Qmatey:一个用于宏基因组快速精确匹配比对和菌株水平分类分级的自动化流程
Qmatey:一个用于宏基因组快速精确匹配比对和菌株水平分类分级的自动化流程

宏基因组学是理解生物体相互作用的强大工具;然而,在菌株水平上对相互作用进行分类、分析和检测仍然是一项挑战。2023年10月,《Briefings in Bioinformatics》发表了一种自动分析流程——定量宏基因组比对和分类精确匹配(Qmatey),可执行基于精确匹配的快速比对,并整合分类分级和分析。

Qmatey是什么?

Qmatey是一个宏基因组自动分析流程,可执行基于精确匹配的快速比对,并整合分类分级和分析。其无需使用限制分辨率的宏基因组组装的基因组、整理后的泛基因或限制分辨率的k-mer spectra,即可查询大型数据库。Qmatey通过仅使用扩增子、定量简化测序和鸟枪测序数据集分析中显示的diagnostic reads,最大限度地减少了错误分类,并保持了菌株水平的分辨率。
Qmatey解决了目前宏基因组分选和分析的局限性,包括菌株水平和分类群落基因相似时的性能不佳。为了缓解灵敏度更高的MegaBLAST 配对工具速度较慢的问题,Qmatey采用了优化的多处理 MegaBLAST。
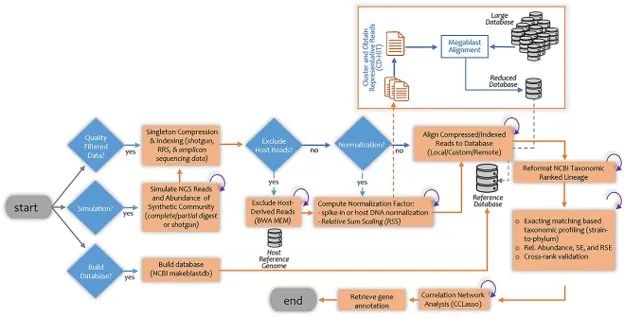
Qmatey流程图
Qmatey的性能测试
开发团队利用多个数据库和三种微生物组/元基因组测序方法介绍了 Qmatey 的实用性。
使用Qmatey分析来自一个合成群落的鸟枪数据,其中26种菌株中有35%处于低丰度(0.01-0.06%),在保持100%精度的同时,菌株水平召回率为85-96%,种水平召回率为92-100%。基准测试结果表明,排名靠前的Kraken2和 KrakenUniq工具比Qmatey多识别出2-4个分类群(召回率为 92-100%),但却产生了 315-1752个假阳性分类群,并对精确度造成了很高的影响(1-8%)。
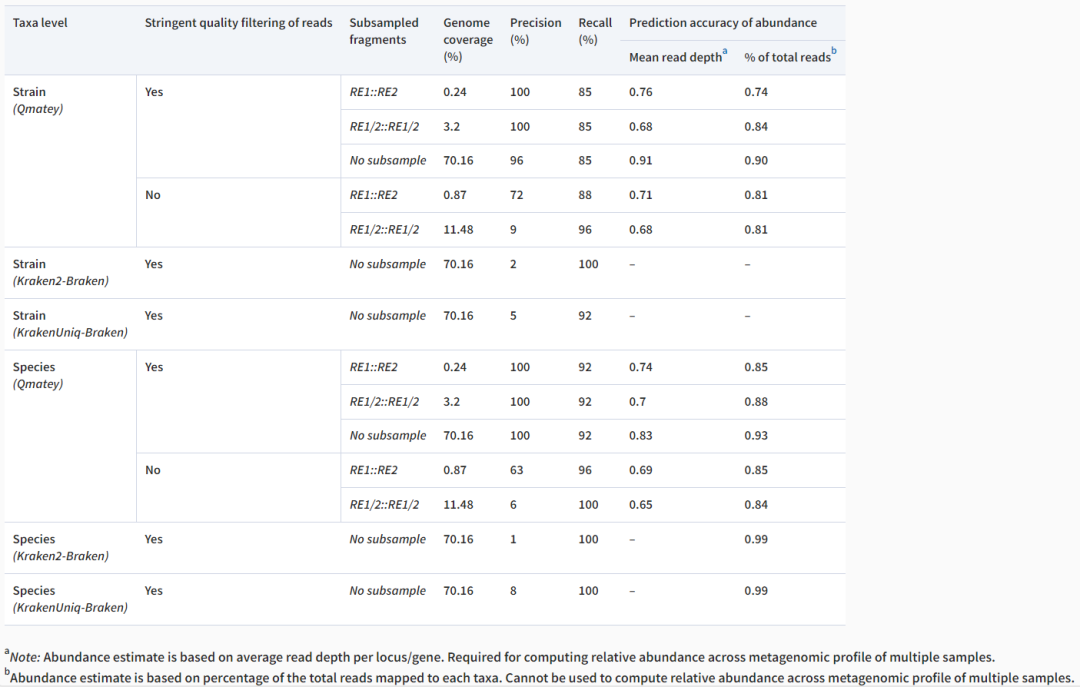
使用MBARC-26模拟群落实验数据在不同的二次采样覆盖率下Qmatey得出的宏基因组图谱的质量指标。
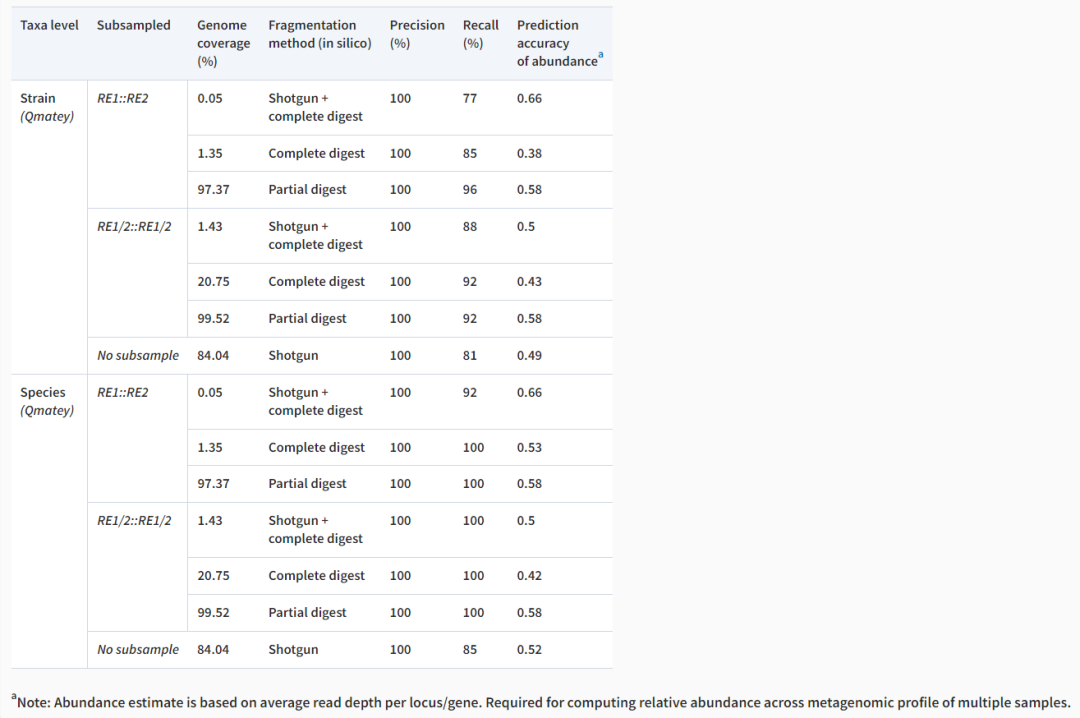
使用MBARC-26模拟群落模拟NGS数据在不同二次采样覆盖率下Qmatey宏基因组图谱的质量指标。
与其他工具相比,Qmatey对所有微生物组/宏基因组数据类型都具有稳定性,并在单个分析流程中实现了分组和分析。
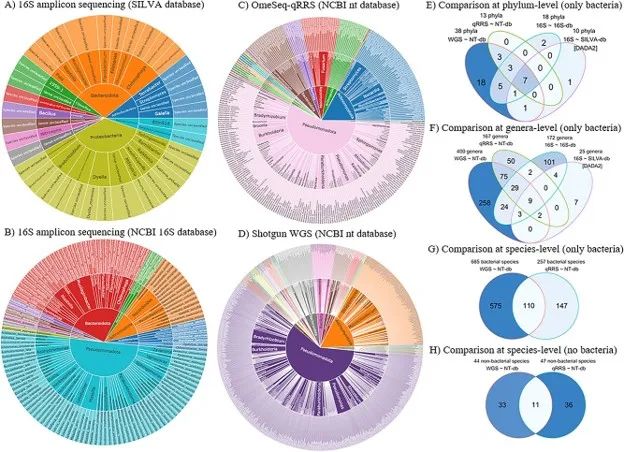
Sunburst显示了利用DADA2 (A)和Qmatey (B) - (D)在种水平(从中心到外环:门、属和种)鉴定的分类群多样性。
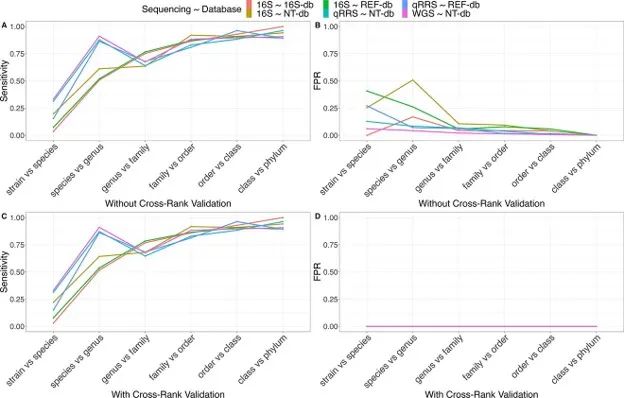
基于3种宏基因组测序方法(16S扩增子、OmeSeq-qRRS和鸟枪测序)和5个数据库(NCBI 16S、nt、RefSeq和16S SILVA数据库)的数据,建立宏基因组图谱的质量指标(灵敏度、假阳性率和鉴定的类群数量)。
Qmatey 宏基因组分类和分析流程的优点和缺点
优点
1)程序界面友好,易于使用,结果可重复。可进行分类(分类)和剖析(检测和量化)。
2)可分析来自各种宏基因组/微生物组测序方法(全基因组鸟枪、16S/ITS扩增子和简化基因组测序)的数据。分析时还可将高代表性宿主基因组排除在比对之外(提高速度)。
3)菌株级分类/分析,具有高召回率和丰度预测准确率。
4)对diagnostic reads的识别可实现高精度,而不会影响召回率。
5)可灵活查询大型数据库和小型/定制数据库。还可以利用分类群信息自动从快速序列构建数据库。
6)尽管MegaBLAST算法的计算强度更大,但 Qmatey比大多数工具都要快。它将 MegaBLAST 的速度提高了数百到数千倍。此外,对鸟枪数据进行二次采样可将速度提高约 1000 倍。
7)在不需要Spark集群的情况下,多节点运行单个作业提交。
缺点(以及Qmatey中部分缓解问题的方法)
1)数据库中的错误、偏差、错误注释和丢失分类群可能导致假阳性和假阴性。
解决方案:识别diagnostic reads可有效缓解一些数据库问题。例如,基因组组装中的水平转移基因和污染性reads将不具有诊断性,不能用于分类学分类。
2)质量过滤宽松的序列读取(即高碱基检出错误)可能会导致假阳性率。
解决方案:增加严格的质量过滤以解决这一问题。
Qmatey管道是用bash和R脚本语言(不包括依赖项)编写的。它是开源的,可在github上获取,并附有从扩增子、鸟枪和简化测序策略中获取的一整套示例数据集:
👉 https://github.com/bodeolukolu/Qmatey.
参考文献
Alison K Adams, Brandon D Kristy, Myranda Gorman, Peter Balint-Kurti, G Craig Yencho, Bode A Olukolu, Qmatey: an automated pipeline for fast exact matching-based alignment and strain-level taxonomic binning and profiling of metagenomes, Briefings in Bioinformatics, Volume 24, Issue 6, November 2023, bbad351, https://doi.org/10.1093/bib/bbad351
腾讯云开发者
