每日论文速递 | Google提出PERL:将PEFT与RLHF结合起来

每日论文速递 | Google提出PERL:将PEFT与RLHF结合起来

zenRRan
发布于 2024-03-26 10:56:03
发布于 2024-03-26 10:56:03
深度学习自然语言处理 分享 整理:pp

摘要:从人类反馈中强化学习(RLHF)已被证明是将预训练的大型语言模型(LLM)与人类偏好相匹配的有效方法。但是,使用 RLHF 训练模型的计算成本很高,而且整个过程也很复杂。在这项工作中,我们研究的 RLHF 是使用 Hu 等人[2021]提出的参数高效的低库自适应(Low-Rank Adaptation,LoRA)方法来训练底层模型的。我们研究了 "参数高效强化学习"(PERL)的设置,其中我们使用 LoRA 进行奖励模型训练和强化学习。我们比较了 PERL 和传统微调(完全微调)在 7 个基准(包括 2 个奖励建模和强化学习的新数据集)中的不同配置。我们发现,PERL 的性能与传统的 RLHF 设置相当,同时训练速度更快,占用内存更少。这使得 RLHF 的高性能得以实现,同时减少了限制其作为大型语言模型对齐技术的采用的计算负担。我们还发布了两个新颖的向上/向下偏好数据集:"Taskmaster Coffee "和 "Taskmaster Ticketing",以促进围绕 RLHF 的研究。
https://arxiv.org/abs/2403.10704
Q1: 这篇论文试图解决什么问题?


A:这篇论文探讨了如何通过人类反馈对预训练的大型语言模型(Pretrained Large Language Models, LLMs)进行参数高效的强化学习(Reinforcement Learning from Human Feedback, RLHF)。具体来说,它试图解决以下问题:
- 计算成本高:使用RLHF对模型进行训练是计算密集型的,因为它需要大量的内存和计算资源。
- 训练数据收集困难:创建有效的奖励模型需要大量的高质量训练数据,这在实践中可能难以收集。
- 训练效率低:传统的RLHF方法涉及对奖励模型和策略模型的所有参数进行微调,这不仅耗时,而且可能导致过拟合。
为了解决这些问题,论文提出了一种名为“参数高效强化学习”(Parameter Efficient Reinforcement Learning, PERL)的方法。PERL使用低秩适应(Low-Rank Adaptation, LoRA)技术来训练奖励模型和强化学习策略,从而减少了训练过程中的参数数量,提高了训练效率,降低了内存需求,并减少了训练时间。通过这种方法,PERL能够在保持与常规RLHF相当的性能水平的同时,显著降低了计算成本。
Q2: 有哪些相关研究?
A:这篇论文提到了多个相关领域的研究,包括:
预训练大型模型(PLMs):论文提到了多种预训练语言模型,如GPT-4、Gemini等,这些模型在多种任务上表现出色,但仍存在一些局限性,如输出不准确或不遵循人类指令等问题。
对齐预训练大型模型与人类/AI偏好:研究如何通过收集上下文、成对生成和相关偏好数据来对齐PLMs与人类偏好,以克服PLMs的局限性。这包括使用AI反馈来减少人工标注成本。
强化学习从人类/AI反馈(RL{H/AI}F):RLHF是一种流行的对齐方法,它首先在首选输出上拟合奖励模型,然后使用该奖励模型通过强化学习算法训练策略。
参数高效微调(PEFT):PEFT方法减少了预训练大型模型的可训练参数数量,同时保持与全参数微调相当的性能。LoRA是PEFT的一个例子,它通过低秩矩阵分解来更新权重。
Transformer强化学习(TRL):TRL库是已知的与PERL最接近的实现,它使用共享基础模型来实现RLHF。
论文还提到了一些具体的技术和方法,如PPO(Proximal Policy Optimization)算法、LoRA的低秩投影应用、以及如何通过减少可训练参数来缓解奖励模型的过拟合问题。
此外,论文还探讨了如何通过PERL方法来提高RLHF的效率,包括在多个数据集上的实验结果,以及与现有RLHF方法的比较。论文还提出了未来的研究方向,包括探索PERL在更广泛泛化性上的性能、使用加权平均模型来减少奖励黑客行为等。
Q3: 论文如何解决这个问题?
A:论文提出了一种名为“参数高效强化学习”(PERL)的方法来解决上述问题。PERL的核心思想是结合低秩适应(LoRA)技术与强化学习从人类反馈(RLHF)的方法,以减少训练过程中的参数数量和计算资源消耗。具体的解决方案包括:
- 使用LoRA进行参数高效微调:LoRA通过将权重更新分解为两个可训练的低秩矩阵(下投影和上投影),从而只更新这些低秩矩阵而不是整个模型的参数。这大幅减少了训练时需要更新的参数数量。
- 奖励模型训练:在RLHF过程中,奖励模型(RM)的训练是关键步骤。PERL使用LoRA来训练奖励模型,这样可以在保持与全参数微调相当的性能的同时,显著减少内存使用和训练时间。
- 强化学习策略训练:在RLHF中,策略模型(πRL)通过强化学习算法进行优化,以最大化奖励模型给出的累积奖励。PERL同样使用LoRA来训练策略模型,进一步提高了训练效率。
- 实验验证:论文通过在多个数据集上的实验,展示了PERL方法与常规RLHF方法在性能上的相似性,同时在内存使用和训练速度上取得了显著改进。
- 数据集发布:为了促进RLHF领域的研究,论文还发布了两个新的点赞/点踩偏好数据集:‘Taskmaster Coffee’和‘Taskmaster Ticketing’。
通过这些方法,PERL能够在保持RLHF高性能的同时,显著降低了计算成本,使得RLHF作为一种对齐技术在大型语言模型上的应用变得更加可行。
Q4: 论文做了哪些实验?
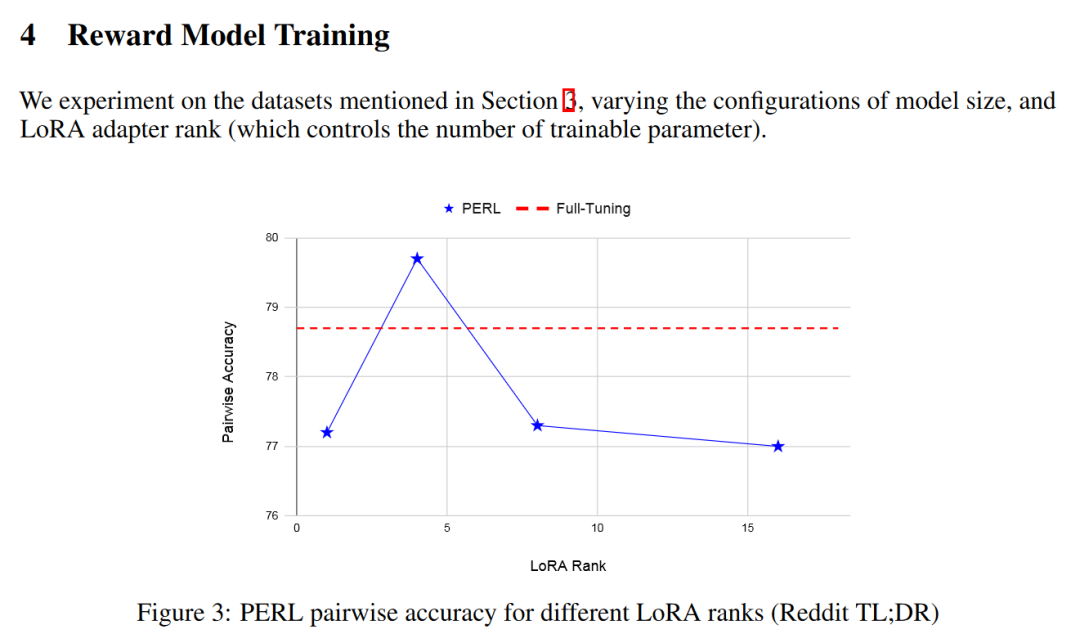
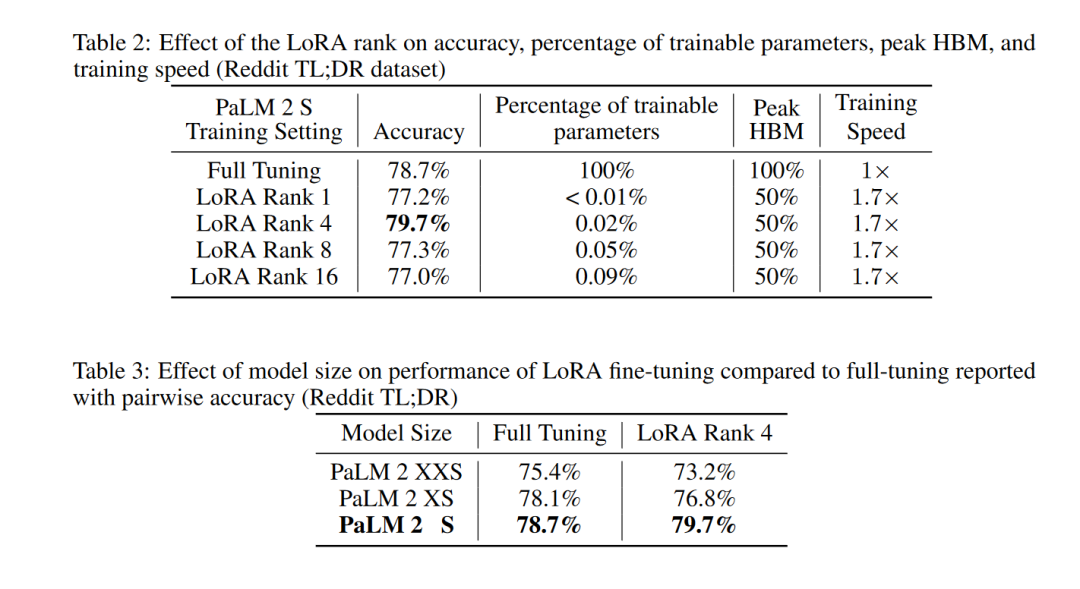
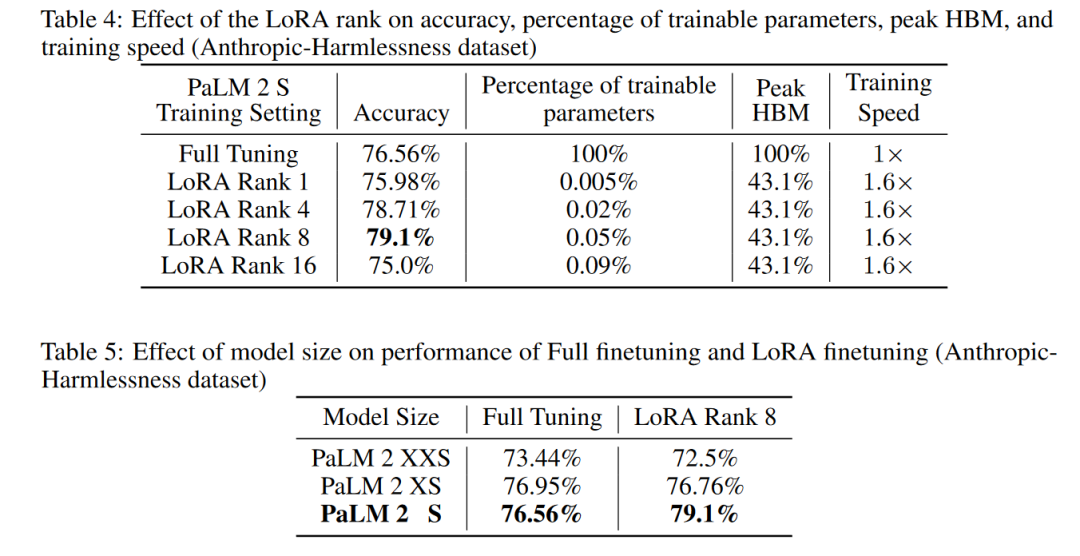
A:论文中进行了一系列实验来评估和验证Parameter Efficient Reinforcement Learning (PERL) 方法的有效性。具体的实验包括:
- 奖励模型训练实验:作者在多个数据集上训练了奖励模型,包括文本摘要、生成无害响应、生成有帮助的响应、UI 自动化和生成中立观点响应等任务。实验比较了使用LoRA进行低秩适应(Low-Rank Adaptation)与传统全参数微调(Full-Tuning)的效果,包括模型大小和LoRA适配器秩的影响。
- 强化学习策略训练实验:在相同的数据集上,作者训练了使用PERL的强化学习策略,并与使用传统RLHF方法训练的策略进行了比较。这些实验评估了在不同模型大小和LoRA适配器秩下策略的性能。
- 性能比较:作者比较了PERL与常规RLHF在多个基准测试上的性能,包括在7个数据集上的奖励模型和强化学习任务。比较的指标包括训练速度、内存使用和结果质量。
- 新数据集发布:为了支持RLHF研究,作者发布了两个新的偏好数据集:Taskmaster Coffee和Taskmaster Ticketing。这些数据集包含了与任务相关的对话和用户反馈,用于训练和评估奖励模型。
- 不同任务的实验:作者在多个不同的NLP任务上进行了实验,包括文本摘要、对话生成和UI自动化等,以展示PERL方法的泛化能力。
通过这些实验,论文证明了PERL方法在减少训练参数、内存占用和加快训练速度方面的优势,同时保持了与全参数微调相当的性能。这些实验结果支持了PERL方法作为一种有效的RLHF技术,适用于大型语言模型的对齐。
Q5: 有什么可以进一步探索的点?
A:论文中提到了一些未来可能的研究方向和可以进一步探索的点:
跨领域泛化:尽管PERL在特定领域的表现与全参数微调相当,但论文中没有深入探讨其在更广泛的泛化场景下的表现。未来的工作可以探索如何通过技术如混合LoRA适配器等来提高跨领域泛化能力。
奖励模型的鲁棒性:奖励模型容易受到“奖励黑客”行为的影响,即模型可能会学习到如何产生高奖励但实际上低质量或不相关的输出。论文提到了通过加权平均多个适配器来减少这种风险的可能性,这是未来研究的一个潜在方向。
更高效的训练方法:尽管PERL已经提高了训练效率,但仍有可能通过进一步的技术创新来减少训练时间和计算资源消耗,例如通过更高效的优化算法或更好的模型初始化策略。
更大规模的模型和数据集:随着模型规模的增加,PERL的效果可能会有所变化。未来的研究可以探索在更大规模的模型上应用PERL,并在更大的数据集上进行训练和评估。
多模态任务的适用性:论文中的实验主要集中在文本任务上。未来的研究可以探索PERL在多模态任务(如图像、音频和视频)中的适用性和效果。
伦理和社会影响:论文提到了使用众包工人创建对话数据集的过程。未来的研究可以考虑更广泛的伦理和社会影响,包括数据集创建过程中的隐私和公平性问题。
可解释性和透明度:提高模型的可解释性和透明度,以便更好地理解和信任模型的决策过程,是NLP领域的一个持续挑战。未来的工作可以探索如何利用PERL方法来增强模型的可解释性。
这些方向为未来的研究提供了丰富的机会,以进一步提高通过人类反馈进行强化学习的方法的效率和有效性。
以上内容均由KimiChat生成,深入了解论文内容仍需精读论文
本文参与 腾讯云自媒体同步曝光计划,分享自微信公众号。
原始发表:2024-03-25,如有侵权请联系 cloudcommunity@tencent.com 删除
评论
登录后参与评论
推荐阅读
目录
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号