用的,相同的元学习模型确定了一个等权重启发式作为资源合理的解决方案。人们也在给定的上下文中应用了这种启发法(Binz等人,2022)。(c) Wang等人(2016年)表明,元学习模型可以在两步任务中表现出基于模型的学习特征(Daw,Gershman,Seymour,Dayan和Dolan,2011年),即使它们是通过无模型方法纯粹训练的。右边的图显示了在一个普通或不普通的转换之后,以及在一个收到或忽略的奖励之后,不同的代理(无模型的、基于模型的、元学习的)重复前面的动作的概率。
在这两项研究中,元学习模型为以前被认为是矛盾的结果提供了一个新的视角。这部分是可能的,因为
元学习使我们能够轻松地操纵潜在学习算法的复杂性。虽然这样做至少在理论上在贝叶斯框架内也是可能的,但是到目前为止还没有发现一个贝叶斯模型能够捕捉到Dasgupta等人(2020年)和Binz等人(2022年)的全部发现。我们假设这可能是因为传统的理性过程模型甚至在接收到任何直接反馈信号之前就很难捕捉到人类策略选择是依赖于上下文的(梅塞尔和斯珀伯,2017)。另一方面,Dasgupta等人(2020年)和Binz等人(2022年)的元学习模型在接受适当的任务分配训练时,能够很容易地显示出特定背景的偏差。
3.2.语言理解
元学习也可以帮助我们回答关于人们如何处理、理解和产生语言的问题。习得一门语言所需的归纳偏差是从经验中习得还是遗传而来就是这些问题之一(Y. Yang & Piantadosi,2022)。McCoy、Grant、Smolensky、Griffiths和Linzen (2020)研究了如何为模型配备一组与人类认知相关的语言归纳偏差。他们对这个问题的解决方案建立在模型不可知的思想上
元学习(Finn等人,2017)。特别是,他们对神经网络的初始权重进行了元学习,这样网络就可以使用标准的基于梯度的学习来快速适应新的语言。当在跨语言的分布上被训练时,这些初始权重可以被解释为跨所有语言共享的通用因子。他们表明,这种方法可以识别归纳偏差(例如,将某些音素视为元音的偏差),这对获取语言的音节结构很有用。虽然他们的工作集中在不同的建模方面,但是他们认为他们的框架“可以”。。。]被用来实证研究这些归纳性偏差的影响。”他们还认为,贝叶斯建模方法只能考虑一组限制性的归纳偏差,因为它需要致力于特定的表示和推理算法。相比之下,元学习框架通过简单地操纵遇到的语言的分布,很容易实现预期的归纳偏差。
将简单元素组合成复杂实体的能力是人类语言的核心。语言“无限使用有限手段”的特性(乔姆斯基,2014)使我们能够从有限的数据中做出强有力的概括。例如,在了解了动词“dax”的含义后,人们很容易理解“dax两次”或“dax慢”的意思。然而,如何以相似的熟练程度建立模型,仍然是一个开放的研究问题。Lake (2019)表明,可以通过元学习训练一个类似变压器的神经网络来进行这种组合归纳。重要的是,在元学习过程中,他的模型适应了需要综合归纳的问题,从而可以获得解决全新问题所需的技能。Lake (2019)认为,元学习“对理解人们如何综合概括有影响。”特别是,它强调了“处理一系列不断变化的学习问题,而不是迭代一个静态数据集”的重要性,正如传统的神经网络训练方案所做的那样。
3.3.归纳偏差
人类的认知伴随着许多有用的归纳偏见,超出了综合推理的能力。对简单的偏好就是这些偏见之一(Chater & Vitányi,2003;费尔德曼,2016)。我们很容易提取抽象的低维规则,使我们能够概括全新的情况。元学习是建立具有相似偏好的模型的理想工具,因为我们可以根据简单的规则轻松地生成任务,并使用它们进行元学习,从而使代理能够从数据中获得所需的归纳偏差。为此,Kumar、Dasgupta、Cohen、Daw和Griffiths (2020b)进行了测试,人类和元强化代理在一系列由语法生成的结构化任务上,将他们的表现与在具有匹配统计的相同任务的非结构化版本上训练的那些人进行比较。在Kumar,Dasgupta等人(2022)中,他们将这些结果扩展到从简单抽象规则生成的更大的任务套件。人类发现在结构化任务中更容易学习,这证实了他们对简单的抽象规则有很强的偏好(Schulz,Tenenbaum,Duvenaud,Speekenbrink和Gershman,2017)。然而,他们的分析也表明,元学习在非结构化任务上比结构化任务更容易。在后续工作中,他们发现这一结果也适用于只接受结构化任务训练但同时接受两种任务评估的代理人(Kumar,Correa等人,2022)——考虑到人们会期望代理人在接受训练的任务分配中表现更好,这是一个非常惊人的发现。
作者通过在训练期间指导代理再现人们提供的描述给定任务的自然语言描述,来解决人类和元学习代理之间的这种不匹配。他们发现,在自然语言描述中建立元学习代理不仅提高了他们的性能,还导致了更像人类的归纳偏差,证明了自然语言可以作为人类认知中抽象的来源。
他们的工作利用另一种有趣的技术来训练元学习代理(Kumar,Correa等人,2022;Kumar,Dasgupta等人,2022年)。它不依赖于手工设计的任务分布,而是涉及使用被称为Gibbs与人一起采样的技术从人类参与者的先前分布中采样任务(Harrison等人,2020;桑伯恩和格里菲斯,2007年)。虽然这样做为他们提供了任务的数据集,但是他们上的相应先验分布的表达式是不可访问的,因此,为给定设置定义贝叶斯模型是很重要的。另一方面,通过对收集的样本进行训练,很容易获得元学习代理。
3.4.基于模型的推理
许多现实场景提供了两种不同类型的学习:无模型和
基于模型。无模型学习算法使用观察到的结果直接调整它们的策略。另一方面,基于模型的学习算法学习环境的转移和回报概率,然后用于下游的推理任务。人们通常认为能够执行基于模型的学习,至少在某种程度上,并假设手头的问题需要它(Daw等人,2011;库尔、库什曼和格什曼,2016年)。Wang等人(2016)表明,元学习算法可以显示基于模型的行为,即使它是通过纯无模型强化学习算法训练的(见图4c)。
拥有一个世界模型也是因果推理的基础。
传统上,进行因果推理依赖于Pearl的do-calculus概念(Pearl,2009)。然而,Dasgupta等人(2019年)表明,元学习可以用于创建从观察数据中得出因果推断的模型,选择信息干预,并进行反事实预测。虽然他们没有将他们的模型与人类数据直接联系起来,但在未来的工作中,它可以作为研究人们如何在复杂领域做出因果判断的基础,并解释他们为什么以及何时偏离规范的因果理论(Bramley,Dayan,Griffiths,& Lagnado,2017;格斯滕贝格、古德曼、拉格纳多和特南鲍姆,2021年)。
这两个例子一起强调了基于模型的推理能力可以在元学习模型中内部出现,如果它们有利于解决遇到的问题。虽然已经有许多传统模型可以执行这些任务,但这些模型在运行时通常很慢,因为它们通常涉及贝叶斯推理、规划或两者兼有。另一方面,元学习“将大部分计算负担从推理时间转移到训练时间,这在训练时间充足但运行时需要快速答案时是有利的”(Dasgupta等人,2019年),因此可以解释人们如何在合理的时间框架内执行如此复杂的计算。
虽然基于模型的推理是元学习模型的新兴属性,但如果需要,它也可以明确地集成到这种模型中。Jensen、Hennequin和Mattar (2023)已经采用了这种方法,并增强了标准元强化学习代理的能力,使其能够使用想象的展开来执行时间扩展规划。在每个时间步中,他们的代理可以决定执行规划操作,而不是直接与环境交互(在这种情况下,是空间导航任务)。他们的元学习代理人选择在训练后持续执行这个计划操作。
重要的是,该模型显示出与人类思考模式惊人的相似之处,通过在早期进行更多的规划,并随着距离目标的增加而增加。
此外,他们发现海马回放的模式类似于他们模型的展开。
3.5.探测
人们不仅必须将观察到的信息整合到他们现有的知识中,而且他们还必须主动确定要采集什么信息。他们经常面临这样的情况,需要他们决定是否应该探索新的东西,或者是否应该利用他们已经知道的东西。先前的研究表明,人们使用定向和随机探索策略的组合来解决这种探索-开发困境(Gershman,2018;舒尔茨&格什曼,2019;威尔逊、吉纳、怀特、拉德维格和科恩,2014年;吴,舒尔茨,施佩肯布林克,纳尔逊,和梅德,2018年)。为什么人们使用这些特殊的策略而不使用其他的?Binz和Schulz (2022a)假设他们这样做是因为人类的探索遵循资源合理的原则。为了验证这一说法,他们通过结合元学习和信息论的思想,设计了一系列资源合理的强化学习算法。他们的元学习模型发现了一套不同的探索策略,包括随机和定向探索,比其他方法更好地捕捉了人类的探索。在这个领域,元学习提供了一条直接的途径
致力于研究这样一种假设,即人们试图以最佳方式探索,但受制于有限的计算资源,而设计手工制作的模型来研究同一问题会更加复杂。
不仅决定如何探索很重要,而且首先决定探索是否值得。Lange和Sprekeler (2020)使用元学习框架研究了这个问题。他们的元学习代理能够在实现探索性学习行为和硬编码学习行为之间灵活地进行插入,
非学习策略。重要的是,哪种行为被实现主要取决于环境属性,如任务分布的多样性、任务的复杂性和主体的生命周期。例如,他们表明,寿命短的代理人应该选择容易找到的小奖励,而寿命长的代理人应该把时间花在探索环境上。Lange和Sprekeler (2020)的研究清楚地表明,元学习使得在认知的理性分析中迭代不同的环境假设在概念上变得容易。
他们只需要根据需要修改环境,然后重新运行元学习程序。相比之下,传统的建模方法需要在每次环境发生变化时手工设计一个新的最优代理。
3.6.认知控制
人类非常善于适应特定任务的需求。这种能力背后的过程统称为认知控制(Botvinick,Braver,Barch,Carter和Cohen,2001)。Cohen (2017)甚至认为“认知控制能力可能是人类行为最显著的特征。”因此,从计算的角度来看,认知控制受到大量关注也就不足为奇了(Botvinick & Cohen,2014;柯林斯&弗兰克,2013)。
最近,一些计算研究已经扩展到元学习框架。
根据需要调整计算资源的能力是认知控制的一个标志。Moskovitz,Miller,Sahani和Botvinick (2022)提出了一个具有这些特征的元学习模型。他们的模型学习了一个简单的默认政策——类似于Binz和Schulz (2022a)的模型——必要时可以用一个更复杂的政策覆盖。他们证明,这个模型不仅能够从认知控制文献中捕捉行为现象,还能够捕捉决策和强化学习任务中的已知效应,从而将这三个领域联系起来。重要的是,他们的研究强调了元学习框架提供了考虑多种计算成本而不仅仅是一种成本的方法——在这种情况下,实现默认策略的成本和偏离默认策略的成本。
考虑背景线索是认知控制的另一个重要方面。Dubey,Grant,Luo,Narasimhan和Griffiths (2020)在元学习框架中实现了这一思想。在他们的模型中,背景线索决定了特定任务神经网络的初始化,然后使用模型不可知的元学习对其进行训练。他们表明,这样的模型捕捉到了“在一个简单但经过充分研究的认知控制任务中,人类行为的环境敏感性。”此外,他们还证明了该方法可以很好地扩展到更复杂的领域(包括MuJoCo(、Erez和Tassa,2012年)、CelebA Liu、罗、王和唐(2015年)以及MetaWorld (Yu等人,2020年)基准测试中的任务),从而为在自然场景中模拟人类行为开辟了新的机会。
4.为什么不是所有东西都是元学习的?
我们已经列出了不同的论点,使元学习成为构建认知模型的有用工具,但重要的是要注意,我们并没有这样说元学习是所有建模问题的最终解决方案。相反,了解元学习何时适合工作,何时不适合是至关重要的。
4.1.缺乏可解释性
也许它最大的危害是元学习从来没有给我们提供可以检查、分析和推理的分析解决方案。与此相反,一些贝叶斯模型有解析解。以我们之前遇到的数据生成分布(等式1-2)为例。对于这些假设,a
后验预测分布的闭式表达式是可用的。通过观察这种封闭形式的表达式,研究人员产生了新的预测,并随后对它们进行了经验测试(Daw等人,2008;达扬&卡卡德,2000;格什曼,2015)。
用元学习模型进行同样的分析并不简单。我们无法获得潜在的数学表达式,这使得理论的结构化探索更加困难。
也就是说,仍然有方法来分析元学习模型的行为。
首先,使用促进可解释性的模型架构是可能的。Binz等人(2022年)依靠这种方法,设计了一种神经网络架构,该架构产生概率单位回归模型的权重,然后用于将应用的策略聚类成不同的类别。这样做使他们能够识别在特定情况下他们的元学习模型使用了哪种策略。
最近,研究人员也开始使用来自认知心理学的工具来分析黑盒模型的行为(Rich & Gureckis,2019;里特、巴雷特、桑托罗和伯特温尼克,2017年;舒尔茨&达扬,2020)。例如,可以像对待心理学实验中的参与者一样对待这些模型,并使用收集的数据来分析他们的行为,类似于心理学家分析人类行为的方式(Binz & Schulz,2023;达斯古普塔等人,2022;拉赫万等人,2019;Schramowski,Turan,Andersen,Rothkopf和Kersting,2022年)。我们认为,这种方法在分析日益强大和不透明的人工智能体方面具有巨大的潜力,包括通过元学习获得的人工智能体。
4.2.复杂的训练过程
当使用元学习框架时,人们还必须处理这样一个事实,即训练神经网络是复杂和耗时的。神经网络模型包含许多活动部分,如权重初始化或所用的优化器,必须对其进行适当选择,以便训练可以在第一时间开始,训练本身可能需要数小时或数天才能完成。当我们想修改
数据生成分配,我们必须从头开始重新培训整个系统。因此,尽管在元学习框架中迭代不同环境假设的过程在概念上是简单明了的,但它可能是耗时的。相比之下,贝叶斯模型有时可以更快地适应环境假设的变化。为了说明这一点,让我们假设您想要通过元学习模型来解释人类行为,该元学习模型是根据来自等式1-2的数据生成分布来训练的,但是发现结果模型并不与观察到的数据很好地吻合。接下来,您要考虑另一个假设,即人们假设一个非平稳的环境。虽然这种修改可以在相应的贝叶斯模型中快速完成,但元学习框架需要对新生成的数据进行再训练。
此外,不能保证完全收敛的元学习模型实际上实现了贝叶斯最优学习算法。虽然我们能够与简单情况下的分析解决方案进行比较,如我们的昆虫长度示例,但通常不可能验证元学习算法是最佳的。事实上,有元学习未能找到贝叶斯最优解的报道(王等,2021)。我们相信,通过用各种不同的方式验证元学习模型,这个问题可以得到某种程度的缓解。但是,最终未来的工作应该提出验证元学习模型的技术。
4.3.元学习还是贝叶斯推理?
总之,两种框架——元学习和贝叶斯推理——都有其独特的优点和缺点。元学习框架不会也不会取代贝叶斯推理,而是对其进行补充。它拓宽了我们可用的工具包,使研究人员能够研究以前无法触及的问题。然而,在某些情况下,传统的贝叶斯推理是更合适的建模选择,正如我们在本节中概述的那样。
5.神经网络的作用
到目前为止,我们讨论的大多数问题都与实现元学习算法的函数逼近器无关。然而,与此同时,我们已经在整个文本的不同点诉诸神经网络。当一个人看先前的工作时,也可以观察到神经网络是元学习环境中的主要模型类。为什么会这样呢?除了它们的普遍性,神经网络还提供了一个巨大的机会:它们提供了一个灵活的框架,用于将不同类型的归纳偏差设计到计算模型中(Goyal & Bengio,2022)。在下一节中,我们将重点介绍三个例子,说明之前的工作是如何实现这一点的。对于这些例子中的每一个,我们都从心理学中提取了一个概念,并展示了它是如何容易地适应元学习模型的。
也许认知建模中最有说服力的观点之一是
基于梯度的学习。它不仅是最有影响力的模型之一——resco rla-Wagner模型(Gershman,2015;R. A. Rescorla,1972)——但也在许多其他人类学习理论中占有突出地位,如连接主义模型(鲁梅尔哈特,麦克莱兰,集团,等,1988)。即使前面概述的
元学习过程依赖于外环中基于梯度的学习,由此产生的内环动态必须与梯度下降没有任何相似之处。然而,可以构建元学习模型,其内环更新依赖于基于梯度的
学习。Finn等人(2017)提出了一种称为模型不可知元学习的元学习技术,该技术可以找到前馈神经网络的最佳初始参数,随后通过梯度下降进行训练。其思想是这些最佳初始参数允许前馈网络以最少数量的梯度步骤推广到多个任务。虽然它们的一般设置与我们讨论的类似,但它导致了通过梯度下降进行学习的模型,而不是在递归神经网络的动力学中实现学习算法的模型。Kirsch和Schmidhuber (2021)最近将这两种方法整合到一个模型中。他们提出的架构由多个相互作用的递归神经网络组成。
重要的是,他们表明这些网络的一种特定配置可以在正向传递中实现反向传播,从而能够在基于记忆的系统中执行基于梯度的学习。
基于样本的模型——如广义类别模型(Nosofsky,2011年)——是建模人们如何将物品归类到不同类别的最重要方法之一(Kruschke,1990年;谢泼德,1987)。他们根据新实例和以前看到的实例之间的估计相似性对该实例进行分类。最近,具有基于样本的推理能力的元学习模型已经被提出用于少镜头分类的任务,其中分类器必须基于仅包含几个样本的训练集进行概括。匹配网络(Vinyals,Blundell,Lillicrap,Wierstra等人,2016年)通过使用训练集中类别的相似性加权组合对新数据点进行分类来实现这一点。重要的是,相似性是在学习的嵌入空间上计算的,从而确保模型可以扩展到高维刺激。后续工作从另一个具有巨大影响力的人类类别学习模型中获得了灵感,并用基于类别原型的机制取代了匹配网络中使用的基于样本的机制(Snell,Swersky和Zemel,2017)。
最后,使用与先前经验的相似性进行推理不仅对监督学习有用,而且在强化学习环境中也有用。在……里
强化学习文献,存储和回忆状态或轨迹以备后用的能力被称为情景记忆(Lengyel & Dayan,2007)。有人认为,情景记忆可能是解释人类在自然环境中表现的关键(Gershman & Daw,2017)。情节记忆在神经科学中也发挥着至关重要的作用,研究表明,高回报的实例存储在海马体中,并在需要时可供回忆(Blundell et al .)(2016)。
Ritter等人(2018年)基于Pritzel等人(2017年)的神经情节控制思想,并利用差分神经字典进行情景回忆
元学习。他们的字典存储了以前经历过的任务的编码,以后需要时可以查询。有了这个补充,他们的元学习模型能够回忆起以前发现的策略,使用类别示例检索记忆,处理组合任务,在穿越环境时恢复记忆,并恢复人们在神经科学启发的任务中使用的学习策略。
总之,人类认知伴随着各种归纳偏差,神经网络提供了灵活的方式来轻松地将它们纳入认知的元学习模型。我们在本节中概述了三个这样的例子,展示了如何将基于梯度的学习、基于范例和原型的推理以及情景记忆集成到元学习模型中。此外,对于神经网络架构,还有许多其他归纳偏差可以在元学习的上下文中使用,但尚未使用。例子包括执行差异化规划的网络(Farquhar,rocktschel,Igl,& Whiteson,2017;Tamar,Wu,Thomas,Levine,& Abbeel,2016),提取基于对象的表征(Piloto,Weinstein,& Botvinick,2022;Sancaktar,Blaes,& Martius,2022),或通过突触可塑性修改自己的连接(Miconi,Rawal,Clune,& Stanley,2020;Schlag,Irie和Schmidhuber,2021年)。
6.走向人类学习的领域通用模型
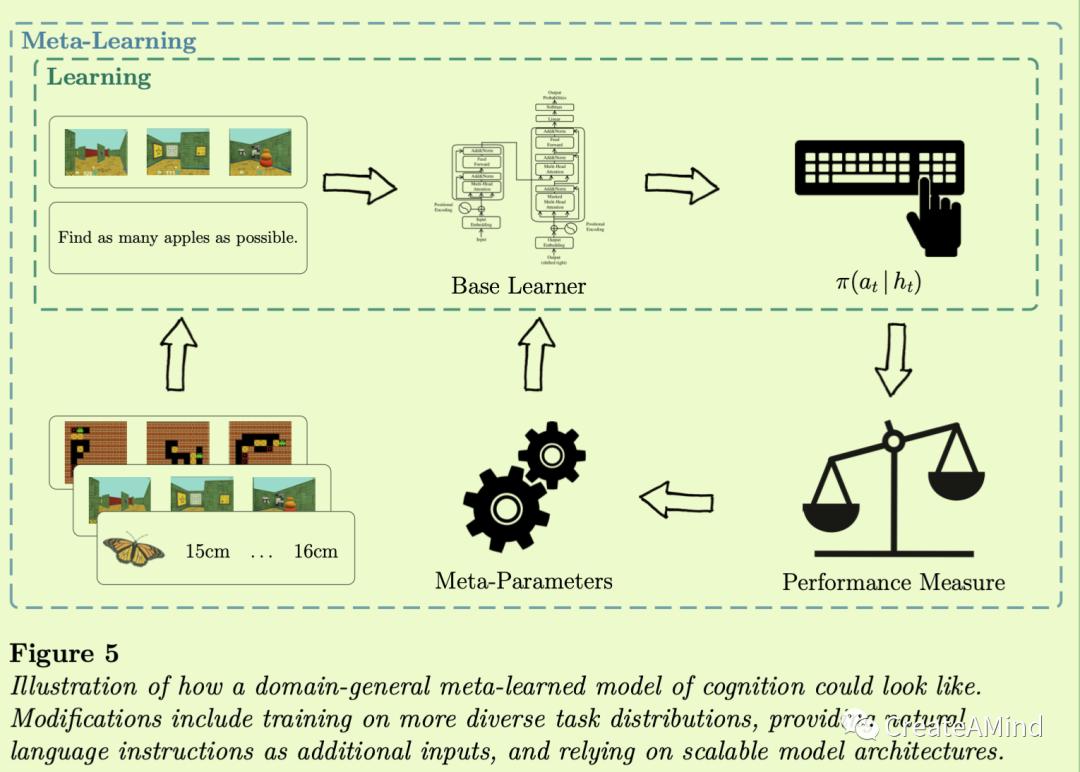
元学习的未来会怎样?当代的认知的元学习模型几乎专门针对特定问题家族的数据生成分布进行训练。虽然这种训练过程使他们能够归纳到这个问题家族中的新任务,但他们不太可能归纳到完全不同的领域。例如,如果元学习算法只被训练来预测昆虫种类的长度,我们就不会期望它执行具有挑战性的迷宫导航任务。
虽然特定领域模型已经(并将继续)为重要的研究问题提供答案,但我们同意Newell (1992)的观点,即“统一的认知理论是将这一奇妙的、不断增加的知识基金置于智力控制之下的唯一途径。( “unified theories of cognition are the only way to bring this wonderful, increasing fund of knowledge under intellectual control.”)”理想情况下,这样一个统一的理论应该在一个领域一般认知模型,不仅能够解决预测任务,而且能够像人类一样做出决策(Gigerenzer & Gaissmaier,2011),类别学习(Ashby,Maddox,等人,2005),导航(Montello,2005),问题解决(Newell,Simon,等人,1972)等等。我们认为元学习框架是实现这一目标的理想工具,因为它允许我们将关于主体对世界的信念(论点1和2)及其计算架构(论点3和4)的任意假设编译成认知模型。
然而,为了通过元学习获得这样一个领域通用的认知模型,需要解决几个挑战。首先,有一个迫在眉睫的问题
应该构建包含许多不同问题的数据生成分布。在这里,我们可能会从机器学习社区中获得灵感,在那里,研究人员通过在大量问题上训练神经网络,设计了通用代理(Reed等人,2022)。(A. A. Team et al .,2023)最近表明,这是扩大元学习模型的一条有前途的道路。他们在一个拥有超过10**40个可能任务的巨大开放世界上训练了一个元强化学习代理。可以适应像人类一样快速地解决问题,并“展示即时假设驱动的探索,有效利用获得的知识,并可以通过第一人称演示成功地得到提示。”同样,我们可能会想出一大堆更常用于研究人类行为的任务(Miconi,2023;莫拉诺-马孙等人,2022;G. R. Yang等人,2019),并使用它们来训练认知的元学习模型。
语言很可能在未来的元学习系统中扮演重要角色。我们不想要一个通过反复试验从头开始学习每项任务的系统,而是一个可以提供一套指令的系统,就像在心理学实验中如何指导人类受试者一样。具有语言能力的智能体不仅能使他们以零距离的方式理解新任务,还能提高他们的认知能力。例如,它允许他们将任务分解为子任务,从其他代理学习,或生成解释(Colas,Karch,Moulin-Frier,& Oudeyer,2022)。
幸运的是,我们目前最好的语言模型(布朗等人,2020;Chowdhery等人,2022)和元学习系统都基于神经网络。因此,将语言能力整合到认知的元学习模型中应该——至少在概念上——相当简单(真的吗???)。这样做将进一步使这种模型能够收获语言的组合性质,以对元学习分布之外的任务进行强有力的概括。最近的一项研究(Riveland & Pouget,2022年)强调了这一点的潜力,该研究发现,语言条件下的递归神经网络模型可以高精度地执行全新的心理物理任务。
此外,一个足够通用的人类认知模型不仅必须能够在几个给定的选项中进行选择,如在决策或类别学习环境中,而且还需要在复杂的世界中进行操作。为此,它需要感知和处理高维的视觉刺激,它需要控制一个具有多个自由度的身体,它需要积极地与其他代理进行互动。其中许多问题一直是深度学习社区的核心(Hill等人,2020;麦克莱兰,希尔,鲁道夫,巴尔德里奇和舒茨,2020年;斯特劳斯,麦基,伯特温尼克,休斯和埃弗雷特,2021年;O.E. L. Team et al .,2021),看看那里开发的解决方案是否可以集成到认知的元学习模型中,这将是有趣的。
最后,在算法方面也有一些需要考虑的挑战。特别是,目前还不清楚目前使用的模型架构和外环学习算法的规模有多大。虽然当代的元学习算法能够找到简单问题的近似贝叶斯最优解,但它们有时很难在更复杂的问题上做到这一点(例如,在王等人(2021)的早期讨论的工作中)。因此,简单地增加
元学习分布是不够的——我们还需要能够处理日益复杂的数据生成分布的模型架构和外环学习算法。transformer architecture(vas Wani等人,2017),在训练大型语言模型方面非常成功(Brown等人,2020;Chowdhery等人,2022年),提供了一个有希望的候选人,但可能有无数其他(迄今尚未发现)的替代品。
因此,总的来说,创建一个领域通用的认知元学习模型仍然有很大的挑战。特别是,我们在本节中已经指出,我们需要(1)对更多样化的任务分配进行元学习,(2)开发能够以自然语言的形式解析指令的代理,(3)将这些代理体现在现实的问题设置中,以及(4)找到可扩展到这些复杂问题的模型架构。图5以图形方式总结了这些要点。
7.结论
大多数人类学习的计算模型都是手工设计的,这意味着在某些时候,研究人员会坐下来定义它们的行为。元学习从一个完全不同的前提开始。人们不是手工设计学习算法,而是通过反复让系统与环境交互来训练系统实现其目标。在…期间,从表面上看,这似乎与传统的学习模型大相径庭,我们已经强调了元学习框架实际上与贝叶斯推理的思想有着很深的联系,从而与认知的理性分析有着很深的联系。以这种联系为出发点,我们强调了元学习框架在构建理性认知模型方面的几个优势。总之,我们的论点表明,元学习不仅可以应用于贝叶斯推理不可能的情况,而且有助于将计算约束和神经科学见解纳入人类认知的理性模型。早期对认知的理性分析的批评一再指出,“理性贝叶斯模型明显不受约束”,它们应该“结合机械论的考虑来发展,以提供对认知的实质性解释”(Jones & Love,2011)。我们相信元学习框架提供了一个理想的机会允许灵活的计算机制的无痛集成。
值得指出的是,元学习也可以以神经网络为起点来激发。从这个角度来看,它通过将神经网络模型的可扩展性引入认知的理性分析,弥合了两个最受欢迎的认知理论——贝叶斯模型和连接主义。因此,我们相信元学习提供了一个强大的工具来将心理学理论扩展到更复杂的环境。然而,与此同时,元学习还没有兑现这一承诺。现有的认知元学习模型通常应用于已经建立模型的经典场景。因此,我们不得不问:是什么阻止了对更复杂和更普遍的范例的应用?首先,这种范式本身必须得到发展。幸运的是,目前有一种在更自然的任务中测量人类行为的趋势(Brä ndle,Stocks,Tenenbaum,Gershman,& Schulz,2022;布兰多,宾兹&舒尔茨,2022;Schulz等人,2019年),这将是一个有趣的角色,元学习将在这种环境下的行为建模中发挥作用。此外,元学习可能是复杂和耗时的。我们希望本文——以及附带的代码示例——能让这种技术更加清晰,更容易被更多的读者所理解。未来硬件的进步可能会使元学习过程更快,因此我们希望元学习最终能够实现其承诺,即在手工设计的算法无法达到的情况下识别人类认知的合理模型。
阅读原文见代码
相关推荐:
腾讯云开发者
