综述 | 自监督学习时间序列分析:分类、进展与展望

自监督学习(SSL)最近在很多深度学习任务上取得了优异的表现,它最显著的优点是可以减少对标签数据的依赖。基于预训练和微调策略,即使只有少量的标签数据也可以取得不错的效果。
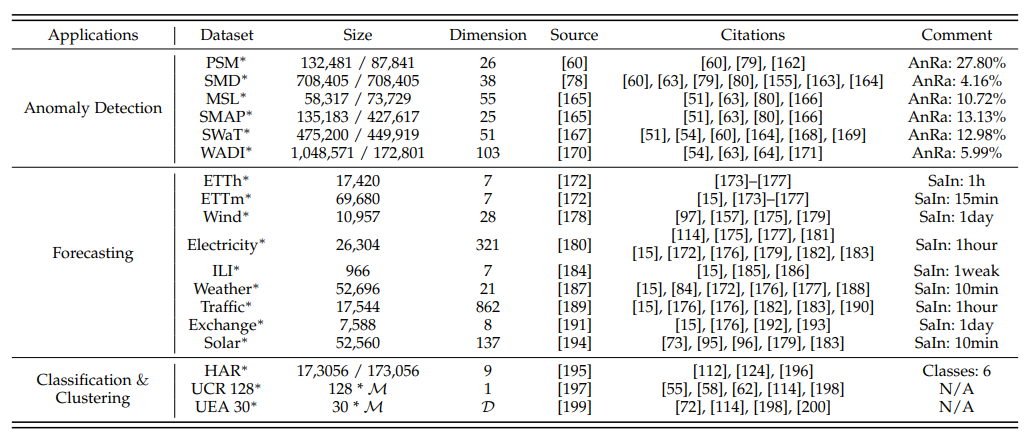
最近,来自浙大和阿里的研究者们总结回顾了当前针对时间序列数据的最先进的SSL方法,撰写综述提供出一个新的时间序列 SSL 方法的分类。他们将自监督学习时间序列分析归纳为三类:基于生成的,基于对比的和基于对抗的。所有的方法都可以进一步分为十个子类别。为了进行时间序列 SSL 方法的实验验证,研究者们还总结了用于时间序列预测、分类、异常检测和聚类任务的数据集。
本期文章将为大家简要分享这篇文章中的精华要点,供广大研究者开发者们参考。

论文地址:https://arxiv.org/abs/2306.10125
自监督学习简介
自监督学习(Self-Supervised Learning,简称SSL)是一种机器学习方法,它从未标记的数据中提取监督信号,属于无监督学习的一个子集。该方法通过创建”预设任务“让模型从数据中学习,从而生成有用的表示,可以用于后续任务。它不需要额外的人工标签数据,因为监督信号直接从数据本身派生。通过设计精良的预设任务,自监督学习在计算机视觉(CV)和自然语言处理(NLP)等领域取得了很大的成功。
这些预设任务通常需要模型通过数据的某种形式预测其它部分。例如,在自然语言处理任务中,预设任务可能包括:屏蔽某些单词,然后预测它们(称为“掩码语言模型”),或者重新排列句子的顺序,然后让模型找出正确的顺序。在计算机视觉中,预设任务可能包括:预测图像的某部分的颜色,或者确定图像的某些部分是否被扭曲或旋转等。
自监督学习的一个重要优点是,它能从大量未标记的数据中学习,而这些数据通常比标记数据更容易获得。此外,由于这种方法不依赖于人工标签,因此可以减少标签错误的影响。自我监督学习在多种任务中都显示出了与监督学习相媲美的性能,这使得它在处理各种实际问题时具有巨大的潜力。
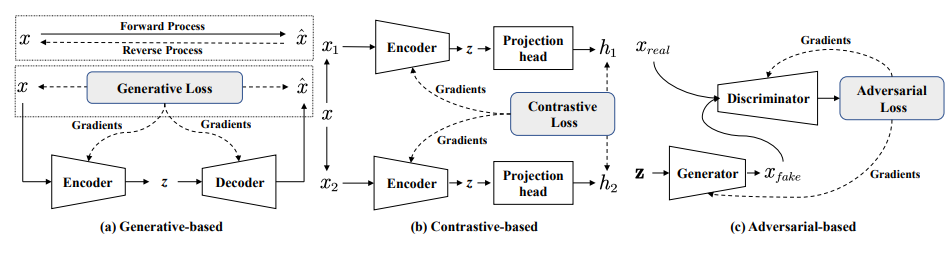
自我监督学习(SSL)的方法通常可以分为三类:
- 基于生成的方法:这种方法首先使用编码器将输入x映射到表示z,然后使用解码器从z重构x。训练目标是最小化输入和重构输入之间的重构误差。
- 基于对比的方法:这是最广泛使用的SSL策略之一,它通过数据增强或上下文采样构建正样本和负样本。然后通过最大化两个正样本之间的互信息(Mutual Information)来训练模型。对比方法通常使用对比相似度度量,例如 InfoNCE loss。
- 基于对抗的方法:这种方法通常由一个生成器和一个判别器组成。生成器生成假样本,而判别器用来区分它们和真实样本。
基于生成的方法
在这个类别中,预文本任务是基于给定的数据视图生成预期的数据。在时间序列建模的背景下,常用的预文本任务包括使用过去的系列来预测未来的时间窗口或特定的时间戳,使用编码器和解码器重构输入,以及预测被遮盖的时间序列的未见部分。如下图所示:
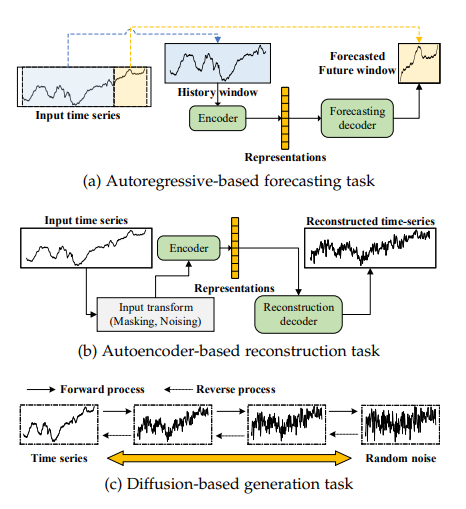
该文的研究者们总结出三种基于生成的自监督学习方法,他们是:基于自回归的预测、基于自编码器的重构和基于扩散模型的生成。值得注意的是,基于自编码器的重构任务也被视为一种无监督框架。在自监督学习(SSL)的背景下,主要使用重构任务作为预文本任务,最终目标是通过自编码器模型获得表示。
基于对比的方法
对比学习是一种广泛使用的自监督学习策略,在计算机视觉和自然语言处理中表现出强大的学习能力。与学习映射规则至真实标签的判别模型和尝试重构输入的生成模型不同,基于对比的方法旨在通过正样本和负样本的对比来学习数据表示。具体而言,正样本应具有类似的表示,而负样本应具有不同的表示。因此,正样本和负样本的选择对于基于对比的方法非常重要。
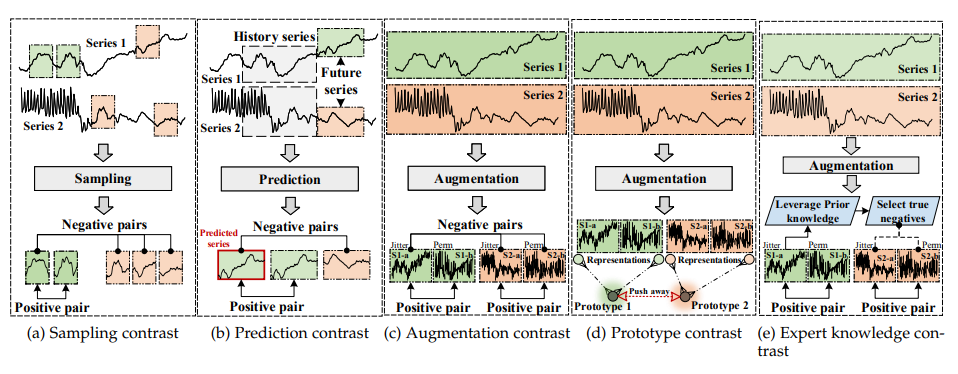
如上图所示,研究者根据正样本和负样本的选择对时间序列建模中现有的基于对比的方法进行整理和总结,他们有:
- 采样对比法:采样对比法遵循时间序列分析中广泛使用的假设,即两个相邻的时间窗口或时间戳具有高度的相似性,因此,正样本和负样本直接从原始时间序列中采样;
- 预测对比法:使用上下文(现在的信息)来预测目标(未来的信息)的预测任务被视为自监督预文任务,目标是最大限度地保留上下文和目标的互信息;
- 增强对比法:增强对比法是最广泛使用的对比框架之一。大多数方法利用数据增强技术生成输入样本的不同视图,然后通过最大化来自同一样本的视图的相似性,并最小化来自不同样本的视图的相似性来学习表示;
- 原型对比法:原型对比学习框架本质上是一种实例区分任务,它鼓励样本在特征空间中形成均匀分布。然而,真实的数据分布应满足同类样本更集中在一个聚类中,而不同聚类间的距离应更远;
- 专家知识对比法:专家知识对比是一种相对较新的表示学习框架。一般来说,这种建模框架将专家的先验知识或信息融入到深度神经网络中,以指导模型的训练。
基于对抗的方法
基于对抗的自监督表示学习方法使用生成对抗网络(GANs)来构建预文本任务。如下图所示:
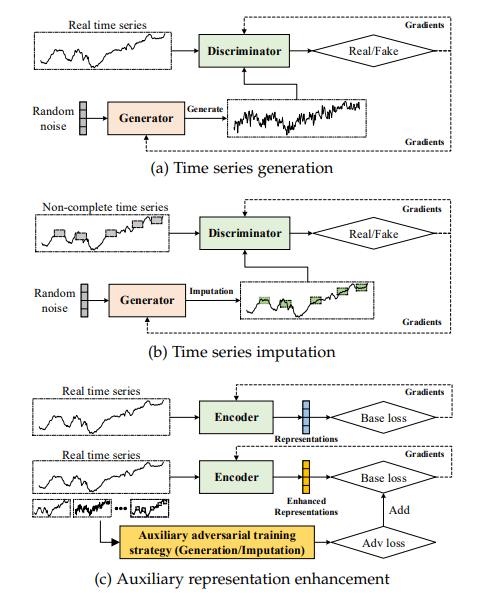
GAN 包含一个生成器 G 和一个判别器 D。生成器 G 负责生成类似于真实数据的合成数据,而判别器 D 负责判断生成的数据是真实数据还是合成数据。因此,生成器的目标是最大化判别器的判断失败率,而判别器的目标是最小化其失败率。这种博弈关系的学习目标是:
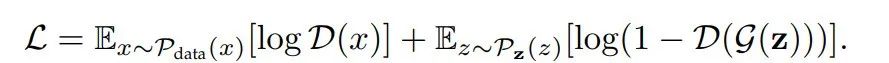
根据最终任务,现有的基于对抗的表示学习方法可以分为:时间序列生成与插补,辅助表示增强。这些基于对抗的自监督学习(SSL)的示例显示在上图中。
应用与数据集
自监督学习(SSL)在各种时间序列任务中都有广泛的应用,例如预测、分类、异常检测等。
01
异常检测
时间序列的异常检测问题主要是在一定的规范或常见信号的基础上,识别出异常的时间点或异常的时间序列。由于获取异常数据的标签具有挑战性,所以大多数时间序列异常检测方法都采用无监督学习框架。其中,基于自回归的预测和基于自编码器的重构是最常用的建模策略。例如,THOC 和GDN 使用基于自回归的预测的自监督学习框架,该框架假设异常的序列或时间点是不可预测的。而RANSynCoders,USAD,AnomalyTrans 和DAEMON 则使用基于自编码器的重构的自监督学习框架,该框架的原理是异常的数据是难以重构的。此外,VGCRN 和FuSAGNet 结合了两种框架,以实现更强健和准确的检测结果。在检测模型中引入基于对抗的自监督学习方法可以进一步扩大正常数据和异常数据之间的差异,如USAD 和 DAEMON。
02
预测
时间序列预测是通过使用统计和建模技术来分析时间序列数据,从而预测未来的时间窗口或时间点。基于自回归预测的预文字任务本质上就是一个时间序列预测任务。因此,已经提出了各种基于预测任务的模型,如Pyraformer,FilM,Quatformer,Informer,Triformer,Scaleformer,Crossformer,和Timesnet。我们发现,分解时间序列(如季节性和趋势),然后在分解的组件上进行学习和预测,可以提高最终预测的精度,如MICN 和 CoST。当时间序列中存在缺失值时,引入对抗性的自监督学习是可行的。例如,LGnet 引入了对抗训练以增强对全局时间分布的建模,这降低了缺失值对预测精度的影响。
02
分类和聚类
分类和聚类任务的目标是识别特定时间序列样本所属的真实类别。由于对比学习的核心是识别正样本和负样本,因此基于对比的自监督学习方法是这两个任务的最佳选择。具体来说,TSTCC 引入了时间对比和上下文对比,以获得更强健的表示。TS2Vec 和 MHCCL 在增强的视图上进行分层的对比学习策略,这使得获得更强健的表示成为可能。与异常检测和预测任务类似,基于对抗的自监督学习策略也可以引入到分类和聚类任务中。例如,DTCR 提出了一个假样本生成策略,以帮助编码器获得更有表现力的表示。
总结与展望
该文集中讨论时间序列自监督学习(SSL)方法,并提供了一个新的分类法。研究者们根据学习范式将现有方法分为三大类:基于生成的、基于对比的和基于对抗的。此外,研究者将所有方法整理成十个详细的子类别:基于自回归的预测、基于自编码器的重构、基于扩散的生成、采样对比、预测对比、增强对比、原型对比、专家知识对比、生成和填充,以及辅助表示增强。研究者还提供了关于应用和广泛使用的时间序列数据集的有用信息。最后,总结了多个未来的发展方向。我们相信,这篇综述填补了时间序列SSL的空白,并激发了对时间序列数据的SSL的进一步研究兴趣。
腾讯云开发者
