R语言主成分、因子分析、聚类对我国城镇私营单位就业人员平均工资数据研究与分析
R语言主成分、因子分析、聚类对我国城镇私营单位就业人员平均工资数据研究与分析

数据显示2019年全国城镇私营单位就业人员年平均工资为53604元,比上年增长8.1%,而2019年全国城镇非私营单位就业人员年平均工资为90501元,名义增长率9.8%(点击文末“阅读原文”了解更多)。
相关视频
实际上,一直以来城镇私营单位就业人员年平均工资都要高于非私营单位,并且增长率也高与非私营单位,主要原因是非私营单位包括机关事业单位、国企、上市公司等。相对效益比较好,自然平均工资水平要高于私营企业。但是,这就会导致私营单位与非私营单位的平均工资差距持续扩大,富的越富,穷的越穷,公私单位工资分歧如果继续扩大,私营企业的竞争力将受到影响,对中国的科技创新和社会进步将构成阻碍。
我们帮助客户通过从不同行业,不同地区的私营单位就业人员平均工资的分析,给予具有针对性的政策建议,正确的引导私营企业向着快速发展的方向前进,这既是现实需要,也是共同富裕理念的需要。
数据准备
本文数据来自国家统计局中国统计年鉴,选自行业分城镇私营单位就业人员平均工资,相关经济指标有农、林、牧、渔业,制造业,电力、热力、燃气及水生产和供应业,建筑业,批发和零售业,交通运输、仓储和邮政业,住宿和餐饮业,信息传输、软件和信息技术服务业,金融业,房地产业,租赁和商务服务业,科学研究和技术服务业,水利、环境和公共设施管理业,居民服务、修理和其他服务业,教育,卫生和社会工作,文化、体育和娱乐业这17个经济指标。地区按省份划分,由于西藏地区数据具有较大缺失,因此选取了除台湾省以外的22个省份,4个直辖市,以及除西藏自治区以外的4个自治区,共30个地区的数据进行研究。
相关性分析
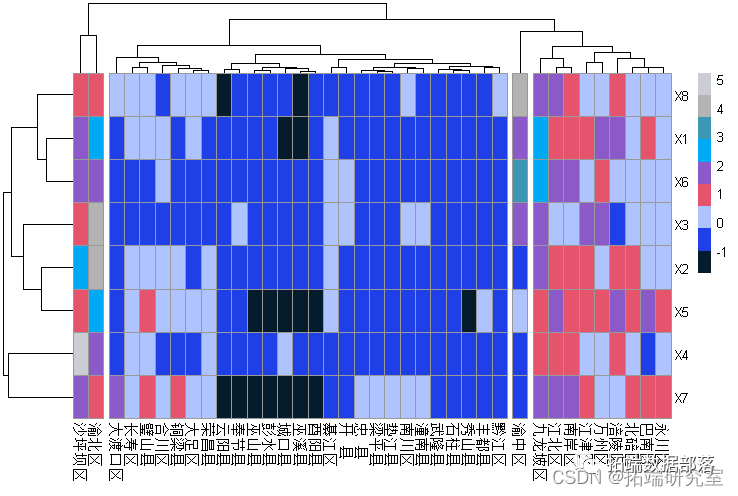
利用R软件绘制出原有变量的的相关系数饼图

从图中可以看出相关系数矩阵中大多数变量之间的相关系数取值较大,且从热力图的颜色可以判断变量间均为正相关关系,大部分变量间相关程度较高,满足进行主成分分析的前提。
02
03
04
确定主成分个数
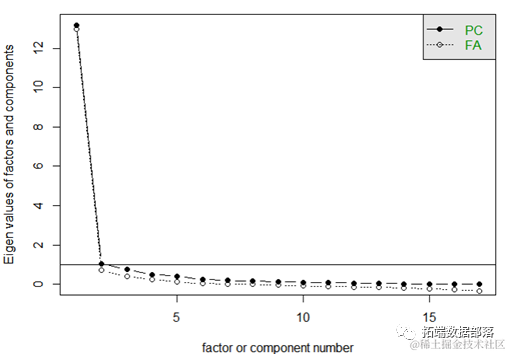
因此利用R语言中eigen()函数输出特征值,筛选出特征值大于1的主成分,从而计算贡献率与累计贡献率。
序号 | 特征值 | 贡献率% | 累计贡献率% |
|---|---|---|---|
1 | 13.192309813 | 77.6 | 77.6 |
2 | 1.035339791 | 6.1 | 83.7 |
其次,也可以通过scree()函数利用Cattell碎石检验绘制碎石图形,表明对于这组数据的描述只需要两个主成分即可。
因子分析
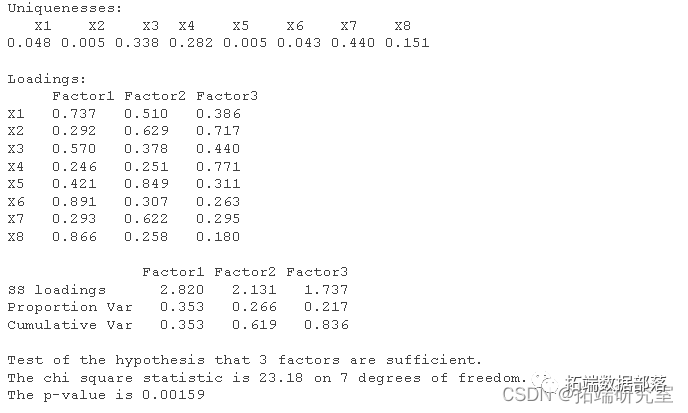
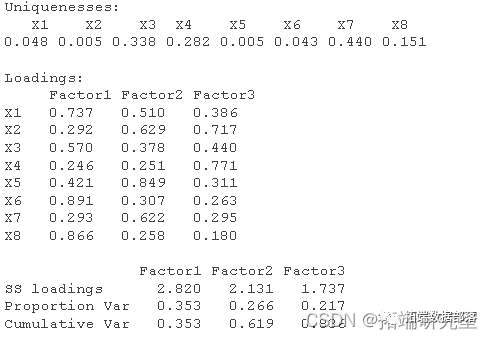
利用R语言principal()函数进行主成分分析,输出如下表结果。
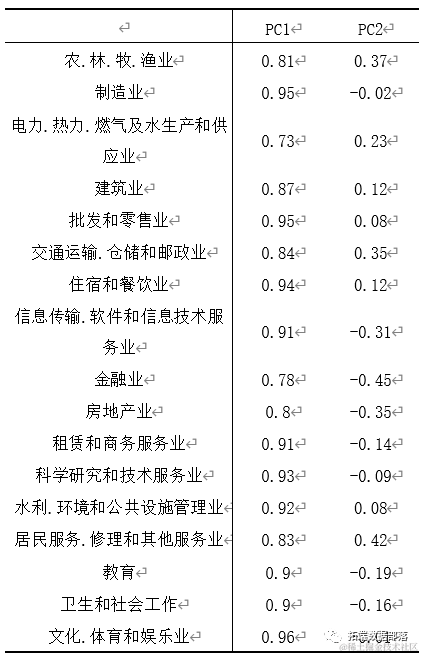
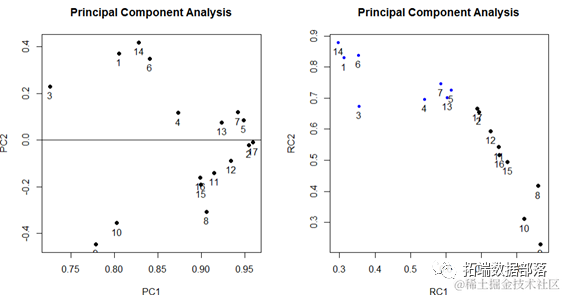
可以看出各个变量在第一主成分的因子载荷都很大,因此需要经过因子旋转才能对因子做相关的命名与解释,以便对实际问题进行分析。
本文采用的方法是方差最大的正交旋转法,使旋转后的因子载荷阵中的每一列元素尽可能地拉开距离,即向0或1两极分化。
利用fa.diagram()函数将经过最大方差的因子旋转后主成分结果进行展示,如下图。
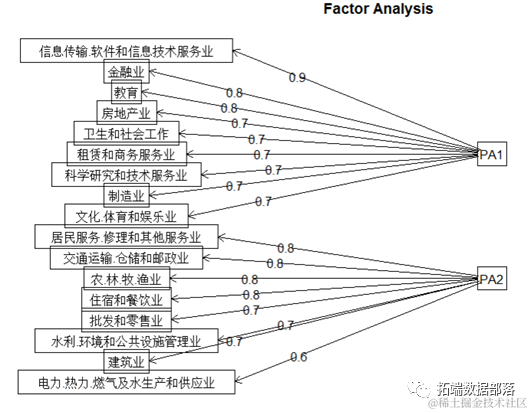
由结果展示可以看出,第一公因子的主因子的这些行业都是一些现代化产业,也就是随着科学技术的高速发展和人民生活水平的日益提高逐渐发展起来的,因此可以命名为新型行业;第二公因子保证了人民的基础生活,因此可以命名为基础行业。
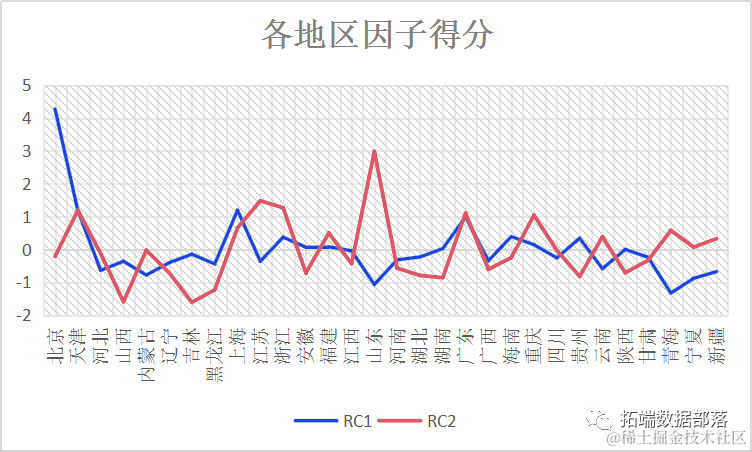
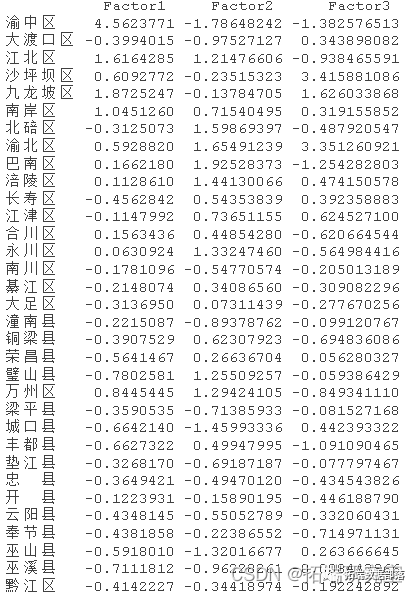
对于第一主成分来说,因子得分最高的城市为北京市,为4.27,远高于其他地区,说明北京市的新型行业发展较为发达,起到引领作用,得分最低的是青海地区,可见新型产业并不是青海省主要发展产业。对于第二主成分来说,因子得分最高的地区为山东省,为2.98,说明山东省的基础行业发展水平较高于其他地区,而基础产业发展最不好的地区为山西省。
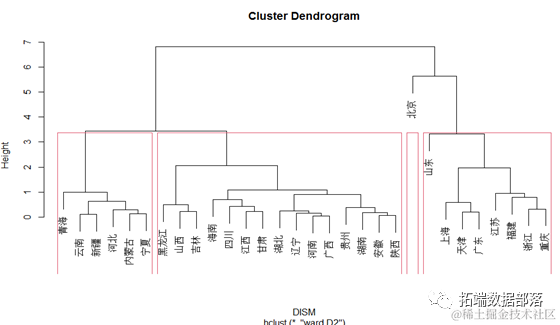
确定聚类个数
展示采用Ward最小方差法得出聚类结果。根据聚类树形图,可以初步设置聚类别的数目为4。
为了进一步确定聚类数目,绘制层次聚类碎石图。
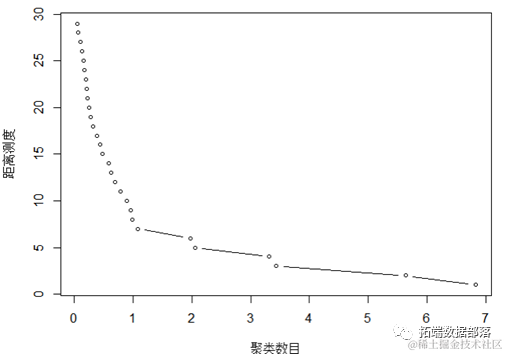
层次聚类碎石图也表明聚类数目为4较为合适。
K-means聚类
利用R软件输出每个类别的类数目与聚类中心,得到下表。
类别 | 类数目 | 新型行业 | 基础行业 |
|---|---|---|---|
1 | 1 | 4.2732372 | -0.2118294 |
2 | 7 | 0.3510077 | 1.3900181 |
3 | 8 | -0.6312877 | 0.2117078 |
4 | 4 | -0.1199993 | -0.8008542 |
各类包含的具体地区如下图
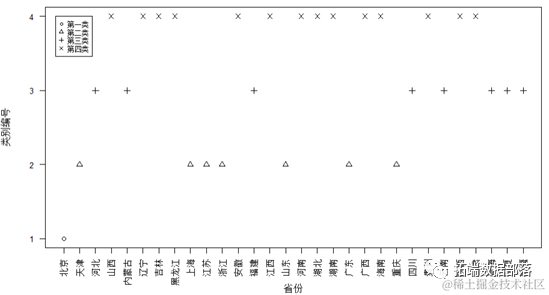
可以看出,北京作为第一类城市的代表,新型行业发展远远高于其他地区,不管是金融业,教育,房地产业还是科学研究和技术服务业、信息传输,软件和信息技术服务业等,都占据着领导地位。
第二类地区基础行业最为雄厚,有些地区属于新一线城市,具有较大的资源优势和相对好的人才质量,交通运输、仓储和邮政业,批发与零售,住宿与餐饮业,建筑业都较为发达。
第三类地区位于内陆地区,部分地域广阔,资源丰富,基础行业发展状况尚可,但新型行业发展欠缺,缺乏高新技术的支持,各地区要重视对科技的投入,完善创新机制,发挥人才优势。
第四类地区既没有资源优势也没有人才优势,因此新型行业和基础行业都处于有待发展的状态。
类别 | 地区 |
|---|---|
第一类地区 | 北京 |
第二类地区 | 天津、上海、江苏、浙江、山东、广东、重庆 |
第三类地区 | 河北、内蒙古、福建、四川、云南、青海、宁夏、新疆 |
第四类地区 | 山西、辽宁、吉林、黑龙江、安徽、江西、河南、湖北、湖南、广西、海南、贵州、陕西、甘肃 |
关于分析师

在此对Huarui He对本文所作的贡献表示诚挚感谢,她专注机器学习、SQL、数据采集领域。擅长R语言、Python、Eviews、SPSS。