PostgreSQL 如果想知道表中某个条件查询条件在索引中效率 ?

PostgreSQL 如果想知道表中某个条件查询条件在索引中效率 ?

AustinDatabases
发布于 2023-09-18 15:26:28
发布于 2023-09-18 15:26:28
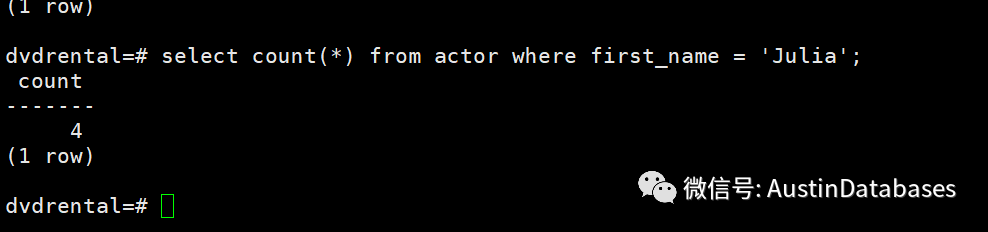
能力是什么,拥有985,211的学历证明,还是钻研各种技术,艺术后,获得的技术专家,或艺术家的title, 或许都不是,能力是变化的,能力是指你能满足他人需求,能提供的一种实力,而我们在这个社会,往往把这样的能力和金钱挂钩,用数字来和别人证明你的能力。最近一直在寻找,如何不通过 select count(*) from table where 字段 = ‘值’ 类似这样的语句,大约会产生多少结果行的问题的解决方案。在一些大表存在的数据库,去不断查询某一个值在这个大表里面的行数,一直是不受欢迎的事情,最后找到了一个还算靠谱的方案。
当然今天的文字并不是要说这个问题,我们提高难度,如果有需求问你,怎么知道现在的表中,某个字段的值,如果被查询的在有索引的情况下,效率如何,通过这个问题,我们可以判断我们的索引该怎么建立。
今天我们需要从 pg_stats 这张表里面要答案, PostgreSQL 数据库本身中是自带直方图和统计信息分析的,比某些开源数据库默认关闭的初始状态来说要好,基于pg_stats 的这张表本身来自于PostgreSQL的另一张表pg_statistic 来说,pg_statistic的信息晦涩难懂,并且不适合直接拿来应用。
pg_stats 里面的数据就要相对来说更适合我们,下面是pg_stats 里面的字段列表,我们需要关注几个部分
1 n_distinct
2 most_common_vals 3 most_common_freqs
dvdrental=# \d pg_stats
View "pg_catalog.pg_stats"
Column | Type | Collation | Nullable | Default
------------------------+----------+-----------+----------+---------
schemaname | name | | |
tablename | name | | |
attname | name | | |
inherited | boolean | | |
null_frac | real | | |
avg_width | integer | | |
n_distinct | real | | |
most_common_vals | anyarray | | |
most_common_freqs | real[] | | |
histogram_bounds | anyarray | | |
correlation | real | | |
most_common_elems | anyarray | | |
most_common_elem_freqs | real[] | | |
elem_count_histogram | real[] | | | 这里我们主要使用这三个字段来进行上面问题的解决方案的核心信息来源。
1 n_distinct
2 most_common_vals 3 most_common_freqs 这里根据相关的表信息的描述,n_disinct的值,在不等于1的情况下,都可以考虑来讲这个字段作为建立索引的可选项。 同时我们针对 most_common_vals 对应 most_comon_freqs 两个字段的值来判定所选的索引,在查询的时候被作为条件时,可能会产生的影响。 我们以下表的列子为例
dvdrental=# select *,t_vals.freqs::float * t_rels.reltuples as rows
from (SELECT tablename,attname,unnest(most_common_vals::text::text[]) as vals,unnest(most_common_freqs::text::float[]) as freqs FROM pg_stats) as t_vals
left join (SELECT relname,reltuples FROM g_class CLS LEFT JOIN pg_namespace N ON ( N.oid = CLS.relnamespace )
WHERE nspname NOT IN ( 'pg_catalog', 'information_schema' ) AND relkind = 'r') as t_rels on t_vals.tablename = t_rels.relname
where t_rels.relname in ('actor')
dvdrental-# ;
tablename | attname | vals | freqs | relname | reltuples | rows
-----------+-------------+------------------------+-------+---------+-----------+------
actor | first_name | Austin | 0.02 | actor | 200 | 4
actor | first_name | Kenneth | 0.02 | actor | 200 | 4
actor | first_name | Penelope | 0.02 | actor | 200 | 4
actor | first_name | Burt | 0.015 | actor | 200 | 3
actor | first_name | Cameron | 0.015 | actor | 200 | 3
actor | first_name | Christian | 0.015 | actor | 200 | 3
actor | first_name | Cuba | 0.015 | actor | 200 | 3
actor | first_name | Dan | 0.015 | actor | 200 | 3
actor | first_name | Ed | 0.015 | actor | 200 | 3
actor | first_name | Fay | 0.015 | actor | 200 | 3
actor | first_name | Gene | 0.015 | actor | 200 | 3
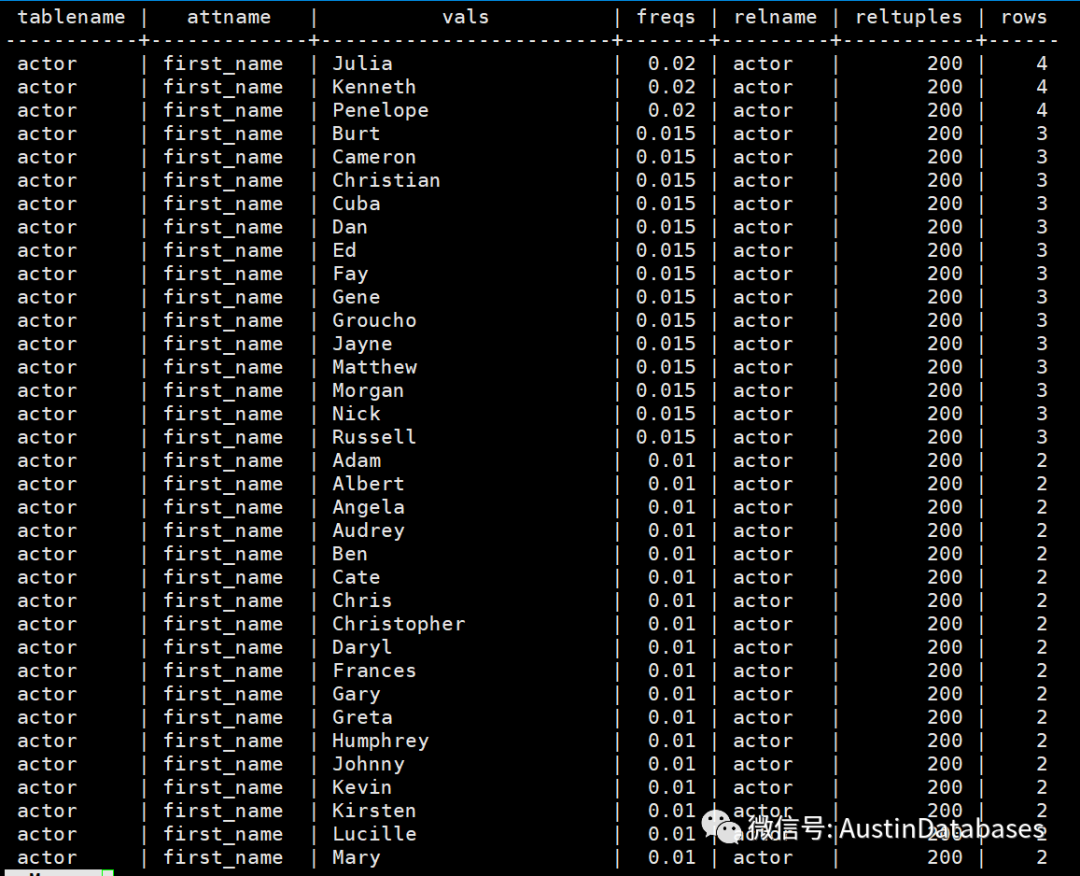
从上面的信息中,我们可以看到一个比啊中的列大致有那些列的值,并且这些值在整个表中占比是多少,通过这个预估的占比,我们马上可以获知,这个值在整个表行中的大约会有多少行,但基于这个值是预估的,所以不是精确的值,同时根据analyze 中对于数据的分析,他们是有采样率的表越大行数越多,这个采样率会变得越小,所以会导致上面的结果和实际的结果是有出入的。
但如果表小,则计算出的评估值和实际值之间的准确性还是蛮高的,参见上图Julia,值的评估。
但如果将这个思路打开,则我们还可以做更多有意思的事情,甚至写出一个评估索引好坏的程序。
with first_name as (
select *,t_vals.freqs::float as freqs_1
from (SELECT tablename,attname,
unnest(most_common_vals::text::text[]) as vals,
unnest(most_common_freqs::text::float[]) as freqs FROM pg_stats) as t_vals
left join (SELECT relname,reltuples FROM pg_class CLS
LEFT JOIN pg_namespace N ON ( N.oid = CLS.relnamespace )
WHERE nspname NOT IN ( 'pg_catalog', 'information_schema' ) AND relkind = 'r') as t_rels on t_vals.tablename = t_rels.relname
where t_rels.relname in ('actor') and attname = 'first_name'),
last_name as (
select *,t_vals.freqs::float as freqs_2
from (SELECT tablename,attname,
unnest(most_common_vals::text::text[]) as vals,
unnest(most_common_freqs::text::float[]) as freqs FROM pg_stats) as t_vals
left join (SELECT relname,reltuples FROM pg_class CLS
LEFT JOIN pg_namespace N ON ( N.oid = CLS.relnamespace )
WHERE nspname NOT IN ( 'pg_catalog', 'information_schema' ) AND relkind = 'r') as t_rels on t_vals.tablename = t_rels.relname
where t_rels.relname in ('actor') and attname = 'first_name')
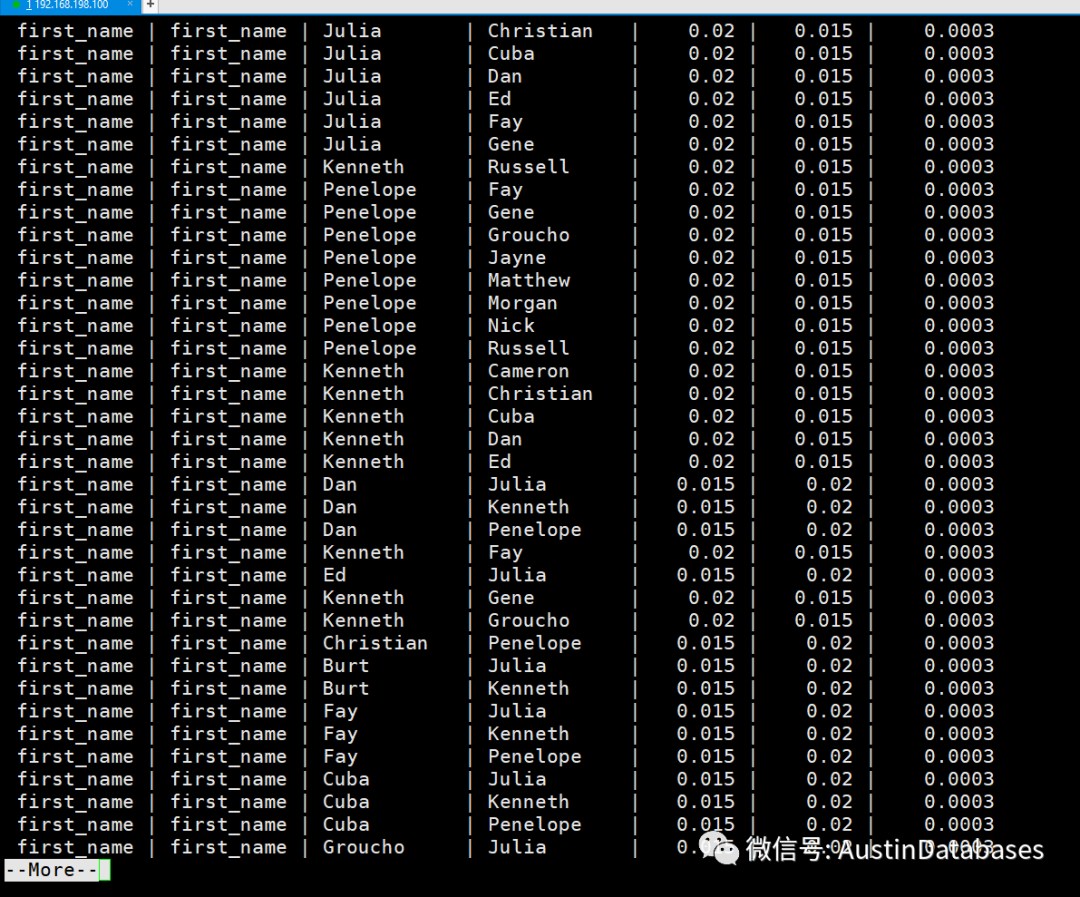
select first_name.attname as first_name,last_name.attname as last_name,
first_name.vals,last_name.vals,first_name.freqs_1,last_name.freqs_2,first_name.freqs_1 * last_name.freqs_2 as index_qua
from first_name
left join last_name on first_name.tablename = last_name.tablename
order by index_qua desc;
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-09-11 06:00,如有侵权请联系 cloudcommunity@tencent.com 删除
本文分享自 AustinDatabases 微信公众号,前往查看
如有侵权,请联系 cloudcommunity@tencent.com 删除。
本文参与 腾讯云自媒体同步曝光计划 ,欢迎热爱写作的你一起参与!
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号