最优控制思考错了? What Is Optimal about Motor Control
最优控制思考错了? What Is Optimal about Motor Control

本文提出了一个有争议的问题:最优控制理论对于理解运动行为有用还是误导?随着人们开始将运动控制和感知的内部模型混为一谈,这个问题变得越来越尖锐(Poeppel 等,2008;Hickok 等,2011)。然而,运动控制中的前向模型并不是感知推理中使用的生成模型。本视角试图强调运动控制和感知的内部模型之间的差异,并询问最优控制是否是思考事物的正确方式。这里考虑的问题可能对最优决策理论和贝叶斯学习和行为方法产生更广泛的影响。
最优控制思考错了? What Is Optimal about Motor Control

https://www.cell.com/neuron/pdf/S0896-6273(11)00930-5.pdf
Abstract摘要
这篇文章提出了一个具有争议性的问题:最优控制理论对于理解运动行为是否有用,还是说它是一个误导?随着人们开始混淆运动控制和感知中的内部模型(Poeppel等,2008年;Hickok等,2011年),这个问题变得越来越严峻。然而,在运动控制中的前向模型并不是感知推理中使用的生成模型。本文试图突出运动控制和感知中的内部模型之间的区别,并询问是否最优控制是正确的思考方式。这里考虑的问题可能对最优决策理论和贝叶斯方法在学习和行为方面的一般应用具有更广泛的影响。
Introduction介绍
最优控制理论目前是理解运动行为的主导范式,在形式化或计算方面。它提供了一种规范控制模型,使许多问题能够在一个连贯而有原则的框架中得到解决(Ko¨ rding, 2007)。此外,它激发了使用优雅的数学来解决大脑面临的一些困难问题(Todorov和Jordan,2002)。最优控制的基本前提是最优的运动带来有价值的状态。这意味着,只要它增加价值,就可以用状态的价值函数来指定运动。尽管这种方法具有引人注目的简单性,但我认为它可能是错误的,有两个原因。首先,我们从流体力学知道,运动不能由单一的价值函数来指定。其次,最优控制理论假设运动是由价值决定的。然而,价值是由运动引起的状态的属性:它是一种结果,而不是一种原因。这意味着真正的问题是理解导致运动的信念的获取和实现——换句话说,用推理和信念来理解运动控制。我对最近的文献的阅读是,人们从最优控制的工程范式向问题制定中的贝叶斯推理范式的转变。然而,这种范式转变可能不会完全完成,直到我们放弃将价值函数作为运动的因果解释。本文比较了最优控制和推理,并试图表明推理(1)符合所有生物系统都适用的命令,(2)解决了一些最优控制中的难题,(3)提供了控制的完整规范,(4)在神经生物学上是合理的,(5)解释了行动而不参考价值。虽然从工程学的角度来看,这可能并不重要,但对于对神经科学中的最优控制进行批判性评价可能很重要。
最近对运动控制理论的发展(Tani, 2003; Verschure等,2003; Tani等,2004; Jirsa和Kelso,2005; Wo¨ rgo¨ tter和Porr,2005)强调感觉运动动力学和感知推理,而不是基于前向-逆向模型的传统最优控制(Miall等,1993; Wolpert等,1995; Wolpert和Miall,1996; Todorov和Jordan,2002; Todorov,2004; Bays和Wolpert,2007; Liu和Todorov,2007; Shadmehr和Krakauer,2008; Diedrichsen等,2010)。参见Schaal等人(2007)试图调和这些观点。基本区别在于,最优控制假设行为可以归纳为优化状态的价值函数,该函数定义了何为最优。本文侧重于以主动推理(Friston等,2009)为形式示例的推理方法,并将其与最优控制进行比较,以确定这些规范方法中哪一种最有用。结论是,最优性可能更好地通过对行为的先验信念而不是价值函数来理解。它进一步表明,主动推理解决了运动控制中的几个关键问题,并统一了有关贝叶斯最优行为、感知和学习的当前思考。有趣的是,基于平衡点假设(Feldman,2009)的论点得出了类似的结论;即,在运动控制中不需要单独的逆向和前向模型,因为可以通过对前向模型进行(贝叶斯)反转来替代逆向模型。这对于感觉运动处理(或学习)的贝叶斯公式没有任何影响,但对于最优性、成本函数和外部拷贝的概念有深远的影响。我们首先回顾主动推理,然后考虑最优控制方案。
Active Inference主动推理
主动推理是自由能原理(Friston, 2010)的一个推论,它认为行动和感知都在最小化惊奇。简而言之,这种最小化的动机在于解释生物系统如何在范围内维持其生物物理状态,并因此抵抗热力学第二定律——换句话说,解释它们如何维持稳态。它们可以通过最小化惊奇的长期平均值来实现这一点,这隐含地最小化了它们感觉状态的熵。惊奇只是一个代理遇到的感觉信号的负对数概率。在信息论中,惊奇被称为自信息,而在统计学中,它是负对数模型证据或边际似然。虽然代理无法直接最小化惊奇,但它们可以最小化总是大于惊奇的自由能;因此有了自由能原理。在一些简化的假设下,这种自由能可以被认为是预测误差。这意味着感知可以通过改变预测来减少预测误差(Dayan等,1995; Rao和Ballard,1999),而行动可以通过改变感觉来减少预测误差(Friston等,2010)。至关重要的是,感觉包括外感和本体感觉两种方式。这导致了一种将感知视为预测编码,将行动视为通过经典反射弧取消本体感觉预测误差的运动神经元放电的观点。在这个框架中,自上而下(皮质脊髓)投射不是本身的运动命令信号,而是关于本体感觉或动觉感觉的预测。
接下来,我们将从最优控制理论推导出主动推断,以确定最优控制的哪些组件是必要的,哪些是不必要的。最优控制可以被视为通过三种简化形式来进行主动推断:第一种将最优控制转化为预测编码,第二种用运动反射弧替代最优控制,第三种用先验信念替代价值函数。第一种简化提供了对感知和行动的统一视角,并突出了贝叶斯过滤在模型反演中的核心作用。此外,它表明在运动控制中的前向模型并不是实际反演的生成模型。第二种简化解决了下行信号延迟的问题,并将经典反射弧重新引入到运动控制的重要组成部分。最后,用关于运动的先验信念取代价值和成本函数完全消除了最优控制问题。
Conventional Motor Control Schemes and Active Inference
传统的电机控制方案和主动推理
图1基于Frens和Donchin (2009)对传统方案的良好概述。这个示意图试图包含最优控制的关键要素,从早期的Smith预测器概念(Miall等,1993)到更近期最优控制和状态估计的综合(Todorov,2004; Ko¨ rding和Wolpert,2004; Paulin,2005)。图1使用了一个连续时间的非线性公式,以强调这些方案必须在神经生物学中实现。主要的三个组成部分是(1)反向模型或最优控制,(2)前向模型和(3)状态估计(见图例)。简而言之,最优控制计算命令信号,以最小化一些成本函数,指定期望的运动。虽然这看起来很直接,但它假定一个底层的最优性方程可以求解(Bellman,1952)。这是一个困难的问题,有几种近似解,从反向归纳到动态规划和强化学习(Sutton和Barto,1981)。最优控制信号取决于被感知信号估计出的运动装置的(隐藏)状态。这种估计通常被解释为一种贝叶斯滤波的形式,用一个(连续时间的)Kalman-Bucy滤波器来表示。在这里,滤波意味着以贝叶斯最优的方式从一系列感知观测中估计隐藏状态。这涉及到用基于状态估计和最优控制信号的输出的前向模型的预测变化来补充预测的变化和基于感知预测误差的更新。这需要控制器将其控制信号的一份输出发送到前向模型。在这个设置中,前向模型也可以被看作是通过用预测来补充嘈杂(和延迟的)感知预测误差以提供贝叶斯最优状态估计来优化状态估计。
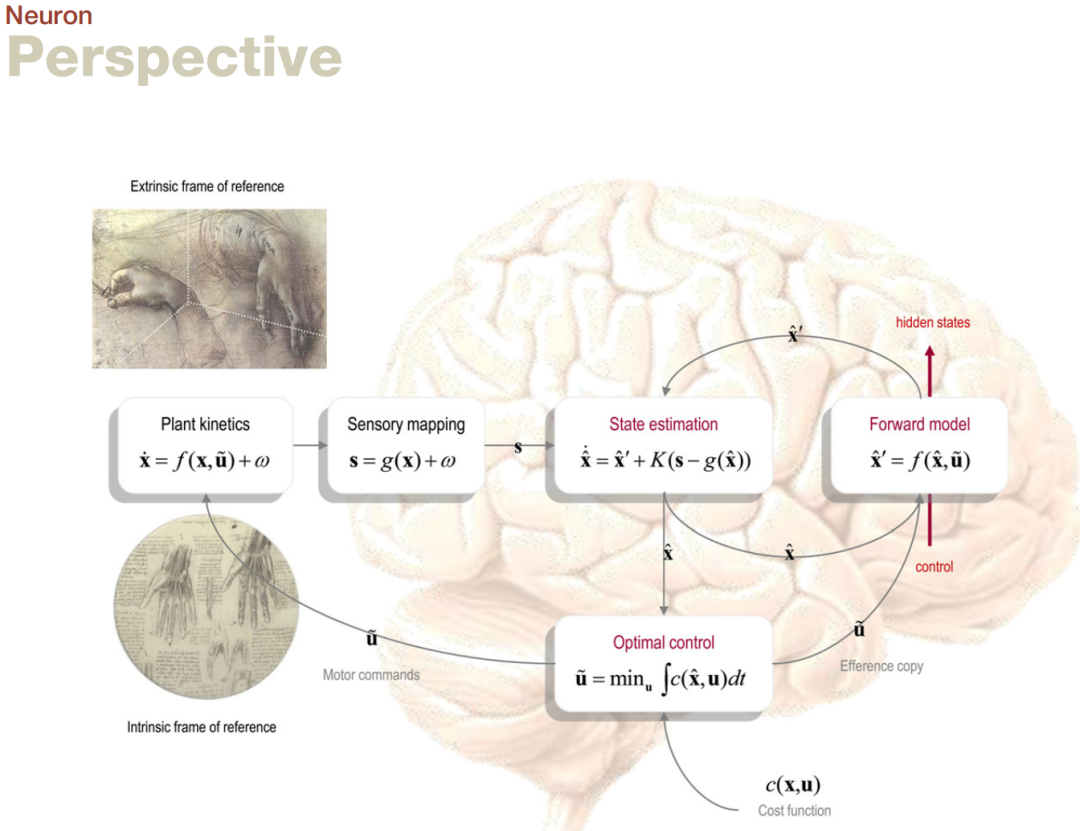

至关重要的是,这些估计可以通过在中枢神经系统和外周神经系统之间信号交换中发生的感觉延迟来解决问题。
总之,传统方案基于独立的反向和前向模型,这两种模型都必须学习。前向模型的学习对应于感觉运动学习,通常被认为是贝叶斯最优的。相反,学习逆模型需要某种形式的动态规划或强化学习,并假设可以通过提供给代理人的成本函数来指定运动。
Predictive Coding and Motor Control预测编码和电机控制
图2显示了对传统方案的轻微重新排列,以突显其与预测编码的形式关系。在数学上,通过将前向模型替换为状态估计,消除了对隐藏状态的预测变化。这突出了一个关键点:在状态估计期间反转的生成模型包括控制信号与隐藏状态变化之间的映射以及从隐藏状态到感觉后果的映射。这意味着前向模型只是这些方案中隐含的完整生成模型的一部分。此外,在图2中,感觉预测误差被明确表示,以显示其构建方式与预测编码相对应。在预测编码方案中,自上而下的预测与自下而上的感觉信息进行比较,以创建预测误差。然后,将预测误差向前传递,以优化隐藏状态的预测,此处使用Kalman-Bucy滤波器显示。有大量关于预测编码作为感知推断模型的文献,认为它是一种生物学上合理的贝叶斯滤波形式。请注意,在预测编码中的感觉预测误差与最优控制和强化学习中的奖励预测误差无关。感觉预测误差是在线状态估计(推断)和优化(学习)前向模型所需的。相反,奖励预测误差仅与学习逆模型相关,涉及值函数或成本的学习。奖励预测误差通常在奖励学习的背景下被引用;然而,在学习运动控制中学习成本路径积分时,也需要完全相同的错误。
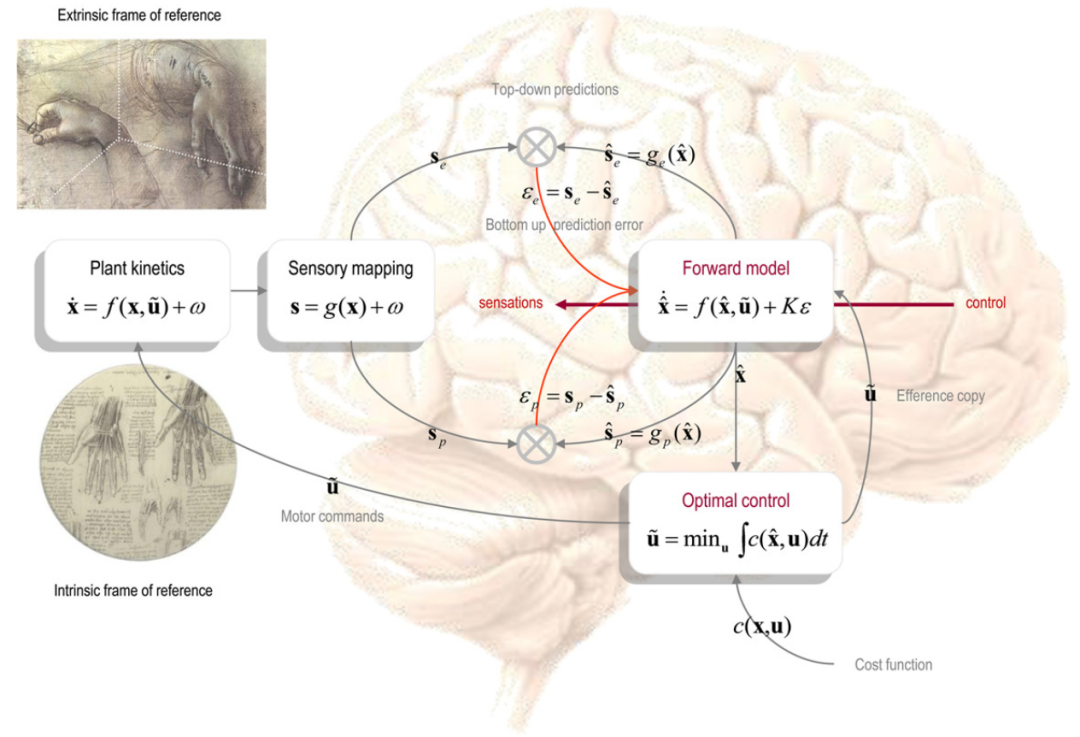
图2. 运动控制中的预测编码

总之,将最优运动控制转化为预测编码是直截了当的。在这种设置中,前向模型是从控制到感觉结果的生成模型的一部分。从最优控制方案的角度来看,这种区别可能微不足道,但对于主动推理来说却很重要,正如我们将在下文看到的那样。
图2区分了由外在和内在参照系中的(隐藏)状态引起的感觉的外感和本体感预测误差。在这里,(高维)内在参照系包含运动装置的状态(例如,肌纤维)。相反,(低维)外在参照系包含在外部空间中的运动(例如,以头为中心的参照系)。内在和外在参照系的概念是根据Kakei等人(2003年)和Shipp(2005年)的理解使用的:Kakei等人讨论了运动表示,这些表示从一个“表示目标空间位置的外在坐标系”开始,并以描述肌肉激活模式的内在坐标系结束。在Feldman和Levin(1995)中,这些参照系是根据物理(内在)和动作感知(外在)参照系来考虑的。这种区别很重要,因为最优控制必须从(1)控制信号到内在(基于肌肉)参照系中的结果的映射进行反演,然后(2)从内在到外在(基于运动)参照系进行映射,其中定义了期望的运动。简而言之,反演映射包括两部分:从外在到内在参照系的映射和从内在参照系到控制信号的映射。反演问题的第二部分很容易,因为运动神经元活动与其结果之间有着简单的关系(如果α运动神经元发射,其肌肉纤维则收缩)。然而,第一部分使反演变得困难,因为有许多内在的自由度相互作用产生外在坐标的轨迹。在接下来的内容中,我们将分离容易(内在)和困难(外在)的反演问题,然后解决困难问题。
Reflex Arcs and the Easy Inverse Problem反射弧和简单逆问题
回顾一下,最优控制中进行状态估计的动机是为了解决嘈杂和延迟的感觉输入问题。然而,从大脑皮层发出的下行控制信号也存在延迟。如果我们认为经典反射弧正在解决简单(内在)的反演问题,那么这些延迟就可以被忽略。换句话说,如果运动神经元被布线到在脊髓的背角抑制本体感预测误差,它们实际上实现了一个反向模型,将期望的感觉结果映射到内在(基于肌肉)坐标系中的原因。在传统方案的简化中,下行运动命令变成了由初级和次级感觉传入神经元传递的本体感的自顶向下预测。需要注意的是,这不是一个开环方案,因为自顶向下的预测是闭环的一部分,通过使用自下而上的(例如,视觉)感觉来优化隐藏状态的估计。
这种简化体现了运动系统的递归和分层解剖学特点,并承认了外周和中枢水平上嵌套的闭环动力学的作用。在这种方案中,最优控制信号间接地通过有关期望的本体感结果的预测来指示动作。这意味着它们的作用是提供有关最小化成本的隐藏状态变化的预测。这些预测(来自图1中的前向模型)要求最优控制来解决困难(外在)的反演问题。然而,这不再是必要的,因为在内在坐标系中不需要控制信号(因为外在预测的内在结果驱动动作)。因此,只需在外在参照系中为前向模型提供有关期望轨迹的预测就足够了。这意味着我们不必解决内在肌肉收缩如何产生外在运动的困难问题;我们只需要解决如何使(外在)运动拉伸(内在)肌肉的前向问题。换句话说,反向模型(最优控制)是不必要的。这将我们带到了主动推理。
Active Inference, Cost, and Priors主动推理、成本和先验
主动推理通过用关于肢体轨迹的先验信念(在外部框架中)取代指定肌肉运动的最优控制信号(在内部框架中),规避了困难的反问题。结果方案如图3所示,其中前向模型现在将关于期望轨迹的先验信念映射到它们的感觉后果上。该模型在形式上与用于感知推理的分层模型完全相同。在这种设置中,运动命令被转换为预测的本体感觉,而它们的外部感觉对应物则成为相关的释放(见图4的左面板)。简而言之,通过一个简单的调整,我们消除了对最优控制和贝尔曼最优方程的需求。这从根本上改变了运动控制的规范模型:最优控制依赖于反模型提供控制信号,这些信号规定了相对于某些成本函数的轨迹。在主动推理中,轨迹是贝叶斯最优的(相对于感官证据或自由能),而没有反模型或成本函数的涉及。这一区别很重要,因为贝叶斯最优轨迹可能并不一定具有明确定义的成本函数(如下所述)。简而言之,主动推理与生成型前向模型的贝叶斯感知和感知运动学习一致,并消除了计算成本的问题。这在费尔德曼(2009)中得到了很好的总结:“基于运动预报的和内部模型理论考虑了所需运动和相关运动命令之间的映射问题。假设通过使用参考框架作为行为生成工具来解决此问题,系统不需要预先编程这些命令。”
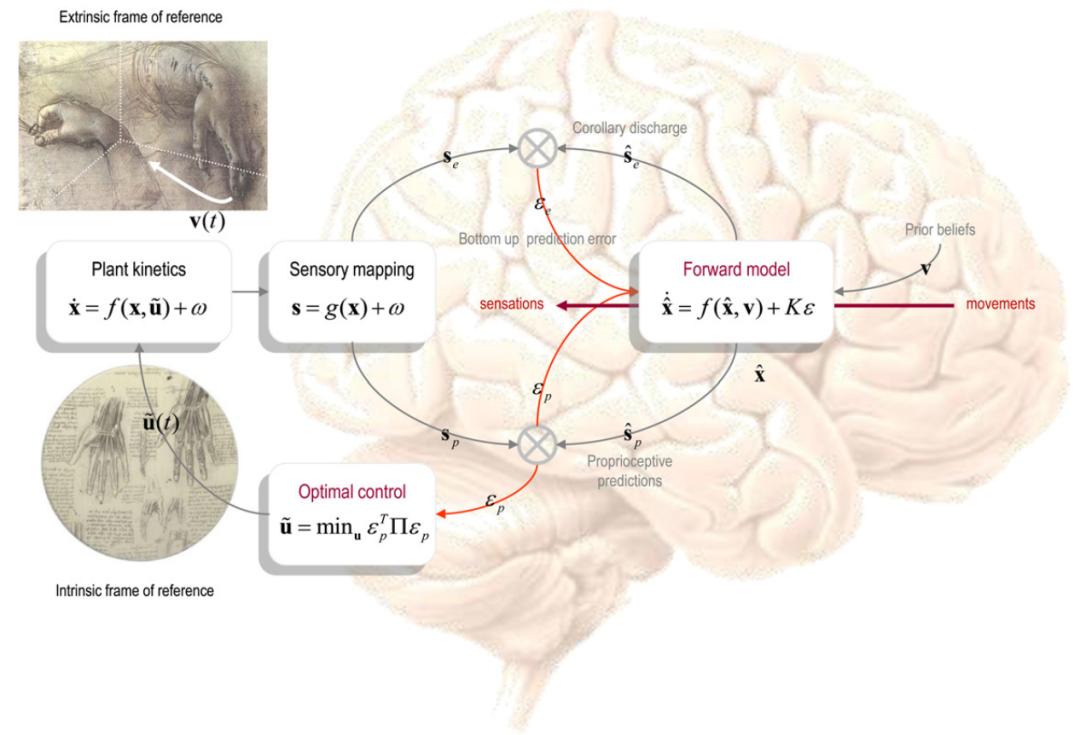
图3. 主动推理 该图代表了前一图中预测编码方案的最终简化。在这里,成本函数被替换为关于(期望的)轨迹在外部参考框架中的先验信念。这些信念进入贝叶斯滤波器,以指导对感觉输入的预测。通过经典的运动反射弧,在外围完成了本体感觉的预测,而关于外部感觉输入的预测对应于相关放电,并且是感知推理的一个组成部分。请注意,最优控制现在简化为仅抑制本体感觉的预测误差。这就是主动推理。
值得注意的是,将成本函数替换为先验信念并不是没有代价的。众所周知,在将问题阐述为推理问题时,问题的计算复杂度并不会减少;关于这一点可以参考Littman等人(2001)在随机可满足性问题设置中的处理。这一事实可以通过在近似最优控制和贝叶斯推理中发现的许多程序来证明。这些程序包括最小化Kullback-Leibler散度(Todorov, 2008;Kappen等人,2009)和期望最大化(Toussaint和Storkey,2006),这两者都可以被表述为最小化自由能(Neal和Hinton,1998)。从某种意义上说,主动推理用一个难推理的最优控制问题取代了一个难最优控制问题。话虽如此,主动推理的好处在于,这些问题可以通过一种简单且符合神经生物学的方式得到解决:通过有效地为预测编码方案配备经典的反射弧(参见图4和Mumford,1992;Friston,2008)。也许,支持主动推理作为运动控制的规范模型的最具说服力的论据是,关于行为的先验信念在层次感知推理中自然而然地出现为自上而下或经验性的先验。这与最优控制形成对比,因为最优控制最终仍然需要解释如何优化成本函数本身。简言之,主动推理消除了成本函数中隐含的人类本体。
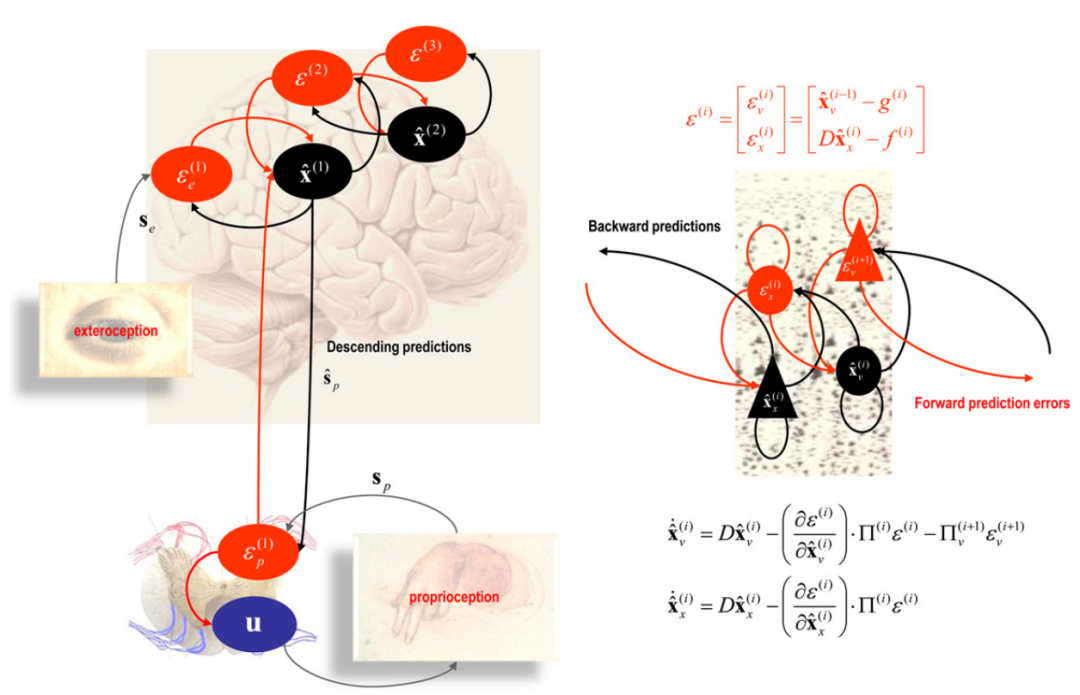
Figure 4. Hierarchical Message Passing in the Brain
图4. 大脑中的分层消息传递 该图示意了可能实现主动推理的一种神经架构。左侧面板显示了预测编码方案的示意图,其中贝叶斯滤波通过浅层(红色)和深层(黑色)金字塔细胞之间的神经信息传递来实现,这些细胞编码了预测误差和条件预测或估计(Mumford,1992)。在这些预测编码方案中,通过反向连接传递的自上而下的预测与下层的状态估计进行比较,形成一个预测误差。然后,这个预测误差以贝叶斯最优的方式向前传递,以更新状态估计。在主动推理中,这个方案简单地扩展到包括经典的反射弧,其中本体感知预测误差驱动脊髓腹角的α运动神经元,以引发外肌收缩和来自肌肉纤维束的初级感觉传入的变化。这些抑制由Renshaw细胞编码的预测误差。右侧面板呈现了在大脑皮层分层中某个任意水平的预测误差和状态估计单元的示意图。在这个示例中,隐藏状态(xx)建模动态,而隐藏原因(xv)介导了上一层对下一层的影响。方程对应于在广义坐标中的广义贝叶斯滤波或预测编码,如(Friston,2008)中描述的。在这种分层形式中,
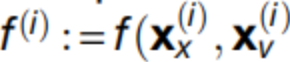
对应于第i层的运动方程,而
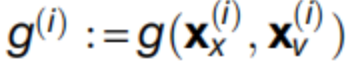
连接层。这些方程构成了代理人的先验信念。D是一个导数运算符,P(i)表示精度或逆方差。这些方程被用于下一个图表中呈现的模拟。
Active Inference and Optimal Control主动推理和最优控制
在这一部分,我们将比较和对比主动推理与最优控制在多个不同层面的情况。我们将从实现和参考框架的层面开始,然后转向在理论层面上的关系,即成本函数与先验之间以及最优控制与推理之间的对偶关系。
在传统方案中,内在参考框架包含引起运动的因素(肌肉长度的变化),而结果(肢体位置的变化)以外部坐标表示。主动推理将其颠倒过来,将引起运动的先验信念视为存在于外部坐标中,而结果则在内在坐标中展开。从哪个角度来看,这些观点是等价的呢?直觉上,一个可以将肢体视为被肌肉拉动,或者将肌肉视为被肢体推动。然而,从隐藏状态(肌肉长度和肢体位置)的角度来看,这两种情况是相同的。换句话说,推和拉的语义纯粹是启发式的;在两种参考框架中,潜在的轨迹只是适当的欧拉-拉格朗日运动方程的解。在主动推理中,由肌肉长度变化引起的运动被建模为导致肌肉长度变化的运动;参见被动运动范式(Mussa Ivaldi等人,1988年)。直观地说,这是有道理的,因为我们意识到的是运动,而不是肌肉。
每一个由成本函数指定的运动是否也能由先验信念来指定?通过诉诸完备类定理(Brown,1981;Robert,1992),可以建立成本函数和先验信念之间的等价关系。该定理表明,任何行为至少对于某个先验信念和成本函数而言都是贝叶斯最优的。然而,这对并不一定是唯一的,这意味着可以交换先验信念和成本函数来产生相同的运动行为。这在主动推理中被利用,以提供一种可以被视为具有运动反射的预测编码的生物学上可行的解决方案。这个方案也可以被视为平衡点假说的一个实例(Feldman and Levin,1995),在这个假说中,固定点被由运动的先验信念指定的轨迹所取代。在主动推理中,这些实际上是在层级生成模型的感知反演过程中持续更新的经验先验。在这种设置中,最优轨迹只是在当前环境下具有最大后验概率的运动。请参阅图4。
Optimal Control as Inference最优控制作为推理
Todorov (2008)清楚地阐述了最优控制和估计之间的对偶关系,这一关系可以追溯到卡尔曼滤波的提出。早期的建议利用这种等价关系,用一个条件于期望观测的辅助随机变量来替代成本。这意味着最小化成本等价于最大化期望观测的似然性。随后的工作集中于解决随之而来的推理问题的高效方法。Dayan和Hinton (1997)在立即奖励的情况下提出了一种期望最大化算法,而Toussaint和Storkey (2006)将计算最优策略的问题表述为一个似然最大化问题。最近,变分贝叶斯程序已被应用于马尔可夫决策过程中的最优决策问题(Botvinick and An, 2008;Hoffman et al., 2009;Toussaint et al., 2008)以及随机最优控制(Mitter and Newton, 2003;Kappen, 2005;van den Broek et al., 2008;Rawlik et al., 2010)。这些方法利用变分技术提供了高效且可计算的解决方案,特别是通过以Kullback-Leibler最小化的形式(Kappen, 2005)和使用Feynman-Kac公式计算成本函数的路径积分(Theodorou et al., 2010;Braun et al., 2011)。那么,主动推理又提供了什么?
Prior Beliefs or Cost Functions?先验信念还是成本函数?
主动推理超越了简单地指出最优控制和贝叶斯推断之间的形式等价性。它将最优控制视为推断的特殊情况,因为有些策略可以由先验指定,而无法由成本函数指定。这源自变分微积分的基本引理,该引理指出,策略或轨迹具有旋度无旋和散度无旋的成分,分别表示值是否变化。这意味着价值只能指定策略的旋度无旋部分。具有旋度无旋的策略或运动被称为具有详细平衡,并且可以表示为李亚普诺夫函数或价值函数的梯度(Ao, 2004)。这意味着只有先验信念才能规定所需的可以行走或书写的无散度运动。这种运动也被称为“螺旋的”,就像搅拌咖啡一样,而不能用成本函数来规定,因为轨迹的每个部分都同样有价值。那么,这对主动推理来说不是问题吗?
主动推理和最优控制之间的差异在于价值或其补充物成本的定义。在最优控制中,价值是成本函数的路径积分,而在主动推理中,价值只是特定状态在关于运动的先验信念下被占据的对数概率或逗留时间。这种价值不需要成本函数。从技术上讲,在随机最优控制中,动作由价值指定,这需要解决一个称为Kolmogorov反向方程的东西。这个方程从未来向现在积分,从未来或终端状态的成本函数开始。相反,在主动推理中,动作直接由先验信念指定,价值由Kolmogorov正向方程的稳态解决定。在主动推理中的正向优化类型与最近引入的用于控制具有螺旋或周期运动的随机非线性问题的优化性质密切相关,例如在运动中,“最优控制过程的稳态状态分布”被近似。简而言之,最优运动由先验信念确定,先验信念赋予状态特定的价值; 但是,价值是最优行为的结果,而不是原因。这里的关键是成本到终点和惊喜是一样的。这确保了最大化价值的长期平均值与最小化感官状态的熵是相同的。这是自由能原理所要求的,也与最大化贝叶斯模型证据相同。价值和惊喜都通过贝叶斯推断进行优化,但两者都不依赖于成本函数。我们将在下面看到一个无成本优化的例子。
总之,最优控制的原则在于将最优运动减少到在价值函数上的流动,就像水流的下坡流动一样。相反,在主动推理中,流动是直接根据构成先验信念的运动方程来指定的,就像风流的模式一样。本质上的区别在于,先验信念可以包括无旋流动(例如,大气环流或科氏效应),而这种流动不能用(标量)价值函数来指定。话虽如此,我不想夸大最优控制在指定极限环或无旋运动方面的缺点; 例如,在最近关于模拟行走的文献中有令人信服的例子。这些方案采用了同时轨迹优化,其使用了轨迹的显式表示(而不是仅表示动作序列的顺序算法)。这种泛化将特定状态的成本函数替换为轨迹上的成本函数。实际上,这将优化一系列运动转换为在高维状态空间上优化价值函数,其坐标是不同时间的状态。这个空间中的一个点编码了一个序列或轨迹。然而,这引出了一个问题,即如何指定一系列序列的行程,而不需要调用甚至更高维的状态空间表示。在推理中,这很容易解决,其中关于序列的先验信念直接由吸引子的层次结构或中央模式生成器编码。最优控制的另一个泛化是考虑随时间变化的价值函数。直观地说,这就像用移动的胡萝卜引导驴子一样(而不是将胡萝卜放在固定位置然后希望驴子找到它)。然而,这只是将问题转化为关于胡萝卜如何移动的问题。在主动推理中,可以将胡萝卜看作是先验信念(指定所需轨迹),而驴子则受后验信念和经典反射的驱使来追随胡萝卜。
Efference Copy and Corollary Discharge效果副本和推论放电
最后,主动推理提供了对运动输出拷贝(EC)和附带放电的特定解释,该解释预测了下行运动信号的感觉后果。在主动推理中,下行信号本身就是感觉后果的预测(参见附带放电)。在这个意义上,大脑中的每一个反向连接(传递自顶向下的预测)都可以被视为附带放电,报告某种感觉运动构建的预测。高级(无模态)表示既具有运动后果又具有感觉后果的事实突显了行动与感知之间密切的关系。请注意,在主动推理中,运动输出拷贝本身消失了。这可能并不太令人惊讶,因为有人断言,“通过EC理论特别是或通过内部模型理论一般提供的动作和感知三个经典问题(姿势 - 运动问题、动觉问题和视觉空间恒常性问题)的解决方案在生理上是不可行的”(Feldman,2009)。
Discussion讨论
上述论点以一种相当抽象的方式呈现,没有对支撑主动推理的假设或背景进行实质性的说明。最好通过参考以下工作来填补这一遗漏,该工作表明成本函数和最优策略可以在主动推理的背景下被制定为先验信念(Friston等人,2009),并且相同的方案可以扩展到包括启发式策略(Gigerenzer和Gaissmaier,2011),这些策略使用动力系统理论进行制定(Friston,2010)。在运动领域,主动推理为视网膜稳定、眼球运动反射、快速眼球运动、提示性伸手、感觉运动整合和自主行为学习提供了一个合理的解释(Friston等人,2010)。在这种情况下,贝叶斯最优的感知运动整合(Ko¨ rding和Wolpert,2004)是一种由于将动作吸收到感知推理中而产生的新属性。当模拟动作观察时,这一点得到了很好的说明。图5中提供了一个例子,其中相同的方案被用来生成自主(手写)运动,并识别由另一代理执行的相同运动。此示例中使用的方程可以在Friston等人(2011)中找到。选择这个例子是为了表明相同的(神经元)表示在执行动作和观察相同动作时扮演先验信念的角色。在这个意义上,镜像神经元的存在(对动作和观察相同动作的选择性响应)是对最优性和推理之间双重性的实证证明。有趣的是,我们可以看到是否可以使用最优控制理论重新复制镜像神经元系统的这种模拟(Miall,2003)。这是一个略微不诚实的挑战,因为最优控制不能产生手写,因为所需的运动是螺旋状的。如上所述,这是最优控制在涉及到巡回(顺序和徘徊)运动时的不足之处。简而言之,完备类定理表明,由成本函数指定的任何最优轨迹都可以由先验信念指定,但并非每个最优轨迹都可以由成本函数指定。
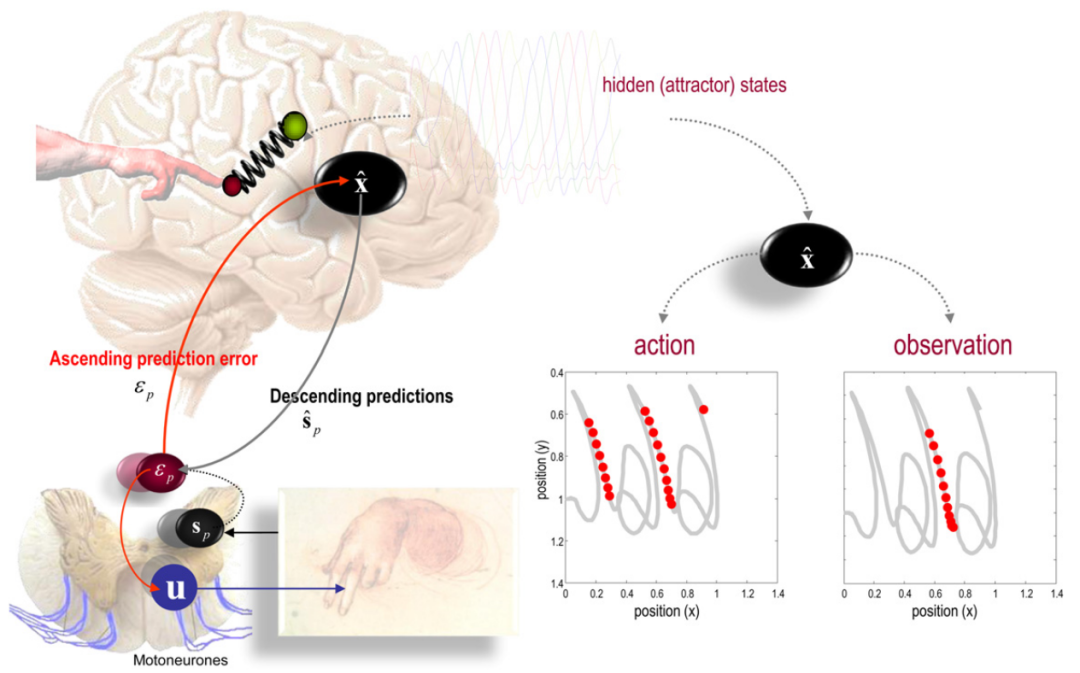
Figure 5. Active Inference and Action Observation主动推理和行动观察
本示意图总结了Friston等人(2011)报道的动作观察模拟的结果。左侧面板将大脑描绘为运动轨迹的前向或生成模型(基于Lotka-Volterra吸引子,其状态以彩色线条随时间变化显示)。该模型提供了关于视觉和本体感输入的预测,这些输入通过脊髓水平的反射弧来规定运动(插图在左下方)。变量的含义与先前的图表相同。吸引子动态与本体感后果之间的映射是通过牛顿力学模拟的,该力学作用于一个双关节手臂,其末端(红色球)由一个想象中的弹簧被拉向目标位置(绿色球)。目标位置(以外部坐标系表示)由吸引子动态中当前活动状态规定。这些吸引子动态及其到外部(运动)坐标系的映射构成了代理的先验信念。随后的后验信念在推理过程中通过预测误差与视觉和本体感觉同步,如前图所总结。所得到的运动序列被配置成类似书写的样子,并作为随时间位置的函数显示在右下方(厚灰色线条)。这些轨迹上的红色点表示在动作过程中何时某个隐藏吸引子状态的特定神经元或神经元群被激活(左侧),以及何时进行同样动作的观察过程中(右侧)。更准确地说,这些点表示响应何时超过了最大活动的一半,并且以肢体位置的函数显示。左侧面板显示了动作期间的响应,并展示了类似位置细胞的选择性和在外部坐标系中运动的方向性选择性。右侧的等价结果是通过向代理呈现相同的视觉信息,但移除本体感知而获得的。这可以被认为是对动作观察的模拟和神经元样活动的镜像。从当前讨论的角度来看,这是一个有趣的例子,因为它突显了感知推理与动作之间的密切关系。
本文讨论的问题在很大程度上是理论性的,涉及到运动控制的形式化或计算建模:具体而言,这些模型应该基于最优控制理论还是最优贝叶斯推理。然而,答案具有一些深刻的神经生物学含义。例如,如果下行运动命令是自顶向下的预测,那么下行运动输出应该与其他系统中的自顶向下或向后连接具有相似的生理和解剖特征。事实上,来自主运动皮层的下行投射与视觉皮层中的向后连接具有许多相似之处:它们起源于颗粒下层,并且以NMDA受体表达的细胞为目标。从正统观点来看(Shipp,2005),这有些矛盾,因为向后调制特性(Sherman和Guillery,1998)不应该是驱动运动命令信号的预期特征。这种表面上的矛盾通过主动推理得到解决,主动推理还提供了一个原则性解释,解释了为什么运动皮层是无颗粒的(R. Adams,个人交流)。
显然,区分最优控制和主动推理涉及许多操作性问题。例如,主动推理如何补偿改变的肢体动力学或外部干扰?对此的处理可以在Friston等人(2010)中找到,其中显示运动轨迹对于肢体上的力和运动增益的波动都表现出了显著的稳健性。就启发性而言,主动推理立即抵消了未预测的力(以抑制力的预测误差);相反,最优控制只能在未预测的力改变运动装置的状态之后调整其(状态相关的)控制信号。我们还未考虑的另一个关键领域是先验信念的学习或获取。在最优控制中,值函数是通过学习的,而在主动推理中,问题归结为学习构成先验信念的参数(运动方程的参数)。这是推理中的一个标准问题,对应于感知学习。例如,图5中所示的代理可以在动作观察期间(关于自由能)优化其参数,并在执行动作期间使用它们来复制观察到的行为。请注意,这种模仿学习形式归结为纯粹的感知学习,并且避开了通过观察被最优控制系统推理值函数的逆优化控制问题(Dvijotham和Todorov,2010)。从主动推理的角度来看,成本函数代表了关于未来的先验信念的一种特定方式。有趣的是,它们的形式简单性使它们成为认知层面目标表示的一个有吸引力的候选者。换句话说,在行为的意识控制中,我们可能会显式地表示成本函数。这在使用最优决策理论描述规划和选择时是隐含的(Botvinick和An,2008;Gläscher等人,2010)。然而,这里提出的论点表明,成本函数本身并不是运动控制的固有部分,因为它们只能指定具有详细平衡的运动轨迹的组成部分。
Conclusion结论
总的来说,主动推理有几个吸引人之处。首先,它摒弃了最优控制(即解决最优性方程和学习成本的问题)。这很重要,因为没有可以处理连续时间中的非线性(和无散度)控制问题的生物学合理方案。其次,它解决了经典形式中延迟控制信号的问题。换句话说,运动皮质脊髓信号是在外周水平上使用快速闭环机制(即外周反射弧)实现的预测。如果这些预测是生成模型的一部分,那么它们可以预见到延迟。最后,主动推理解决了伯恩斯坦的问题。伯恩斯坦的问题在于从内在框架到外在框架的一对多映射。这导致了产生特定轨迹的不确定性。逆问题的结果是,必须调用辅助客观函数(如最小的加速度)来提供唯一的解决方案。在主动推理中,通过关于轨迹的先验信念(可能包括最小加速度)解决了这些问题,这些先验信念唯一地确定了(内在的)运动的(外在的)运动的后果。
一篇即将发表的传感运动学习综述(Wolpert等人,2011)突显了运动控制理论面临的三个关键挑战,这些挑战可以根据上述讨论得到解决:
1. “尚不清楚所开发的学习模型是否能推广到系鞋带或学习滑板等任务。”在这里,最优控制理论将失败,因为这些行为(如书写)涉及到旋转运动。
2. “到目前为止,生物传感运动控制研究中的相对少数原则已经应用到了机器人技术中。”这可能是因为在实际情况下,解决最优方程是棘手的(或者非常缓慢的)。值得注意的是,在机器人学中,引人注目的生物运动再现(Tani,2003)可以被看作是主动推理,其中逆模型(最优控制)被模型反演所取代。
3. “尽管在计算传感运动控制方面取得了重大进展,但该领域在将计算模型与控制的神经生物学模型联系起来方面进展较少。”这可能是因为逆向模型和正向模型并不存在,因为没有最优控制器。这的一个重要推论是,最优控制方案需要学习正向模型和逆向模型(通过使用相关学习和价值学习,分别)。在主动推理中,只有生成模型的相关学习。
这篇文章提出了一个关于最优控制、逆向模型和成本函数在运动控制理论中的有用性的挑衅性问题。我有些期待的答案可能是:“你所说的很有趣,但你忽视了一个基本问题”,或者“最优控制理论是必要的,以解释以下经验观察”。也许在提出这个问题后,人们会提供一些能够改变或细化我的结论的答案。