大语言模型能处理时间序列吗?

#TSer#
大家都知道预训练大型语言模型(LLMs)具有强大的表示学习能力和少样本学习,但要利用LLM处理时间序列,需要解决两个关键问题:
- 如何将时间序列数据输入LLMs
- 如何在不破坏LLM固有特性的情况下对其进行微调使其能够适配时间序列任务
本文介绍一篇由北京大学和阿里联合推出的工作,他们使用 LLM 实现了时间序列的分类和预测任务。

论文地址:https://arxiv.org/abs/2308.08241
论文源码:暂未公布
背景概述
目前将 LLM 利用在时间序列上的工作主要有两种策略:
- LLM for TS:从零开始设计并预训练一个专为处理时间序列数据而优化的基础大模型,然后可根据各种下游任务对模型进行微调。这条路径是最基本的解决方案,基于大量数据,通过预训练向模型灌输时间序列相关知识。
- TS for LLM:旨在将时间序列数据的特性引入到现有的语言模型中,使其能够适用于现有的语言模型,从而基于现有的语言模型处理时间序列的各类任务。这一路径无疑挑战更大,需要超越原始语言模型的能力。
而该论文的研究者更倾向于探索 TS for LLM 方向,主要原因有下面三方面:
- LLM for TS 专注于垂域模型。因为不同领域的 时间序列数据存在巨大的差异,因此需要针对特定领域,如医疗、工业等从头开始构建和训练各种模型。TS for LLM 则几乎不需要训练,通过利用插件模块,更具有通用性和便利性。
- LLM for TS 需要大量数据积累。与文本或图像数据相比,时间序列数据更专业且涉及隐私问题,难以获取大量的同类型时间序列数据,而 TS for LLM 则可以使用相对较小的数据集。
- TS for LLM 保留了语言模型的文本能力,同时提供丰富的补充语义信息,易于访问并且用户友好。
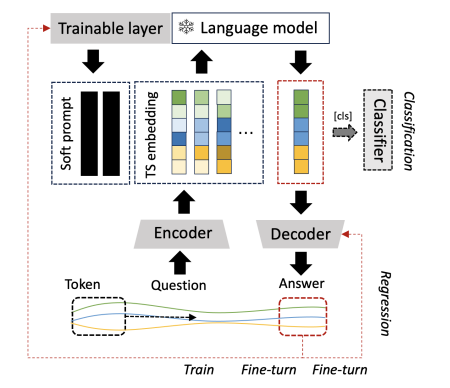
该论文分别通过 instance-wise,feature-wise 和 text-prototype-aligned 这三种对比学习设计了一种时间序列编码器,名叫 TEST,其可以获取适用于 LLM 的时间序列表示。同时,研究者也设计了相应的 Prompt 使得现有的 LLM 能够更适用于时间序列的嵌入,最终实现多种时间序列任务。
方法介绍
该论文所提方法包含如下两个部分:
- 对时间序列进行标记化(分词处理),然后使用对比学习训练时间序列编码器;
- Prompt 设计
两个关键步骤,下面详细进行介绍。
对于一个多元时间序列
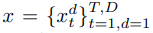
, 首先通过滑动窗口将其划分成K个子序列
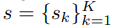
,由此可以将时序离散以构建 token 。子序列对应的正样本来自两部分,一是与其具有重叠样本的子序列,二是通过数据增强获得的实例。通过对原序列加噪声和缩放,或通过对序列进行随机分割并打乱可得到负样本。负样本是与正样本不重叠的样本实例。
接着,利用映射函数

,将每个token映射为M维的表征
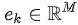
,最终获得序列的 token 集合
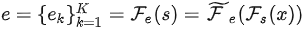
对于获得的token,首先通过目标函数
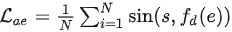
,保证token集合能够充分表征原始序列信息。接下来进一步考虑对比学习。
01
instance-wise 对比学习
构造完正负实例后,就需要设计模型使其可以区分这两种样本,其目标是使得 anchor 实例与其对应的正 token 实例尽可能相似,与负 token 实例差异尽可能大,目标函数如下:

然而,这种对比学习存在一定的弊端:对于可能将没有重叠样本,但位置相近且语义相近的实例视为负例。
02
feature-wise 对比学习
针对上述的问题,研究者进一步设计了 feature-wise 对比学习,关注不同列所包含的语义信息,其目标函数如下:
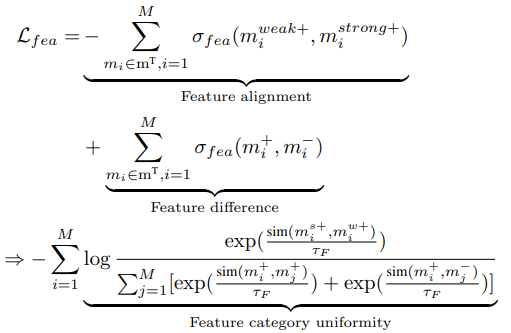
这个目标函数中的
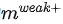
,
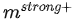
和
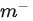
可通过映射
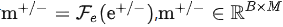
,
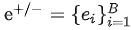
获取。其中B为mini-batch的大小。上述目标函数保证了在特征级别,正样本之间尽可能相似,而负样本之间的特征差异尽可能大。但这样也容易导致特征表示收缩到一个较小的空间。因此目标函数的最后一项需要去最大化不同特征间差异,避免上述这种问题。
03
text-prototype-aligned 对比学习
最后为了让 LLM 更好地理解所构建出来的时序特征表示,研究者还设计了 text-prototype-aligned 对比学习,这步骤的目标是使时序特征表示与文本表示空间进行对齐。目前预训练好的 LLM 已经有了自己的文本特征表示,例如,GPT-2 将词汇表中的文本token 嵌入到维度为 768、1024和1280的表示空间中 。
研究者强制让时间序列标记 e 与文本标记 token 进行对齐。例如,虽然时序特征表示可能缺少对应相关的文本表述,但是可以拉近其与 token 数值、形状和频率等描述的相似度。通过这种形式的对齐,token 就有可能获得表征诸如时间序列小、大、上升、下降、稳定、波动等丰富信息的能力。
然而在实际情况中,因为我们很难获取有监督标签的真实数据作为基准,上述文本时序对齐的结果很可能无法合乎现实逻辑。例如,具有上升趋势子序列对应的表示很可能与具有下降趋势序列的表示非常相近。为了更好地匹配时序特征表示和文本 token,研究者设计了如下的对比损失函数:
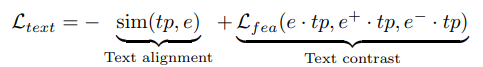
其首先通过约束时序特征向量与文本表示向量之间的余弦相似性,即 text alignment部分。其次,使用文本原型作为坐标轴将时序特征表示映射到相应的位置,从而保证相似的实例在文本坐标轴中有着类似的表示。过程如下图所示:
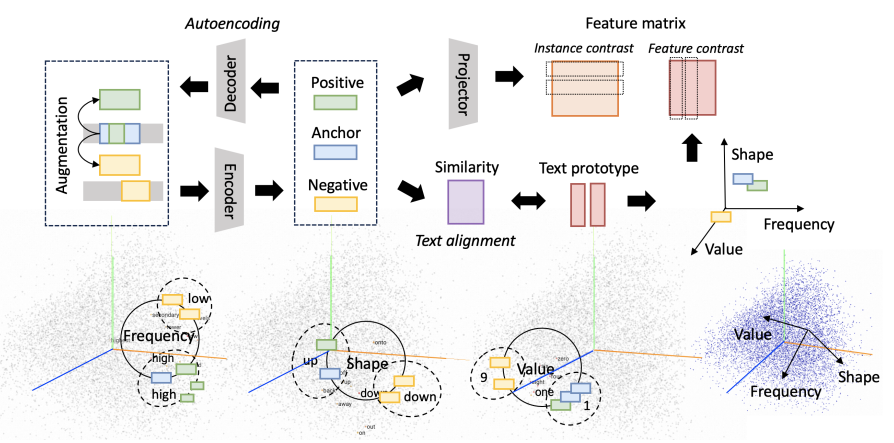
通过上述过程,研究者就构造出了语言模型能够理解的嵌入式表示,以此就可以描述时间序列。然而,如何让语言模型进行接下来的时间序列任务呢?
目前 Prompt 工程和 COT 思维链相对来说比较直观,能够指导模型获得较好的结果,但我们需要连贯的上下文语义才可以使用这种方法,时序特征表示并不具备这样的特效。因此,该论文的研究者们进一步训练了针对于时序数据的软提示(soft prompt),使得语言模型能够识别到不同的序列模式,进而实现下游时序任务。这些软提示是针对特定任务的表示,初始化的方式比较灵活:1) 可以从均匀分布中随机初始化,2) 从下游任务标签的文本嵌入中获取初始值,3) 从词汇表中最常见的词汇中获取初始值等。软提示的目标函数如下:
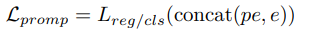
文章提到有监督微调方法能有效提高下游时序任务的准确性,但考虑到训练成本高昂以及无法保证微调后的语言模型能够有效理解时序特征表示中的语义信息,研究者放弃了有监督微调而采用了训练软提示的方式。研究者也证明了经过训练软提示确实能够达到有监督微调相似的效果。具体训练过程如下:

实验情况
实验环节,研究者采用了 TEST,针对不同的语言模型,对其在时间序列分类与预测任务上的性能进行考察。实验结果如下图所示:
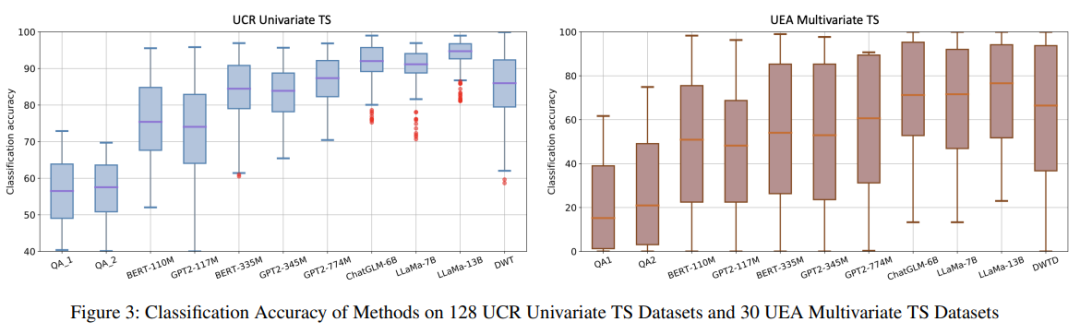
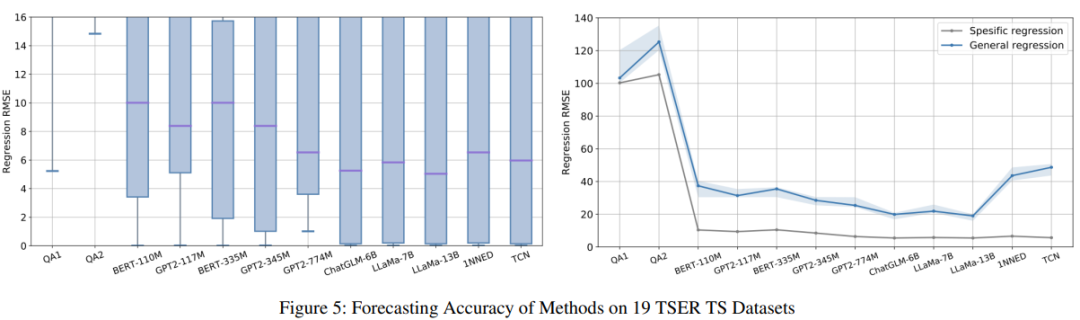
可以看到,这些语言模型能够达到与常见基准模型相当的性能。实验结果还显示,使用更大的模型能够带来更精确的结果。研究者认为,这种现象产生的根本原因与语言模型预训练数据集的规模有关。在预训练阶段使用了越多的数据集,原型选择和提示设计的角色就不再那么重要。
总结
该文的研究者们提出了TEST 框架,以在 TS for LLM 的思想下实现时序数据的实例、特征和文本原型对齐嵌入方法。它可以激活 LLM 实现时间序列任务,同时保持其原始语言能力。在分类和预测任务上的实验表明,使用 TEST,LLM 可以实现有竞争力的表现。未来研究者们会测试其他时间序列任务,如异常检测,研究时间序列和文本的更多对齐方法。