ICLR 2024 | TIME-LLM:将时序数据重新编码为更自然的文本表示
ICLR 2024 | TIME-LLM:将时序数据重新编码为更自然的文本表示

时间序列预测在许多现实世界的动态系统中具有重要意义,并已得到广泛研究。与自然语言处理(NLP)和计算机视觉(CV)不同,其中单个大型模型可以处理多个任务,时间序列预测模型通常需要专门设计,以满足不同任务和应用的需求。虽然预训练的基础模型在NLP和CV领域取得了令人印象深刻的进展,但其在时间序列领域的发展仍受限于数据稀疏性。最近的研究表明,大型语言模型(LLM)在处理复杂的标记序列时,具备稳健的模式识别和推理能力。然而,如何有效地对齐时间序列数据和自然语言并利用这些能力,仍然是一个挑战。
本文介绍一篇用大语言模型(LLM)来做时间序列预测的工作。论文采用了通道独立的策略,即把多变量预测分解为多个独立的单变量预测。

论文地址:https://arxiv.org/abs/2310.01728
论文源码:https://anonymous.4open.science/r/Time-LLM
论文概述
在这项工作中,作者提出了TIME-LLM,这是一个重新编程框架,将LLM重新用于一般时间序列预测,同时保持基础语言模型的完整性。作者首先使用文本原型对输入时间序列进行重新编程,然后将其输入到冻结的LLM中,以对齐这两种模式。为了增强LLM对时间序列数据的推理能力,作者提出了Prompt-as-Prefix(PaP)方法,通过在输入时间序列中添加额外的上下文和提供自然语言的任务指令,丰富输入时间序列。最后,将LLM转换后的时间序列补丁投影出来以获得预测结果。
这项工作中的主要贡献可以总结如下:
• 引入了大型语言模型重新编程用于时间序列预测的全新概念,而无需修改预训练的主干模型。由此,作者表明预测可以被视为另一个可以由现成的LLM有效解决的“语言”任务。
• 提出了一个新的框架,即TIME-LLM,它包括将输入时间序列重新编程为更自然的文本原型表示,并通过声明性提示(例如领域专家知识和任务说明)来增强输入上下文,以指导LLM推理。该技术指明了多模态基础模型在语言和时间序列方面的卓越表现。
• TIME-LLM在主流预测任务中的表现始终超过最先进的性能,特别是在少样本和零样本场景中。此外,在保持出色的模型重编程效率的同时,能够实现更高的性能。大大释放LLM在时间序列和其他顺序数据方面尚未开发的潜力。
模型框架
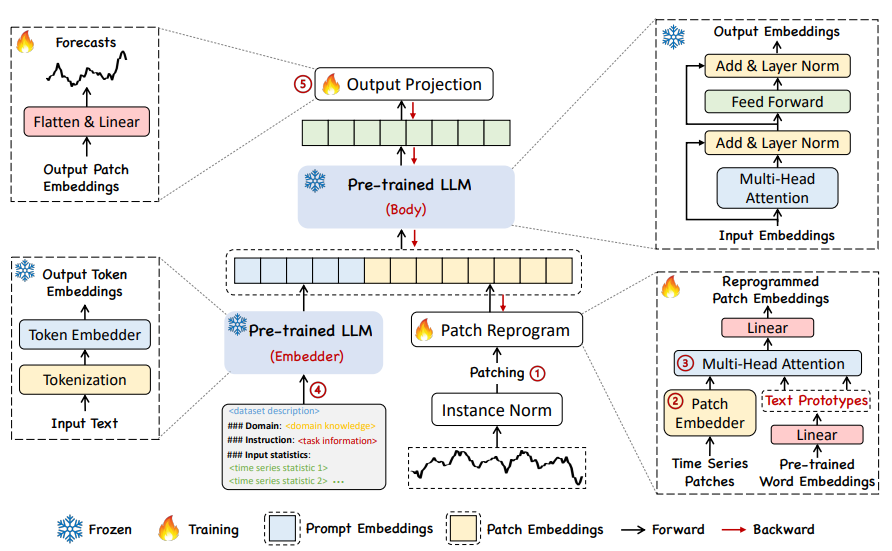
01
Input Embedding
如上方模型框架图中①和②所示,时间序列先通过RevIN的归一化操作,然后分patch进行embedding,得到shape为
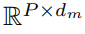
的时序输入特征
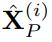
。
02
Patch Reprogramming
由于时间序列和文本在表达方式上存在差异,两者属于不同的模态。时间序列既不能直接编辑,也不能无损地用自然语言描述,这给直接引导LLM理解时间序列带来了重大挑战,而不需要资源密集型的微调。因此,需要将时序输入特征对齐到自然语言文本域上。
对齐不同模态的一个常见方法就是cross-attention,只需要把所有词的embedding和时序输入特征做一个cross-attention(其中时序输入特征为Query,所有词的embedding为Key和Value)。但是,词汇表很大,肯定无法直接将时序特征对齐到所有词上,而且也并不是所有词都和时间序列有对齐的语义关系。
为解决上述问题,文章对其进行了线性组合获取text prototypes
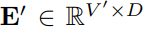
,text prototypes中包含的词数量远小于原始词汇量,组合起来可以用于表示时序数据的变化特性,例如“短暂上升或缓慢下降”。 接下来文章通过多头自注意力机制自适应地获取patch对应的文本描述,如下:
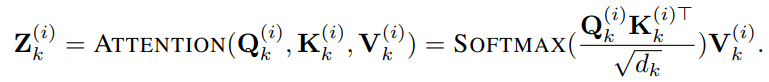
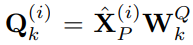
,
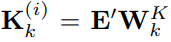
,
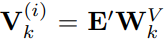
将多个head的输出拼在一起并通过一个线性层获得
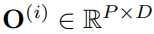
,作为时序数据的表征(注意这个是单通道数据的表征)。通过上述注意力机制,聚合的是词表征而不是原始序列的embbedding,这样是为了更好地适配LLM,毕竟LLM是在语料数据上训练的而不是时序数据。
03
Prompt-as-Prefix
Prompt-as-Prefix (PaP) 是一种简单而有效的方法,用于任务特定的激活LLM。然而,将时间序列直接翻译成自然语言带来了相当大的挑战,这既阻碍了遵循指令的数据集的创建,也阻碍了在不牺牲性能的情况下即时提示的有效利用。
最近的进展表明,其他数据模式,如图像可以无缝地集成到提示的前缀中,从而基于这些输入进行有效的推理。受这些发现的启发,作者为了使他们的方法直接适用于现实世界的时间序列,提出了一个替代问题:提示能否作为预处理操作,以丰富输入上下文并指导重新编程时间序列补丁的转换?这个概念被称为Prompt-as-Prefix (PaP) ,此外,作者还观察到它显著提高了LLM对下游任务的适应能力,同时补充了补丁的重新编程。通俗点说,就是把时间序列数据集的一些先验信息,以自然语言的方式,作为前缀prompt,和对齐后的时序特征拼接喂给LLM,是不是能够提升预测效果?
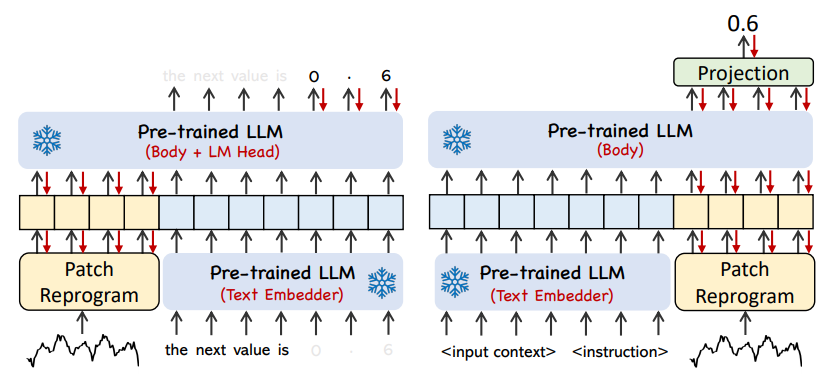
上图展示了两种提示方法。在Patch-as-Prefix中,语言模型被提示预测时间序列中的后续值,以自然语言表达。这种方法遇到了一些约束:(1)语言模型在无外部工具辅助下处理高精度数字时通常表现出较低的敏感性,这给长期预测任务的精确处理带来了重大挑战;(2)对于不同的语言模型,需要复杂的定制化后处理,因为它们在不同的语料库上进行预训练,并且可能在生成高精度数字时采用不同的分词类型。这导致预测以不同的自然语言格式表示,例如
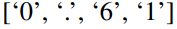
和
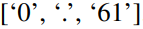
,表示十进制的0.61。
另一方面,Prompt-as-Prefix巧妙地避免了这些约束。在实践中,作者确定了构建有效提示的三个关键组件:(1)数据集上下文;(2)任务指令,让LLM适配不同的下游任务;(3)统计描述,例如趋势、时延等,让LLM更好地理解时序数据的特性。下图给出了一个提示示例。

实验效果
TIME-LLM在多个基准测试和设置中,尤其是在少样本和零样本场景中,均以较大优势持续超越最先进的预测方法。
下表1显示,其中TIME-LLM在大多数情况下超过了所有基线,并且对大多数基线有显著的优势。
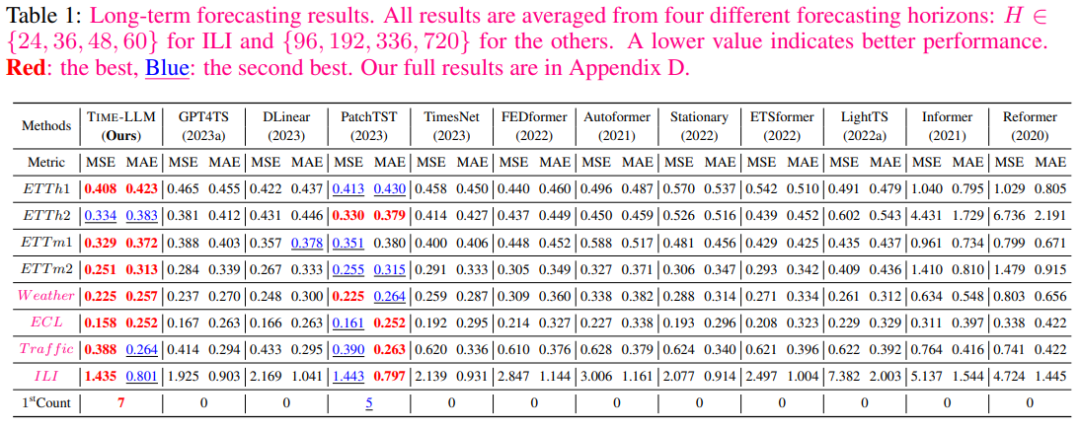
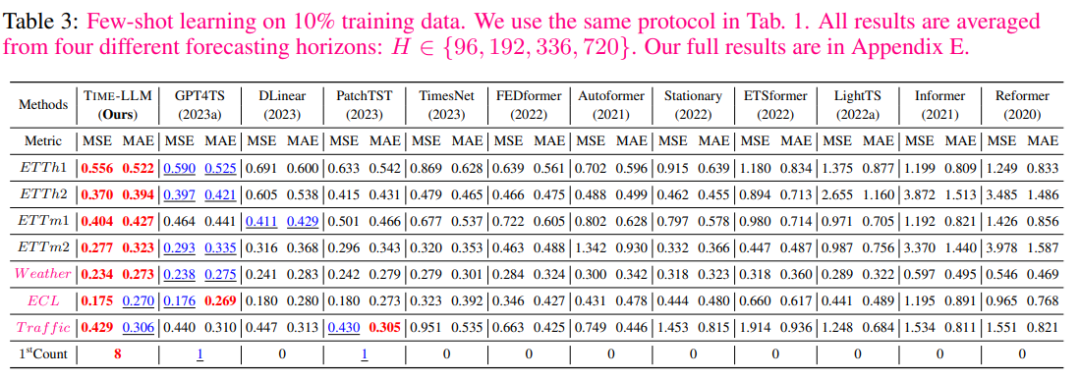
在10%少样本学习的领域中,与GPT4TS相比,作者的方法实现了5%的MSE降低,而无需对LLM进行任何微调。与最近的SOTA模型如PatchTST、DLinear和TimesNet相比,作者的平均改进超过了8%、12%和33%。
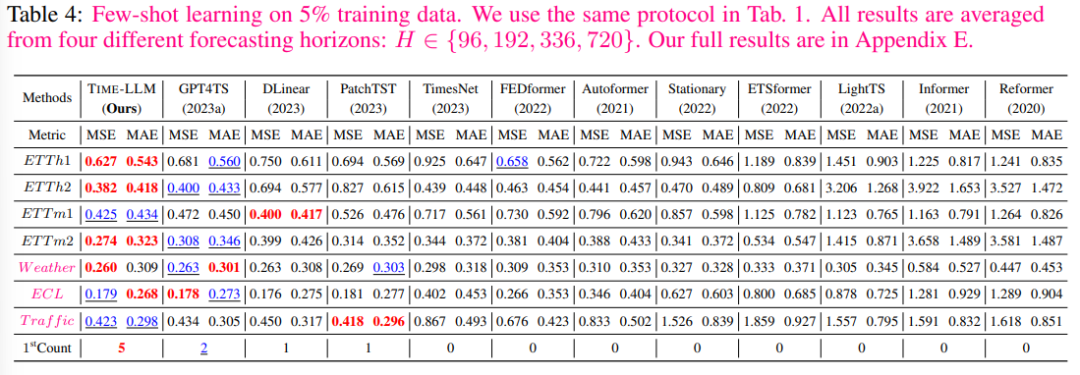
在5%少样本学习场景中,可以观察到类似的趋势,与GPT4TS相比,作者的平均改进超过了5%。与PatchTST、DLinear和TimesNet相比,TIME-LLM展现出惊人的平均改进超过20%。
感兴趣的朋友,可以查阅论文原文了解更多实验数据及结果。
腾讯云开发者
