【CV 向】如何打造一个“数串串神器“

导言
最近,我看到了这样一个视频,觉得很有意思,就随手保存下来了。😁😁😁
之前吃串串火锅,老板数竹签不是称重就是用手慢慢数,但是称重似乎总是得不到正确的竹签数目,而且容易暗箱操作;而慢慢数总是要等待比较长的时间,感觉两者对处理数竹签的问题都存在比较大的缺陷。因此,一款可以数竹签的应用因此产生,一下就弥补了两种处理方式所存在的缺陷。

当我第一眼看到这个 APP,就想到一个比较经典的 CV 案例 —— 数钢管,虽然我们平时不会将钢管和竹签联系在一起,但是如果将他们两个放在一起,你会发现两者似乎有“异曲同工”之处。

接下来的部分 ,我先来讲解一下经典案例数钢管,然后再过渡到数竹签的应用。
数钢管
想致富,先修路。想要很好的解决某个问题,思路首先要打开。如何打开思路呢?那就需要大胆的想象,去将“钢管”与我们的思维联系在一起,去思考一下我们在日常生活中是如何识别钢管的。
数钢管场景分析
如何去数钢管呢?一般分为两步,①识别一个物体是钢管,②钢管数 + 1。钢管数+1 大家应该都会吧,那么主要的难点是就是如何如何识别一个物体是钢管了。那么一个人又会怎样去判断一个物体是钢管呢?
通常情况下,我们会动用我们的“五感”来完成这项操作,但由于我们这里所说的是计算机视觉的内容,所以这里就只会列举和视觉相关可能情况:
1、颜色识别:人类首先会注意到钢管的颜色。钢管通常具有金属质感,常见的颜色有银灰色、黑色等。人们通过观察钢管的颜色来初步判断是否为钢管。
2、形状识别:人类会观察钢管的形状。钢管通常是圆柱形状,具有一定的长度和直径。人们会注意到钢管的直线边缘,并尝试通过比较宽度和长度的比例来判断是否为钢管。
3、光泽度分析:人们会注意到钢管的光泽度。钢管通常具有金属光泽,反射周围环境的光线。通过观察钢管表面的反射情况,人们可以进一步确认是否为钢管。
4、……
上面是一些可能存在的情况,但由于我们的目的是钢管和计数,钢管之间会存在堆叠的状态,而不仅仅是识别单个钢管,钢管之间会有遮挡等因素,而使“银灰色、黑色、圆柱形、有金属光泽等”钢管特征并不能应用到该场景下,所以我们进一步思考,堆叠状态下的钢管是什么样子,或者说它们有什么共同特征来方便我们计数。
下面是一副简易的堆积钢管侧面的模型图(如果为了存储或运输也有可能会变成六边形),我们能够看到,钢管就变成了一个个堆叠起来的圆橙色部分可以看做是一个个钢管,而灰色部分则是钢管所包裹成的阴影。如果我们能够找到每个钢管的轮廓这个问题就简单多了。
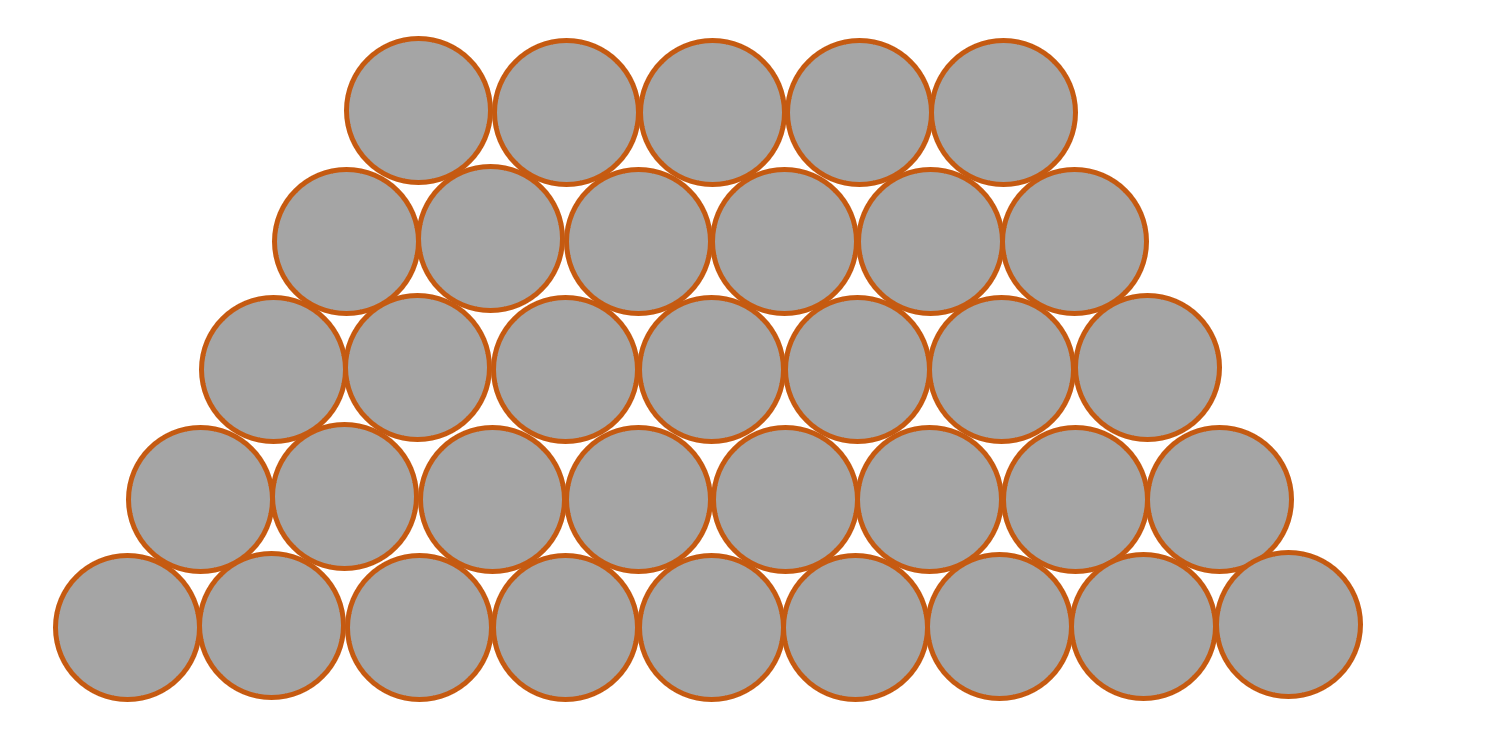
数钢管实战
图像预处理
当我们获得图像后,一般需要对图像进行色彩空间转换、噪声去除、对比度增强、图像平滑等预处理操作,才能够更好地进行后续的图像分析任务的处理。

下面将介绍几种适用数钢管场景的 CV 算法,大家可以了解一下来优化自己的数钢管应用。
Blob Detection
Blob Detection(斑点检测)是一种计算机视觉中常用的图像分析技术,用于检测和识别图像中的斑点或区域。斑点通常是图像中的亮点或暗点,其在图像中具有一定的特征和属性,例如颜色、大小、形状等。Blob Detection的目标是找到这些斑点并提取相关信息。
Blob Detection的原理可以概括如下:
1、阈值化:首先,将图像进行灰度处理,并应用适当的阈值化方法,将图像转换为二值图像。这可以通过简单的全局阈值化、自适应阈值化等方法来实现。
2、连通区域分析:在二值图像中,通过连通区域分析来找到图像中的连通区域。连通区域是由相邻像素组成的区域,像素具有相似的特征。
3、斑点筛选:通过对连通区域的属性进行筛选,识别出符合预设条件的斑点。这些属性可以包括斑点的面积、圆度、凸性等。
4、斑点标记:对于通过筛选的斑点,可以进行标记,例如绘制边界框、绘制圆形等,以便在图像上可视化这些斑点的位置和特征。
Blob Detection算法的参数可以根据具体的应用场景和图像特征进行调整。常见的参数包括最小阈值、最大阈值、斑点面积阈值、形状过滤等。这些参数的调整可以影响斑点的检测率和准确性。下面是一段示例代码,你可以调整参数来达到更好的效果
import cv2
import numpy as np
# 读取图像
image = cv2.imread("img.png", cv2.IMREAD_GRAYSCALE)
# 预处理:二值化
_, threshold = cv2.threshold(image, 0, 255, cv2.THRESH_BINARY_INV + cv2.THRESH_OTSU)
# 设置Blob Detector的参数
params = cv2.SimpleBlobDetector_Params()
params.minThreshold = 20 # 最小阈值
params.maxThreshold = 100 # 最大阈值
params.filterByArea = True # 按斑点面积过滤
params.minArea = 100 # 最小斑点面积
params.filterByCircularity = False # 不按圆度过滤
params.filterByConvexity = False # 不按凸度过滤
params.filterByInertia = False # 不按惯性过滤
# 创建Blob Detector
detector = cv2.SimpleBlobDetector_create(params)
# 斑点检测
keypoints = detector.detect(threshold)
# 绘制检测结果
image_with_keypoints = cv2.cvtColor(image, cv2.COLOR_GRAY2BGR)
for kp in keypoints:
x, y = kp.pt
size = kp.size
cv2.circle(image_with_keypoints, (int(x), int(y)), int(size/2), (0, 0, 255), 2)
# 显示结果
cv2.imshow("Steel Pipe Detection", image_with_keypoints)
cv2.waitKey(0)
cv2.destroyAllWindows()
# 输出钢管数量
steel_pipe_count = len(keypoints)
print("Steel Pipe Count:", steel_pipe_count)HoughCircle
Hough Circle Transform(霍夫圆变换)是一种用于在图像中检测圆的经典算法。它基于霍夫变换的原理,通过在极坐标空间中搜索圆的参数,并将其转换回图像空间,从而实现对圆的检测和提取。
Hough Circle Transform 的原理可以概括如下:
- 边缘检测:首先,在输入图像上应用边缘检测算法(如Canny边缘检测),以获取图像中的边缘信息。
- 参数空间:在霍夫圆变换中,使用三个参数来表示一个圆:圆心的x坐标、圆心的y坐标以及圆的半径r。通过设定合适的参数范围,创建一个二维的参数空间来表示所有可能的圆。
- 累加器数组:对于每个边缘点,根据其可能的圆心和半径,在参数空间中进行累加。即对于每个边缘点,对应的参数空间中的位置加上一个权重值。
- 圆检测:在累加器数组中找到具有高累加值的位置,这些位置对应于可能的圆心和半径组合。这些位置表示了图像中存在的圆。
- 阈值和非最大抑制:根据设定的阈值,筛选出累加值高于阈值的圆。对于相邻的圆,进行非最大抑制,保留具有最高累加值的圆,抑制其他圆。
- 绘制圆:根据筛选出的圆心和半径,在原始图像上绘制检测到的圆。
Hough Circle Transform 的参数包括边缘检测的参数、参数空间的分辨率、最小半径和最大半径的范围等。这些参数的设置会影响圆的检测结果,需要根据具体的应用场景和图像特征进行调整。
同样,下面给出一段代码,你可以修改代码达到更好地效果。
import cv2
import numpy as np
# 读取图像
image = cv2.imread("img.png")
# 预处理:灰度化
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 边缘检测
edges = cv2.Canny(gray, 50, 150)
# 霍夫圆变换
circles = cv2.HoughCircles(edges, cv2.HOUGH_GRADIENT, dp=25, minDist=1, param1=1, param2=20, minRadius=10, maxRadius=30)
# 钢管计数
steel_pipe_count = 0
# 绘制检测到的钢管
if circles is not None:
circles = np.round(circles[0, :]).astype(int)
for (x, y, r) in circles:
cv2.circle(image, (x, y), r, (0, 255, 0), 2)
cv2.circle(image, (x, y), 2, (0, 0, 255), 3)
steel_pipe_count += 1
# 显示结果
cv2.imshow("Steel Pipes", image)
cv2.waitKey(0)
cv2.destroyAllWindows()
# 输出钢管数量
print("Steel Pipe Count:", steel_pipe_count)
轮廓分析
轮廓分析是计算机视觉和图像处理中常用的一种技术,用于检测和描述图像中的对象形状。它基于图像的边缘信息,通过连接边缘点构成闭合的曲线,从而得到物体的轮廓。
轮廓分析的基本步骤如下:
- 边缘检测:首先,在输入图像上应用边缘检测算法(如Canny边缘检测)或其他边缘提取方法,以获取图像中的边缘信息。
- 轮廓提取:通过在边缘图像上应用轮廓提取算法(如cv2.findContours函数),寻找并提取闭合的轮廓。轮廓由一系列有序的点组成,可以表示对象的外形。
- 轮廓特征提取:对于每个提取的轮廓,可以计算一些特征来描述其形状、大小、方向等。常用的轮廓特征包括轮廓长度、面积、周长、外接矩形、外接圆等。
- 轮廓筛选和过滤:根据应用需求,可以通过一些筛选条件和过滤方法,对提取的轮廓进行进一步处理。例如,可以根据轮廓的特征进行筛选,去除过小或过大的轮廓,或者根据形状特征进行形态学处理。
- 轮廓绘制和可视化:可以将提取的轮廓绘制在原始图像上,以便进行可视化和结果展示。这可以通过绘制轮廓曲线、外接矩形或其他几何形状来实现。
轮廓分析在许多图像处理和计算机视觉任务中都有广泛应用,如目标检测、形状识别、图像分割等。通过对轮廓的分析和提取,可以获取图像中对象的形状信息,从而实现对图像中感兴趣区域的提取、分类、计数等操作。
下面结合本例给出一段代码,你也可以修改,查看是否能够获得更好的效果。
import cv2
# 读取图像
image = cv2.imread("img.png")
# 转换为灰度图像
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
# 进行图像预处理
blurred = cv2.GaussianBlur(gray, (5, 5), 0)
_, threshold = cv2.threshold(blurred, 100, 255, cv2.THRESH_BINARY)
# 轮廓检测
contours, _ = cv2.findContours(threshold, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
# 钢管计数
steel_pipe_count = 0
# 遍历轮廓
for contour in contours:
# 进行轮廓逼近
epsilon = 0.02 * cv2.arcLength(contour, True)
approx = cv2.approxPolyDP(contour, epsilon, True)
# 判断是否为钢管(通过轮廓的形状等特征)
if len(approx) >= 4:
(x, y, w, h) = cv2.boundingRect(approx)
aspect_ratio = w / float(h)
# 调整判断条件
if 0.1 <= aspect_ratio <= 1.4 and cv2.contourArea(contour) > 50:
# 绘制钢管轮廓
cv2.drawContours(image, [approx], 0, (0, 255, 0), 2)
steel_pipe_count += 1
# 显示结果
cv2.imshow('image', threshold)
cv2.imshow("Steel Pipes", image)
cv2.waitKey(0)
cv2.destroyAllWindows()
# 输出钢管数量
print("Steel Pipe Count:", steel_pipe_count)
结合深度学习
深度学习和OpenCV是两种不同但可以相互结合的技术,它们在图像分析和处理任务中发挥着重要作用。深度学习通过神经网络模型和大规模数据训练,能够学习到图像中的复杂特征和模式,具有很强的图像识别和分类能力。
而OpenCV是一个强大的计算机视觉库,提供了丰富的图像处理和分析工具,可以实现各种传统的图像处理算法。结合深度学习和OpenCV可以发挥两者的优势,提高图像分析的准确性和效果。
在钢管识别中,可以利用集成的深度学习模型对预处理后的图像进行钢管识别。根据模型的输出结果,确定图像中存在钢管的位置信息。然后,可以使用OpenCV中的轮廓分析、形状分析等技术对钢管进行进一步处理和计数。
数竹签分析
而数串串,与数钢管有异曲同工之处,图像预处理后,两者的图像会有所不同,但由于“串串”是实心的,而钢管是空心的,这是两者区别最大的地方;需要针对串串的特点进行特定的预处理和参数调整,并对实心的串串重新训练模型,需要针对串串的特点进行特定的预处理和参数调整。

总结
在本文中,我们介绍了使用OpenCV和深度学习来解决数钢管和数串串的问题,使用OpenCV的Blob Detection和Hough Circle技术对钢管以及串串进行检测,并使用轮廓分析对钢管进行计数。然而仅仅适用 OpenCV 技术似乎是不行的,需结合深度学习才能达到更好的效果。
腾讯云开发者
