每日学术速递1.1


CV - 计算机视觉 | ML - 机器学习 | RL - 强化学习 | NLP 自然语言处理
点击下方卡片,关注「AiCharm」公众号
Subjects: cs.CV
1.UniRef++: Segment Every Reference Object in Spatial and Temporal Spaces

标题:UniRef++:分割时空空间中的每个参考对象
作者:Jiannan Wu, Yi Jiang, Bin Yan, Huchuan Lu, Zehuan Yuan, Ping Luo
文章链接:https://arxiv.org/abs/2312.15715
项目代码:https://github.com/FoundationVision/UniRef
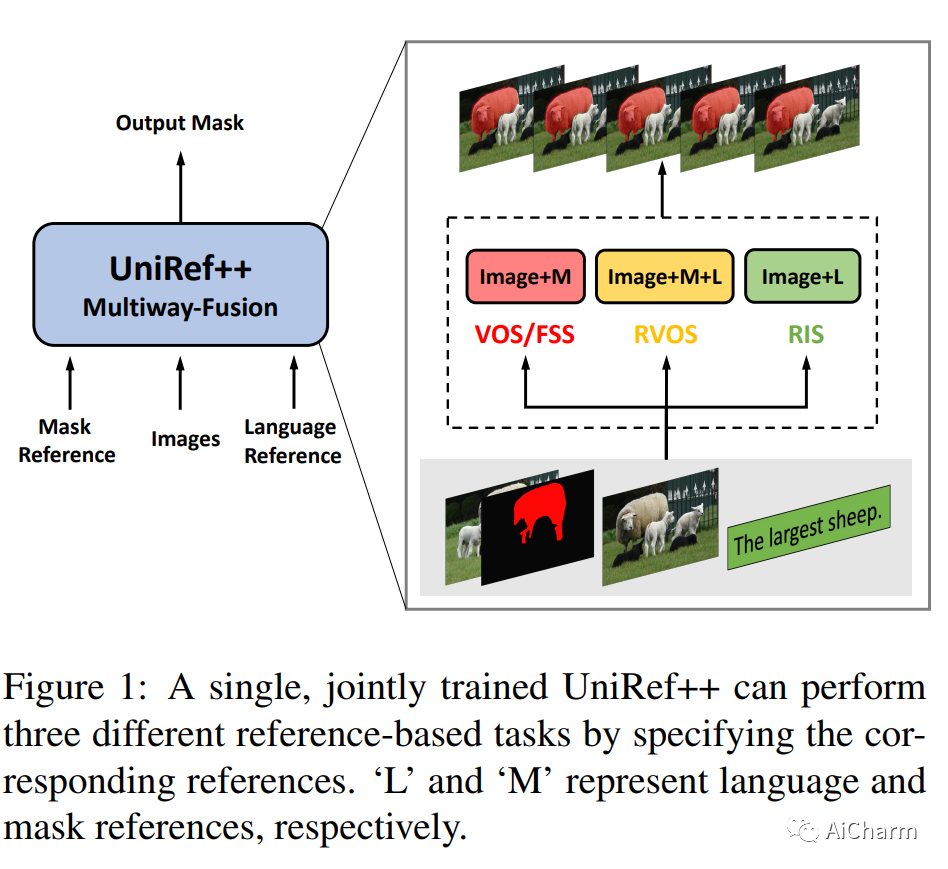

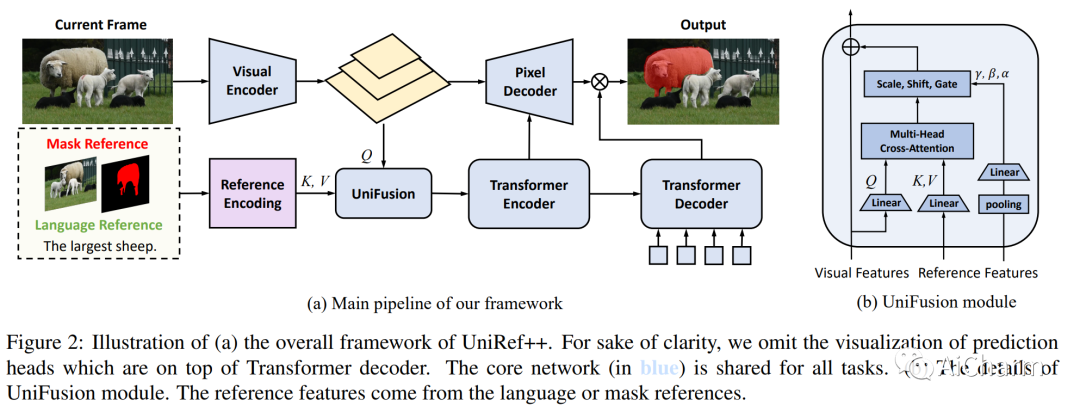
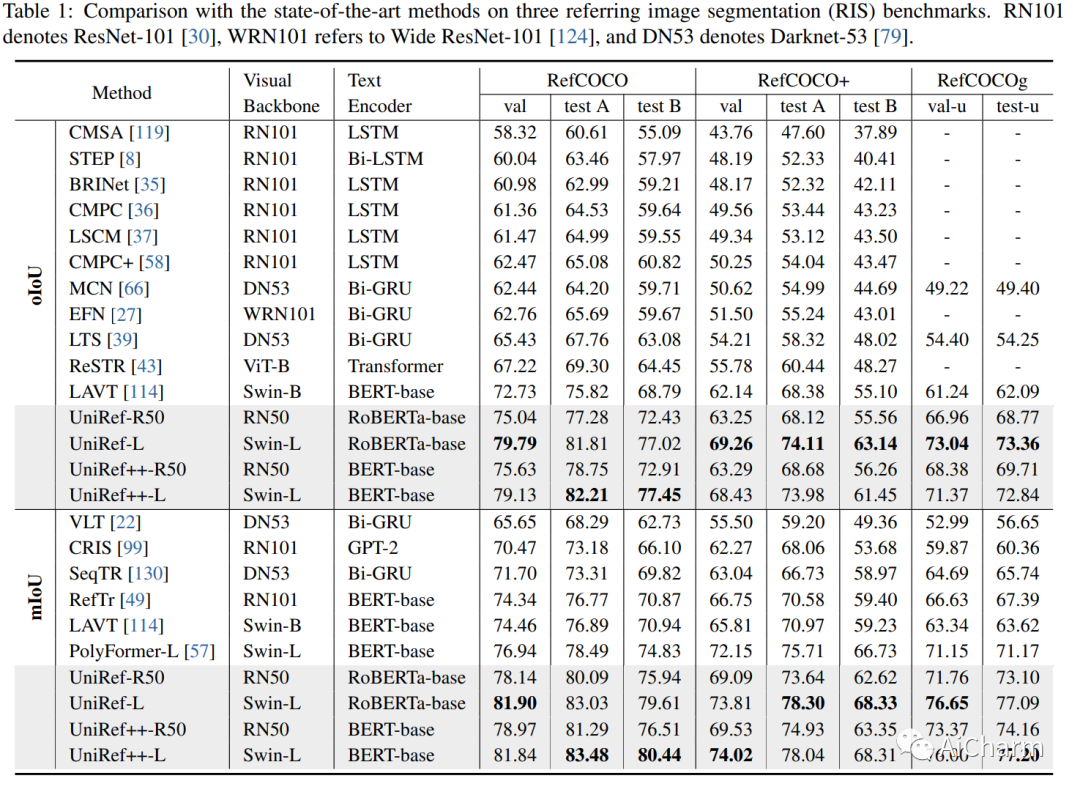
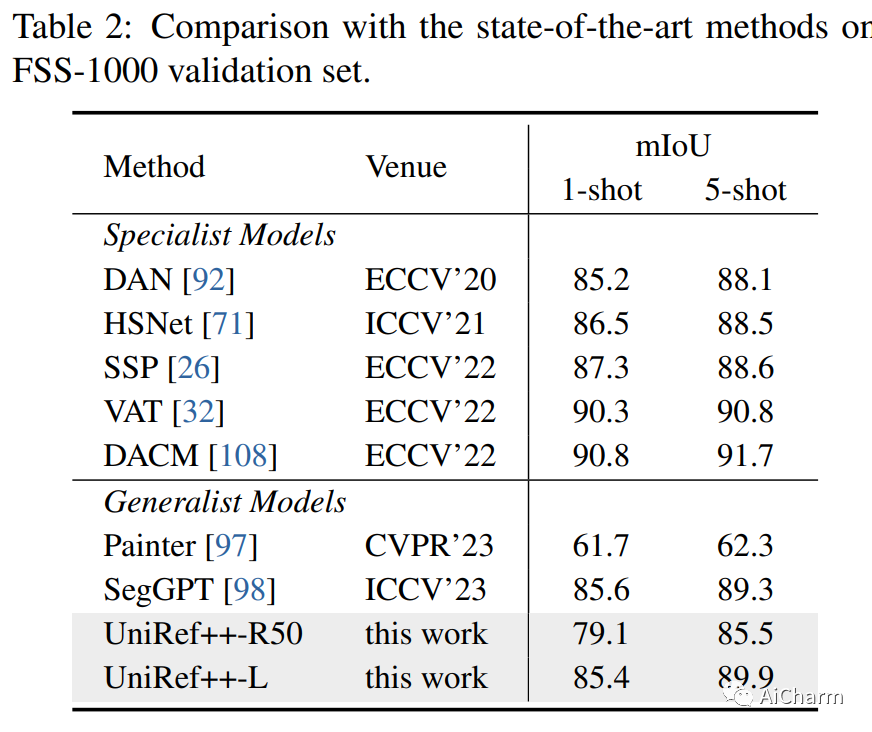

摘要:
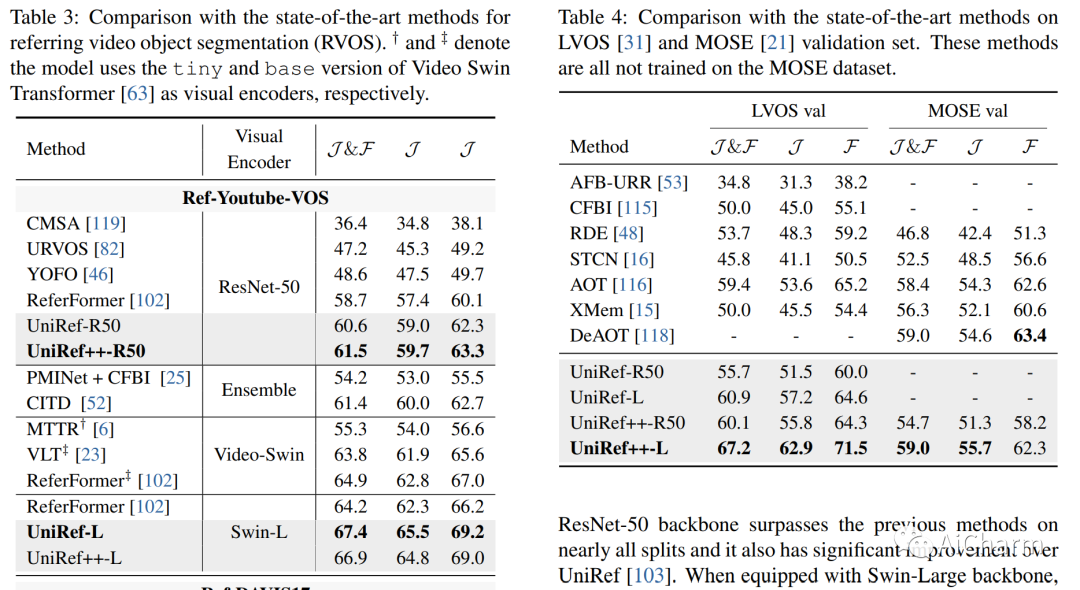
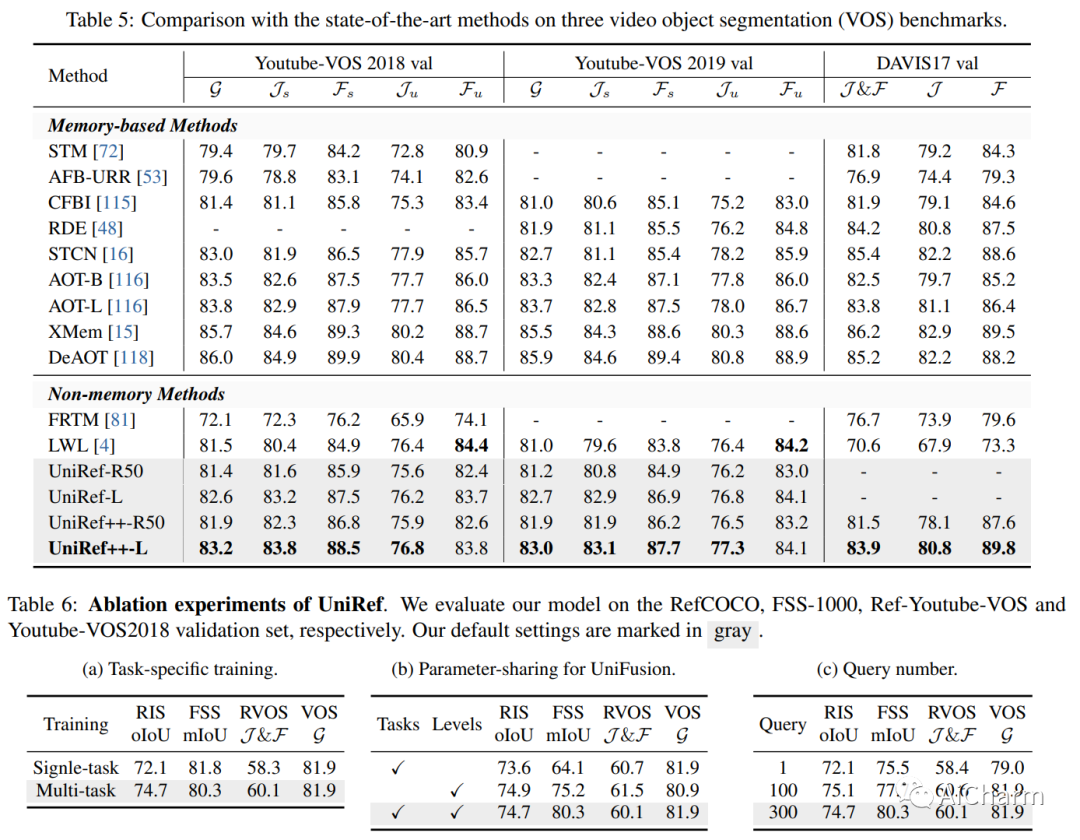
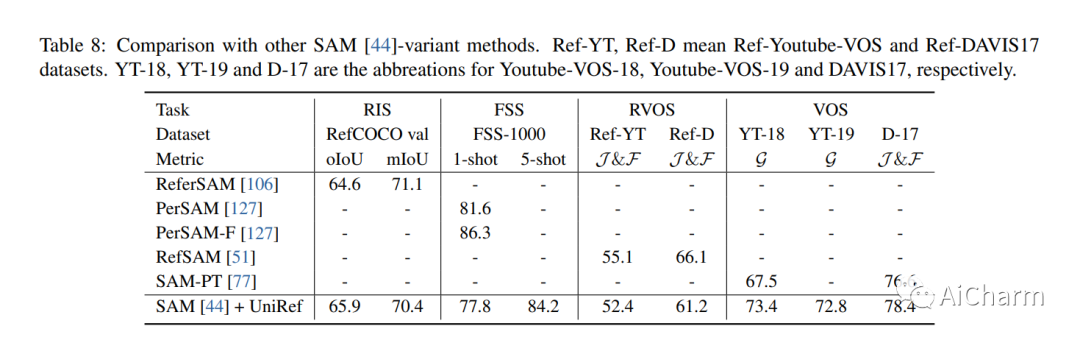
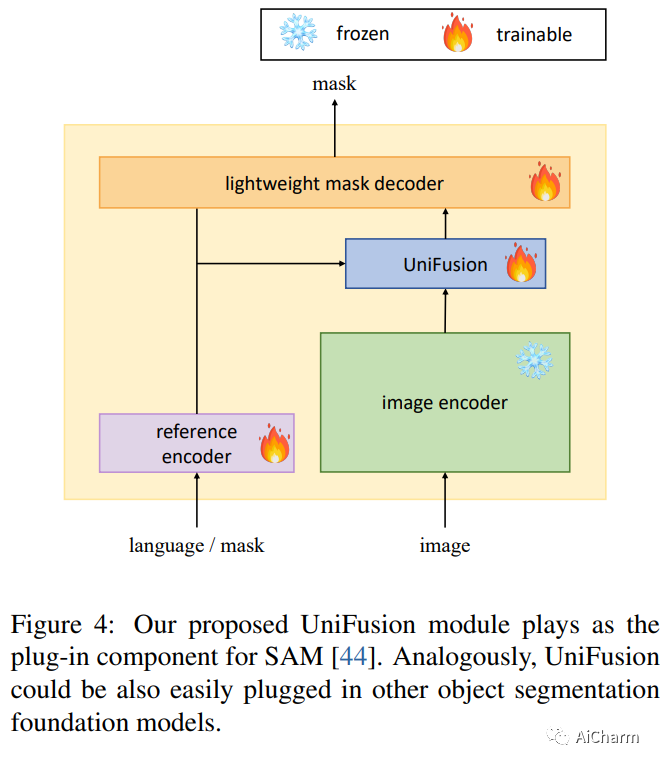
基于参考的对象分割任务,即参考图像分割(RIS)、少镜头图像分割(FSS)、参考视频对象分割(RVOS)和视频对象分割(VOS),旨在通过利用以下任一方法来分割特定对象:语言或带注释的掩码作为参考。尽管各个领域都取得了重大进展,但当前的方法是针对特定任务设计和朝不同方向开发的,这阻碍了这些任务的多任务能力的激活。在这项工作中,我们结束了当前碎片化的情况,并提出 UniRef++ 将四个基于引用的对象分割任务统一到一个架构中。我们方法的核心是提出的 UniFusion 模块,该模块执行多路融合,以处理相对于指定参考的不同任务。然后采用统一的Transformer架构来实现实例级分割。通过统一的设计,UniRef++可以在广泛的基准上进行联合训练,并可以通过指定相应的参考在运行时灵活地完成多个任务。我们在各种基准上评估我们的统一模型。大量的实验结果表明,我们提出的 UniRef++ 在 RIS 和 RVOS 上实现了最先进的性能,并且通过参数共享网络在 FSS 和 VOS 上具有竞争力的性能。此外,我们还展示了所提出的 UniFusion 模块可以轻松地合并到当前先进的基础模型 SAM 中,并通过参数高效的微调获得令人满意的结果。
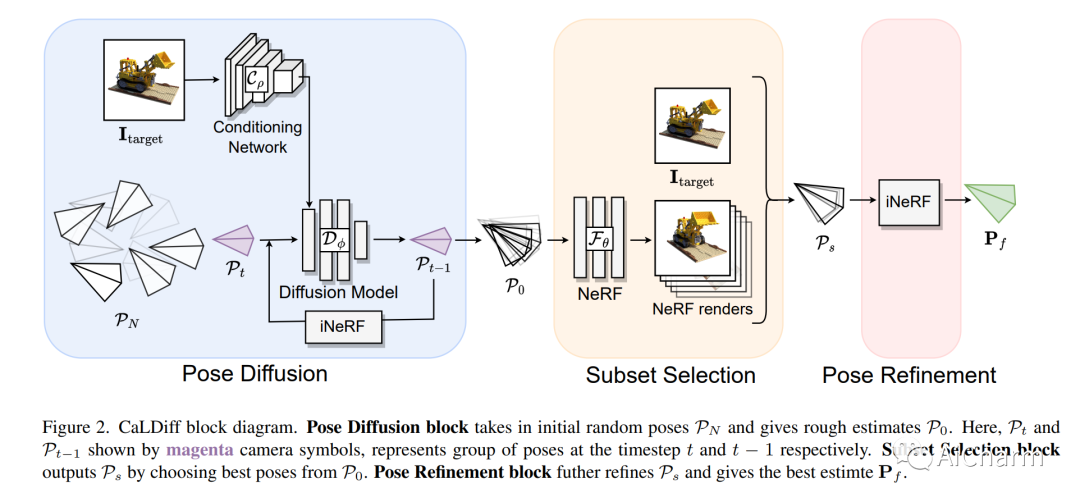
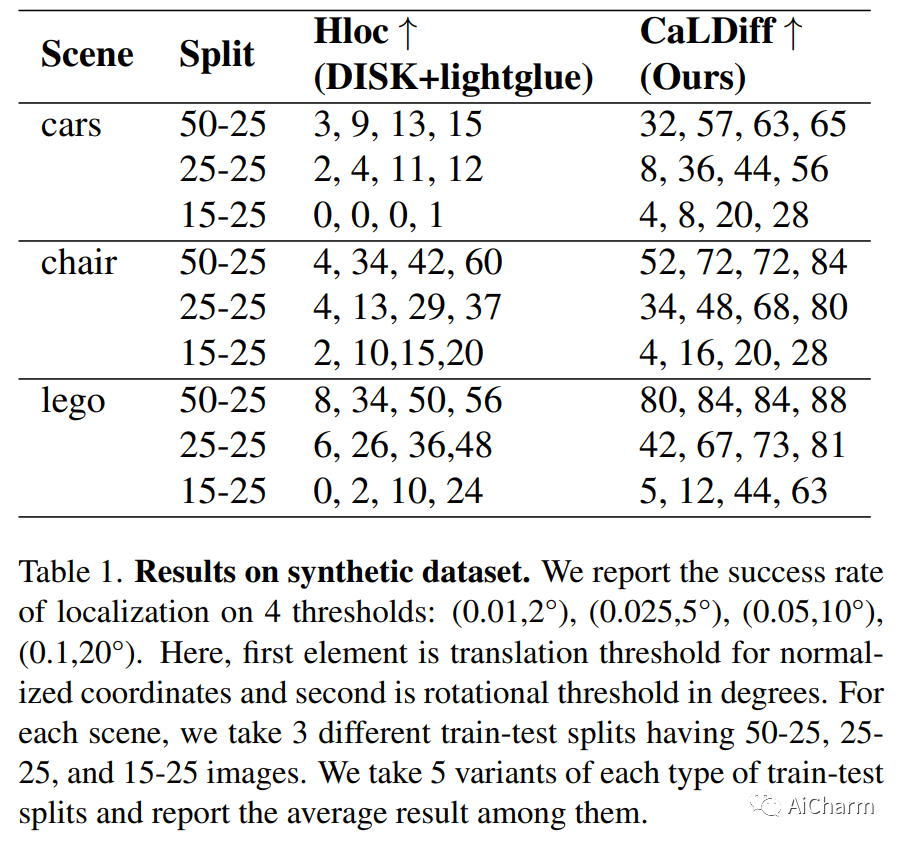
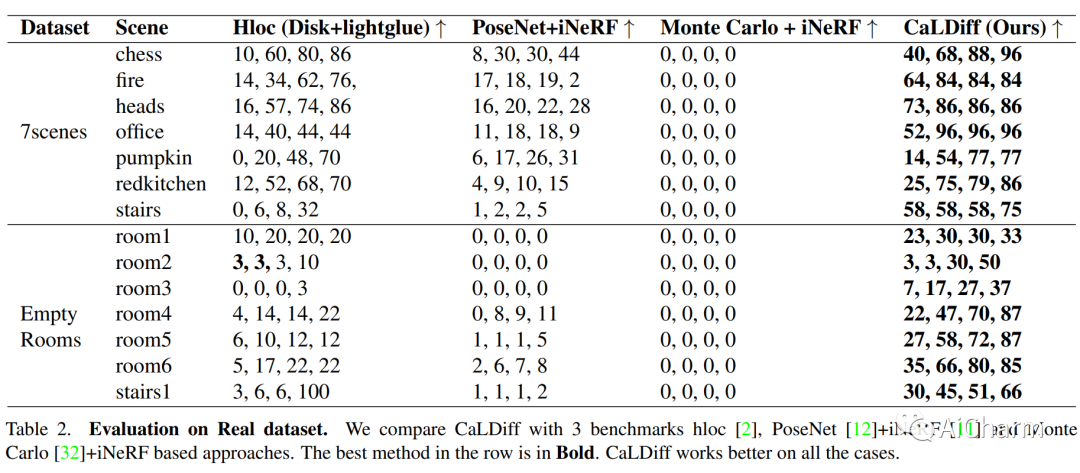
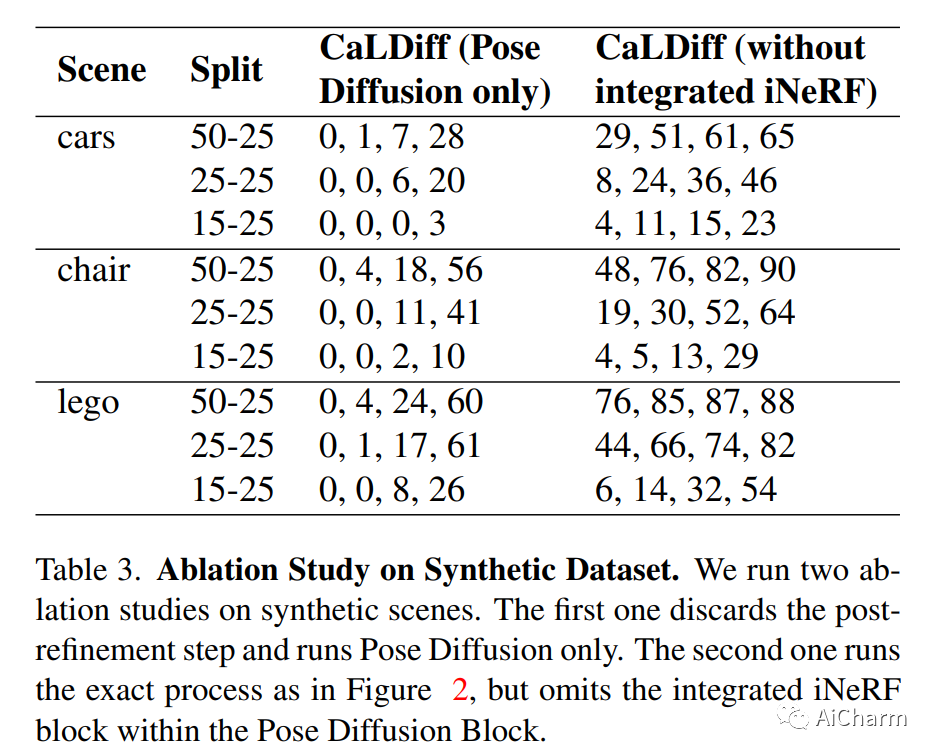
2.CaLDiff: Camera Localization in NeRF via Pose Diffusion

标题:CaLDiff:NeRF 中通过姿势扩散进行相机定位
作者:Rashik Shrestha, Bishad Koju, Abhigyan Bhusal, Danda Pani Paudel, François Rameau
文章链接:https://arxiv.org/abs/2312.15242




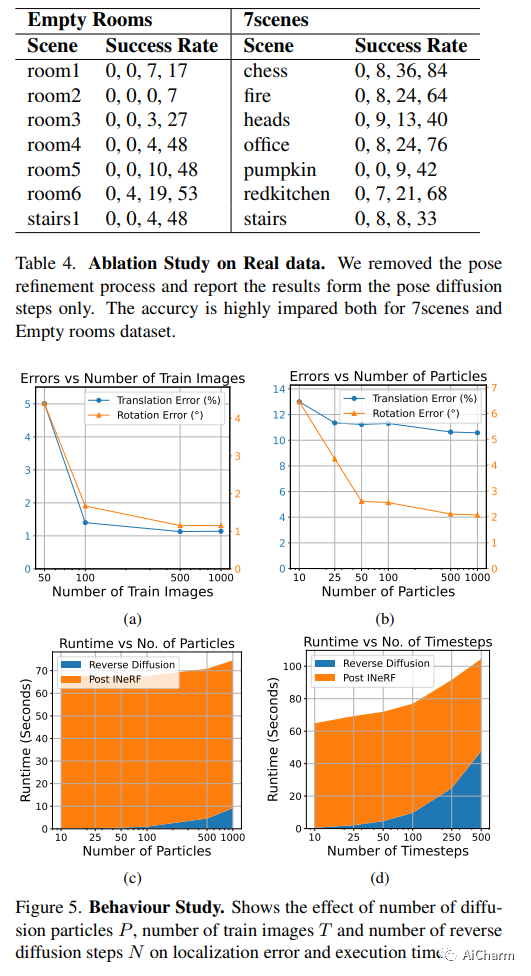
摘要:
随着基于 NeRF 的隐式 3D 表示的广泛使用,在同一表示中进行相机定位的需求变得显而易见。这样做不仅可以避免基于 NeRF 之外的本地化,从而简化本地化过程,而且还有可能提供增强本地化的优势。本文研究了 NeRF 中使用扩散模型进行相机姿态调整的相机定位问题。更具体地说,给定一个预先训练的 NeRF 模型,我们训练一个扩散模型,该模型根据要定位的图像迭代更新随机初始化的相机姿势。在测试时,新相机分两步定位:首先,使用所提出的位姿扩散过程进行粗定位,然后是 NeRF 中位姿反转过程的局部细化步骤。事实上,所提出的通过位姿扩散(CaLDiff)方法进行相机定位还将位姿反转步骤集成到扩散过程中。得益于我们下游的细化感知扩散流程,这种集成提供了更好的本地化。我们对具有挑战性的现实世界数据进行的详尽实验验证了我们的方法,提供了比比较方法和既定基线更好的结果。我们的源代码将公开。
3.PlatoNeRF: 3D Reconstruction in Plato's Cave via Single-View Two-Bounce Lidar

标题:PlatoNeRF:通过单视图二反射激光雷达对柏拉图洞穴进行 3D 重建
作者:Tzofi Klinghoffer, Xiaoyu Xiang, Siddharth Somasundaram, Yuchen Fan, Christian Richardt, Ramesh Raskar, Rakesh Ranjan
文章链接:https://arxiv.org/abs/2312.14239
项目代码:https://platonerf.github.io/
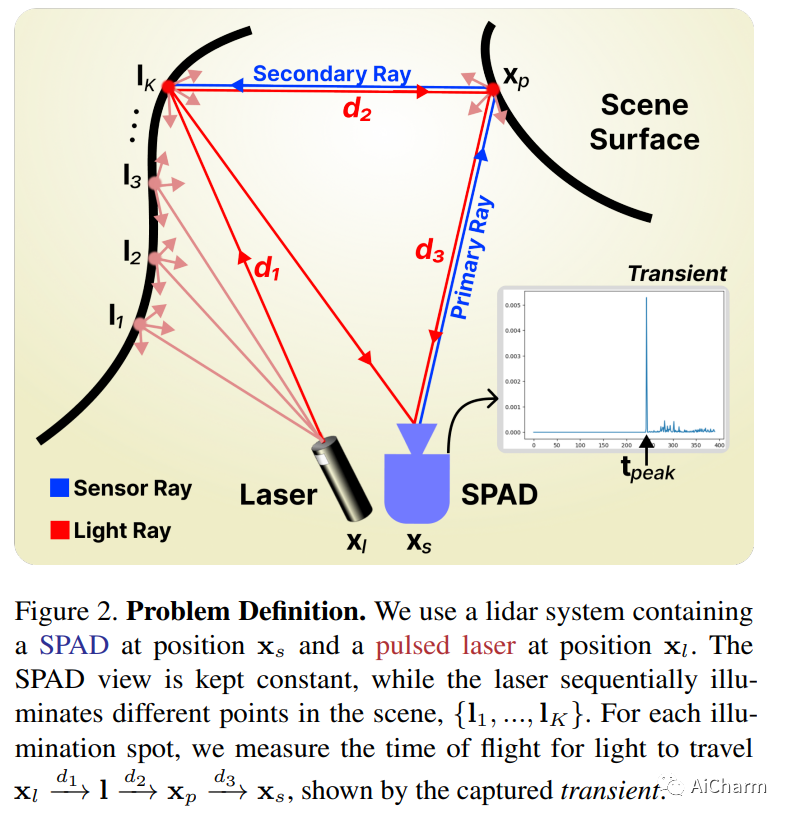

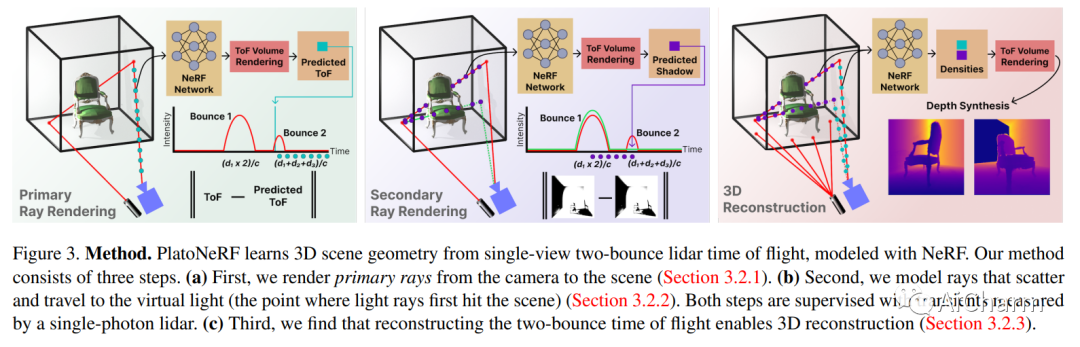

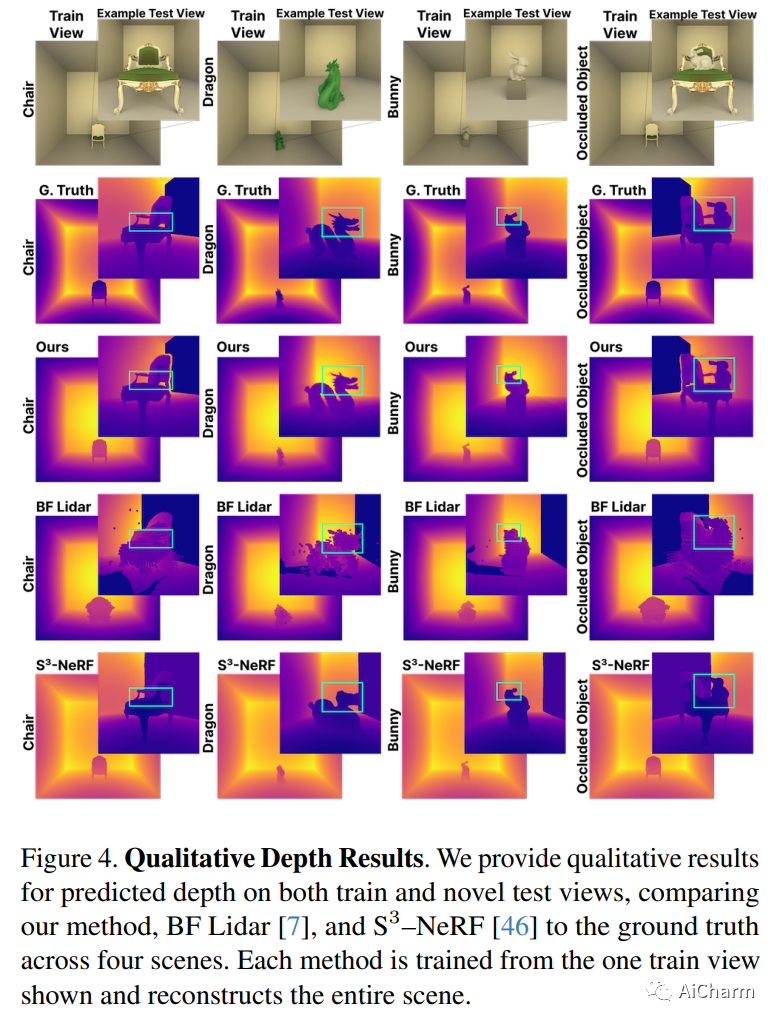
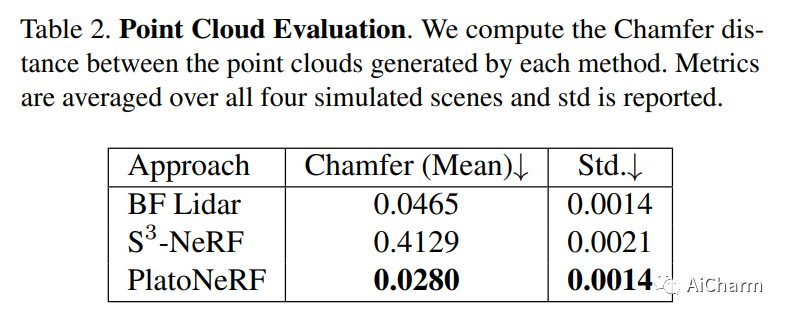
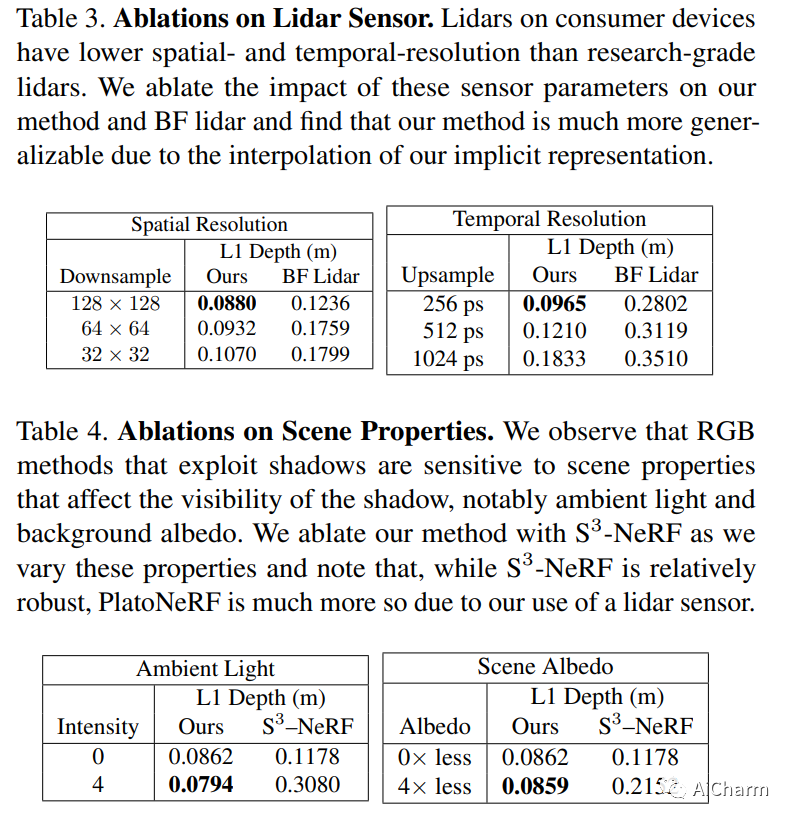
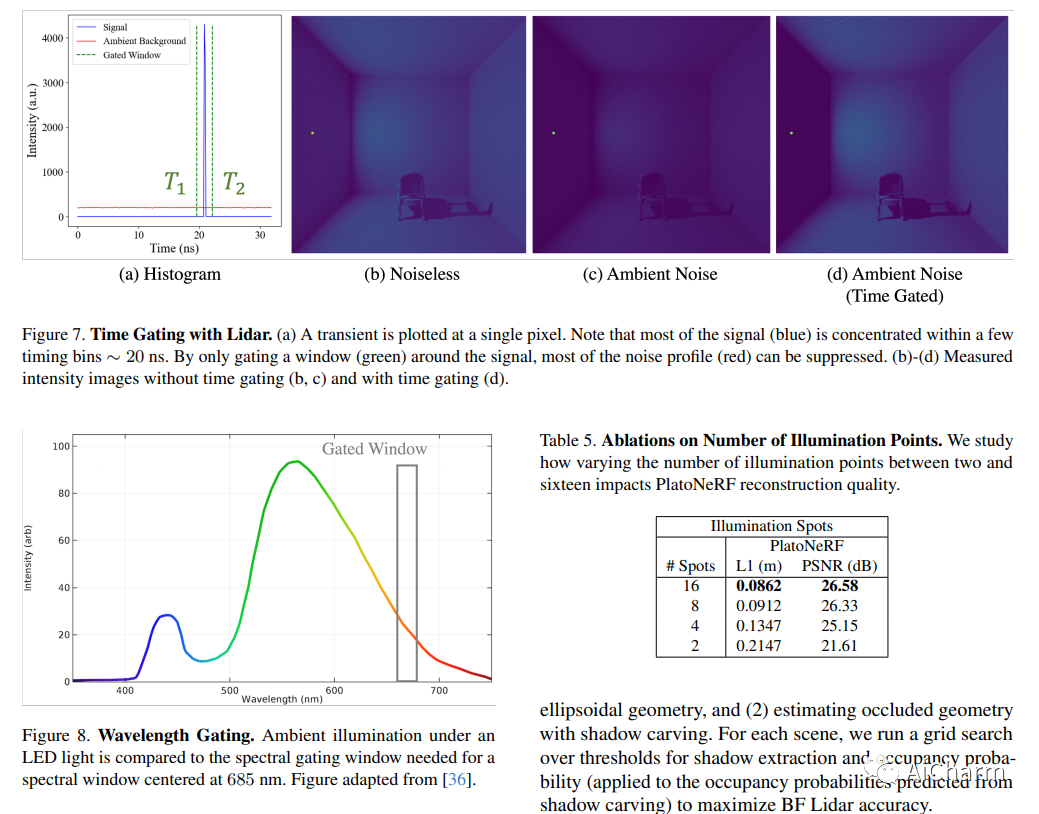
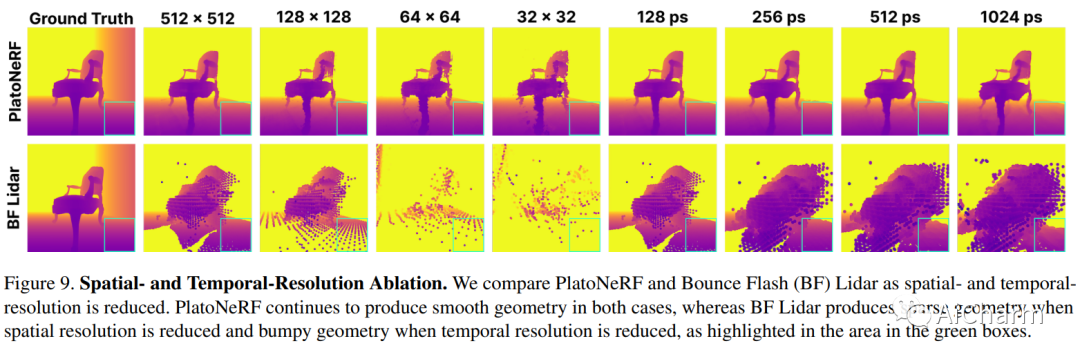
摘要:
由于单眼线索的模糊性和缺乏有关遮挡区域的信息,从单一视图进行 3D 重建具有挑战性。神经辐射场 (NeRF) 虽然在视图合成和 3D 重建中很流行,但通常依赖于多视图图像。使用 NeRF 进行单视图 3D 重建的现有方法依赖于遮挡区域幻觉视图之前的数据(这在物理上可能不准确),或者依赖于 RGB 相机观察到的阴影(在环境光和低反照率背景下很难检测到)。我们建议使用单光子雪崩二极管捕获的飞行时间数据来克服这些限制。我们的方法使用 NeRF 模拟两次反射光路,并使用激光雷达瞬态数据进行监控。通过利用 NeRF 和激光雷达测量的两次反射光的优势,我们证明我们可以重建可见和遮挡的几何形状,而无需先验数据或依赖受控的环境照明或场景反照率。此外,我们证明了在传感器空间和时间分辨率的实际限制下改进的泛化能力。我们相信,随着单光子激光雷达在手机、平板电脑和耳机等消费设备上变得无处不在,我们的方法是一个有前途的方向。
喜欢的话,请给我个在看吧!
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-01-01,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号