iTransformer:让 Transformer 重回时序预测主流地位?
iTransformer:让 Transformer 重回时序预测主流地位?

#TSer#
Transformer 模型在自然语言处理和计算机视觉领域取得了巨大的成功,并成为了基础模型。然而,最近一些研究开始质疑基于Transformer的时间序列预测模型的有效性。这些模型通常将同一时间戳的多个变量嵌入到不可区分的通道中,并在这些时间标记上应用注意力机制来捕捉时间依赖关系。
近日,来自清华大学软件学院机器学习实验室和蚂蚁集团研究人员合作发布的一篇时间序列预测论文,试图打破质疑,引起业界热议。
鉴于对Transformer的预测模型的争议,研究者反思了为什么Transformer在时间序列预测中的表现甚至不如线性模型。因此,这篇论文里提出了iTransformer作为针对时间序列进行最小适应的基本骨干,其原生组件自然地处理了反转的维度,即讨论了倒置Transformer在时间序列预测方面的有效性。
iTransformer 将每个时间序列嵌入为变量令牌,并使用前馈网络进行序列编码,以捕捉多元相关性。iTransformer 模型在真实数据集上获得了更先进的性能,为改进基于Transformer的预测器提供了有希望的方向。

论文地址:https://arxiv.org/abs/2310.06625
论文源码:https://github.com/thuml/Time-Series-Library
研究背景
该论文的问题背景是关于基于Transformer的时间序列预测模型的架构修改是否合理的讨论。
传统的Transformer模型在时间序列预测中存在性能下降和计算爆炸的问题,同时对于具有较大回溯窗口的序列预测也存在挑战。此外,传统的Transformer模型将每个时间步的多个变量嵌入到同一个标记中,可能导致学习到的注意力图无意义。
因此,该论文提出了一种称为iTransformer的新方法,通过重新设计Transformer架构,将注意力机制和前馈网络的职责进行了倒置,以更好地捕捉多变量之间的相关性和学习非线性表示。
下图是vanilla Transformer和提出的iTransformer之间的比较:
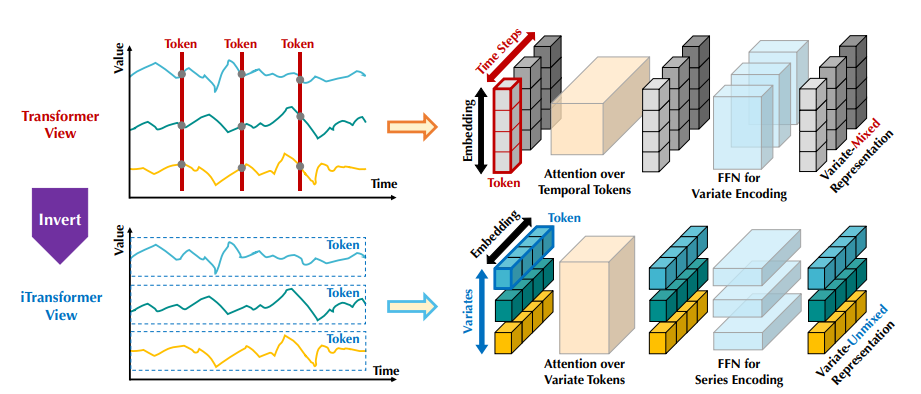
1. 嵌入方式:传统的Transformer将每个时间步嵌入到时间令牌中,而iTransformer则将整个时间序列独立地嵌入到变量令牌中。
2. 多元相关性:由于iTransformer将每个时间序列独立嵌入为变量令牌,因此可以通过注意力机制描绘多元相关性,而传统的Transformer则无法很好地处理多元相关性。
3. 编码方式:在iTransformer中,系列表示由前馈网络进行编码,而传统的Transformer则使用注意力机制和前馈网络进行编码。
综上所述,iTransformer通过不同的嵌入方式和编码方式,能够更好地处理多元相关性,为时间序列预测提供了更有效的解决方案。
方法介绍
研究者认为,Transformer的原始模块已经经过了广泛领域的验证,而现有的问题在于Transformer的架构没有被正确地应用。因此,提出的iTransformer模型并没有修改Transformer的任何原生组件,而是通过全新的倒置视角来实现更好的预测性能。
01
Embedding the whole series as the token
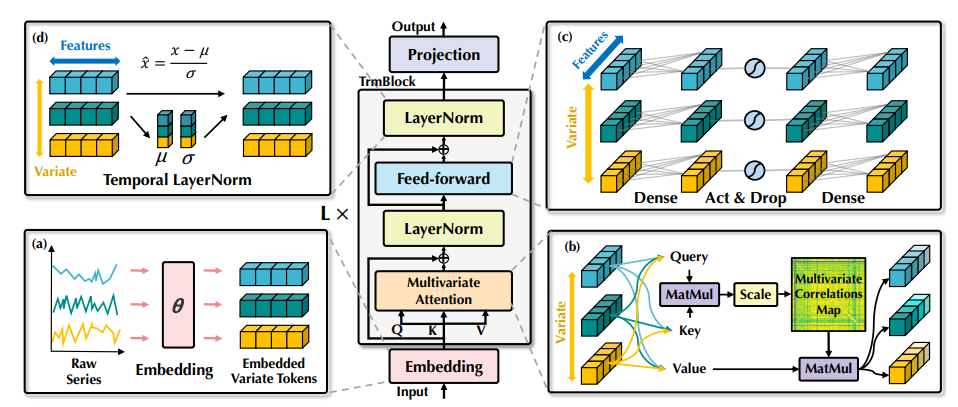
iTransformer的整体结构,与Transformer的编码器具有相同的模块布局(如下图):(a)不同变量的原始序列被独立地嵌入到令牌中。(b)将自注意力应用于嵌入的变量令牌,增强了可解释性,揭示了多元相关性。(c)每个令牌的序列表示由共享的前馈网络提取。(d)采用层归一化来减少变量之间的差异。
在iTransformer中,基于历史序列预测每个特定变量的未来序列的过程可以简单地表述如下:
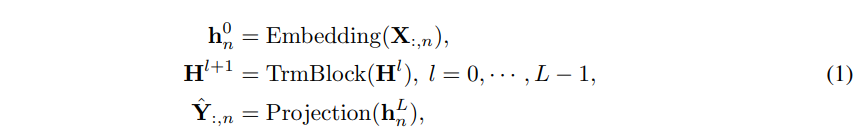
其中,H = {h1, ..., hN } ∈ R^N×D 表示N个维度为D的嵌入令牌。嵌入和投影操作都是通过多层感知机(MLP)实现的。得到的变量令牌通过自注意力机制进行交互,并在每个TrmBlock中由共享的前馈网络独立处理。由于前馈网络的神经元排列隐式地存储了序列的位置顺序,因此不再需要使用位置嵌入。
02
倒置Transformer模块分析
1. 层归一化(Layer normalization)
在传统的Transformer模型中,层归一化被用于对同一时间戳的变量表示进行归一化,逐渐增加每个变量之间的不可分辨性。但是,当收集的时间点没有按时间对齐时,这种操作会引入非因果或延迟过程之间的交互噪声。
因此,在倒置版本中,归一化被应用于单个变量的序列表示,这已被证明在解决非平稳问题方面是有效的。此外,由于所有序列作为(变量)令牌被归一化为正态分布,因此可以减小由不一致的测量引起的差异。
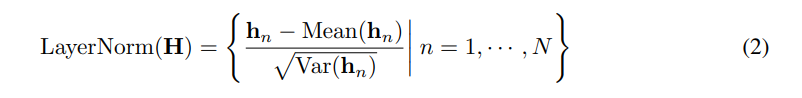
2. 前馈网络(Feed-forward network)
Transformer利用前馈网络作为编码令牌表示的基本构建块,并且它被相同地应用于每个令牌。
与原始的Transformer相比,倒置版本的前馈网络被应用于不同令牌的通道上,可以提取复杂的特征来描述时间序列。堆叠的倒置块致力于编码观察到的时间序列,并解码未来系列的特征,使用密集的非线性连接。此外,在独立时间序列上进行相同的线性操作,可以作为最近的线性预测器和通道独立策略的组合,有助于理解系列特征。
最近有对线性预测器的研究表示,由MLP提取的时间特征应该在不同的时间序列之间共享。基于以上,研究者提出了一种合理的解释,即MLP的神经元被训练来描绘任何时间序列的内在属性,比如振幅、周期性和甚至频谱(神经元作为滤波器),作为比时间点上的自注意力更有优势的预测表示学习器。
实验验证了分工有助于享受线性层的优势,例如提供更高的回溯系列的性能提升,以及对未见过的变量的泛化能力。
3. 自注意力(Self-attention)
倒置模型将注意力机制应用于多元时间序列预测,其中每个变量的整个序列被视为一个独立的进程。
研究者提出自注意力图(Attention Map)的每个位置满足以下公式:
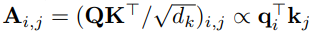
通过线性投影得到查询、键和值,并利用这些元素计算预Softmax分数,以揭示变量之间的相关性。高度相关的变量将在下一次表示交互时获得更大的权重。这种机制提供更自然和可解释的方式来建模多元时间序列数据。
实验分析
在这个部分,研究者对提出的iTransformer模型进行了广泛的实验评估,验证了该模型在各种时间序列预测任务中的性能。此外,还深入探讨了将Transformer组件的职责进行反转对特定时间序列维度的影响。
01
数据集
研究者在实验中使用了6个真实世界的数据集,包括ETT、Weather、Electricity、Traffic、Solar-Energy和PEMS。这些数据集涵盖了不同领域的时间序列数据,并且具有不同的维度和特征。
同时研究者还在支付宝交易平台的线上服务负载预测任务场景的数据(Market)中进行了预测。
02
实验结果
研究者与10种最新的预测模型进行对比,包括代表性的 Transformer 模型。实验结果如下:

可以看到,iTransformer 在六大测试基准中都取得最优的效果,并在 Market 数据的多个场景里取得最优效果。在长时预测以及多维时间预测这两个预测任务中(普遍认为是最具有挑战的预测任务),iTransformer 全面地超过了近几年的预测模型。
03
框架通用性
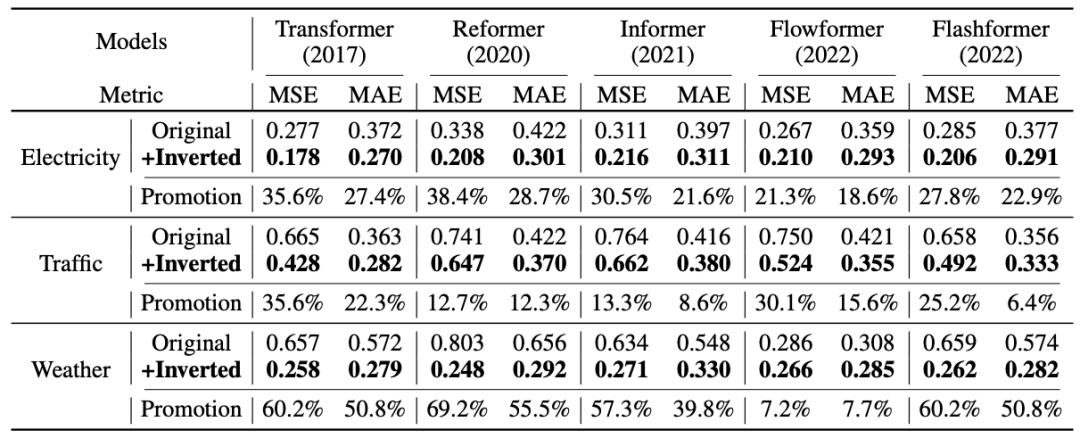
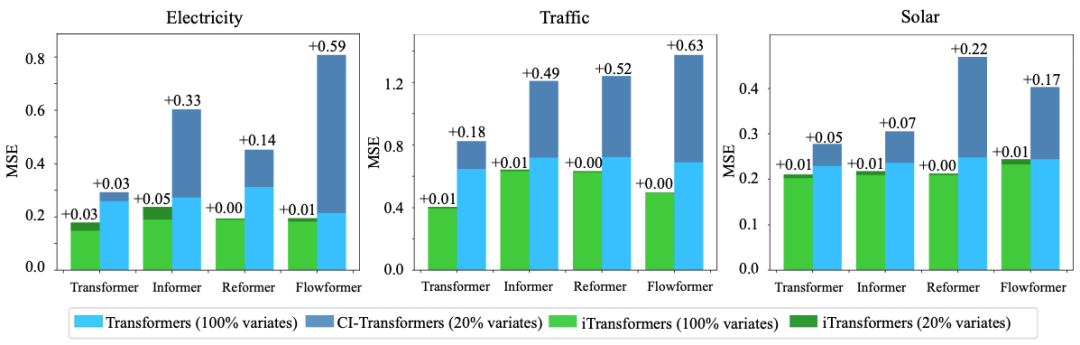
研究者在 Reformer、Informer、Flowformer、Flashformer 等进行时序预测的 Transformer 变体模型上测试倒置的通用性,证明了倒置是更加符合时序数据特点的结构框架。
1. 可以提升预测效果
2. 能泛化未知变量
3. 可以使用更长的历史观测

总结
该论文的研究者基于多维时间序列的本身的数据特性,回归了现有 Transformer 模型对时序数据建模的问题,提出了一个通用的时序预测框架:iTransformer。这个框架引入倒置的概念对时间序列进行观察,使其可以针对性完成时序数据的建模,并且具备通用性。
面对 Transformer 在时序预测领域是否有效的质疑,这个工作为后续研究提供了很好的案例,让 Transformer 重新回到时间序列预测的主流位置,为时序数据领域的基础模型研究提供新的思路。