动手实战 | 用 TSLearn 进行时间序列聚类和可视化

#TSer#
时间序列的聚类在工业生产生活中十分常见,大到工业运维中面对海量KPI曲线的隐含关联关系的挖掘,小到股票收益曲线中的增长模式归类,都要用到时序聚类的方法帮助我们发现数据样本中一些隐含的、深层的信息。
TSLearn 是一个流行的 Python 包,提供用于分析时间序列的机器学习工具。该包基于 scikit-learn、numpy 和 scipy 库,启动和运行内置的聚类算法非常简单直接。
本次文章将给大家展示一个使用 TSLearn 进行时间序列聚类和可视化的过程。
项目地址:https://github.com/tslearn-team/tslearn
首先,导入我们需要的依赖:
import pandas as pd
import numpy as np
from tslearn.preprocessing import TimeSeriesScalerMeanVariance接着用 Pandas 提取一些时间序列数据。其中 plots 为常用的绘图功能。我们定义输入,就可以轻松地画出时间序列的图像。现在我们开始定义聚类的参数:
n_clusters = 50 # number of clusters to fit
smooth_n = 15 # n observations to smooth over
model = 'kmeans' # one of ['kmeans','kshape','kernelkmeans','dtw']接下来,将获取的数据进行一些标准处理:
if n_charts:
charts = np.random.choice(get_chart_list(host), n_charts).tolist()
print(charts)
else:
charts = get_chart_list(host)
# get data
df = get_data(host, charts, after=-n, before=0)
if smooth_n > 0:
if smooth_func == 'mean':
df = df.rolling(smooth_n).mean().dropna(how='all')
elif smooth_func == 'max':
df = df.rolling(smooth_n).max().dropna(how='all')
elif smooth_func == 'min':
df = df.rolling(smooth_n).min().dropna(how='all')
elif smooth_func == 'sum':
df = df.rolling(smooth_n).sum().dropna(how='all')
else:
df = df.rolling(smooth_n).mean().dropna(how='all')
print(df.shape)
df.head()然后就可以用 tslearn 建立我们的聚类模型了:
if model == 'kshape':
model = KShape(n_clusters=n_clusters, max_iter=10, n_init=2).fit(X)
elif model == 'kmeans':
model = TimeSeriesKMeans(n_clusters=n_clusters, max_iter=10, n_init=2).fit(X)有了聚类集群后,我们可以先准备一些辅助对象,供后面画图使用:
cluster_metrics_dict = df_cluster.groupby(['cluster'])['metric'].apply(lambda x: [x for x in x]).to_dict()
cluster_len_dict = df_cluster['cluster'].value_counts().to_dict()
clusters_final.sort()
df_cluster.head()最后,让我们分别绘制每个聚类群组,看看有什么结果:
for cluster_number in clusters_final:
x_corr = df[cluster_metrics_dict[cluster_number]].corr().abs().values
plot_lines(df, cols=cluster_metrics_dict[cluster_number], renderer='colab', theme=None, title=plot_title)这里有一些很好的例子:
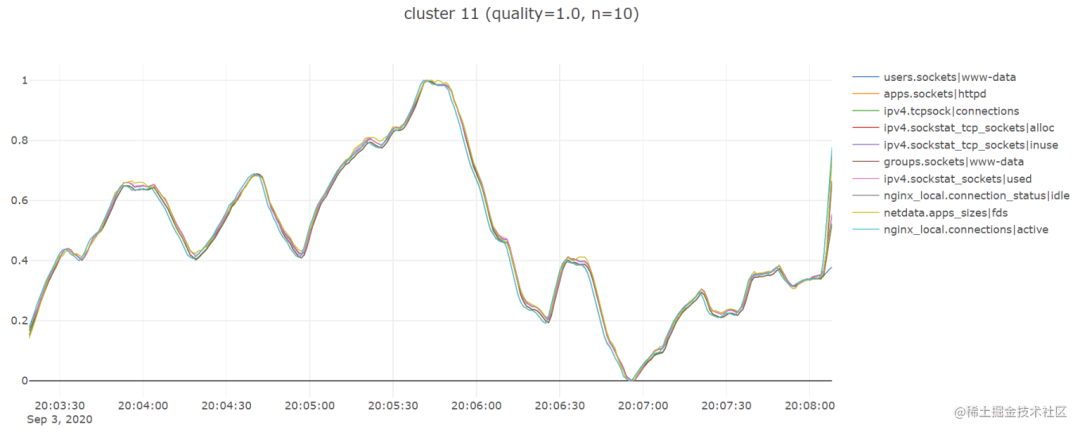
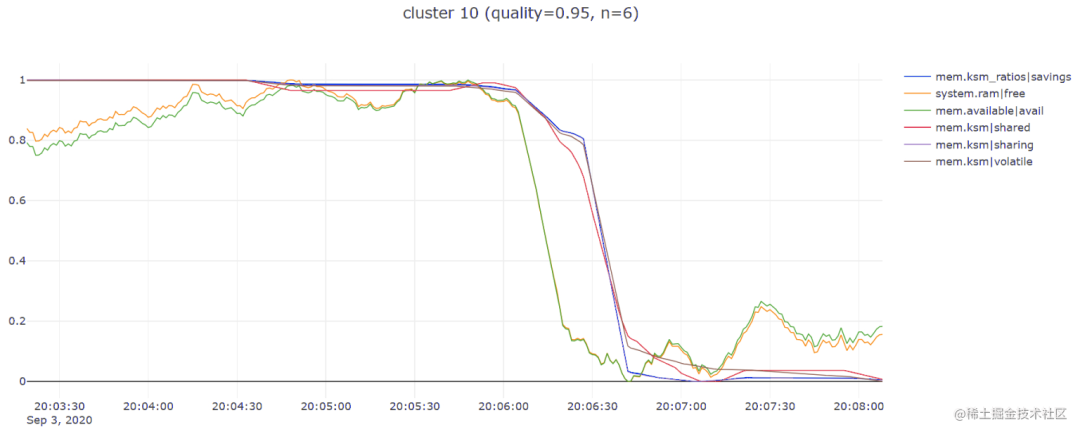
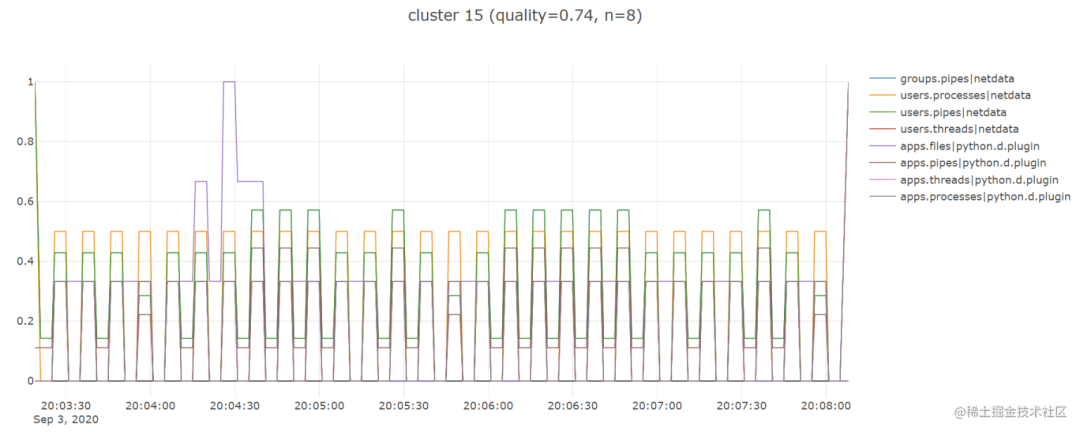
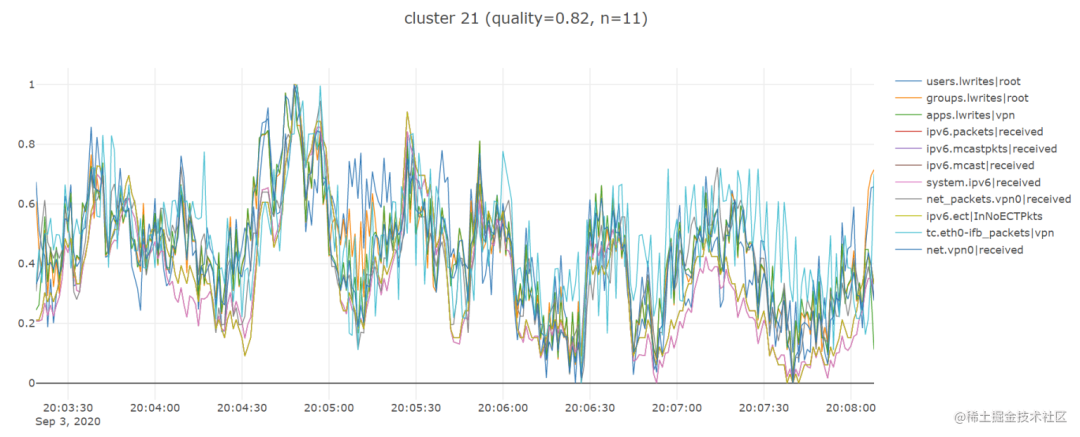
通过上面步骤,我发现 tslearn 库非常有用,因为它节省了我很多时间,让我快速建立并运行了一个工作原型,所以我期待着还能使用它提供的其他一些时间序列相关功能。
本文整理自 https://tecdat.cn/?p=33484
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-11-02,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者
