LLM入门5 | SAM代码从入门到出门 | MetaAI

LLM入门5 | SAM代码从入门到出门 | MetaAI

机器学习炼丹术
发布于 2023-09-02 13:54:59
发布于 2023-09-02 13:54:59
<<大型语言模型LLM与Visual>>
LLM入门3 | 基于cpu和hugging face的LLaMA部署
LLM入门4 | Segment Anything | MetaAI
- Segment Anything!
- official github:https://github.com/facebookresearch/segment-anything
- 论文:https://ai.facebook.com/research/publications/segment-anything/
- 文章转自微信公众号:机器学习炼丹术(已授权)
今天撸代码!视觉的代码果然比NLP的代码更好撸一些。
运行效果
# 读取照片
image = cv2.imread('images/dog.jpg')
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
# 展示照片
plt.figure(figsize=(20,20))
plt.imshow(image)
plt.axis('off')
plt.show()

官方提供了三个尺寸不同的SAM模型:
import sys
sys.path.append("..")
from segment_anything import sam_model_registry, SamAutomaticMaskGenerator, SamPredictor
sam = sam_model_registry[model_type](checkpoint=sam_checkpoint)
sam.to(device=device)
mask_generator = SamAutomaticMaskGenerator(sam)
非常好加载,基本上pytorch和torchvision版本不太落后就可以加载。里面的model_type需要和模型参数对应上,"vit_h"或者"vit_l"或者"vit_b",即便加载最大的2.4G的vit_h模型,也只需要占用8G的显卡。算是非常小的模型了。这里SAM测试的效果,很多情况下效果并不太好,是一个foundation model,我觉得主要原因是模型参数比较少。导致他不能很好的解决所有的问题。正确用法是对小领域最微调。
现在我们加载完数据,加载完模型。对图片进行预测:
masks = mask_generator.generate(image)
print(len(masks))
print(masks[0].keys())

说明上一张图片的预测结果当中,包含了44个mask,每一个mask又包含下面的参数:
segmentation: the maskarea: the area of the mask in pixelsbbox: the boundary box of the mask in XYWH formatpredicted_iou: the model's own prediction for the quality of the maskpoint_coords: the sampled input point that generated this maskstability_score: an additional measure of mask qualitycrop_box: the crop of the image used to generate this mask in XYWH format
plt.figure(figsize=(20,20))
plt.imshow(image)
# 这个函数就是给每个mask随机颜色
show_anns(masks)
plt.axis('off')
plt.show()
下面是两个运行的不同结果。


##3 剖析
3.1
- 先从sam_model_registry看起来
- 看完模型结构,看SamAutomaticMaskGenerator类就行了。
3.2 模型结构
sam_model_registry = {
"default": build_sam,
"vit_h": build_sam,
"vit_l": build_sam_vit_l,
"vit_b": build_sam_vit_b,
}
def build_sam_vit_h(checkpoint=None):
return _build_sam(
encoder_embed_dim=1280,
encoder_depth=32,
encoder_num_heads=16,
encoder_global_attn_indexes=[7, 15, 23, 31],
checkpoint=checkpoint,
)
build_sam = build_sam_vit_h
def build_sam_vit_l(checkpoint=None):
return _build_sam(
encoder_embed_dim=1024,
encoder_depth=24,
encoder_num_heads=16,
encoder_global_attn_indexes=[5, 11, 17, 23],
checkpoint=checkpoint,
)
def build_sam_vit_b(checkpoint=None):
return _build_sam(
encoder_embed_dim=768,
encoder_depth=12,
encoder_num_heads=12,
encoder_global_attn_indexes=[2, 5, 8, 11],
checkpoint=checkpoint,
)
这里的h,l和b我也不知道啥意思,可能是ViT当中的命名。b可能是base,l是large,h是huge?三个模型公用同一个模型结构,然后区别就在于:
encoder_embed_dim: embedding维度encoder_depth:编码器深度encoder_num_heads:多头注意力的头数encoder_global_attn_indexes=[7, 15, 23, 31]:不知道global attn是啥,难道是论文中提高的prompt和image之前的cross-attention数量?
不管怎么说,我们必须要看一下_build_sam方法:
3.3 build_sam
def _build_sam(
encoder_embed_dim,
encoder_depth,
encoder_num_heads,
encoder_global_attn_indexes,
checkpoint=None,
):
# prompt的embedding是256
prompt_embed_dim = 256
# 图片尺寸是1024x1024
image_size = 1024
# 把整张图片划分成16个patch
vit_patch_size = 16
# 所以每一个patch是64x64的大小
image_embedding_size = image_size // vit_patch_size
# 这里和论文说的一样,sam包含了三个模块,image-encoder,prompt-encoder和两个融合的mask-decoder
"""
SAM predicts object masks from an image and input prompts.
Arguments:
image_encoder (ImageEncoderViT): The backbone used to encode the
image into image embeddings that allow for efficient mask prediction.
prompt_encoder (PromptEncoder): Encodes various types of input prompts.
mask_decoder (MaskDecoder): Predicts masks from the image embeddings
and encoded prompts.
pixel_mean (list(float)): Mean values for normalizing pixels in the input image.
pixel_std (list(float)): Std values for normalizing pixels in the input image.
"""
sam = Sam(
image_encoder=ImageEncoderViT(
depth=encoder_depth,
embed_dim=encoder_embed_dim,
img_size=image_size,
mlp_ratio=4,
norm_layer=partial(torch.nn.LayerNorm, eps=1e-6),
num_heads=encoder_num_heads,
patch_size=vit_patch_size,
qkv_bias=True,
use_rel_pos=True,
global_attn_indexes=encoder_global_attn_indexes,
window_size=14,
out_chans=prompt_embed_dim,
),
prompt_encoder=PromptEncoder(
embed_dim=prompt_embed_dim,
image_embedding_size=(image_embedding_size, image_embedding_size),
input_image_size=(image_size, image_size),
mask_in_chans=16,
),
mask_decoder=MaskDecoder(
num_multimask_outputs=3,
transformer=TwoWayTransformer(
depth=2,
embedding_dim=prompt_embed_dim,
mlp_dim=2048,
num_heads=8,
),
transformer_dim=prompt_embed_dim,
iou_head_depth=3,
iou_head_hidden_dim=256,
),
pixel_mean=[123.675, 116.28, 103.53],
pixel_std=[58.395, 57.12, 57.375],
)
sam.eval()
if checkpoint is not None:
with open(checkpoint, "rb") as f:
state_dict = torch.load(f)
sam.load_state_dict(state_dict)
return sam
3.3 SAM
class Sam(nn.Module):
mask_threshold: float = 0.0
image_format: str = "RGB"
def __init__(
self,
image_encoder: ImageEncoderViT,
prompt_encoder: PromptEncoder,
mask_decoder: MaskDecoder,
pixel_mean: List[float] = [123.675, 116.28, 103.53],
pixel_std: List[float] = [58.395, 57.12, 57.375],
) -> None:
super().__init__()
self.image_encoder = image_encoder
self.prompt_encoder = prompt_encoder
self.mask_decoder = mask_decoder
self.register_buffer("pixel_mean", torch.Tensor(pixel_mean).view(-1, 1, 1), False)
self.register_buffer("pixel_std", torch.Tensor(pixel_std).view(-1, 1, 1), False)
@property
def device(self) -> Any:
return self.pixel_mean.device
@torch.no_grad()
def forward(
self,
batched_input: List[Dict[str, Any]],
multimask_output: bool,
) -> List[Dict[str, torch.Tensor]]:
"""
Predicts masks end-to-end from provided images and prompts.
If prompts are not known in advance, using SamPredictor is
recommended over calling the model directly.
Arguments:
batched_input (list(dict)): A list over input images, each a
dictionary with the following keys. A prompt key can be
excluded if it is not present.
'image': The image as a torch tensor in 3xHxW format,
already transformed for input to the model.
'original_size': (tuple(int, int)) The original size of
the image before transformation, as (H, W).
'point_coords': (torch.Tensor) Batched point prompts for
this image, with shape BxNx2. Already transformed to the
input frame of the model.
'point_labels': (torch.Tensor) Batched labels for point prompts,
with shape BxN.
'boxes': (torch.Tensor) Batched box inputs, with shape Bx4.
Already transformed to the input frame of the model.
'mask_inputs': (torch.Tensor) Batched mask inputs to the model,
in the form Bx1xHxW.
multimask_output (bool): Whether the model should predict multiple
disambiguating masks, or return a single mask.
Returns:
(list(dict)): A list over input images, where each element is
as dictionary with the following keys.
'masks': (torch.Tensor) Batched binary mask predictions,
with shape BxCxHxW, where B is the number of input promts,
C is determiend by multimask_output, and (H, W) is the
original size of the image.
'iou_predictions': (torch.Tensor) The model's predictions
of mask quality, in shape BxC.
'low_res_logits': (torch.Tensor) Low resolution logits with
shape BxCxHxW, where H=W=256. Can be passed as mask input
to subsequent iterations of prediction.
"""
# 对图像做预处理,然后推叠成B,C,W,H的形状
# 使用image_encoder对图像进行编码
input_images = torch.stack([self.preprocess(x["image"]) for x in batched_input], dim=0)
image_embeddings = self.image_encoder(input_images)
outputs = []
for image_record, curr_embedding in zip(batched_input, image_embeddings):
if "point_coords" in image_record:
points = (image_record["point_coords"], image_record["point_labels"])
else:
points = None
sparse_embeddings, dense_embeddings = self.prompt_encoder(
points=points,
boxes=image_record.get("boxes", None),
masks=image_record.get("mask_inputs", None),
)
low_res_masks, iou_predictions = self.mask_decoder(
image_embeddings=curr_embedding.unsqueeze(0),
image_pe=self.prompt_encoder.get_dense_pe(),
sparse_prompt_embeddings=sparse_embeddings,
dense_prompt_embeddings=dense_embeddings,
multimask_output=multimask_output,
)
masks = self.postprocess_masks(
low_res_masks,
input_size=image_record["image"].shape[-2:],
original_size=image_record["original_size"],
)
masks = masks > self.mask_threshold
outputs.append(
{
"masks": masks,
"iou_predictions": iou_predictions,
"low_res_logits": low_res_masks,
}
)
return outputs
def postprocess_masks(
self,
masks: torch.Tensor,
input_size: Tuple[int, ...],
original_size: Tuple[int, ...],
) -> torch.Tensor:
"""
Remove padding and upscale masks to the original image size.
Arguments:
masks (torch.Tensor): Batched masks from the mask_decoder,
in BxCxHxW format.
input_size (tuple(int, int)): The size of the image input to the
model, in (H, W) format. Used to remove padding.
original_size (tuple(int, int)): The original size of the image
before resizing for input to the model, in (H, W) format.
Returns:
(torch.Tensor): Batched masks in BxCxHxW format, where (H, W)
is given by original_size.
"""
masks = F.interpolate(
masks,
(self.image_encoder.img_size, self.image_encoder.img_size),
mode="bilinear",
align_corners=False,
)
masks = masks[..., : input_size[0], : input_size[1]]
masks = F.interpolate(masks, original_size, mode="bilinear", align_corners=False)
return masks
def preprocess(self, x: torch.Tensor) -> torch.Tensor:
"""Normalize pixel values and pad to a square input."""
# Normalize colors
# 自然图像imagenet的归一化
x = (x - self.pixel_mean) / self.pixel_std
# Pad
# 是否需要pad
h, w = x.shape[-2:]
padh = self.image_encoder.img_size - h
padw = self.image_encoder.img_size - w
x = F.pad(x, (0, padw, 0, padh))
return x
3.4 ImageEncoderViT
比较长的代码,有时候觉得最好是用视频的方式来记录会更好。
import torch
import torch.nn as nn
import torch.nn.functional as F
from typing import Optional, Tuple, Type
from .common import LayerNorm2d, MLPBlock
# This class and its supporting functions below lightly adapted from the ViTDet backbone available at: https://github.com/facebookresearch/detectron2/blob/main/detectron2/modeling/backbone/vit.py # noqa
class ImageEncoderViT(nn.Module):
def __init__(
self,
img_size: int = 1024,
patch_size: int = 16,
in_chans: int = 3,
embed_dim: int = 768,
depth: int = 12,
num_heads: int = 12,
mlp_ratio: float = 4.0,
out_chans: int = 256,
qkv_bias: bool = True,
norm_layer: Type[nn.Module] = nn.LayerNorm,
act_layer: Type[nn.Module] = nn.GELU,
use_abs_pos: bool = True,
use_rel_pos: bool = False,
rel_pos_zero_init: bool = True,
window_size: int = 0,
global_attn_indexes: Tuple[int, ...] = (),
) -> None:
"""
Args:
img_size (int): Input image size.
patch_size (int): Patch size.
in_chans (int): Number of input image channels.
embed_dim (int): Patch embedding dimension.
depth (int): Depth of ViT.
num_heads (int): Number of attention heads in each ViT block.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool): If True, add a learnable bias to query, key, value.
norm_layer (nn.Module): Normalization layer.
act_layer (nn.Module): Activation layer.
use_abs_pos (bool): If True, use absolute positional embeddings.
use_rel_pos (bool): If True, add relative positional embeddings to the attention map.
rel_pos_zero_init (bool): If True, zero initialize relative positional parameters.
window_size (int): Window size for window attention blocks.
global_attn_indexes (list): Indexes for blocks using global attention.
"""
super().__init__()
self.img_size = img_size
# 这是一种划分patch的方法
self.patch_embed = PatchEmbed(
kernel_size=(patch_size, patch_size),
stride=(patch_size, patch_size),
in_chans=in_chans,
embed_dim=embed_dim,
)
self.pos_embed: Optional[nn.Parameter] = None
# 这个pos_embedding是可训练的?并且每一个embedding都有吗?
if use_abs_pos:
# Initialize absolute positional embedding with pretrain image size.
self.pos_embed = nn.Parameter(
torch.zeros(1, img_size // patch_size, img_size // patch_size, embed_dim)
)
self.blocks = nn.ModuleList()
for i in range(depth):
# 每一个block,里面包含了多头注意力,还有全连接层等等
block = Block(
dim=embed_dim,
num_heads=num_heads,
mlp_ratio=mlp_ratio,
qkv_bias=qkv_bias,
norm_layer=norm_layer,
act_layer=act_layer,
use_rel_pos=use_rel_pos,
rel_pos_zero_init=rel_pos_zero_init,
window_size=window_size if i not in global_attn_indexes else 0,
input_size=(img_size // patch_size, img_size // patch_size),
)
self.blocks.append(block)
# 就是输出层了,这里的out_channs就是为了和prompt_embedding维度对齐,变成256
self.neck = nn.Sequential(
nn.Conv2d(
embed_dim,
out_chans,
kernel_size=1,
bias=False,
),
LayerNorm2d(out_chans),
nn.Conv2d(
out_chans,
out_chans,
kernel_size=3,
padding=1,
bias=False,
),
LayerNorm2d(out_chans),
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.patch_embed(x)
if self.pos_embed is not None:
x = x + self.pos_embed
for blk in self.blocks:
x = blk(x)
x = self.neck(x.permute(0, 3, 1, 2))
return x
class Block(nn.Module):
"""Transformer blocks with support of window attention and residual propagation blocks"""
def __init__(
self,
dim: int,
num_heads: int,
mlp_ratio: float = 4.0,
qkv_bias: bool = True,
norm_layer: Type[nn.Module] = nn.LayerNorm,
act_layer: Type[nn.Module] = nn.GELU,
use_rel_pos: bool = False,
rel_pos_zero_init: bool = True,
window_size: int = 0,
input_size: Optional[Tuple[int, int]] = None,
) -> None:
"""
Args:
dim (int): Number of input channels.
num_heads (int): Number of attention heads in each ViT block.
mlp_ratio (float): Ratio of mlp hidden dim to embedding dim.
qkv_bias (bool): If True, add a learnable bias to query, key, value.
norm_layer (nn.Module): Normalization layer.
act_layer (nn.Module): Activation layer.
use_rel_pos (bool): If True, add relative positional embeddings to the attention map.
rel_pos_zero_init (bool): If True, zero initialize relative positional parameters.
window_size (int): Window size for window attention blocks. If it equals 0, then
use global attention.
input_size (int or None): Input resolution for calculating the relative positional
parameter size.
"""
super().__init__()
# 归一化曾选择layer norm
self.norm1 = norm_layer(dim)
# attentionmo模块
self.attn = Attention(
dim,
num_heads=num_heads,
qkv_bias=qkv_bias,
use_rel_pos=use_rel_pos,
rel_pos_zero_init=rel_pos_zero_init,
input_size=input_size if window_size == 0 else (window_size, window_size),
)
# 第二个归一化层
self.norm2 = norm_layer(dim)
self.mlp = MLPBlock(embedding_dim=dim, mlp_dim=int(dim * mlp_ratio), act=act_layer)
self.window_size = window_size
def forward(self, x: torch.Tensor) -> torch.Tensor:
shortcut = x
x = self.norm1(x)
# Window partition
# 这个比较关键,解释了之前的问题:window_size=window_size if i not in global_attn_indexes else 0
# sam的window_size设置成了14
# 当block的数量不在global_attn_indexes的时候,windows_size=14,否则就是0
if self.window_size > 0:
H, W = x.shape[1], x.shape[2]
x, pad_hw = window_partition(x, self.window_size)
# 所以这里的attention是在
x = self.attn(x)
# Reverse window partition
if self.window_size > 0:
x = window_unpartition(x, self.window_size, pad_hw, (H, W))
# 两个残差
x = shortcut + x
x = x + self.mlp(self.norm2(x))
return x
class Attention(nn.Module):
"""Multi-head Attention block with relative position embeddings."""
def __init__(
self,
dim: int,
num_heads: int = 8,
qkv_bias: bool = True,
use_rel_pos: bool = False,
rel_pos_zero_init: bool = True,
input_size: Optional[Tuple[int, int]] = None,
) -> None:
"""
Args:
dim (int): Number of input channels.
num_heads (int): Number of attention heads.
qkv_bias (bool: If True, add a learnable bias to query, key, value.
rel_pos (bool): If True, add relative positional embeddings to the attention map.
rel_pos_zero_init (bool): If True, zero initialize relative positional parameters.
input_size (int or None): Input resolution for calculating the relative positional
parameter size.
"""
super().__init__()
self.num_heads = num_heads
head_dim = dim // num_heads
self.scale = head_dim**-0.5
self.qkv = nn.Linear(dim, dim * 3, bias=qkv_bias)
self.proj = nn.Linear(dim, dim)
self.use_rel_pos = use_rel_pos
if self.use_rel_pos:
assert (
input_size is not None
), "Input size must be provided if using relative positional encoding."
# initialize relative positional embeddings
self.rel_pos_h = nn.Parameter(torch.zeros(2 * input_size[0] - 1, head_dim))
self.rel_pos_w = nn.Parameter(torch.zeros(2 * input_size[1] - 1, head_dim))
def forward(self, x: torch.Tensor) -> torch.Tensor:
B, H, W, _ = x.shape
# qkv with shape (3, B, nHead, H * W, C)
qkv = self.qkv(x).reshape(B, H * W, 3, self.num_heads, -1).permute(2, 0, 3, 1, 4)
# q, k, v with shape (B * nHead, H * W, C)
# 因为之前做了那个window partition,导致这里的H和W从原来的64x64变成了14x14,
# 这里的14其实是对64做了一个采样得到的。
q, k, v = qkv.reshape(3, B * self.num_heads, H * W, -1).unbind(0)
attn = (q * self.scale) @ k.transpose(-2, -1)
# 跳过
if self.use_rel_pos:
attn = add_decomposed_rel_pos(attn, q, self.rel_pos_h, self.rel_pos_w, (H, W), (H, W))
attn = attn.softmax(dim=-1)
x = (attn @ v).view(B, self.num_heads, H, W, -1).permute(0, 2, 3, 1, 4).reshape(B, H, W, -1)
x = self.proj(x)
return x
def window_partition(x: torch.Tensor, window_size: int) -> Tuple[torch.Tensor, Tuple[int, int]]:
"""
Partition into non-overlapping windows with padding if needed.
Args:
x (tensor): input tokens with [B, H, W, C].
window_size (int): window size.
Returns:
windows: windows after partition with [B * num_windows, window_size, window_size, C].
(Hp, Wp): padded height and width before partition
本来是Bx64x64的尺寸,经过变换后变成了Bx25,14,14,C的尺寸
"""
B, H, W, C = x.shape
# 这里的W和H表示64,given image size=1024 and patch_size=16
# (14-64%14)%14=6?
pad_h = (window_size - H % window_size) % window_size
pad_w = (window_size - W % window_size) % window_size
if pad_h > 0 or pad_w > 0:
x = F.pad(x, (0, 0, 0, pad_w, 0, pad_h))
# Hp和Wp都是70,
Hp, Wp = H + pad_h, W + pad_w
# Hp // window_size=5
#B,5, 14, 5, 14, C
x = x.view(B, Hp // window_size, window_size, Wp // window_size, window_size, C)
#B,5, 5 14,, 14, C
windows = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(-1, window_size, window_size, C)
return windows, (Hp, Wp)
def window_unpartition(
windows: torch.Tensor, window_size: int, pad_hw: Tuple[int, int], hw: Tuple[int, int]
) -> torch.Tensor:
"""
Window unpartition into original sequences and removing padding.
Args:
x (tensor): input tokens with [B * num_windows, window_size, window_size, C].
window_size (int): window size.
pad_hw (Tuple): padded height and width (Hp, Wp).
hw (Tuple): original height and width (H, W) before padding.
Returns:
x: unpartitioned sequences with [B, H, W, C].
"""
Hp, Wp = pad_hw
H, W = hw
B = windows.shape[0] // (Hp * Wp // window_size // window_size)
x = windows.view(B, Hp // window_size, Wp // window_size, window_size, window_size, -1)
x = x.permute(0, 1, 3, 2, 4, 5).contiguous().view(B, Hp, Wp, -1)
if Hp > H or Wp > W:
x = x[:, :H, :W, :].contiguous()
return x
class PatchEmbed(nn.Module):
"""
Image to Patch Embedding.
"""
def __init__(
self,
kernel_size: Tuple[int, int] = (16, 16),
stride: Tuple[int, int] = (16, 16),
padding: Tuple[int, int] = (0, 0),
in_chans: int = 3,
embed_dim: int = 768,
) -> None:
"""
Args:
kernel_size (Tuple): kernel size of the projection layer.
stride (Tuple): stride of the projection layer.
padding (Tuple): padding size of the projection layer.
in_chans (int): Number of input image channels.
embed_dim (int): embed_dim (int): Patch embedding dimension.
"""
super().__init__()
self.proj = nn.Conv2d(
in_chans, embed_dim, kernel_size=kernel_size, stride=stride, padding=padding
)
def forward(self, x: torch.Tensor) -> torch.Tensor:
x = self.proj(x)
# B C H W -> B H W C
x = x.permute(0, 2, 3, 1)
return x
3.5 PromptEncoder
一个现成的辅助标注逻辑与代码!
- point的编码就是:一个点先用高斯核做卷积,然后用sin和cos做位置编码的,然后positive point加上一个位置编码A,negativepoint加上另一个编码B
- box是和point是一样的逻辑,一个点先用高斯核做卷积,然后用sin和cos做位置编码的,最后两个corner是加上位置编码C和D。所以总共设置了四个位置编码(4个embedding的参数)
- 如果输入的是mask,那么就是对mask做下采样的卷积,1到4,4到16,16到256通道。如果没有mask,那么就是有一个no-mask-embed的编码
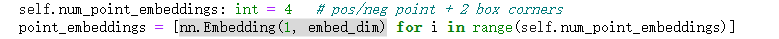
# Copyright (c) Meta Platforms, Inc. and affiliates.
# All rights reserved.
# This source code is licensed under the license found in the
# LICENSE file in the root directory of this source tree.
import numpy as np
import torch
from torch import nn
from typing import Any, Optional, Tuple, Type
from .common import LayerNorm2d
class PromptEncoder(nn.Module):
def __init__(
self,
embed_dim: int,
image_embedding_size: Tuple[int, int],
input_image_size: Tuple[int, int],
mask_in_chans: int,
activation: Type[nn.Module] = nn.GELU,
) -> None:
"""
Encodes prompts for input to SAM's mask decoder.
Arguments:
embed_dim (int): The prompts' embedding dimension
image_embedding_size (tuple(int, int)): The spatial size of the
image embedding, as (H, W).
input_image_size (int): The padded size of the image as input
to the image encoder, as (H, W).
mask_in_chans (int): The number of hidden channels used for
encoding input masks.
activation (nn.Module): The activation to use when encoding
input masks.
"""
super().__init__()
self.embed_dim = embed_dim
self.input_image_size = input_image_size
self.image_embedding_size = image_embedding_size
self.pe_layer = PositionEmbeddingRandom(embed_dim // 2)
self.num_point_embeddings: int = 4 # pos/neg point + 2 box corners
point_embeddings = [nn.Embedding(1, embed_dim) for i in range(self.num_point_embeddings)]
self.point_embeddings = nn.ModuleList(point_embeddings)
self.not_a_point_embed = nn.Embedding(1, embed_dim)
self.mask_input_size = (4 * image_embedding_size[0], 4 * image_embedding_size[1])
self.mask_downscaling = nn.Sequential(
nn.Conv2d(1, mask_in_chans // 4, kernel_size=2, stride=2),
LayerNorm2d(mask_in_chans // 4),
activation(),
nn.Conv2d(mask_in_chans // 4, mask_in_chans, kernel_size=2, stride=2),
LayerNorm2d(mask_in_chans),
activation(),
nn.Conv2d(mask_in_chans, embed_dim, kernel_size=1),
)
self.no_mask_embed = nn.Embedding(1, embed_dim)
def get_dense_pe(self) -> torch.Tensor:
"""
Returns the positional encoding used to encode point prompts,
applied to a dense set of points the shape of the image encoding.
Returns:
torch.Tensor: Positional encoding with shape
1x(embed_dim)x(embedding_h)x(embedding_w)
"""
return self.pe_layer(self.image_embedding_size).unsqueeze(0)
def _embed_points(
self,
points: torch.Tensor,
labels: torch.Tensor,
pad: bool,
) -> torch.Tensor:
"""Embeds point prompts."""
points = points + 0.5 # Shift to center of pixel
if pad:
padding_point = torch.zeros((points.shape[0], 1, 2), device=points.device)
padding_label = -torch.ones((labels.shape[0], 1), device=labels.device)
points = torch.cat([points, padding_point], dim=1)
labels = torch.cat([labels, padding_label], dim=1)
point_embedding = self.pe_layer.forward_with_coords(points, self.input_image_size)
point_embedding[labels == -1] = 0.0
point_embedding[labels == -1] += self.not_a_point_embed.weight
point_embedding[labels == 0] += self.point_embeddings[0].weight
point_embedding[labels == 1] += self.point_embeddings[1].weight
return point_embedding
def _embed_boxes(self, boxes: torch.Tensor) -> torch.Tensor:
"""Embeds box prompts."""
boxes = boxes + 0.5 # Shift to center of pixel
coords = boxes.reshape(-1, 2, 2)
corner_embedding = self.pe_layer.forward_with_coords(coords, self.input_image_size)
corner_embedding[:, 0, :] += self.point_embeddings[2].weight
corner_embedding[:, 1, :] += self.point_embeddings[3].weight
return corner_embedding
def _embed_masks(self, masks: torch.Tensor) -> torch.Tensor:
"""Embeds mask inputs."""
mask_embedding = self.mask_downscaling(masks)
return mask_embedding
def _get_batch_size(
self,
points: Optional[Tuple[torch.Tensor, torch.Tensor]],
boxes: Optional[torch.Tensor],
masks: Optional[torch.Tensor],
) -> int:
"""
Gets the batch size of the output given the batch size of the input prompts.
"""
if points is not None:
return points[0].shape[0]
elif boxes is not None:
return boxes.shape[0]
elif masks is not None:
return masks.shape[0]
else:
return 1
def _get_device(self) -> torch.device:
return self.point_embeddings[0].weight.device
def forward(
self,
points: Optional[Tuple[torch.Tensor, torch.Tensor]],
boxes: Optional[torch.Tensor],
masks: Optional[torch.Tensor],
) -> Tuple[torch.Tensor, torch.Tensor]:
"""
Embeds different types of prompts, returning both sparse and dense
embeddings.
Arguments:
points (tuple(torch.Tensor, torch.Tensor) or none): point coordinates
and labels to embed.
boxes (torch.Tensor or none): boxes to embed
masks (torch.Tensor or none): masks to embed
Returns:
torch.Tensor: sparse embeddings for the points and boxes, with shape
BxNx(embed_dim), where N is determined by the number of input points
and boxes.
torch.Tensor: dense embeddings for the masks, in the shape
Bx(embed_dim)x(embed_H)x(embed_W)
"""
bs = self._get_batch_size(points, boxes, masks)
sparse_embeddings = torch.empty((bs, 0, self.embed_dim), device=self._get_device())
if points is not None:
coords, labels = points
# coords就是坐标,labels就是正样本还是负样本
point_embeddings = self._embed_points(coords, labels, pad=(boxes is None))
sparse_embeddings = torch.cat([sparse_embeddings, point_embeddings], dim=1)
if boxes is not None:
box_embeddings = self._embed_boxes(boxes)
sparse_embeddings = torch.cat([sparse_embeddings, box_embeddings], dim=1)
if masks is not None:
dense_embeddings = self._embed_masks(masks)
else:
dense_embeddings = self.no_mask_embed.weight.reshape(1, -1, 1, 1).expand(
bs, -1, self.image_embedding_size[0], self.image_embedding_size[1]
)
return sparse_embeddings, dense_embeddings
class PositionEmbeddingRandom(nn.Module):
"""
Positional encoding using random spatial frequencies.
"""
def __init__(self, num_pos_feats: int = 64, scale: Optional[float] = None) -> None:
super().__init__()
if scale is None or scale <= 0.0:
scale = 1.0
self.register_buffer(
"positional_encoding_gaussian_matrix",
scale * torch.randn((2, num_pos_feats)),
)
def _pe_encoding(self, coords: torch.Tensor) -> torch.Tensor:
"""Positionally encode points that are normalized to [0,1]."""
# assuming coords are in [0, 1]^2 square and have d_1 x ... x d_n x 2 shape
coords = 2 * coords - 1
coords = coords @ self.positional_encoding_gaussian_matrix
coords = 2 * np.pi * coords
# outputs d_1 x ... x d_n x C shape
return torch.cat([torch.sin(coords), torch.cos(coords)], dim=-1)
def forward(self, size: Tuple[int, int]) -> torch.Tensor:
"""Generate positional encoding for a grid of the specified size."""
h, w = size
device: Any = self.positional_encoding_gaussian_matrix.device
grid = torch.ones((h, w), device=device, dtype=torch.float32)
y_embed = grid.cumsum(dim=0) - 0.5
x_embed = grid.cumsum(dim=1) - 0.5
y_embed = y_embed / h
x_embed = x_embed / w
pe = self._pe_encoding(torch.stack([x_embed, y_embed], dim=-1))
return pe.permute(2, 0, 1) # C x H x W
def forward_with_coords(
self, coords_input: torch.Tensor, image_size: Tuple[int, int]
) -> torch.Tensor:
"""Positionally encode points that are not normalized to [0,1]."""
coords = coords_input.clone()
coords[:, :, 0] = coords[:, :, 0] / image_size[1]
coords[:, :, 1] = coords[:, :, 1] / image_size[0]
return self._pe_encoding(coords.to(torch.float)) # B x N x C
3.6 MaskDecoder
这一块我有点蒙了,光看代码有点绕不过来了。之后做项目的时候在解析把。。
import torch
from torch import nn
from torch.nn import functional as F
from typing import List, Tuple, Type
from .common import LayerNorm2d
class MaskDecoder(nn.Module):
def __init__(
self,
*,
transformer_dim: int,
transformer: nn.Module,
num_multimask_outputs: int = 3,
activation: Type[nn.Module] = nn.GELU,
iou_head_depth: int = 3,
iou_head_hidden_dim: int = 256,
) -> None:
"""
Predicts masks given an image and prompt embeddings, using a
tranformer architecture.
Arguments:
transformer_dim (int): the channel dimension of the transformer
transformer (nn.Module): the transformer used to predict masks
num_multimask_outputs (int): the number of masks to predict
when disambiguating masks
activation (nn.Module): the type of activation to use when
upscaling masks
iou_head_depth (int): the depth of the MLP used to predict
mask quality
iou_head_hidden_dim (int): the hidden dimension of the MLP
used to predict mask quality
"""
super().__init__()
self.transformer_dim = transformer_dim
self.transformer = transformer
self.num_multimask_outputs = num_multimask_outputs
self.iou_token = nn.Embedding(1, transformer_dim)
self.num_mask_tokens = num_multimask_outputs + 1
self.mask_tokens = nn.Embedding(self.num_mask_tokens, transformer_dim)
self.output_upscaling = nn.Sequential(
nn.ConvTranspose2d(transformer_dim, transformer_dim // 4, kernel_size=2, stride=2),
LayerNorm2d(transformer_dim // 4),
activation(),
nn.ConvTranspose2d(transformer_dim // 4, transformer_dim // 8, kernel_size=2, stride=2),
activation(),
)
self.output_hypernetworks_mlps = nn.ModuleList(
[
MLP(transformer_dim, transformer_dim, transformer_dim // 8, 3)
for i in range(self.num_mask_tokens)
]
)
self.iou_prediction_head = MLP(
transformer_dim, iou_head_hidden_dim, self.num_mask_tokens, iou_head_depth
)
def forward(
self,
image_embeddings: torch.Tensor,
image_pe: torch.Tensor,
sparse_prompt_embeddings: torch.Tensor,
dense_prompt_embeddings: torch.Tensor,
multimask_output: bool,
) -> Tuple[torch.Tensor, torch.Tensor]:
"""
Predict masks given image and prompt embeddings.
Arguments:
image_embeddings (torch.Tensor): the embeddings from the image encoder
image_pe (torch.Tensor): positional encoding with the shape of image_embeddings
sparse_prompt_embeddings (torch.Tensor): the embeddings of the points and boxes
dense_prompt_embeddings (torch.Tensor): the embeddings of the mask inputs
multimask_output (bool): Whether to return multiple masks or a single
mask.
Returns:
torch.Tensor: batched predicted masks
torch.Tensor: batched predictions of mask quality
"""
masks, iou_pred = self.predict_masks(
image_embeddings=image_embeddings,
image_pe=image_pe,
sparse_prompt_embeddings=sparse_prompt_embeddings,
dense_prompt_embeddings=dense_prompt_embeddings,
)
# Select the correct mask or masks for outptu
if multimask_output:
mask_slice = slice(1, None)
else:
mask_slice = slice(0, 1)
masks = masks[:, mask_slice, :, :]
iou_pred = iou_pred[:, mask_slice]
# Prepare output
return masks, iou_pred
def predict_masks(
self,
image_embeddings: torch.Tensor,
image_pe: torch.Tensor,
sparse_prompt_embeddings: torch.Tensor,
dense_prompt_embeddings: torch.Tensor,
) -> Tuple[torch.Tensor, torch.Tensor]:
"""Predicts masks. See 'forward' for more details."""
# Concatenate output tokens
output_tokens = torch.cat([self.iou_token.weight, self.mask_tokens.weight], dim=0)
output_tokens = output_tokens.unsqueeze(0).expand(sparse_prompt_embeddings.size(0), -1, -1)
tokens = torch.cat((output_tokens, sparse_prompt_embeddings), dim=1)
# Expand per-image data in batch direction to be per-mask
src = torch.repeat_interleave(image_embeddings, tokens.shape[0], dim=0)
src = src + dense_prompt_embeddings
pos_src = torch.repeat_interleave(image_pe, tokens.shape[0], dim=0)
b, c, h, w = src.shape
# Run the transformer
hs, src = self.transformer(src, pos_src, tokens)
iou_token_out = hs[:, 0, :]
mask_tokens_out = hs[:, 1 : (1 + self.num_mask_tokens), :]
# Upscale mask embeddings and predict masks using the mask tokens
src = src.transpose(1, 2).view(b, c, h, w)
upscaled_embedding = self.output_upscaling(src)
hyper_in_list: List[torch.Tensor] = []
for i in range(self.num_mask_tokens):
hyper_in_list.append(self.output_hypernetworks_mlps[i](mask_tokens_out[:, i, :]))
hyper_in = torch.stack(hyper_in_list, dim=1)
b, c, h, w = upscaled_embedding.shape
masks = (hyper_in @ upscaled_embedding.view(b, c, h * w)).view(b, -1, h, w)
# Generate mask quality predictions
iou_pred = self.iou_prediction_head(iou_token_out)
return masks, iou_pred
# Lightly adapted from
# https://github.com/facebookresearch/MaskFormer/blob/main/mask_former/modeling/transformer/transformer_predictor.py # noqa
class MLP(nn.Module):
def __init__(
self,
input_dim: int,
hidden_dim: int,
output_dim: int,
num_layers: int,
sigmoid_output: bool = False,
) -> None:
super().__init__()
self.num_layers = num_layers
h = [hidden_dim] * (num_layers - 1)
self.layers = nn.ModuleList(
nn.Linear(n, k) for n, k in zip([input_dim] + h, h + [output_dim])
)
self.sigmoid_output = sigmoid_output
def forward(self, x):
for i, layer in enumerate(self.layers):
x = F.relu(layer(x)) if i < self.num_layers - 1 else layer(x)
if self.sigmoid_output:
x = F.sigmoid(x)
return x
<<其他>>
医学图像重建 | Radon变换,滤波反投影算法,中心切片定理
功能连接矩阵 | 双向LSTM深度时间组学习针对轻度认知障碍
ICA | 用RNN-ICA探索功能核磁内在网络模型的时空动力学
WBIR | DeepSTAPLE:UDA任务下学习多模态配准质量
<<AlphaFold2专题>>
alphaFold2 | 模型细节之Evoformer(四)
alphaFold2 | 补充Evoformer之outer productor mean(五)
<<StyleGAN2专题>>
生成专题1 | 图像生成评价指标 Inception Score (IS)
<<蛋白质分子结构相关>>
NLP | 简单学习一下NLP中的transformer的pytorch代码
DTI特征工程 | iDTI-ESBoost | 2017 | REP
DTI | Drug-target interaction基础认识
<<CVPR目录>>
第一弹CVPR 2021 | 多分辨率蒸馏的异常检测 VIT Vision Transformer | 先从PyTorch代码了解
preprint版本 | 何凯明大神新作MAE | CVPR2022最佳论文候选
简单的结构 | MLP-Mixer: An all-MLP Architecture for Vision | CVPR2021
域迁移DA |Addressing Domain Shift for Segmentation | CVPR2018
医学图像配准 | SYMnet 对称微分同胚配准CNN(SOTA) | CVPR2020
光流 | flownet | CVPR2015 | 论文+pytorch代码
图像分割 | Context Prior CPNet | CVPR2020
自监督图像论文复现 | BYOL(pytorch)| 2020
自监督SOTA框架 | BYOL(优雅而简洁) | 2020
笔记 | 吴恩达新书《Machine Learning Yearning》
图片质量评估论文 | 无监督SER-FIQ | CVPR2020
图像质量评估论文 | Deep-IQA | IEEETIP2018
图像质量评估论文 | rank-IQA | ICCV2017
注意力论文解读(1) | Non-local Neural Network | CVPR2018 | 已复现
卷积网络可解释性复现 | Grad-CAM | ICCV | 2017
轮廓检测论文解读 | Richer Convolutional Features| CVPR | 2017
轮廓检测论文解读 | 整体嵌套边缘检测HED | CVPR | 2015
卷积涨点论文复现 | Asymmetric Conv ACNet | ICCV | 2019
pytorch实现 | Deformable ConvNet 可变卷积(下) | CVPR | 2017
图像处理论文详解 | Deformable Convolutional Networks (上)| CVPR | 2017
<<小白学PyTorch>>
扩展之Tensorflow2.0 | 21 Keras的API详解(下)池化、Normalization层
扩展之Tensorflow2.0 | 21 Keras的API详解(上)卷积、激活、初始化、正则
扩展之Tensorflow2.0 | 20 TF2的eager模式与求导
扩展之Tensorflow2.0 | 19 TF2模型的存储与载入
扩展之Tensorflow2.0 | 18 TF2构建自定义模型
扩展之Tensorflow2.0 | 17 TFrec文件的创建与读取
扩展之Tensorflow2.0 | 16 TF2读取图片的方法
扩展之Tensorflow2.0 | 15 TF2实现一个简单的服装分类任务
小白学PyTorch | 14 tensorboardX可视化教程
小白学PyTorch | 13 EfficientNet详解及PyTorch实现
小白学PyTorch | 12 SENet详解及PyTorch实现
小白学PyTorch | 11 MobileNet详解及PyTorch实现
小白学PyTorch | 9 tensor数据结构与存储结构
小白学PyTorch | 7 最新版本torchvision.transforms常用API翻译与讲解
小白学PyTorch | 6 模型的构建访问遍历存储(附代码)
小白学PyTorch | 5 torchvision预训练模型与数据集全览
小白学PyTorch | 3 浅谈Dataset和Dataloader
<<小样本分割>>
<<图网络>>
图网络 | Graph Attention Networks | ICLR 2018 | 代码讲解
<<图像质量评估>>
图片质量评估论文 | 无监督SER-FIQ | CVPR2020
图像质量评估论文 | Deep-IQA | IEEETIP2018
图像质量评估论文 | rank-IQA | ICCV2017
<<图像轮廓检测>>
轮廓检测论文解读 | Richer Convolutional Features| CVPR | 2017
轮廓检测论文解读 | 整体嵌套边缘检测HED | CVPR | 2015
<<光流与配准>>
医学图像配准 | SYMnet 对称微分同胚配准CNN(SOTA) | CVPR2020
光流 | flownet | CVPR2015 | 论文+pytorch代码
医学图像配准 | Voxelmorph 微分同胚 | MICCAI2019
<<DA域迁移>>
域迁移DA |Addressing Domain Shift for Segmentation | CVPR2018
self-training | 域迁移 | source-free的域迁移(第一篇)
self-training | MICCAI2021 | BN层的source free的迁移
<<医学图像AI>>
医学图像 | DualGAN与儿科超声心动图分割 | MICCA
医学AI论文解读 | 超声心动图在临床中的自动化检测 | Circulation | 2018 | 中英双语
<<小白学图像(网络结构)>>
卷积网络可解释性复现 | Grad-CAM | ICCV | 2017
孪生网络入门(下) Siamese Net分类服装MNIST数据集(pytorch)
3D卷积入门 | 多论文笔记 | R2D C3D P3D MCx R(2+1)D
小白学目标检测 | RCNN, SPPNet, Fast, Faster
小白学图像 | BatchNormalization详解与比较
小白学图像 | Group Normalization详解+PyTorch代码
<<小白学机器学习>>
小白学SVM | SVM优化推导 + 拉格朗日 + hingeLoss
小白学LGB | LightGBM = GOSS + histogram + EFB
机器学习不得不知道的提升技巧:SWA与pseudo-label
五分钟理解:BCELoss 和 BCEWithLogitsLoss的区别
<<小白面经>>
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-04-08,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号