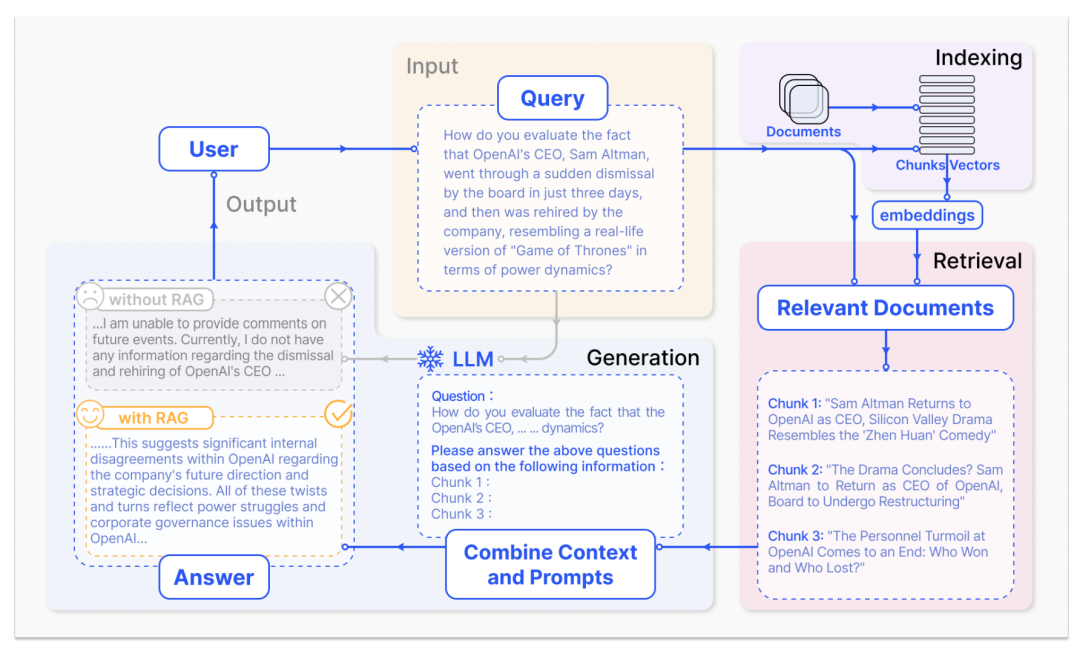
在当前信息时代,大型语言模型(Large Language Models,LLMs)的发展速度和影响力日益显著。随着技术进步,我们见证了从基本的Transformer架构到更为复杂和高效的模型架构的演进,如Mixture of Experts (MOE) 和Retrieval-Augmented Generation (RAG)。这些进步不仅推动了人工智能领域的边界,也对理解和应用这些技术提出了新的要求。
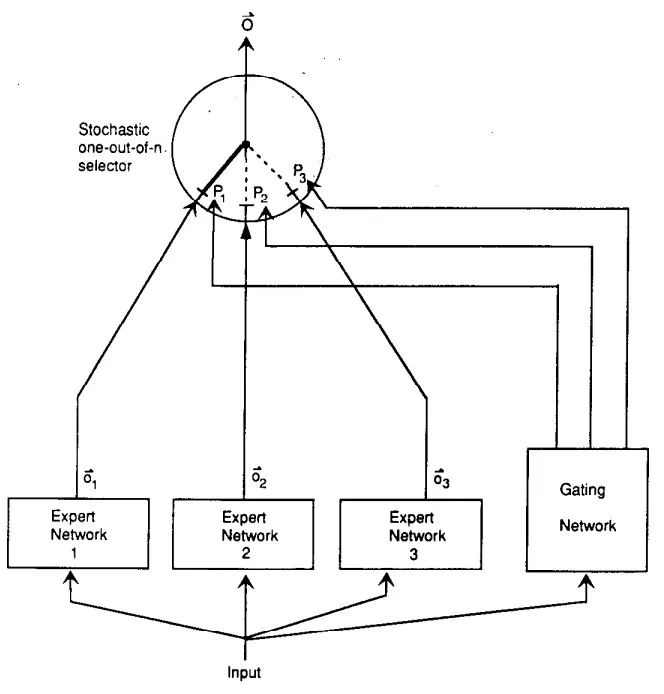
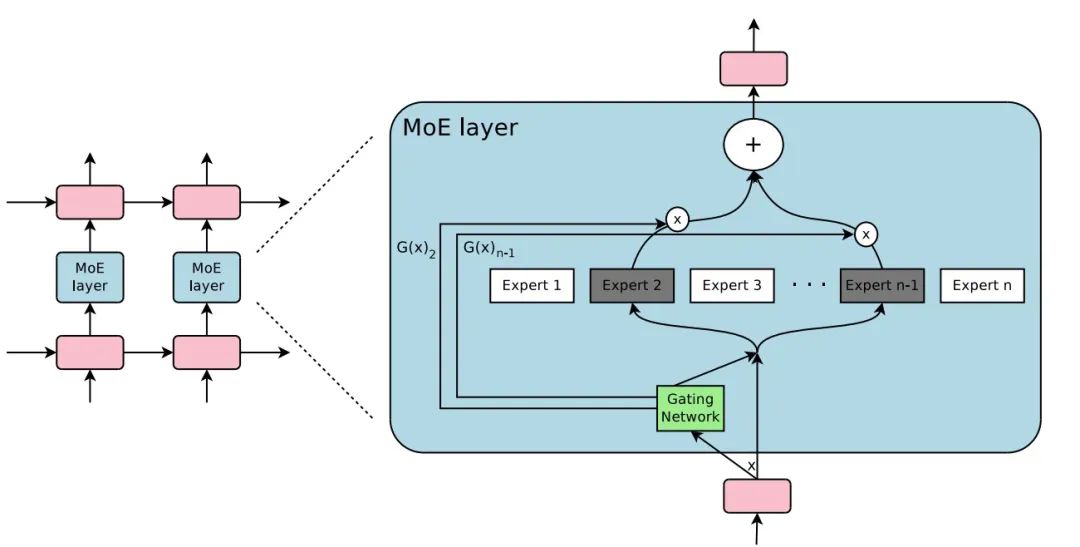
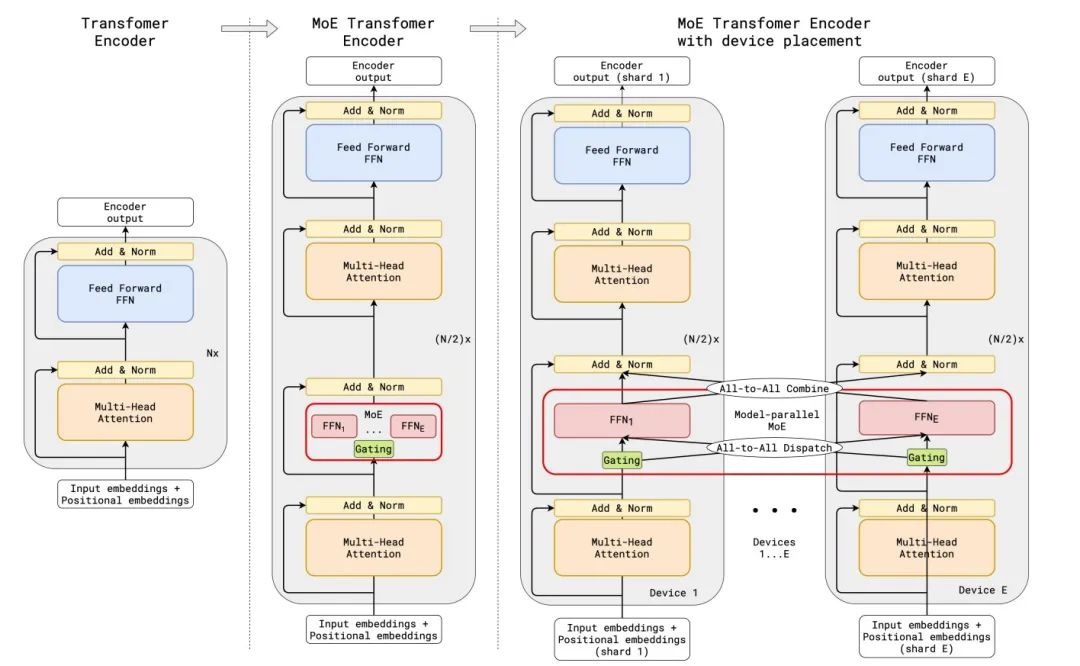
MoE的理念起源于1991年的论文Adaptive Mixture of Local Experts。考虑到多任务场景下训练同一模型,在某场景更新权重时会影响到模型对其他场景的表现,干扰效应强,会造成学习缓慢和泛化不良,在这种情况下,给定训练样本,如果能够事先知道其对应于哪个子任务,那么可以使用由几个不同的“专家”网络组成的系统以及使用一个门控网络来决定每个训练样本应该使用哪个专家。如果输出不正确,权重变化将定位到所选专家(和门控网络),不会干扰到其他专家在其他情况下的权重
-\inftyG(x)=Softmax(KeepTopK(H(x),k))H(x)_i=(x\cdot W_g)_i+StandardNormal()\cdot Softplus((x\cdot W_{noise})_i)
KeepTopK(v,k)_i=\begin{cases}v_i&\text{ if }v_i\text{ is in the top }k\text{ elements of }v.\\-\infty&\text{ otherwise.}\end{cases}
Sanseviero, et al., ["Mixture of Experts Explained"], Hugging Face Blog, 2023.
Jacobs, R. A., Jordan, M. I., Nowlan, S. J., & Hinton, G. E. (1991). Adaptive mixtures of local experts. Neural computation, 3(1), 79-87.
Shazeer, N., Mirhoseini, A., Maziarz, K., Davis, A., Le, Q., Hinton, G., & Dean, J. (2017). Outrageously large neural networks: The sparsely-gated mixture-of-experts layer. arXiv preprint arXiv:1701.06538.
[Mixture-of-Experts (MoE) 经典论文一览]
Lepikhin, D., Lee, H., Xu, Y., Chen, D., Firat, O., Huang, Y., ... & Chen, Z. (2020). Gshard: Scaling giant models with conditional computation and automatic sharding. arXiv preprint arXiv:2006.16668.
Gao, Y., Xiong, Y., Gao, X., Jia, K., Pan, J., Bi, Y., ... & Wang, H. (2023). Retrieval-augmented generation for large language models: A survey. arXiv preprint arXiv:2312.10997.
[Advanced RAG Techniques: an Illustrated Overview]