原创 | 有趣的等待时间悖论


作者:贾恩东本文约1500字,建议阅读5分钟对生活中等待时间的平均值,有一个有趣的悖论,本文做一个通俗且深入的介绍。在生活中,你可能会时常遇到如下场景:
1. 购物时排队结账;
2. 等待下一班公交或者地铁;
3. 等待下一趟电梯;
4. 开车时在路口等待红绿灯 ……
以上场景发生时,我们通常不得不选择等一会,那关于这个等待时间的平均值,其实有一个有趣的悖论,本文中作者会对其做一个通俗且深入的介绍。
严谨些的定义:
1. 在一个周期性发生的事件中,其周期不固定,但平均周期为T;
2. 你以均匀的概率选择1个时间点(比如等公交时不借助APP实时观察车到站再选择出发);
3. 你在2中所选择的时间点距离下一次事件发生的等待时间为X 则,关于这个等待时间X,我们有如下结论:
4. 乍看这个等待时间X的期望应该是T/2;
5. 我们的生活经验告诉我们,这个X的均值很可能大于T/2;
乍看为何X=T/2,其实挺显然的,因为我们不妨在区间(0,T)上以均匀分布的概率选一个点x,x到右端点的距离的期望计算如下:

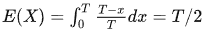
那为何我们日常的生活经验总觉得这个等待时间,经常大于事件平均周期的一半呢?是我们的错觉吗?我们不妨再用一个简单的程序模拟试试:
1. 我们假设T=10,事件发生了10000次,构建事件发生时刻的序列event_timer。

2. 我们检查一下,这个序列中,相邻事件发生的平均间隔是否等于10。

3. 我们开始模拟等待的时间。

4. 重复模拟500000次,计算等待的均值。

等待事件的均值居然近似等于事件的平均发生周期?说好的一半呢?

这就是等待时间悖论。
可能已经有聪明的读者想到是为什么了。
我们不妨再给大家举一个更容易看懂这种悖论来源的例子:你想考察一个学校的班级的平均学生数,于是就对学校的学生随机采样并询问他们的班级人数,最终对所有结果求均值。这样看起来容易,但真的没问题吗?
你会发现,学生人数更多的班级里的学生更容易被采样到,所以最终的统计结果比真实值偏大。
这种情况是由于我们的有偏采样(biased sampling)导致的。
我们不妨对之前的程序中,相邻事件发生的间隔时间画出分布直方图。我们已经知道,这个间隔的均值是T。

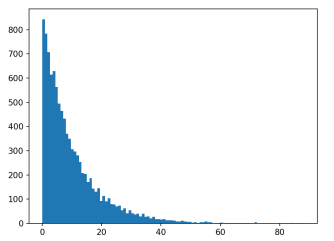
可以看出,这个分布很像指数分布,但其实我们在程序中,实际是把事件发生时刻做了一个均匀分布的生成,这其实就是一个泊松过程(之前作者已写过一文读懂系列中介绍过了泊松分布,这里就不再做介绍了),这个分布我们不妨写成:
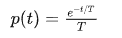
关于等待时间,其实就是在相邻事件间隔 t 上取 w,其概率可以如下简单得到:
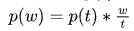
可以简单假设,等待时间 w 可以和事件间隔 t 的分布一致。我们为了验证这一说法,不妨对之前仿真得到的等待时间也画出一个分布直方图。

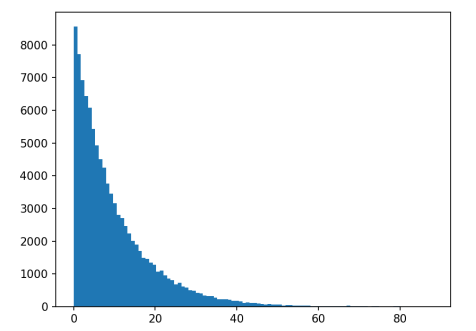
基本和我们大胆的推断一致。
所以等待时间的分布也是一个泊松分布,其期望就是相邻事件的间隔时间,而不是什么一半。当然了,这个假设都是建立在事件前后发生独立,事件发生时刻是一个均匀分布的前提下,即:泊松过程是一个无记忆过程。但在现实中,情况可能不会那么理想,比如,在公交或者地铁系统中,其有更具体的计划表,后一个事件的发生和前一个事件发生并非独立,因此我们的平均等待时间,会少于事件平均周期T,但却总是要大于这个平均周期的一半。
参考文章:
[1]The Waiting Time Paradox, or, Why Is My Bus Always Late? | Pythonic Perambulations (jakevdp.github.io)
编辑:于腾凯
校对:林亦霖
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-12-10,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号