数据挖掘实战:聚类分群实现精准营销

数据挖掘实战:聚类分群实现精准营销

Python数据科学
发布于 2023-12-13 16:01:04
发布于 2023-12-13 16:01:04
本次分享一个通过聚类实现精准营销的实战项目。
风控中分群介绍
本实战案例介绍如何通过无监督的聚类算法对银行客户进行分群。所谓物以类聚,人以群分,有相似属性、行为特征等的客户就可以聚合为一类人群。在信贷风控中,聚类分群多应用于没有Y标签的场景,如反欺诈、客户画像等。
以反欺诈为例,现在我们想抓出黑产,但有没有Y标签无法使用监督学习训练模型,这时就可以先找出有可能识别出黑产的一些特征数据,比如设备信息、行为操作信息、地址信息等,通过聚类算法就可以将操作频率高、地址切换频率高这种异常行为的人群归为一类,从而打出黑产的标签。
当然,此时的标签还有待考证,但至少是一种维度的参考,可以参与到策略的使用中,比如我们可以将黑产标签设计成一个弱规则,与其他规则组合使用来判断客户风险。通过上线的监测观察来检验标签的识别效果。
再比如,我们现在有客户的基础属性、业务等画像数据,想对客户的价值高低进行识别,从而能够有针对性的进行产品营销。此时同样可以通过聚类划分出对业务影响不同程度的客群,然后再以此设计策略。
数据&需求
以下数据为银行客户的信息和业务画像数据,营销策略部的业务需求是拟通过聚类对客户价值进行分层,以此设计营销白名单。
df = pd.read_excel('cluster_split_sample.xlsx')
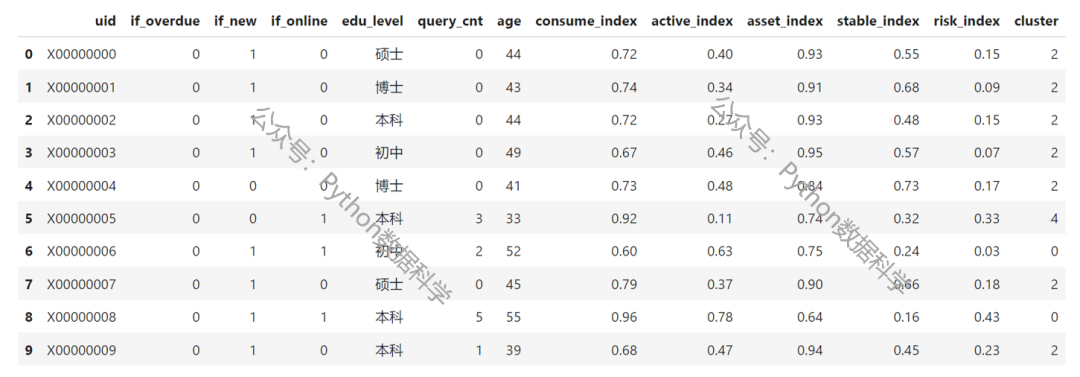
字段含义:
- if_new:是否为新客,1代表新客,0代表老客
- if_online:是否为线上渠道进件,1代表线上,0代表线下
- edu_level:学历,包括初中、高中、本科、硕士、博士
- query_cnt:近12个月征信机构查询次数
- age:年龄,20到60岁
- consume_index:消费指数,对个人信用卡、三方支付等渠道的消费能力评估,越高代表消费能力越强
- active_index:平台活跃指数,对个人在平台行为的活跃度描述,越高代表活跃度越高
- asset_index:资产指数,对个人存款、理财、股票、期货等金融资产的加总评估,越高代表资产越大
- stable_index: 稳定指数,对联系方式、地址、职业的综合稳定性评估,越高代表越稳定
- risk_index:风险指数,对个人消费贷、房贷、车贷、经营贷的综合风险评估,越高代表风险越大
Kmeans聚类
聚类有很多算法,比如kmeans、Hierarchical、DBSCAN、Spectral、GMM等,这里选择比较常用的kmeans算法。
聚类簇数
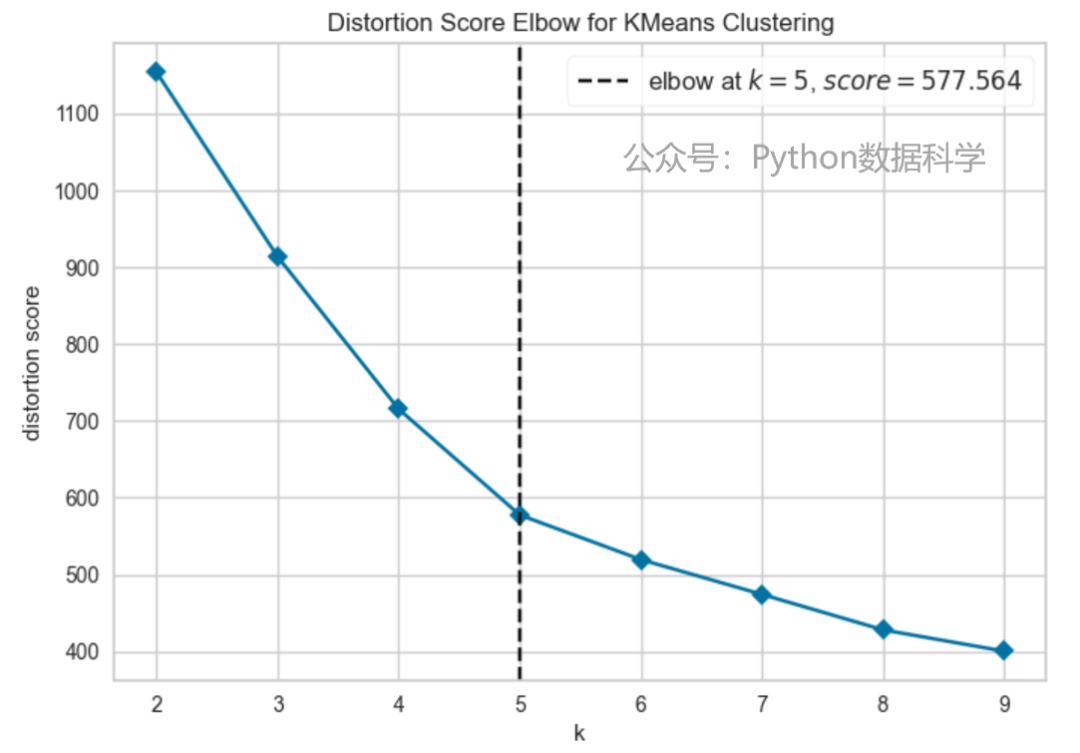
kmeans聚合的关键是选取合适的簇,也就是分群的数量。下面通过肘部拐点法和轮廓系数的分析进行筛选。
使用yellowbrick进行拐点可视化分析。遍历了2到10的簇数,然后给出最优拐点为5的结果。
from yellowbrick.cluster import KElbowVisualizer
n_min = 2
n_max = 10
model = KMeans(init = 'k-means++', random_state = 40)
visualizer = KElbowVisualizer(model, k=(n_min,n_max), timings=False)
# 可视化
visualizer.fit(df_clu)
visualizer.show()
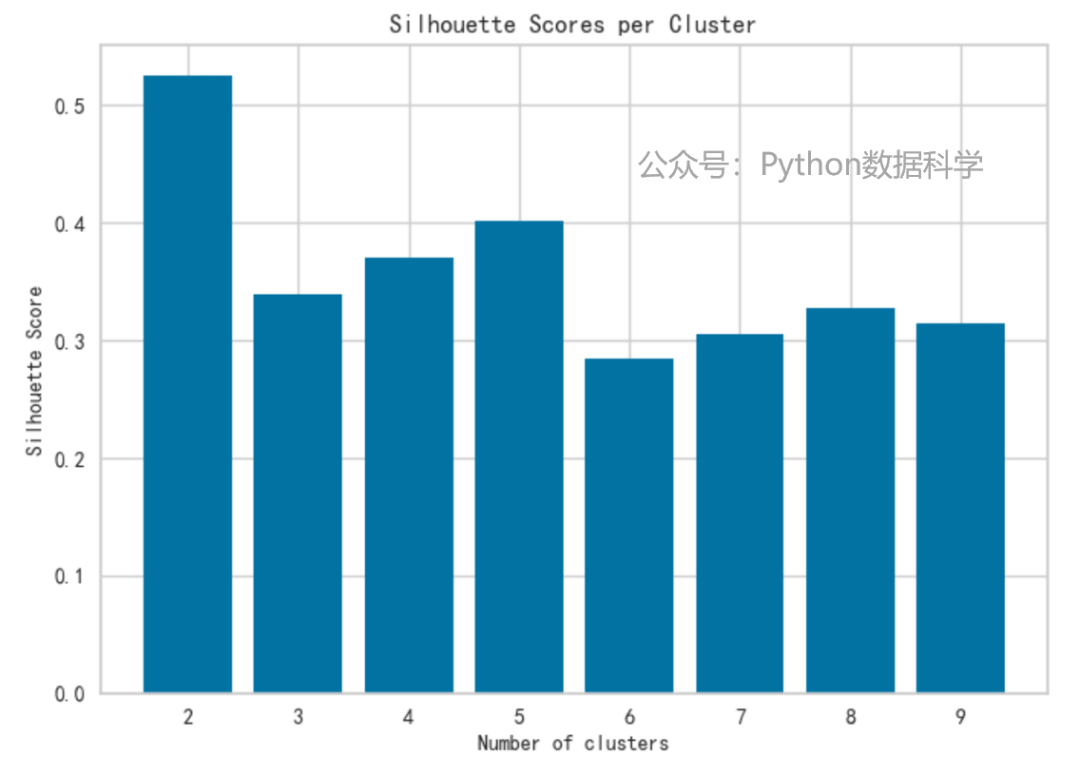
然后,计算轮廓系数并进行可视化。可以看到,除了1以外最好的结果也是5。
silhouette_scores = []
for cluster in range(n_min,n_max):
kmeans = KMeans(n_clusters=cluster, random_state=40).fit_predict(df_clu)
sil_score = metrics.silhouette_score(df_clu,kmeans, metric='euclidean')
silhouette_scores.append((cluster, sil_score))
# 可视化对比结果
plt.bar([a for a,_ in (silhouette_scores)], [b for _,b in (silhouette_scores)])
plt.title ('Silhouette Scores per Cluster')
plt.xlabel('Number of clusters', fontsize = 10)
plt.ylabel('Silhouette Score', fontsize = 10)
plt.show()
构建模型
确定用5作为最终的簇数,并将数据输入到kmeans聚合算法构建模型。
n_clu = 5
model = KMeans(n_clusters=n_clu, random_state=40)
# 给每个样本输出分类
df['cluster'] = model.fit_predict(df_clu)
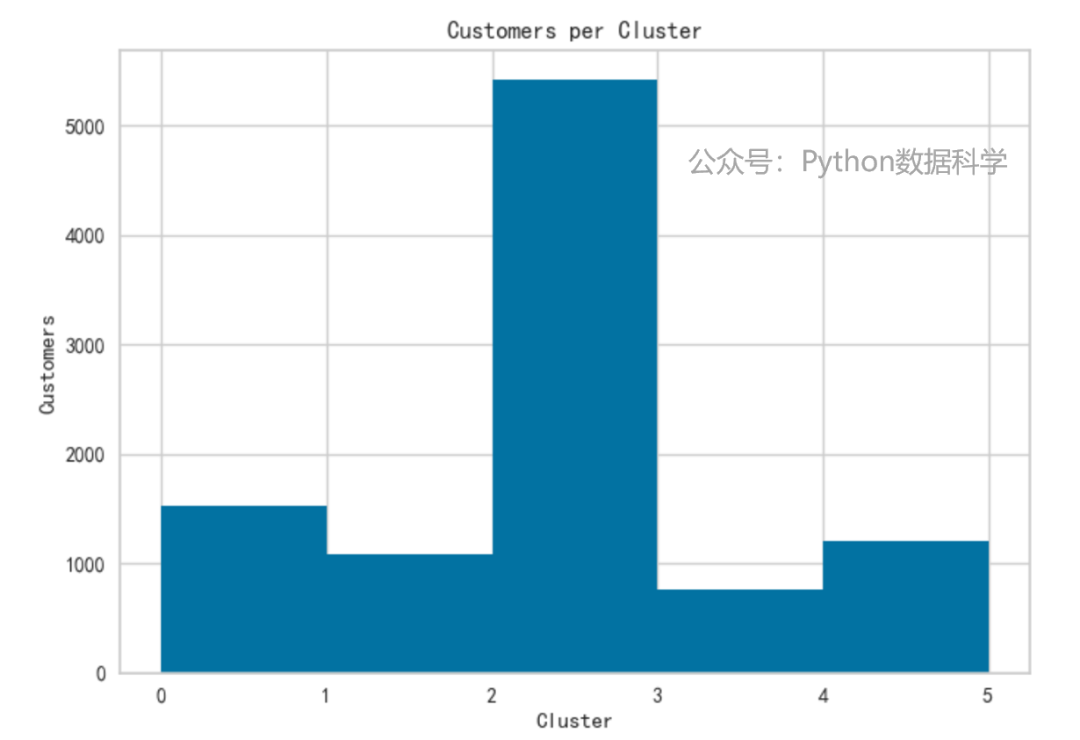
得到聚类以后,首先来看下各类下的样本数量占比分布。
# 群簇数量分布可视化
plt.hist(df['cluster'], bins=range(n_clu+1))
plt.title ('Customers per Cluster')
plt.xlabel('Cluster')
plt.ylabel('Customers')
plt.show()
可以看到,没有数量特别少的类别,分群3的占比是最多的。
类别分析
为了证实我们的分群是有起到分层效果的,对分群下的各个维度特征进行可视化分析,对比各分群的差异。
# 分群后的画像特征
plt.figure(figsize=(10,10))
for i in range(0,len(index_lst)):
plt.subplot(3, 2, i+1)
sns.barplot(x='cluster',y=index_lst[i],data=df, palette="husl")
plt.title(index_lst[i])
plt.tight_layout()
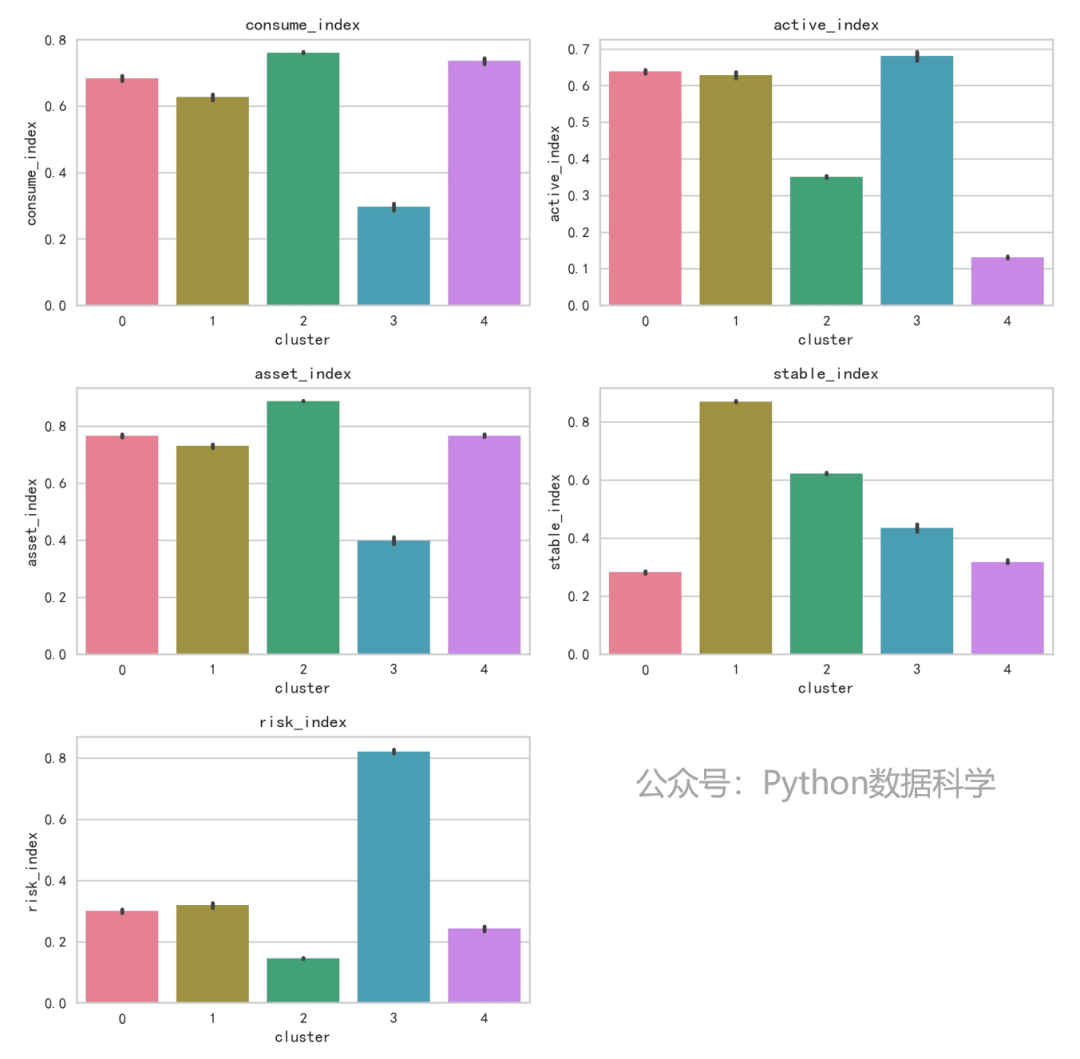
# 各分群下的指数分布
for column in index_lst:
plt.figure(figsize=(15,3))
for i in range(0,n_clu):
plt.subplot(1,n_clu,i+1)
cluster = df[df['cluster']==i]
cluster[column].hist(color="g")
plt.title('{} \n{}'.format(column, i))
plt.tight_layout()
plt.show()
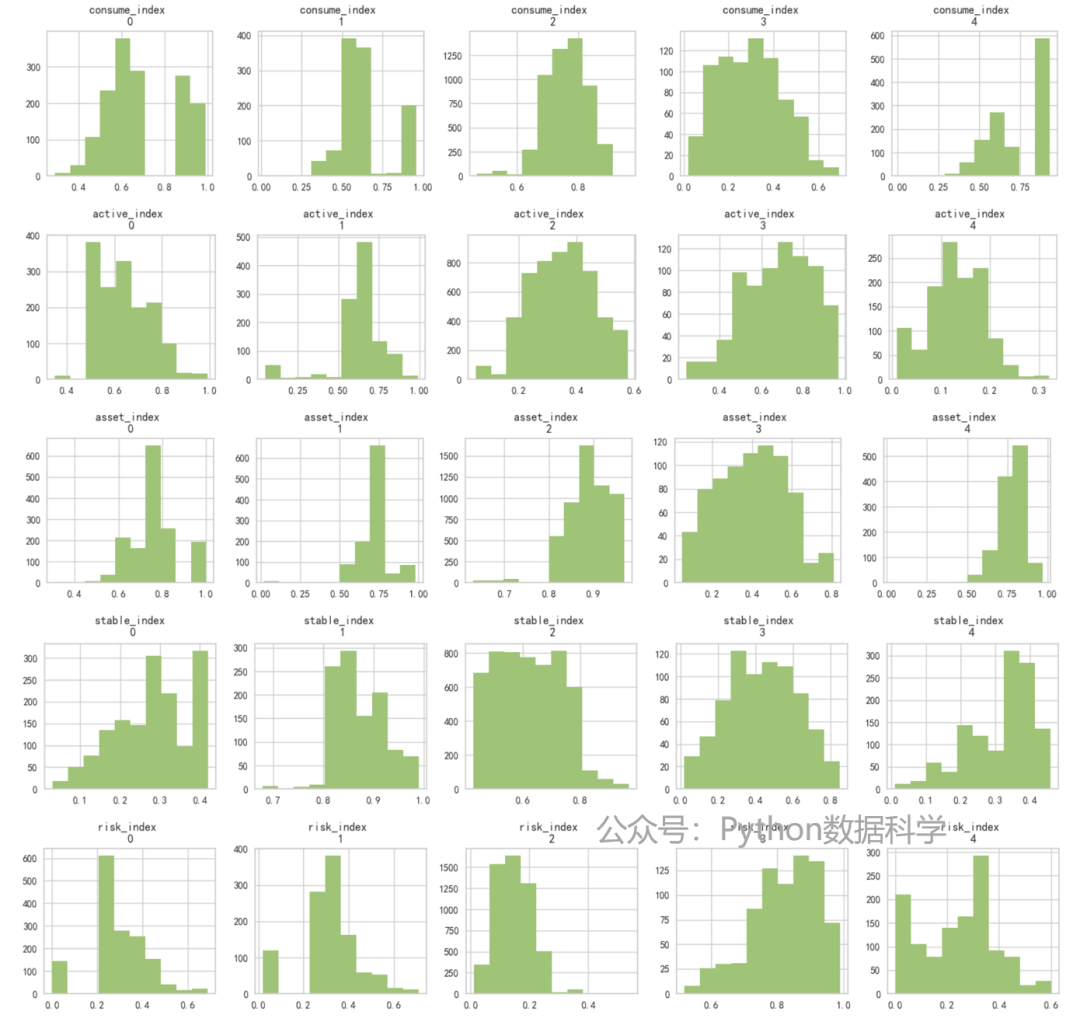
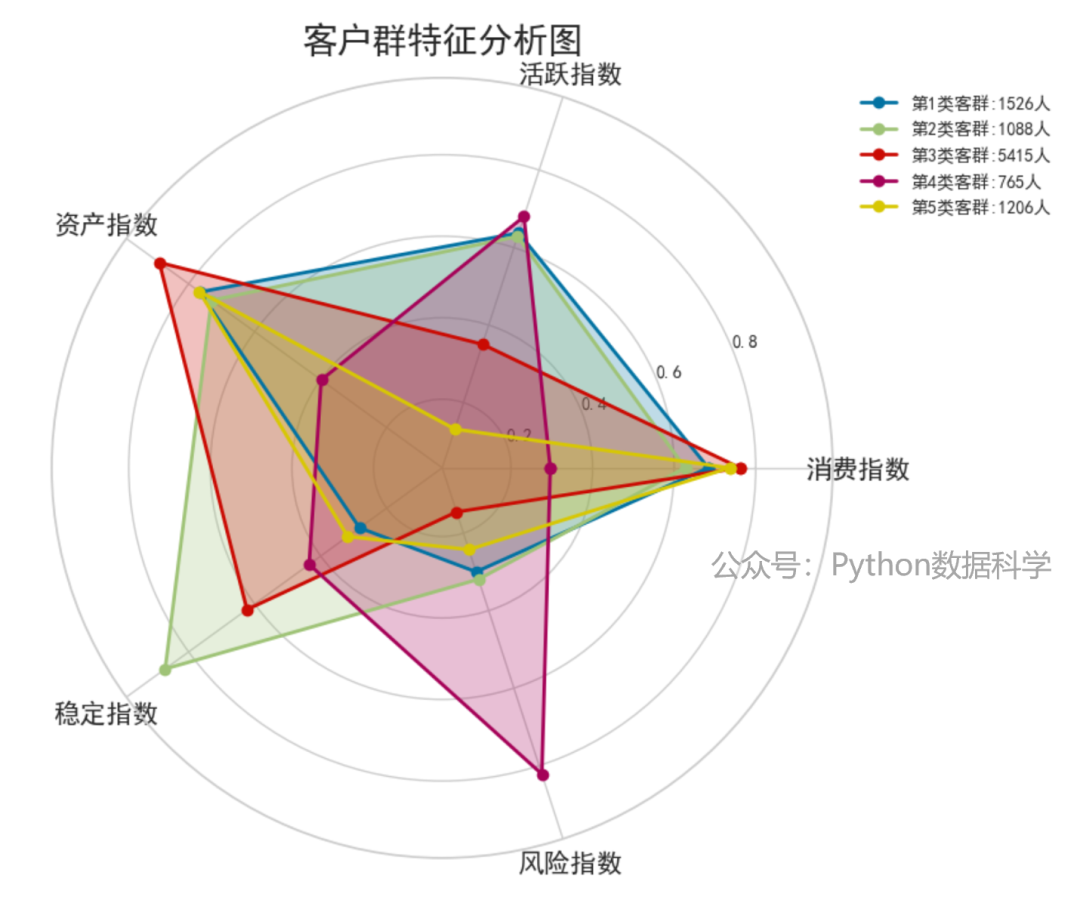
通过以上可视化结果,我们对5个类定义出不同的特征表现,并用雷达图进行效果展示。
r1 = pd.Series(model.labels_).value_counts() # 统计各个类别的数目
r2 = pd.DataFrame(model.cluster_centers_) # 找出聚类中心
r = pd.concat([r2, r1], axis=1) # 得到聚类中心对应的类别下的数目
r.columns = index_lst + [u'类别数目'] # 重命名表头
max = r2.values.max()
min = r2.values.min()
# 绘图
fig=plt.figure(figsize=(10, 8))
ax = fig.add_subplot(111, polar=True)
center_num = r.values
feature = ["消费指数","活跃指数","资产指数","稳定指数","风险指数"]
N =len(feature)
for i, v in enumerate(center_num):
# 设置雷达图的角度,用于平分切开一个圆面
angles=np.linspace(0, 2*np.pi, N, endpoint=False)
# 为了使雷达图一圈封闭起来,需要下面的步骤
center = np.concatenate((v[:-1],[v[0]]))
angles=np.concatenate((angles,[angles[0]]))
# 绘制折线图
...
# 设置雷达图的范围
ax.set_ylim(min-0.1, max+0.1)
# 添加标题
plt.title('客户群特征分析图', fontsize=20)
# 添加网格线
ax.grid(True)
# 设置图例
plt.legend(loc='upper right', bbox_to_anchor=(1.3,1.0),ncol=1,fancybox=True,shadow=True)
# 显示图形
plt.show()
# plt.savefig("客户群特征分析图.jpg",dpi=200)
价值分层&策略设计
在对分群特征分析之后,可以判断出不同客群的典型特征,结合对业务的理解划分出不同价值程度的分类。
- 客群5:消费能力强、资产质量好、风险低,活跃度极差,是需要重点挽留的高价值客群;
- 客群3:消费能力强、资产质量好、风险低,活跃度较差,是需要促活的高价值客群;
- 客群2:风险中低,资产、消费、活跃均衡,稳定性高,是需要继续维持的中高价值客群;
- 客群1:与客户群2类似,但稳定度差一些,是需要继续维持的中高价值客群;
- 客群4:高风控的下沉人群,同时活跃度较高,存在多头的风险,是需要避免的高危低价值客群;
业务或者策略人员可以针对这个分层设计相应的营销策略。
客群 | 特点 | 策略建议 |
|---|---|---|
客群5 | 高价值,但不活跃 | 重要挽留,给这类客户筛出为白名单,调整产品权益如提高额度、降低利率,进行电话营销防止流失 |
客群3 | 高价值,中等活跃 | 重要发展,临到期客户提前电话营销促成复购;对已到期存量客户通过PUSH、短信推送营销活动 |
客群2&客群1 | 中高价值、中等活跃 | 重要维持,临到期客户提前电话营销促成复购;对已到期存量客户通过PUSH、短信推送营销活动 |
客群4 | 低价值,高风险,高活跃 | 不考虑营销此类客群,如果有高利率产品进行下探,可以小范围内尝试,进行适当的回捞 |
--end--
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2023-12-12,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号