ICCV 2023 | COMPASS:任意尺度空间可伸缩性的深度图像压缩
ICCV 2023 | COMPASS:任意尺度空间可伸缩性的深度图像压缩

题目:COMPASS: High-Efficiency Deep Image Compression with Arbitrary-scale Spatial Scalability 作者:Jongmin Park,Jooyoung Lee,Munchurl Kim 来源:ICCV 2023 文章链接:https://openaccess.thecvf.com/content/ICCV2023/html/Park_COMPASS_High-Efficiency_Deep_Image_Compression_with_Arbitrary-scale_Spatial_Scalability_ICCV_2023_paper.html 内容整理:李江川 近年来,基于神经网络的图像压缩得到了积极的发展,与传统方法相比,其表现出了令人印象深刻的性能。然而,大多数工作都集中在不可扩展的图像压缩上,而空间可扩展图像压缩虽然有很多应用,但却很少受到关注。在本文中,作者提出了一种新的基于神经网络的空间可伸缩图像压缩方法,称为COMPASS,它支持任意尺度的空间可扩展性。作者提出的COMPASS具有非常灵活的结构,在参考过程中可以任意确定层数及其各自的比例因子。为了减少任意尺度因子下相邻层之间的空间冗余,COMPASS采用了一种基于隐式神经表示的层间任意尺度预测方法,称为LIFF。实验结果表明,与SHVC和最先进的基于神经网络的空间可扩展图像压缩方法相比,对于各种比例因子的组合,COMPASS分别实现了最大-58.33%和-47.17%的BD速率增益。对于各种比例因子,COMPASS也显示出与单层编码相当甚至更好的编码效率。
目录
- 引言
- 提出的方法
- 总体框架
- LIFF:层间任意尺度预测
- 实验
- 固定比例因子为2
- 任意比例因子
- 结论
引言
在多媒体系统中,不同的终端设备需要不同分辨率大小和不同质量的图像,但大多数现有的基于神经网络的图像压缩方法必须将同一图像的不同版本单独压缩为多个比特流,从而导致低编码效率。为了解决这个问题,有一些关于可缩放图像压缩的研究,其中图像的各种版本以分层方式的编码到单个比特流中。每个层负责对图像的一个对应版本进行编解码,并且通过不同的预测方法来减少相邻层之间的冗余。
可缩放编码方法分为两类:用于不同质量级别图像的质量可缩放编解码和用于不同分辨率大小图像的空间可缩放编解码。本文关注的是与质量可伸缩编码相比尚未被积极研究的空间可伸缩编码。在传统的可扩展编码中,SVC和SHVC作为H.264/AVC和H.265/HEVC的扩展,取得了一定的效果。尽管与不同版本的单层压缩相比,它们的编码效率显著提高,但可扩展编码尚未在现实世界中广泛应用。这可能是因为与相同空间大小的单层编码相比,累积比特流的编码效率较低。可伸缩编码由于其在层之间的冗余去除能力不足而通常产生较低的编码效率。
为了解决上述问题,本文提出了一种新的基于神经网络的具有任意尺度空间可伸缩性的图像压缩网络,称为COMPASS。COMPASS支持空间可缩放的图像压缩,将图像的多个任意缩放版本编码为单个比特流,其中图像的每个版本都用其对应的层进行编码。COMPASS中采用了一种基于隐式神经表示的层间任意尺度预测方法,称为局部隐式滤波函数(LIFF),该方法可以有效地减少相邻层之间的冗余,并支持任意尺度因子。基于其卓越的层间预测能力,与现有的可扩展编码方法相比,COMPASS显著提高了编码效率,并在各种尺度因子下实现了与单层编码相当甚至更好的编码效率。而单层编码的编码效率可视为可缩放编码效率的上限。
总之,这篇文章的主要贡献可以概括为:
- 提出的COMPASS是第一种针对任意比例因子的基于神经网络的空间可缩放图像压缩方法,主要采用了一种基于隐式神经表示的层间任意尺度预测方法,被称为LIFF,它可以有效减少空间域中的层间冗余并支持任意尺度缩放因子。
- COMPASS显著优于现有的空间可扩展编码方法。此外,COMPASS是第一个在不同比例因子下,基于相同的图像压缩主干,在编码效率方面表现出与单层编码相当甚至更好的性能的方法。
提出的方法
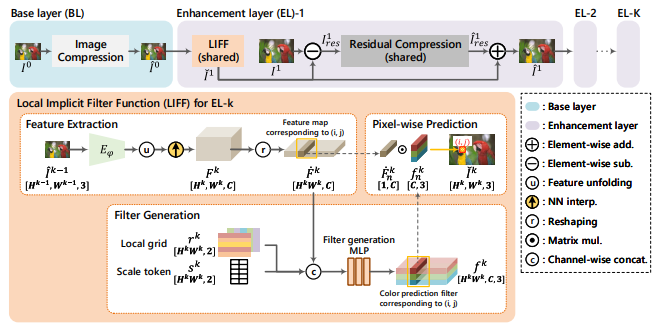
图1 COMPASS的总体结构
总体框架
COMPASS由两种类型的层组成:编码最低分辨率图像的基础层(BL)和顺序编码任意尺度的多个更高分辨率图像的一个或多个增强层(EL)。对于以任意比例因子逐渐增加大小的
个缩放图像
的空间可缩放编码,COMPASS在BL和
个EL中进行多重编码,每个EL对相应缩放的输入图像进行编码。需要注意的是,在COMPASS中,所有EL都使用相同的共享模块,每个EL都递归操作,这种方式提供了可扩展性,并且还减少了模型参数的数量。在BL中,最小尺寸的输入图像
被馈送到基于CNN的图像压缩模块中,以重构
。在第k个EL中,将对应的输入图像
和前一层的重构图像
馈送到当前增强层中以重构
。具体而言,在第k个EL中,层间任意尺度预测模块可以有效地估计和减少任意尺度因子图像的空间冗余度。因此,残差压缩模块仅对重构
得到的基本残差进行编码。COMPASS压缩第k层图像的过程可以被描述为:
在公式中,当
时:
其中,
表示BL的图像压缩模块,
指第k个EL的残差压缩模块,图像压缩模块和残差压缩模块采用了相同的结构。
表示从较低分辨率图像中重建得到的高分辨率的图像,这个过程是由LIFF实现的,
就代指LIFF的实现。对于图像压缩模块和残差压缩模块,因为图像大小会在卷积过程中不断二倍的下采样,需要提前将图像上采样为2的幂次,这会降低编码效率。因此,在卷积过程中进行分层填充,如果输入图像的宽度或高度在压缩模块的编码器部分的每个卷积层中是奇数,则执行大小为1的复制填充。在解码器部分的相应卷积层,对填充部分进行裁剪。
LIFF:层间任意尺度预测
这个部分的设计主要参考了图像超分领域两篇工作:Meta-SR和局部隐式图像函数(LIIF)。为了使用COMPASS实现高编码效率,有效减少相邻层之间的冗余是至关重要的。LIFF模块首先将前一层的重构图像
转换到特征域,然后通过简单的插值提高其分辨率以匹配任意放大的预测
。LIFF模块还为每个像素坐标生成颜色预测滤波器,然后通过将生成的滤波器应用于对应于目标像素坐标的提取到的特征切片来逐像素估计RGB颜色。LIFF模块的过程分为3个阶段:1)特征提取,2)滤波器生成,3)逐像素预测。
在特征提取阶段,通过类似RDN的特征提取器
从前一层的重构图像
中提取特征信息,并应用特征展开和最近邻上采样来生成特征图。在滤波器生成阶段,会通过一个MLP生成颜色预测滤波器。首先会将高分辨率图像对应位置的特征和空间坐标以及缩放因子进行串联。空间坐标对应于从低分辨率图像到高分辨率图像的位置映射,可以表示为
。其中
代表在高分辨率图像中的像素点的归一化坐标,
代表将高分辨率图像中的像素点投影到低分辨率图像上的归一化坐标。缩放因子
是一个固定值。在逐像素预测阶段,通过简单的矩阵乘法将颜色预测滤波器应用于生成的特征图,这个过程可以表示为
。在训练COMPASS时,每一层都会使用RD损失,模型的整体损失是每一层损失之和。
实验
作者在不同情况下比较了模型的性能:分别是固定比例因子为2的编码效率和任意比例因子的编码效率。对比的对象有SHVC,之前SOTA的基于神经网络的空间可缩放编解码方法,此外还比较的COMPASS中使用的图像压缩模型。对比时的不同设置分别称为Simulcast和Single-layer,Simulcast代表将不同分辨率的图像单独编码后,统计累计的码率与最大分辨率图像的PSNR。Single-layer代表只压缩最大分辨率图像,统计其码率与PSNR。Mean-scale和Factorized代表不同的图像压缩模型。测试数据集是Kodak。
固定比例因子为2
在这里,模型被设置为一个BL和两个EL,层间缩放比例为2。表一和图一显示了模型在率失真方面的编码效率性能。
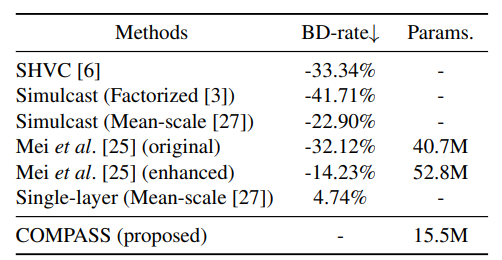
表1 固定比例因子为2时的编码效率和模型大小
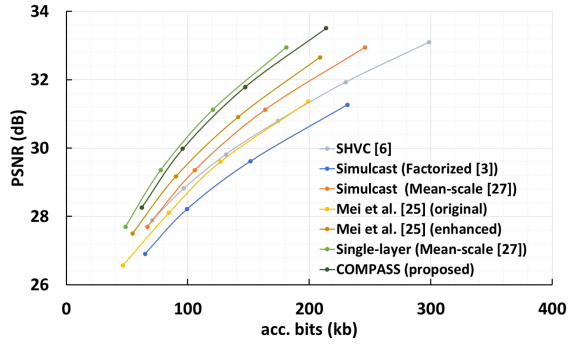
图2 模型的率失真曲线
从这些结果可以看出,COMPASS显著优于除Single-layer之外的所有空间可扩展编码方法。并且在模型大小上小于之前SOTA的结果。此外,令人印象深刻的是,COMPASS实现了与Mean-scale单层编码相当的结果。
任意比例因子
在这里进行了两种不同的实验,分别是单层任意比例因子放大和双层任意比例因子放大。对单层的情况,就是一个BL和一个EL,层间的放大因子分别为
和
。对双层放大的情况,就是一个BL和两个EL,BL和第一个EL之间的放大因子为
,而两个EL之间的放大因子(相对于BL)分别为
和
。因为SOTA的空间可扩展编码方法不支持除
以外的放大因子,这里使用双三次插值来提高或降低输出图像的比例,以与其他比例因子相匹配。具体结果可见表2和表3。
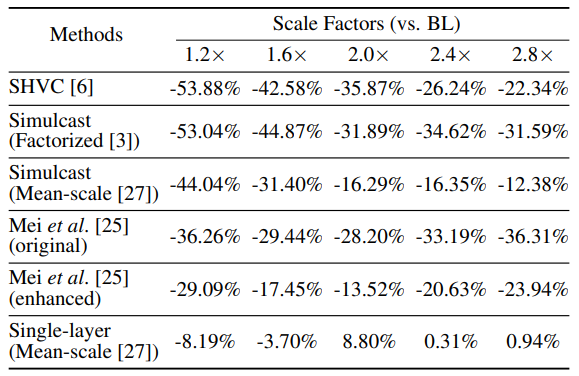
表2 单层放大的编码效率
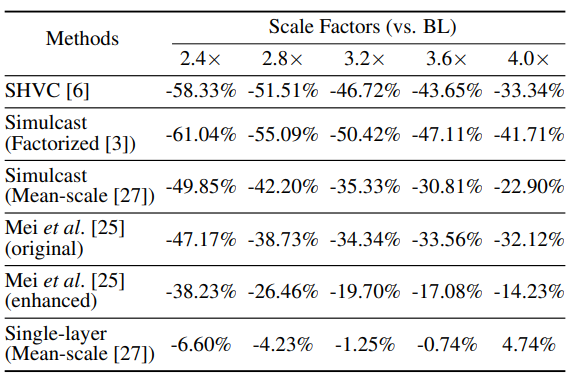
表3 两层放大的编码效率
从结果中可以看到,不论是几次放大,COMPASS在不同尺度因子的整个范围内显著优于所有空间可扩展编码方法,并且实现了与Mean-scale单层编码相当的结果。令人惊讶的是,COMPASS甚至在一些比例因子方面优于它。这是因为单层编码的输入图像需要填充到64的倍数,才能被处理到图像压缩网络的CNN架构中,这可能导致编码效率降低。而COMPASS的优势源于LIFF模块可以很好地对任意尺度因子进行层间预测
结论
本文提出了一种新的基于神经网络的空间可扩展图像压缩方法,称为COMPASS,该方法可以实现高编码效率,同时支持相邻层之间的任意尺度因子。为了提高模型的可拓展性,所有的增强层都共享LIFF模块和残差压缩模块,它们被递归地执行到更高的比例因子中。层间任意尺度预测采用LIFF模块,可以有效减少任意尺度因子的层间空间冗余。实验结果表明,在所有尺度因子组合的率失真性能方面,COMPASS显著优于SHVC、Simulcast编码和现有的基于神经网络的空间可扩展编码方法。COMPASS还使用了比现有的基于神经网络的空间可扩展编码方法更少的参数。可以说COMPASS是第一个在不同比例因子下,基于相同的图像压缩主干,在编码效率方面表现出与单层编码相当甚至更好的性能的作品。